
CPP-ELM: Cryptographically Privacy-Preserving Extreme Learning Machine for Cloud Systems
TÜBİTAK - BİLGEM Cyber Security Institute, Kocaeli, Turkey
- DOI
- 10.2991/ijcis.11.1.3How to use a DOI?
- Keywords
- Extreme learning machine; Privacy-preserving machine learning; Homomorphic encryption
- Abstract
The training techniques of the distributed machine learning approach replace the traditional methods with a cloud computing infrastructure and provide flexible computing services to clients. Moreover, machine learning-based classification methods are used in many diverse applications such as medical predictions, speech/face recognition, and financial applications. Most of the application areas require security and confidentiality for both the data and the classifier model. In order to prevent the risk of confidential data disclosure while outsourcing the data analysis, we propose a privacy-preserving protocol approach for the extreme learning machine algorithm and give private classification protocols. The proposed protocols compute the hidden layer output matrix H in an encrypted form by using a distributed multi-party computation (or cloud computing model) approach. This paper shows how to build a privacy-preserving classification model from encrypted data.
- Copyright
- © 2018, the Authors. Published by Atlantis Press.
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
Classification algorithms are used for predicting the label of new instances by a classifier model that is built using correctly identified input observations. In order to achieve high performance results for accurate classification, the classification algorithm needs a large number of valid input instances.
Today, many organizations such as financial and medical institutions produce large-scale data sets. Machine learning-based data analysis tools are used by these organizations. The main problems with these data sets are privacy and security concerns. All of these tools want full authority to access private and confidential data to build a supervised or unsupervised model.
Even though various anonymization techniques are applied to confidential data sets to protect privacy, the confidential data itself can be still retrieved by an adversary via various method 15. Imagine a scenario in which two or more institutions want to build a classification model 19 by combining each other’s confidential dataset. In such a case, it is crucial to find a new privacy-based training method for classification algorithms that can run together on multiple confidential data sets without retrieving the private data.
In machine learning, a classification algorithm basically consists of two sequential steps: model building and labeling of new instances. The model building phase of a classification algorithm creates a classifier hypothesis, h, from the correctly labeled input data set 𝒟. In the phase of labeling new instances, the classifier hypothesis h predicts the label of unseen input instances 𝒳. The traditional classifier algorithms require direct access to data, which poses security and privacy risks as mentioned above.
Extreme learning machines (ELMs) were recently introduced as a probabilistic neural network learning algorithm, proposed by Huang et al. 3 based on generalized single-hidden layer feed-forward networks (SLFNs). The major properties of the ELM method are the high generalization property of multi-class labeling of unseen input instances, small model building time in comparison to the traditional gradient-based learning methods, and being parameter-free with randomly generated hidden layer nodes.
In this research, we propose a privacy-preserving ELM classification model building method based on a Paillier cryptosystem22 that constructs the global neural network classification model from encrypted and partitioned data sets from different sites. The labeled input data set is vertically partitioned and distributed among the different sites, and then the intermediate computation results of each party are aggregated by an independent trusted party (or at the client-side of the computation) to privately build a classification model that is used for predicting the correct label.
The contributions of our paper are as follows:
- •
The Paillier cryptosystem encryption-based ELM training model is proposed for learning and thus private classification model training is achieved.
- •
The computation of the hidden layer output matrix of the probabilistic neural network model is distributed to independent sites, thus minimizing the data communication.
Our paper is organized as follows: in Section 2, we briefly introduce some of the related works for privacy-preserving training. In Section 3, we describe the ELM, homomorphic encryption, the Paillier cryptosystem, and the arbitrary data partitioning technique. In Section 4, we describe the proposed secure multi-party training and model building method. Section 5 evaluates our proposed training and classification model. Section 6 concludes the paper.
2. Related Works
In this section, we review the existing works that have been developed for different security and privacy-preserving machine learning methods. We highlight detailed differences between our proposed learning model and the existing works. Encryption methods can be employed to address the security and privacy concerns in machine learning 16,17.
