
Interactive Attention-Based Convolutional GRU for Aspect Level Sentiment Analysis
- DOI
- 10.2991/hcis.k.210704.002How to use a DOI?
- Keywords
- Sentiment classification; convolutional neural network; gated recurrent units; attention mechanism
- Abstract
Aspect level sentiment analysis aims at identifying sentiment polarity towards specific aspect terms in a given sentence. Most methods based on deep learning integrate Recurrent Neural Network (RNN) and its variants with the attention mechanism to model the influence of different context words on sentiment polarity. In recent research, Convolutional Neural Network (CNN) and gating mechanism are introduced to obtain complex semantic representation. However, existing methods have not realized the importance of sufficiently combining the sequence modeling ability of RNN with the high-dimensional feature extraction ability of CNN. Targeting this problem, we propose a novel solution named Interactive Attention-based Convolutional Bidirectional Gated Recurrent Unit (IAC-GRU). IAC-GRU not only incorporates the sequence feature extracted by Bi-GRU into CNN to accurately predict the sentiment polarity, but also models the target and the context words separately and learns mutual influence between them. Additionally, we also incorporate the position information and Part-of-Speech (POS) information as prior knowledge into the embedding layer. The experimental results on SemEval2014 datasets show the effectiveness of our proposed model.
- Copyright
- © 2021 The Authors. Publishing services by Atlantis Press International B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Sentiment analysis is a vital task in Natural Language Processing (NLP), which has received extensive attention from academic and industry. Traditional sentiment analysis can be divided into two categories: the document level and the sentence level, assuming that a document or a sentence contains only one sentiment polarity, respectively. The above assumption is unreasonable in many cases, which is compensated by fine-grained aspect-level sentiment analysis. Aspect-level sentiment analysis aims at identifying sentiment polarity towards different aspect terms in a given sentence. For instance, in the sentence “the bathroom is tidy but the service is terrible.”, the polarity for the aspect “bathroom” and “service” are positive and negative separately.
Traditional approaches generally design rich features for sentiment classification [1,2], but the method is time-consuming and labor-intensive. More importantly, its performance greatly depends on the quality of feature engineering and has encountered bottlenecks. With the great success of deep learning in machine translation [3], question answering [4], and other fields, researchers have introduced Recurrent Neural Network (RNN) and its variants into aspect level sentiment analysis, such as target-dependent Long-Short Term Memory (TD-LSTM) and target-connection LSTM (TC-LSTM) proposed by Tang et al. [5] which models the interaction between target and context words, and Hierarchical Bidirectional LSTM proposed by Ruder et al. [6]. To enforce the model to pay much attention to the aspect-specific words, attention mechanism have been introduced into deep neural network and achieved outstanding performance, e.g. ATAE-LSTM [7], IAN [8]. After incorporating various additional auxiliary information like location information, commonsense information, etc. into the model, RNN-based model has already achieved advanced performance while it’s complex and time-consuming during training. Gated mechanism-based Convolutional Neural Network (CNN) provides researchers alternative approach with simpler structure and superior performance [9–11].
In previous work, either a complex RNN-based attention mechanism or gated mechanism-based CNN was used to improve performance. But both approaches sacrifice the advantages of the other. Therefore, this paper proposes a neural network model, named Interactive Attention-based Convolutional Bidirectional Gated Recurrent Unit (IAC-GRU), which integrates CNN and Bi-GRU to effectively extract complex semantics and sequence features as well as aspect-specific correlation. In addition, position and Part-of-Speech (POS) information are incorporated into word embedding to distinguish the crucial information of the context words for polarity detection. Inspired by previous studies, an interactive attention network is used to model targets and context words respectively and calculate their mutual effects.
The contributions of this paper is as follows: (1) A novel IAC-GRU based on the fusion of CNN and Bi-GRU is presented. (2) The effectiveness of the position information of context words relative to aspect terms is investigated. (3) The validity of the filtered POS information of context words and target words is studied. (4) Experimental results indicate that our IAC-GRU surpasses the state-of-art baselines on the widely used SemEval2014 datasets.
