
Results on Cumulative Measure of Inaccuracy in Record Values
- DOI
- 10.2991/jsta.2018.17.1.2How to use a DOI?
- Keywords
- Measure of inaccuracy; Cumulative inaccuracy; Record values
- Abstract
In this paper, we propose cumulative measure of inaccuracy in lower record values and study characterization results in case of dynamic cumulative inaccuracy. We also discuss some properties of the proposed measures. Finally, we study a problem of estimating the cumulative measure of inaccuracy by means of the empirical cumulative inaccuracy in lower record values.
- Copyright
- Copyright © 2018, the Authors. Published by Atlantis Press.
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
Let X and Y be two non-negative random variables with distribution functions F(x), G(x) and reliability functions
2. Cumulative measure of inaccuracy
The cumulative measure of inaccuracy between FLn (distribution function of nth lower record value Ln) and F is presented as
In the following, we present some examples and properties of I(FLn, F).
Example 2.1.
- i.
If X has a inverse Weibull distribution with the cdf
Figure 1 shows the function I(FLn, F) for α = β = 2. It is an increasing function of n.
- ii.
If X is uniformly distributed in [0, θ]. Then, we obtain
From Figure 1 it is clear that I(FLn, F) for standard uniform distribution is increasing function of n and limn→∞ I(FLn, F) = 2θ.
- iii.
If X is exponentially distributed with mean
From Figure 1 it is clear that I(FLn, F) for exponential distribution with mean
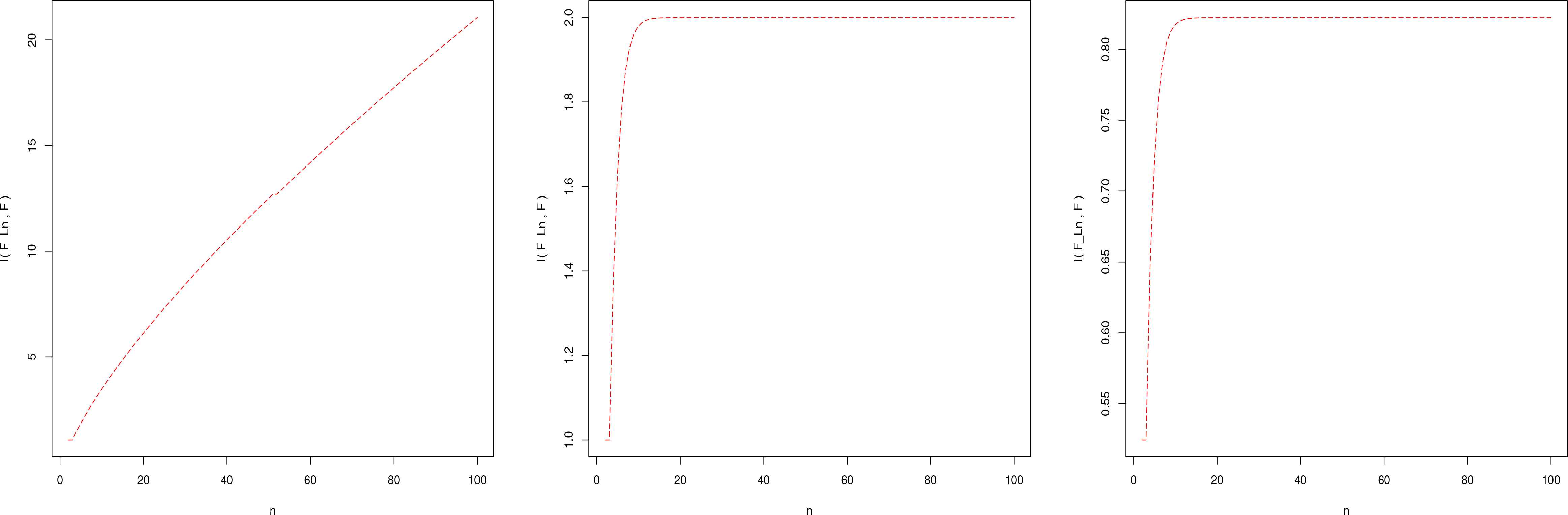
Plot of I(FLn, F) in inverse Weibull distribution for α = β = 2 (left), uniform distribution on (0, 1) (middle) and exponential distribution with λ = 2(right).
Proposition 2.1.
Suppose that X is a non-negative random variable with cdf F, then we have
Proposition 2.2.
Let X be a non-negative random variable with cdf F, then we have
Proof.
By (2.1) and the relation
Proposition 2.3.
Let X be a non-negative random variable with cdf F, then an analytical expression for I(FLn, F) is given by
Proposition 2.4.
Let a, b > 0 for n = 1, 2, .... It holds that
Proof.
