
Communication-Efficient Distributed SGD with Error-Feedback, Revisited
 , Le Trieu Phong3,
, Le Trieu Phong3, - DOI
- 10.2991/ijcis.d.210412.001How to use a DOI?
- Keywords
- Optimizer; Distributed learning; SGD; Error-feedback; Deep neural networks
- Abstract
We show that the convergence proof of a recent algorithm called dist-EF-SGD for distributed stochastic gradient descent with communication efficiency using error-feedback of Zheng et al., Communication-efficient distributed blockwise momentum SGD with error-feedback, in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019 (NeurIPS 2019), 2019, pp. 11446–11456, is problematic mathematically. Concretely, the original error bound for arbitrary sequences of learning rate is unfortunately incorrect, leading to an invalidated upper bound in the convergence theorem for the algorithm. As evidences, we explicitly provide several counter-examples, for both convex and nonconvex cases, to show the incorrectness of the error bound. We fix the issue by providing a new error bound and its corresponding proof, leading to a new convergence theorem for the dist-EF-SGD algorithm, and therefore recovering its mathematical analysis.
- Copyright
- © 2021 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
1.1. Background
For training deep neural networks over large-scale and distributed datasets, distributed stochastic gradient descent (distributed SGD) is a vital method. In distributed SGD, a central server updates the model parameters using information transmitted from distributed workers, as illustrated in Figure 1.
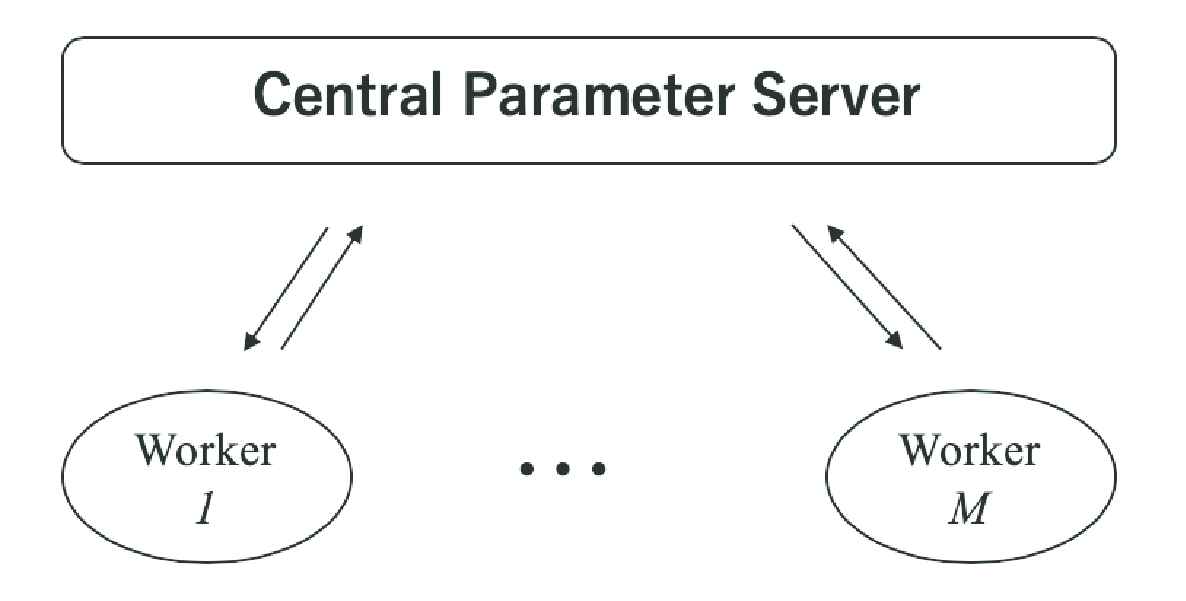
The computation model of distributed SGD. Multiple workers communicate with a central parameter server synchronously. Each worker, after local computations on its data, uploads selected results to the server. The server aggregates all uploaded results from the workers, and sends back the aggregated result from its computations to all workers. These are iterated for multiple rounds.
Communication between the server and distributed workers can be a bottleneck in distributed SGD. Alleviating the bottleneck is a considerable concern of the community, so that variants of distributed SGD using gradient compression have been proposed to reduce the communication cost between workers and the server.
Recently, Zheng et al. [1] proposed an algorithm named dist- EF-SGD recalled in Algorithm 1, in which gradients are compressed before transmission, and errors between real and compressed gradients in one step of the algorithm are re-used in future steps.
1.2. Our Contributions
In this paper, we point out a flaw in the convergence proof of Algorithm 1 given in Zheng et al. [1]. We then fix the flaw by providing a new convergence theorem with a new proof for Algorithm 1.
Zheng et al. [1] stated the following theorem for any sequence of learning rate {ηt}.
Theorem A
(Theorem 1 of [1], problematic). Suppose that Assumptions 1-3 (given together with related notations in Section 2) hold. Assume that the learning rate
Problem in Theorem A.
Unfortunately, the proof of Theorem A as given in [1] becomes invalidated when the learning rate sequence {ηt} is decreasing. In that proof, a lemma is employed to handle decreasing learning rate sequences. However, in Section 3 we present several counter-examples showing that lemma does not hold. We move on to fix that lemma and finally obtain the following result as our correction for Theorem A.