The remaining of this paper is organized as follows. Section 2 discusses the existing works in aspect level sentiment analysis. Section 3 details the proposed model including word embedding, neural network and attention mechanism. Section 4 shows the competitive results on well-known datasets and verifies the effectiveness of our model. Finally, we summarize our work in Section 5.
2. RELATED WORK
Different from traditional sentiment analysis, aspect level sentiment analysis aims at identifying sentiment polarity towards different aspect terms in a given sentence. Earlier methods are generally based on dictionary or machine learning depended on various kinds of artificial features. Dictionary-based method generally aggregates the sentiment features of surrounding words to aspect term itself. In [12], Hu and Liu assigned a sentiment label to each adjective in the sentence by looking up the sentiment dictionary. If there are negators in the surrounding five words, the sentiment polarity will be reversed. Finally, the majority voting is used to assign the same sentiment labels to all targets in the sentence. Traditional methods based on machine learning are commonly achieved by constructing semantic features to train classifiers. Yu and Zha [13] employed a parse tree to obtain sentiment words for each aspect and used SVM to obtain the sentiment label. Jiang et al. [14] explored the grammar structures to build SVM classifier. Rao et al. [15] applied a graph-based semi-supervised learning framework to build sentiment lexicons, which has achieved competitive performance. However, aforementioned methods are time-consuming and labor-intensive.
Recently, a variety of deep neural networks have been proposed and achieved remarkable results in aspect level sentiment analysis, e.g. Recursive Neural Network [16–18], Recurrent Neural Network [5–7], Convolutional Neural Network [19], Memory Network [20–23].
Tang et al. [5] first introduced LSTM into aspect level sentiment analysis to capture the relationship between target and context words. Jiang et al. [1] revealed that 40% of the errors were due to neglected target information. Hence, Tang et al. [5] divided a sentence into left and right parts fused with target information and used two separate LSTMs to model the relation. LSTM is limited to capturing the information transmitted from the proceeding text to the following text. Ruder et al. [6] applied a hierarchical bidirectional LSTM to leverage the intra- and inter-sentence relationships. To enforce the model to attend important information related to targets, Wang et al. [7] took the concatenations of the word embedding and aspect embedding as the input of LSTM and joined the attention mechanism behind the hidden layer to classify the sentiment label which validate the effectiveness of attention mechanism. The biggest performance limitation of fine-grained sentiment analysis lies in the serious lack of training samples. He et al. [24] adopted pre-training and multi-task learning based on attentive LSTM model to transfer the knowledge learned from extensive document level corpus to aspect level sentiment analysis. Ma et al. [8] made use of LSTM to extract sequence features of target and context words respectively to monitor the generation of attention weight vector. Compared with LSTM, CNN can capture higher level semantic features including local and global features.
Huang et al. [9] introduced a parameterized CNN. Xue et al. [19] incorporated the gating mechanism into CNN with multiple filters to extract n-gram features. Their performance proved that CNN-based method is a potential direction worth exploring. Memory network has achieved great success in the field of natural language processing and provides a new solution for aspect level sentiment analysis. Tang et al. [22] first proposed a multi-hop attention model based on external storage and used multiple computing layers to calculate the importance of text features. Li et al. [23] also presented an end-to-end method based on deep memory network to jointly perform aspect extraction and aspect-based sentiment analysis.
3. PROPOSED MODEL
In this section, we start with an overview of the proposed IAC-GRU model. Then, each layer of the IAC-GRU model is introduced in detail. Finally, we introduce the loss function. For aspect level sentiment analysis, we assume that the sentence, S = [w1, w2, ... wN], the aspect term, T = [t1, t2, ... tM] in which N represents the length of sentence, M represents the length of target and T is a subsequence of S. The goal of IAC-GRU model is to infer the sentiment polarity of different targets in a given sentence. Firstly, the target and context words are encoded respectively and position information and POS information are fused in word embedding. Next, word embeddings are input into separate two Bi-GRUs to collect the sequence features in a sentence. Then, a hidden layer state from Bi-GRU is fed into CNN and the maximum pooling is employed to calculate the interaction between target and context words. Finally, the output of two attention mechanisms is concatenated for a classifier. The overall architecture of our model is shown in Figure 1.