Recently, numerous significant privacy-preserving machine learning models have been proposed. Secretans et al. 26 proposed a new probabilistic neural network (PNN) training model. In their proposed method, the PNN is built with an approximation to the optimal classifier. The theoretically optimal classifier is known as the Bayesian optimal classifier. Their proposed method needs at least three sites to be involved in the computation of the secure matrix summation. The secure matrix is used for adding the partial class conditional probability vectors.
Aggarwal et al. 1 proposed a new condensation-based training method. In their paper, it was shown that the anonymized data closely matched the characteristics of the original data. Their proposed approach produces disclosable data that satisfy privacy concerns by providing utility for data analysis. Each instance in the data is randomized while a few statistical properties of these instances are kept.
Graepel et al. 8 implemented two binary classification algorithms for homomorphically encrypted data: linear means and Fisher’s linear discriminant. They make scaling adjustments that preserve the results, but leave the fundamental methodology unchanged.
Samet et al. 25 proposed new privacy-preserving algorithms for both back-propagation training and ELM classification between several sites. Their proposed algorithms are applied to the perceptron learning algorithm and presented for only single-layer models.
Bost et al. 4 developed a two-party computation framework and used a mix of different partially and fully homomorphic encryption schemes, which allowed them to use machine learning techniques based on hyperplane decisions, naive Bayes, and binary decision trees. The fundamental methodologies are still unchanged, but substantial communication between two “honest, but curious” parties is required.
Oliveria et al. 20 developed techniques for distorting private numerical attributes to protect confidentiality for clustering analysis methods. Their approach transforms data by using several different types of geometric transformations such as translation, rotation, and scaling while keeping the Euclidean distance.
Guang et al. 9 developed a new training method for a privacy-preserving back-propagation algorithm using horizontally partitioned data sets for a multisite learning case. Their approach uses homomorphic encryption-based secure summation in its protocols.
Yu et al. 33 developed a new privacy-preserving training method for a support vector machine (SVM) classification algorithm. Their protocols build the global SVM classifier hypothesis from the distributed data at multiple sites, without retrieving or pooling the data of each site with others. Homomorphic encryption-based secure multi-party integer sums are applied in their protocols to compute the Gram matrix of the SVM algorithm formulation in a distributed manner from the encrypted partitioned data held by several different sites.
Yang et al. 31 proposed a privacy-preserving schema using homomorphic encryption in image processing. A secret key homomorphic encryption was constructed for encrypting image. Then the encrypted image can be processed homomorphically.
Tso et al. 29 proposed a new practical approach to prevent data disclosure from inside attack. Their approach is based on FairplayMP framework which enables programmers who are not experts in the theory of secure computation to implement such protocols. The method supports privacy-preserving machine learning for medical data stored in parties.
3. Preliminaries
In this section, we briefly introduce preliminary information about the ELM, homomorphic encryption, the Paillier cryptosystem, secure multi-party computation, and arbitrarily partitioned data.
3.1. Extreme Learning Machine
As mentioned before, a probabilistic neural network-based ELM classification algorithm was proposed for single-layer feed-forward neural networks 3,12,14,6. Later, the ELM algorithm was expanded to a new model of generalized single-layer feed-forward networks. In this model, the hidden layer of the ELM may not be a neuron like in previous papers 10,11. The first advantage of the ELM classification algorithm is its training time performance. The training phase of the ELM algorithm can be a hundred times faster than the standard SVM algorithm or the classical neural network algorithm. The reason for this rapid model building is that its hidden node biases vectors and input weight vectors are arbitrarily generated, and then the output layer weights of the model can be calculated by using a least-squares method 28,13. As a result, the most appreciable property of the ELM training phase is based on the creation of probabilistic hidden layer parameters for performance issues.
Let us give a set of input instances 𝒟 = {(xi,yi) | i = 1, ⋯, n}, xi ∈ ℝp, yi {1,2, ⋯ , K}} from some unknown distribution 𝒳; they are sampled independently and identically distributed (i.i.d.). The main objective of a neural network model is to find a hypothesis h : 𝒳 → 𝒴 where 𝒳 is the input instances and 𝒴 is the set of all possible outcomes. The outcome of a single-layer feed-forward neural network with N hidden nodes in an n-dimensional vector space can be shown as:
The output function of the ELM algorithm for generalized SLFNs can be identified by:
For binary classification problems, the decision function of the ELM model becomes:
We can rewrite Eq. 2 in another form, as shown in Eq. 4:
The hidden nodes of the ELM can be arbitrarily created and they can be independent from the input data set.