Theorem 1.
(Our correction for Theorem A) With all notations and assumptions are identical to Theorem A, we have
Algorithm 1 Distributed SGD with Error-Feedback (dist-EF-SGD) [1]
1: Input: Loss function
2: Initialize: initial parameter
3: for
4: • on each worker 1 ⩽ i ⩽ M:
5: pick data ξt,i from the dataset
6:
7:
8:
9:
10:
11:
12: • on central parameter server:
13: pull ∆t,i from each worker i
14:
15: push
16:
17: end for
such that the probability
In addition, we show that the upper bound in Theorem 1 becomes
1.3. Paper Roadmap
We begin with notations and settings in Section 2. In Section 3, we provide counter-examples to justify the issue in [1] for both nonconvex and convex cases. We then correct the issue in Section 4 and then present a proof for Theorem 1 in Section 5.
1.4. Related Works
The use of gradient compression for reducing the communication cost is widely considered in distributed machine learning recently. One line of research is to compress the gradient only on the worker side before sending the result to the parameter server, namely one-side compression. The parameter server receives and aggregates these results and sends back the aggregated result to all workers. Some recent papers such as [2–5] are in this line of research.
Another line of research uses gradient compression on both workers and server, namely two-side compression. In these two-side compression methods, the workers send the compressed local gradients or some corrected forms of them to the parameter server, and the parameter server compresses the aggregated result before sending it back to all workers. Papers [1,6,7] use two-side compression with an identical method of gradient compression for both workers and the parameter server. Paper [8] considers two-side compression with flexible compression for both workers and the parameter server.
2. PRELIMINARIES
Let
For completeness, we recall the algorithm of Zheng et al. [1] in Algorithm 1 and its explanation as follows. At iteration t, the scale
In order to construct Algorithm 1, Zheng et al. [1] used the idea of Karimireddy et al. [9] that combined gradient compression with error correction. The innovative ideas of Zheng et al. [1] were to apply compression on the parameter server and to use the scale
2.1. Compressor and Assumptions
Following [5,9], an operator
Given a loss function
Assumption 1.
f is lower-bounded, i.e., f* =
By [10], the L-smooth condition in (2) implies that
Assumption 2.
Let Et denote the expectation at iteration t. Then Et[gt,i] = ∇f(xt) and the stochastic gradient gt,i has bounded gradient, i.e.,
Assumption 3.
The full gradient ∇f is uniformly bounded, i.e.,
Under Assumptions 2 and 3, we have
2.2. Supporting Lemmas
We need a few supporting lemmas for proving Theorem 1.
Lemma 1.
Let
Proof.
Since
Applying the Cauchy–Schwarz inequality on
Therefore
Lemma 2.
Let {at}, {αt}, {βt} be non-negative sequences in ℝ such that a0 = 0 and, for all
Then
In particular, if βt = β for all t, then
Proof.
By (5), we have
Proving by induction, assume that then we have
3. THE ISSUE IN ZHENG ET AL. [1]
In order to prove the convergence theorem for Algorithm 1, Zheng et al. [1] have used the following lemma.
Lemma A
(Lemma 2 of [1], incorrect). For any
Intuitively, Lemma A can become incorrect because its right-hand side only depends on the gradient bound G and compressor parameter δ, and does not capture the scaling factor ηt−1/ηt of the errors
Claim 1.
Lemma A (i.e., Lemma 2 of [1]) does not hold. More precisely, referring to Algorithm 1, there exist a sequence of loss functions
Claim 1 is justified by the following counter-examples, in which we intentionally utilize the fact that the quotient ηt−1/ηt as in line 7 of Algorithm 1 can be large with decreasing learning rate sequences.
Counter-example 1.
(Convex case) For t ⩾ 0 and
Then at t = 1, Claim 1 holds true.
Proof.
(Justification of Counter-example 1) It is trivial that the loss function
The function
The last inequality is equivalent to
Therefore δ = 0.9 suffices.
To continue, let us consider the number of workers is M = 2. Initially e0,i = 0 on each worker i ∈ {1,2} and
At t = 0 we have the computations on the workers and the server as follows.
- –
On worker 1:
- –
On worker 2, p0,2 = p0,1, ∆0,2 = ∆0,1, and e1,2 = e1,1.
- –
On server:
- –
At t = 1 we have the computations on the workers and the server as follows:
- –
On worker 1:
- –
On worker 2: p1,2 = p1,1, ∆1,2 = ∆1,1, and e2,2 = e2,1.
- –
On server:
- –
Now we compute the left- and right-hand sides of (7) with t = 2.
Thus
Counter-example 2.
(Convex case) For t ⩾ 0 and xt,ξ ∈ ℝ, we consider the sequence of loss functions
Then at t = 1, Claim 1 holds true.
Proof.
(Justification of Counter-example 2) It is trivial that the loss function
At t = 0 we have the computations on the workers and the server as follows:
- –
On worker 1:
- –
On worker 2, p0,2 = p0,1, ∆0,2 = ∆0,1, and e1,2 = e1,1.