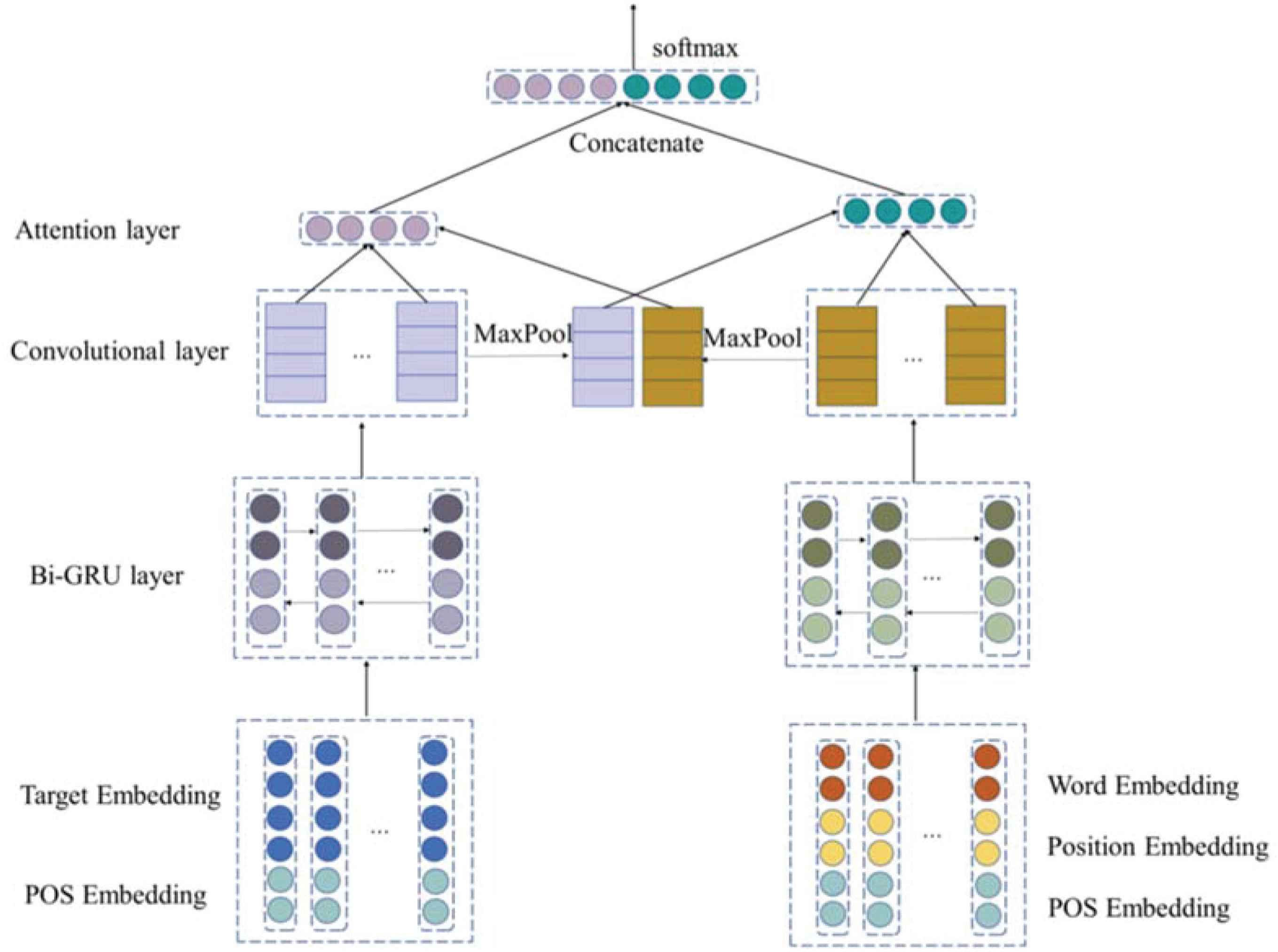
Architecture of the proposed model for aspect level sentiment analysis.