3.2. Homomorphic Encryption
Homomorphic encryption schemes enable operations on plaintexts to be performed on their respective ciphertexts without revealing the plaintexts when data are divided between two or more parties as it facilitates computations with ciphertexts. One can say that a public-key encryption scheme is additively homomorphic if, given two encrypted messages such as ⟦a⟧ and ⟦b⟧ there exists a public-key summation operation such that ⟦a⟧ ⊕ ⟦b⟧ is an encryption of the plaintext of a + b. The formal definition is that an encryption scheme is additively homomorphic if for any private key, public key (sk, pk), the plaintext space 𝒫 = ℤN for a,b ℝN.
3.2.1. Paillier’s Encryption Scheme
The Paillier cryptosystem22 is a probabilistic and asymmetric encryption algorithm. The Paillier cryptosystem is based on the problem of deciding whether a given number is an nth residue modulo n2 where n is the product of two large primes21. The problem of computing the nth residue classes is believed to be computationally hard.
Let us give a set of possible plaintext messages M and a set of secret and public key pairs K = pk × sk, where pk is the public key and sk is the secret key of the cryptosytem. Then the Paillier homomorphic encryption cryptosystem satisfies the following property of any two plaintext messages m1 and m2 and a constant value a:
One of the main properties of the Paillier cryptosystem is that it is based on a probabilistic encryption algorithm. Large-scale data sets are sparse matrices in which most of the elements are zero. In order to prevent the guessing of elements of the input data set, the Paillier cryptosystem has probabilistic encryption that does not encrypt two equal plaintexts with the same encryption key into the same cipher-text.
3.3. Arbitrarily Partitioned Data
In this work, arbitrarily partitioned data exist between multplei sites (K), where K > 2 is considered. In the arbitrarily partitioned data scheme, there is not any specific order of how the data set is split between the multiple sites. More specifically, let us give a data set X = {x1
, ⋯ xn}, consisting of n instances, and each instance in X contains m numeric features
4. Cryptographically Privacy-Preserving ELM (CPP-ELM)
In this section, we briefly introduce our assumptions in the security model, our notations, and the sequence diagram of the overall method. In Section 4.6, we explain our proposed privacy-preserving training of the ELM algorithm in detail.
4.1. Security Model
In this paper, the aim is to enable multiple parties (or servers) to cooperatively build the ELM classification model without retrieving their own confidential input data set. Our main assumption is that the input data set is divided between two or more parties that are willing to train an ELM classifier if nothing beyond the expected end results is revealed 2. Our other assumption is that all parties follow the protocol; this is called a semi-honest security model 18,32.
4.2. Notations
The input instance x of data set 𝒳 is shown in the form of x = {x1, ⋯·xn}. In this work, two or more parties that hold vertically partitioned data are considered.
- •
Boldface lowercase letters denote the vectors (e.g., x).
- •
⟦m⟧ denotes the ciphertext of a message m.
- •
sign(m) denotes the sign of the plaintext number m.
- •
⊕ denotes encrypted addition and ⊗ denotes encrypted multiplication with the public-key operation.
4.3. Floating Point Numbers
The Paillier encryption scheme operates only on integer numbers. Thus, the proposed protocols manipulate only integers. However, the ELM classification algorithm is typically applied to continuous data. Nonetheless, in the case of an input data set with real numbers in the protocol, we need to map floating point input data vectors into the discrete domain with a conversion function (i.e. scaling).
Let ConvertToInteger : ℝm → ℤm be the corresponding function that multiplies its floating point number argument by an exponent (K : 2K) and then rounds them to the nearest integer value and thus supports finite precision. Eq. 11 shows the conversion function:
4.4. Vertically Partitioned Data
The input data set that is used for finding an ELM-based classifier consists of m rows in n-dimensional vector space shown with 𝒟 ∈ ℝm×n. Input matrix 𝒟 is arbitrarily and vertically partitioned into k different sites of P0, P1, ⋯ , Pk and each attribute of rows is owned by a private site as depicted in Fig. 1. As denoted in Eq. 6, in the second phase of the ELM training, hidden layer output matrix H is computed using randomly generated hidden node parameters w, b, and β. The ELM training phase then computes the output weight vector, β, by multiplying H and T. Each element of matrix H is computed with activation function g. The global G matrix is such that G(wi,xi,bi) = g(xi · wi + bi) for sigmoid or G(wi,xi,bi) = g(bi − ||xi − wi||) for radial-based functions. The (i, j)th element of H is:

Vertically Partitioned Data Set 𝒟.