From (2.3) , we have
The proof is completed.
Proposition 2.5.
Let X be a absolutely continue non-negative random variable with I(FLn, F) < ∞, for all n ≥ 1. Then we have
Proof.
By using (2.1) and Fubini’s theorem we obtain
Remark 2.1.
Let X be a symmetric random variable with respect to the finite mean µ = E(X), i.e. F(x + µ) = 1 − F(µ − x) for all x ∈ ℝ. Then
Kayal (2016) defined the MIT of lower record values as
Proposition 2.6.
Let X be a non-negative random variable with cdf F, then we have
Proof.
From (2.2) we have
Proposition 2.7.
Suppose that X is a non-negative random variable with cdf F, then we have
Proof.
By using (1.4) and (2.2) we obtain
Remark 2.2.
Let X be a non-negative random variable with cdf F and Xi+1 be the (i + 1) th lower record with pdf fLi+1(x). Then for n ≥ 1, we have
Proof.
The proof follows from Proposition 2.7.
Remark 2.3.
In analogy with (2.1) , a measure of cumulative past inaccuracy associated with F and FLn is given by
In the sequel we obtain upper bound of I(F, FLn).
Proposition 2.8.
Let X be a non-negative random variable that take values in [0, a]. Then,
Proof.
The proof follows from Proposition 1.9 of Ghosh and Kundu(2017) with the help of log-sum inequality.
In the next propositions we recall some lower bounds for I(FLn, F).
Proposition 2.9.
If X denotes an absolutely continue non-negative random variable with mean µ = EX < ∞. Then for n ≥ 1, we have
Proof.
From (2.3) we have
Proposition 2.10.
Let X be a non-negative random variable with cdf F, then we have
Proof.
Since (F(x))n ≤ F(x), for all n = 1, 2, ..., we have
Remark 2.4.
Let X be a non-negative random variable with cdf F, then for n = 1, 2, ... we have
Proof.
By using Proposition 4.3 of Dicresenzo and Longobardi (2009) a lower bound for 𝒞ℰ(X) is
Proposition 2.11.
For a non-negative random variable and n = 1, 2, ..., we have
Proof.
From Proposition 5.1 of Wang (1998), we have
Corollary 2.1.
Let X be a non-negative random variable with survival function
Proof.
The proof follows by recalling (2.9) and Proposition 4.2 of Di Crescenzo and Longobardi (2009).
Now we can prove an important property of inaccuracy measure using some properties of stochastic ordering. For that we present the following definitions:
- 1.
The random variable X is said to be smaller than Y according to stochastically ordering (denoted by X ≤st Y) if P(X ≥ x) ≤ P(Y ≥ x) for all x. It is known that X ≤st Y ⇔ E(ϕ(X)) ≤ E(ϕ(Y)) for all increasing functions ϕ such that the expectations exist.
- 2.
The random variable X is said to be smaller than Y in likelihood ratio ordering(denoted by X ≤lr Y) if
- 3.
A random variable X is said to be smaller than a random variable Y in the decreasing convex order, denoted by X ≤dcx Y, if E(ϕ(X)) ≤ E(ϕ(Y)) for all decreasing convex functions ϕ such that the expectations exist.
- 4.
A non-negative random variable X is said to have decreasing reversed hazard rate DRHR if
Theorem 2.1.
Suppose that the non-negative random variable X is DRHR, then
Proof.
Let fLn(x) be the pdf of n-th lower record value XLn. Then, the ratio
Theorem 2.2.
Let X and Y be two non-negative random variables such that X ≤dcx Y, then we have
Proof.
Since
Proposition 2.12.
Let X be a non-negative random variable with absolutely continuous cumulative distribution function F(x). Then for n = 1, 2, ... we have
Proof.
Since −logF(x) ≥ 1 − F(x), the proof follows by recalling (2.1) .
Proposition 2.13.
Let X be a non-negative random variable with absolutely continuous cumulative distribution function F(x). Then for n = 1, 2, ... we have
Assume that
Proposition 2.14.
If θ ≥ (≤)1, then for any n = 1, 2, ... we have
Proof.
Suppose that θ ≥ (≤)1, then it is clear [F(x)]θ ≤ (≥)F(x), and hence we have
3. Dynamic cumulative measure of inaccuracy
In the reliability theory dynamical measures are useful to describe the information content carried by random lifetimes as age varies. In this section, we study dynamic version of I(FLn, F). If a system that begins to work at time 0 is observed only at deterministic inspection times, and is found to be down at time t, then we consider a dynamic cumulative measure of inaccuracy as
Note that
Theorem 3.1.