3.1. Position Embedding
Earlier studies have realized the significance of position information, and generally used pre-defined strategy and training as model parameters to model it. Tang et al. [22] combined two ways of taking position information into consideration and introduced them into the field of aspect level sentiment analysis. Inspired by previous approaches, we believe that context word closer to the target contributes more to the sentiment polarity given target. In order to quantify the correlation between target and context words, we use a relative distance to obtain a one-dimensional word position index or a word position matrix according to one or more aspect terms appearing in the sentence. We assume that the target itself in word position index is marked as 0. The relative distance of words ri is calculated as in (1):
3.2. POS Embedding
POS information is drawn as a prior knowledge into sentiment analysis to infer the sentiment polarity. However, not all POS categories have contribution to sentiment polarity, and blindly using POS categories introduces additional noise into the proposed model. Inspired by Shuang et al. [25], we assign POS tags to each word in the sentence from the candidate set {Padj, Padv, Pverb, Pother}. Taking the sentence “We recently decided to try this location, and to our delight, they have outdoor seating, perfect since I had my yorkie with me.” as an example, the natural language toolkit (NLTK) is employed to obtain the POS index in our experiment. Thus the POS index of sentence is represented as posc = {Pother, Padv, Pother, Pother, Pverb, Pother, Pother, Pother, Pother, Pother, Pother, Pother, Pother, Pother, Pother, Padj, Pother, Pother, Pother, Pother, Pother, Pother, Pother}. The POS index of aspect is represented as post = {Pother}. We acquire the final POS embedding of target
3.3. Word Embedding
We map the context of N words [w1, w2, ... wN] and the target of M words [t1, t2, ... tM] into a low-dimensional dense continuous embedding by looking up the embedding matrix E ∈ Rv×d, where v indicates the vocabulary size and d indicates the dimension of word embedding. In our experiment, E is initialized by pre-trained word embedding vector obtained by Glove [29]. We label the context embedding as [
3.4. Bidirectional Gated Recurrent Units
Standard RNN [26] has achieved excellent performance in numerous NLP tasks while it suffers from the problems of gradient explosion and vanishing gradient. LSTM [27], as a variant used to over-come the defects of RNN, does well in learning long-term dependencies. GRU [28] is similar to LSTM along with a simpler structure. Instead of introducing additional memory units, GRU adds an update gate based on the original RNN to control how much information the current state needs to retain from the historical state and the degree of receiving from the candidate state. GRU also uses a reset gate to control the influence of the previous state on the current state. The GRU state is calculated as follows:
3.5. Convolutional Nerual Network
We stitch CNN behind the hidden layer state of Bi-GRU to extract the local and global semantic features inside the targets and inside the context. For context words, we take the right hidden state as input and use the convolutional layer with multiple convolutional kernels along with different widths. We slide a convolution filter
3.6. Interactive Attention Network
Each word in a sentence has a different contribution to sentiment polarity. In order to enforce the proposed model pay attention to words more relevant to a given aspect, we introduce an interactive attention mechanism to treat the target and context words equally and calculate their interaction to supervise the generation of attention weight vector. We obtain the attention weights vector of aspect to context words αi and context to aspect words βi as follows:
3.7. Model Training
The objective of model optimization in our paper is to minimize cross-entropy loss between y and
4. EXPERIMENTS
4.1. Datasets
We conduct our experiments on SemEval 2014 Task 4, which contains abundant customer reviews of Restaurants and Laptop domains. The source datasets are signed with four sentiment polarity: positive, negative, conflict and neutral. Drawing on the experience of existing approaches, we remove conflict polarity. The details of data set are shown in Table 1.
| DataSet | Laptop | Restaurants | ||||
|---|---|---|---|---|---|---|
| Positive | Neural | Negative | Positive | Neural | Negative | |
| Train | 987 | 460 | 866 | 2164 | 633 | 805 |
| Test | 341 | 169 | 128 | 728 | 196 | 196 |
Details of the SemEval2014
4.2. Experimental Setting
In our experiments, we employ 300-dimensional word embedding vectors pre-trained by Glove [29]. Both position embedding dimension and POS dimension as auxiliary information are set to 100 and 36 as in [31], which is initialized randomly and fine-tuned during training process. Hidden units are set to 200. The coefficient for L2 regularization is set to 1e-5 and dropout is set to 0.5 as in [8]. In the relevant parameter settings of CNN, the kernel num is set to 100. The kernel sizes for context words and target terms are set to 1, 3, 5 and 1 as in [31], respectively. The batch size is set to 32 and the num of epoch is set to 100. We select Adam as an optimizer with a learning rate of 0.001. We choose Accuracy as the evaluation metric.