Let
From Eq. 13, the computation of the hidden layer output matrix H can be distributed into k different parties by using the secure sum of matrices, such that:
4.5. Sequence Diagram of Overall Method
In this section, we present the conceptual level of the CPP-ELM. We define the converting of the flow of messages into the flow of methods. In the sequence diagram, we use the following notation for the actions executed by an actor when receiving a signal:
- •
M: Method invocation.
- •
:User, :ClientApp, :CloudApp: Actors
The CPP-ELM is composed of four steps, as shown in Fig. 2 - 3:
- •
Client initialization
- •
Information sharing
- •
Hidden layer output matrix computation
- •
Classifier model building
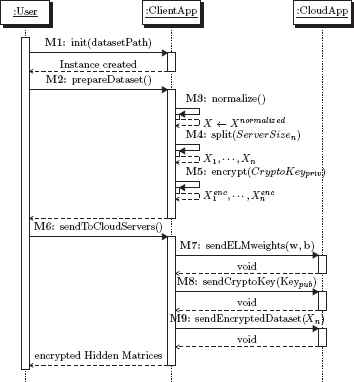
Sequence diagram of overall method: Client computation.
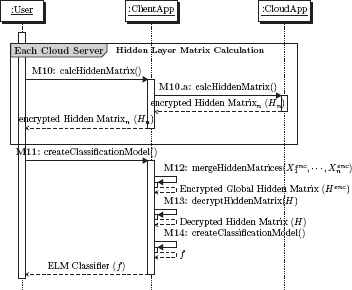
Sequence diagram of overall method: server computation.
4.6. Privacy-Preserving ELM Algorithm
In this section, a cloud-based privacy-preserving multi-party CPP-ELM learning algorithm over arbitrarily partitioned data is presented.
4.6.1. Client Initialization
In the client initialization phase of the proposed method, first the client normalizes the input data set 𝒟 = {(x,y)|x ℝn,y ℝ}. Let xmin and xmax be an input data set of minimum and maximum values of each corresponding feature. Hence, the normalized data set can be written as:
Next, the client splits the whole data set 𝒟 based on the server size of the cloud systems and then it encrypts each element of the input data set 𝒟 individually by using its public-key through the Paillier cryptosystem as shown in Eq. 17:
Algorithm 1 shows the overall process in the initialization phase.

Client Initialization.
4.6.2. Information Sharing
In the second phase of the CPP-ELM, first the client sends the encrypted sub-data set ⟦𝒟i⟧ to each party Pi.
Second, the client generates public and secret keys, as described in Algorithm 1: the client generates and assigns random weights w ℝn and b ℝn, and then sends the weight vectors’ corresponding items to each Pk. Algorithm 2 shows the overall process.

Information Sharing
4.6.3. Hidden Layer Output Matrix Computation
The encrypted sub-data sets ⟦ 𝒟 ⟧ of each server and weight vectors w,b are used for computing the encrypted hidden layer output matrix for each data chunk ⟦ Hi ⟧, ∀i ∈ k. The computed ⟦Hi⟧ is sent to the client. Considering a case where a party k = 1, we have:
The party (server) knows the plaintext weight vectors w,b. It can perform the required multiplication and additions with its own encrypted sub-data set ⟦𝒟i⟧ by performing dot multiplication of each row with w and addition of b.
Algorithm 3 shows the calculation of the hidden layer output matrix for each server in the encrypted domain.

Hidden Layer Output Matrix Calculation.