Let X be a nonnegative continuous random variable with distribution function F(.). Let the dynamic cumulative inaccuracy of the nth lower record value denoted by I(FLn, F;t) < ∞, t ≥ 0. Then I(FLn, F;t) characterizes the distribution function.
Proof.
From (3.1) we have
Then for all t, from (3.3) we get
4. Empirical cumulative measure of inaccuracy
In this section we study the problem of estimating the cumulative measure of inaccuracy by means of the empirical cumulative inaccuracy in lower record values. Let X1, X2, ..., Xm be a random sample of size m from an absolutely continuous cumulative distribution function F(x). Then according to (2.3), the empirical cumulative measure of inaccuracy is defined as
Example 4.1.
Let X1, X2, ..., Xm be a random sample drawn from exponential distribution with mean
| E[Î(FLn, F)] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| α | 0.5 | 1 | 2 | 0.5 | 1 | 2 | 0.5 | 1 | 2 | 0.5 | 1 | 2 |
| m | n = 2 | n = 3 | n = 4 | n = 5 | ||||||||
| 10 | 1.96 | 0.980 | 0.490 | 2.395 | 1.197 | 0.598 | 2.614 | 1.307 | 0.653 | 2.711 | 1.355 | 0.677 |
| 15 | 2.011 | 1.005 | 0.502 | 2.471 | 1.235 | 0.617 | 2.716 | 1.358 | 0.679 | 2.834 | 1.417 | 0.708 |
| 20 | 2.035 | 1.017 | 0.508 | 2.506 | 1.253 | 0.626 | 2.765 | 1.382 | 0.691 | 2.896 | 1.448 | 0.724 |
| Var[Î(FLn, F)] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| α | 0.5 | 1 | 2 | 0.5 | 1 | 2 | 0.5 | 1 | 2 | 0.5 | 1 | 2 |
| m | n = 2 | n = 3 | n = 4 | n = 5 | ||||||||
| 10 | 0.252 | 0.063 | 0.015 | 0.291 | 0.072 | 0.018 | 0.306 | 0.076 | 0.0191 | 0.310 | 0.077 | 0.0194 |
| 15 | 0.173 | 0.043 | 0.010 | 0.201 | 0.050 | 0.012 | 0.214 | 0.053 | 0.013 | 0.219 | 0.054 | 0.013 |
| 20 | 0.131 | 0.032 | 0.008 | 0.153 | 0.038 | 0.009 | 0.164 | 0.041 | 0.010 | 0.168 | 0.042 | 0.0105 |
Numerical values of E[Î(FLn, F)] and Var[Î(FLn, F)] for exponential distribution.
| E[Î(FLn, F)] | var[Î(FLn, F)] | |||||||
|---|---|---|---|---|---|---|---|---|
| m | n=2 | n=3 | n=4 | n=5 | n=2 | n=3 | n=4 | n=5 |
| 10 | 0.437 | 0.581 | 0.660 | 0.697 | 0.014 | 0.019 | 0.021 | 0.022 |
| 15 | 0.459 | 0.619 | 0.713 | 0.760 | 0.010 | 0.014 | 0.016 | 0.017 |
| 20 | 0.470 | 0.637 | 0.739 | 0.794 | 0.007 | 0.011 | 0.013 | 0.014 |
Numerical values of E[Î(FLn, F)] and Var[Î(FLn, F)] for uniform distribution.
Example 4.2.
Let X1, X2, ..., Xm be a random sample from a population uniformly distributed in (0, 1). Then the sample spacings Uk+1 are independent of beta distribution with parameters 1 and m (for more details see Pyke (1965)). Now from (4.3) we obtain
Conclusions
In this paper, we discussed on concept of inaccuracy between FLn and F. We proposed a dynamic version of cumulative inaccuracy and studied characterization results of it. It is also proved that I(FLn, F;t) can uniquely determine the parent distribution F. Moreover, we studied some new basic properties of I(FLn, F) and I(FLn, F;t) such as the stochastic order properties. We also constructed bounds for characterization results of I(FLn, F). Finally, we estimated the cumulative measure of inaccuracy by means of the empirical cumulative inaccuracy in lower record values. These concepts can be applied in measuring the inaccuracy contained in the associated past lifetime.
References
Cite this article
TY - JOUR AU - Saeid Tahmasebi AU - Ahmad Nezakati AU - Safeih Daneshi PY - 2018 DA - 2018/03/31 TI - Results on Cumulative Measure of Inaccuracy in Record Values JO - Journal of Statistical Theory and Applications SP - 15 EP - 28 VL - 17 IS - 1 SN - 2214-1766 UR - https://doi.org/10.2991/jsta.2018.17.1.2 DO - 10.2991/jsta.2018.17.1.2 ID - Tahmasebi2018 ER -