4.3. Baselines
In order to validate the effectiveness of model, we compare our proposed model with the following several classic and competitive models:
TD-LSTM: It uses a left one LSTML and a right one LSTMR to model the preceding and following contexts separately to take the target information into consideration and concatenates the hidden states from two LSTMs for final prediction [5].
ATAE-LSTM: It feeds aspect embedding together with word embedding into LSTM and uses the hidden states appended with aspect embedding to generate the attention weight vector [7].
IAN: Interactive attention network (IAN) [8] employs two separate LSTMs to treat target words and context words equally, and uses the average-pooling of the hidden states to supervise the interactive attention weight vector.
GCAE: Gated convolutional network with aspect embedding (GCAE) [19] uses a convolutional filter to capture n-gram features and utilizes the gating units and max-pooling layer to extract sentiment feature.
CMA-MemNet: Multi-head self-attention memory network (CMA-MemNet) [30] uses a memory network to extract rich semantic information in sequences and combines a convolutional network with self-attention to make up for the grammatical information and the semantic information of the sequence itself ignored by memory network.
IGCN: Compared with other CNN-based network, IGCN [31] takes the separate modeling of targets into account and uses gate mechanism to learn their interaction. It also incorporates position information and POS information.
4.4. Results
As shown in Table 2, the proposed IAC-GRU model achieves the best performance compared with baseline models on both Restaurants and Laptop datasets. TD-LSTM performs the worst, although it utilizes the standard LSTM to capture target-dependent feature information in preceding and following context. It still doesn’t pay enough attention to the target information. ATAE-LSTM obtains better performance than TD-LSTM, as it employs attention mechanism to enforce the model to show solicitude for the most target-relevant information in a given sentence. IAN uses an interactive attention network to capture the interaction between aspect and context words, thus it performs better than TD-LSTM and ATAE-LSTM. CGAE introduces a convolutional network and gate mechanism to gain n-gram aspect-relevant features at multi-granularity. Therefore, its performance is reasonably superior than previous LSTM-based models. CMA-MemNet simultaneously uses CNN and memory network to learn the rich semantic features as well as the syntactic features related to targets. CMA-MemNet has made competitive improvement than CGAE. IGCN has the similar performance as CMA-MemNet on Restaurants datasets due to its independent modeling of targets and interactive learning, but it obtains higher accuracy than CMA-MemNet on Laptop datasets. IAC-GRU feeds position and POS information as auxiliary information together with word embedding into Bi-GRU which has similar performance and simpler structure compared with LSTM to obtain significant sequence feature. CNN is also applied to extract high-level semantic features and integrate interactive attention networks. Hence IAC-GRU outperforms all baseline methods on Restaurants and Laptop datasets.