4.6.4. Classifier Model Building
The client can now compute the last step given in Fig. 3, i.e. compute the value of the ELM-based classifier function in the private domain. First, the client decrypts each encrypted hidden layer output matrix ⟦Hi⟧ received from each party by using its own private key and then computes the global hidden layer output matrix H. The smallest norm least-squares solution of the linear system5 is:
Algorithm 4 shows the classifier model building in the decrypted domain.

Classification Model Building.
5. Experiments
5.1. Experimental Setup
We have implemented our proposed protocols and the classifier training phase in Python by using the scikit-learn library for machine learning and the PyPhe library for the partially homomorphic encryption implementation.
To show the training phase time performance of the proposed protocols, we tested different public data sets with parties and encryption/decryption keys that have different lengths. For the experiments, we consider four different data sets from the UCI Machine Learning Repository called Australian, Breast Cancer, Ionosphere, and Sonar. Table 5.1 shows the details of the data sets.
| Data Set | Sample | Class | Attributes |
|---|---|---|---|
| Ionosphere | 351 | 2 | 34 |
| Sonar | 208 | 2 | 60 |
| Breast Cancer | 683 | 2 | 10 |
| Australian | 690 | 2 | 14 |
Details of Data Sets Used in Experiments.
Each data set is arbitrarily vertically partitioned among each party (K ∈ {2,3,5,7,10}), and then the results in the encrypted-domain are compared with the results of the plain-domain. In plain-domain training, the conventional ELM training phase is performed for all data sets in a single pass. All experiments are repeated 5 times and the results are averaged. All data sets are publicly available in SVM-light format on the LIBSVM website.
The Ionosphere data set consists of a phased array of 16 high-frequency antennas with a total transmitted power on the order of 6.4 kilowatts. “Good” radar returns are those showing evidence of some type of structure in the ionosphere. “Bad” returns are those that do not; their signals pass through the ionosphere 27. The data set contains 351 training instances.
The Sonar data set is used for the study of the classification of sonar signals using a neural network. The task is to train a network to discriminate between sonar signals bounced off a metal cylinder and those bounced off a roughly cylindrical rock 7. The data set contains 208 training instances.
The Breast Cancer data set contains 699 instances, with 458 benign (65.5%) and 241 (34.5%) malignant cases. Each instance is described by 9 attributes with an integer value 30.
The Australian data set concerns credit card applications. The data set contains 690 instances and each instance is described by 14 attributes 23.
5.2. Experimental Results
Table 2 shows the best performance of the conventional ELM method of each experimental data set.
| Data Set | Accuracy |
|---|---|
| Ionosphere | 0.8613 |
| Sonar | 0.7293 |
| Breast Cancer | 0.9592 |
| Australian | 0.8438 |
Accuracy Results in the Plain-Domain for Each Data Set.
The proposed CPP-ELM training method has been implemented in Python 2.7 using the PyPhe library, version 1.0. Both the server and the clients are modeled as different process with the Python multiprocessing library. Each process sends the variables to each other via file exchange. The developed software is tested on a computer with 1.6 GHz Intel(R) is (R) processor and 4 GB of RAM running on a Windows 64-bit operating system. The system has been tested while varying the party size of each data set from 3 to 10, and with key lengths of 512 and 1024 bits. Performance results are shown in Table 3.
| Data | Key | Number of Parties | ||||
|---|---|---|---|---|---|---|
| 2 | 3 | 5 | 7 | 10 | ||
| Ion. | 512 | 7477,43 | 8280,77 | 9743,51 | 11481,17 | 12542,17 |
| 1024 | 39550,93 | 40020,45 | 45148,68 | 56751,82 | 82240,62 | |
| Sonar | 512 | 8345,99 | 7824,33 | 8621,37 | 10192,59 | 11047,74 |
| 1024 | 33775,32 | 30149,92 | 35418,41 | 38780,89 | 44357,66 | |
| Breast | 512 | 7681,71 | 9245,26 | 10630,49 | 13672,9 | 18651,20 |
| 1024 | 44035,76 | 48736,21 | 58554,61 | 72524,98 | 99986,21 | |
| Aust. | 512 | 8709,58 | 10463,64 | 11629,93 | 15406,08 | 17817,07 |
| 1024 | 39188,52 | 45621,76 | 52264,14 | 71074,53 | 79875,20 | |
Performance Results (in Seconds) for Each Data Set.