| Restaurant | Laptop | |
|---|---|---|
| TD-LSTM [22] | 75.63 | 68.13 |
| ATAE-LSTM [7] | 77.2 | 68.7 |
| IAN [8] | 78.60 | 72.10 |
| CGAE [19] | 77.28 | 69.14 |
| CMA-MemNet [30] | 81.26 | 73.24 |
| IGCN [31] | 81.34 | 75.24 |
| IAC-GRUw/o position | 80.63 | 73.20 |
| IAC-GRUw/o POS | 81.24 | 73.69 |
| IA-GRU | 81.07 | 75.01 |
| IAC-GRU | 82.32 | 76.02 |
Experimental results for aspect-level sentiment analysis
4.5. Case Study
We visualize the attention weight in several samples as Figure 2. The details of samples are indicated in Table 3. We randomly select two sentences from the Restaurants test dataset which contains a single and multiple aspect terms, respectively. In the first example, the neighboring words of the target “people” do not contain corresponding sentiment words. Even so, the model still pays attention to the negative words “never” and the verb “disappoints” that describes target “people”. This approves that our IAC-GRU model can capture the context words which play a vital role in inferring the sentiment polarity. In Case 2, when aspect term is “waiter”, the affective word “friendly” which is close to each other gets higher attention score, while far away from each other such as “shame”, “supportive” gets less attention. This fully gives sufficient expression to the significance of position information. In view of the sentiment word “supportive”, the aspect term “staff” is easy to be judged as positive. Nevertheless, its real sentiment polarity needs to be obtained by combining the negator “didn’t” or the distant adjective “shame”. When the sentence contains multiple targets or negative words, our IAC-GRU model still obtains correct result. This means that IAC-GRU fully learns the internal representation of the aspect term and the interaction of word embedding and position and POS information between target and context words.

The attention scores proposed by our model. Deeper color marks higher attention score.
| Description | Text |
|---|---|
| Single target (case 1) | I trust the [people]positive at Go Sushi, it never disappoints. |
| Multi-targets (case 2) | Our [waiter]positive was friendly and it is a shame that he didn’t have a supportive [staff]negative to work with. |
Details of the samples
4.6. Ablation Study
To investigate the effectiveness of CNN, position information, and POS information, we compare IAC-GRU with three ablated models, namely, IA-GRU which only removes the CNN component, IAC-GRUw/o position which only removes the position embedding, and IAC-GRUw/o POS which only removes the POS embedding. The results are shown in Table 2. Obviously, IAC-GRUw/o position decreases by 1.69% and 2.82% on Restaurants and Laptop datasets, which indicates that the position information incorporated in the model will make the words close to aspect get higher weight as the auxiliary information of filtering classification. The performance of IAC-GRUw/o POS drops 1.08% and 2.33% compared with the complete model, which indicates that words marked as different POS categories will be treated differently during model training. IA-GRU only uses Bi-GRU to extract sequence information and ignores context information besides word level. Hence, its performance is inferior to the complete model. In summary, IAC-GRU outperforms three ablated models, which reconfirms that the three critical components have significant impact on performance.
5. CONCLUSIONS
In this paper, we proposed an interactive attention-based convolutional GRU for aspect-level sentiment analysis (IAC-GRU). IAC-GRU incorporates the position and POS information into word embedding and uses Bi-GRU and CNN to capture the sequence feature and the high-level local and global features simultaneously. Additionally, we constructed an interactive attention network to treat the target and context words equally and model the mutual interaction. The experimental results on SemEval2014 datasets (i.e., Restaurants and Laptop datasets) demonstrated the effectiveness of the proposed IAC-GRU model. Finally, we designed three ablation study with CNN, position embedding, and POS embedding as the unique variable. The descending performance demonstrated the effectiveness of the three critical components.
Finally, in this paper, we mainly focus on the performance of position information and POS information in this task, while the interaction between aspects is not explicitly considered. In the future, we will explore the interaction between multiple aspects and introduce more efficient and concise pre-trained models such as BERT to improve our task performance.
CONFLICTS OF INTEREST
The authors declare they have no conflicts of interest.
AUTHORS’ CONTRIBUTION
Lisha Chen contributed in methodology, software, validation and writing. Tianrui Li, Huaishao Luo and Chengfeng Yin contributed in review & editing.
ACKNOWLEDGMENT
This work was supported by the Key R & D Project of Sichuan Province, China (No. 2020YFG0035).
REFERENCES
Cite this article
TY - JOUR AU - Lisha Chen AU - Tianrui Li AU - Huaishao Luo AU - Chengfeng Yin PY - 2021 DA - 2021/07/20 TI - Interactive Attention-Based Convolutional GRU for Aspect Level Sentiment Analysis JO - Human-Centric Intelligent Systems SP - 25 EP - 31 VL - 1 IS - 1-2 SN - 2667-1336 UR - https://doi.org/10.2991/hcis.k.210704.002 DO - 10.2991/hcis.k.210704.002 ID - Chen2021 ER -