It is noted that the average training and model building time depends on the total number of instances used for classification. Fig. 4 shows the encryption time for each data set, which is affected by the number input instances and feature size. This process is computed at the client-side and can be pre-computed offline.
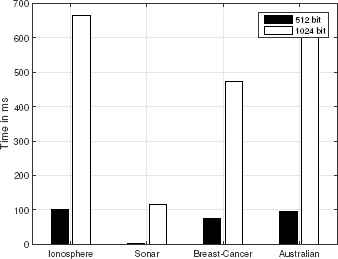
Encryption Costs for Different Data Sets.
In the proposed method, CPP-ELM, there are three different factors (party size, complexity of the input data set, and key bit length) that affect the computation time according to the experimental results.
As show in Fig. 5, when the number of parties varies from 3 to 10, then the overall hidden layer output matrix H computation stays relatively stable in the proposed model, at about 5 minutes to 8.5 minutes for 512-bit key length encryption and 20 minutes to 43 minutes for 1024-bit key length encryption.
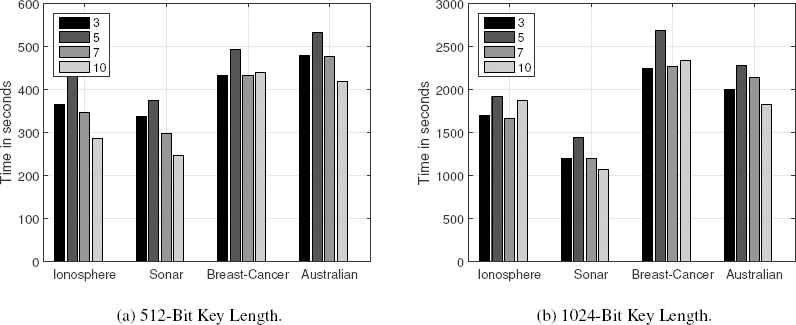
H Computation Time for Different Party Numbers and Data Sets.
In cryptographic systems, all computations work with integers. Thus, all real numbers used in our algorithms are mapped into finite fields by using a scaling procedure. Before starting the learning phase, the client converts the input data set to integer representation by multiplying and rounding the results. In the last stage, in Algorithm 4, the client scales down the hidden layer output matrix H. This scaling operation causes accuracy loss in the final classifier model. Table 4 shows the best performance of the CPP-ELM method for each experimental data set.
| Data Set | 512 Bits | 1024 Bits |
|---|---|---|
| Ionosphere | 0.7311 | 0.6598 |
| Sonar | 0.5976 | 0.5856 |
| Breast Cancer | 0.9433 | 0.9204 |
| Australian | 0.6877 | 0.6444 |
Accuracy Results in the Encrypted-Domain on Each Data Set.
6. Conclusion
In this work, we proposed a privacy-preserving and practical multi-party ELM learning scheme over arbitrarily vertically partitioned data between two or more parties. We have also provided cryptographically secure protocols for computing the hidden layer output matrix and have shown how to aggregate encrypted intermediate matrices securely. In our proposed approach, the client encrypts its input data, creates arbitrarily and vertically partitioned data, and then uploads the encrypted messages to a cloud system. The cloud system can execute the most time-consuming operation of ELM training without knowing any confidential information. One interesting future work is to extend the privacy-preserving training to other existing classification algorithms.
We suggest that the method proposed here is appropriate for areas such as healthcare where data privacy is highly sensitive. Data privacy is protected by transferring the identification information to the remote cloud service provider in an encrypted manner. Using the high computational power provided by the cloud service provider, the classification model is built on the encrypted data set. In this way, the cloud service provider can create a classification model without reaching plaintext data.
References
Cite this article
TY - JOUR AU - Ferhat Özgür Çatak AU - Ahmet Fatih Mustacoglu PY - 2018 DA - 2018/01/01 TI - CPP-ELM: Cryptographically Privacy-Preserving Extreme Learning Machine for Cloud Systems JO - International Journal of Computational Intelligence Systems SP - 33 EP - 44 VL - 11 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.11.1.3 DO - 10.2991/ijcis.11.1.3 ID - Çatak2018 ER -