- –
On server:
- –
At t = 1 we have the computations on the workers and the server as follows:
- –
On worker 1:
- –
On worker 2, p1,2 = p1,1, ∆1,2 = ∆1,1, and e2,2 = e2,1.
- –
On server:
- –
Now we compute the left- and right-hand sides of (7) with t = 2. We have
Thus
Counter-example 3.
(nonconvex case) For t ⩾ 0,xt,ξ ∈ ℝ, we consider the sequence of loss functions
Then at t = 1, Claim 1 holds true.
Proof.
(Justification of Counter-example 3) First, we check that Assumptions 1-3 are satisfied.
The function ϕ is lower-bounded because 0 ⩽ ϕ(x) ⩽ 1, ∀x ∈ ℝ. The upper bound of ∇ϕ(x) is
The function ϕ is L-smooth, with L = 1. Indeed, for all
Since
This means that in order to prove
If x ⩾ y, we obtain ϕ(x) ⩾ ϕ(y). Therefore
Let φ(x) = ϕ(x)−x. Because
To continue, let us consider the number of workers M = 2. We initialize e0;i = 0 on each worker
At t = 0 we have the computations on the workers and the server as follows:
- –
On worker 1:
- –
On worker 2, p0,2 = p0,1, ∆0,2 = ∆0,1, and e1,2 = e1,1.
- –
On server:
- –
At t = 1 we have the computations on the workers and the server as follows.
- –
On worker 1:
- –
On worker 2, p1,2 = p1,1, ∆1,2 = ∆1,1, and e2,2 = e2,1.
- –
On server:
- –
Now we compute the left- and right-hand sides of (7) with t = 2. We have
Thus
4. CORRECTING THE ERROR BOUND OF ZHENG ET AL. [1]
In general, the error
Theorem 2.
(Fix for Lemma 2 of [1]) With
Remark 1.
[Sanity check of the new upper bound] The right-hand side of Theorem 2 can become large together with decreasing leaning rate sequences. Therefore, the error bounds of the sequences in counter-examples 1-3 do satisfy Theorem 2. Indeed, the upper bound on the error in Theorem 2 at t = 1 is
Concretely, at sanity check,
- which is indeed larger than
- which is indeed larger than
- which is indeed larger than
Proof.
[Proof of Theorem 2] We have
Moreover, since
By choosing
Therefore
Therefore
With
By applying Lemma 2 with
Since
Therefore,
Substituting (16) and (20) to (10), we obtain
As a sanity check, Theorem 2 matches the results given in [1] when the learning rate is nondecreasing. As a result, Theorems 1 and A agree when the learning rate is nondecreasing.
Corollary 1.
(Sanity check of Theorem 2, cf. Lemma 6 of [1] with μ = 0) In Theorem 2, if {ηt} is a nondecreasing sequence such that
Proof.
Since {ηt} is nondecreasing, we have
Replacing (21) and (22) to Theorem 2, we have the result stated in Corollary 1.
5. CORRECTING THE CONVERGENCE THEOREM OF ZHENG ET AL. [1]
Because the error bound plays a crucial role in the proof of the convergence theorem of dis-EF-SGD, fixing [1, Lemma 2] as in Theorem 2 leads to the consequence that the convergence theorem need to be fixed as well.
Proof.
(Proof of Theorem 1) Following [1], we consider the iteration
Since f is L-smooth, by (3), we have Moreover, we have
Moreover, we have
Following [1], we assume that
Substituting the above bound to (25) gives us
Moreover, we have
Taking
Since
Applying Theorem 2 gives us
Taking summation and dividing by
Following Zheng et al. [1], let o ∈ {0, …, T − 1} be an index such that
Then
The following corollary establishes the convergence rate
Corollary 2.
(Convergence rate with decreasing learning rate) Under the assumptions of Theorem 1, if
Proof.
Following [1], assume that
Therefore
Since
Moreover, we have
Substituting (32), (33), and (34) to (31) gives us
Because
By the same reason as in (36) and (37), we have
Moreover, we have
Furthermore, becauce
Therefore
6. CONCLUSION
We show that the convergence proof of dist-EF-SGD of Zheng et al. [1] is problematic when the sequence of learning rate is decreasing. We explicitly provide counter-examples with certain decreasing sequences of learning rate to show the issue in the proof of Zheng et al. [1]. We fix the issue by providing a new error bound and a new convergence theorem for the dist-EF-SGD algorithm, which helps recover its mathematical foundation.
CONFLICTS OF INTEREST
The authors declare that there are no conflicts of interest.
AUTHORS' CONTRIBUTIONS
Tran Thi Phuong established the research direction. Both authors contributed to the technical contents, and to the edition of the manuscript. Both authors read, revised, and approved the final manuscript.
ACKNOWLEDGMENTS
We are grateful to Shuai Zheng for his communication and verification. We also thank the anonymous reviewers for their careful comments. The work of Le Trieu Phong was supported in part by JST CREST under Grant JPMJCR19F6.
REFERENCES
Cite this article
TY - JOUR AU - Tran Thi Phuong AU - Le Trieu Phong PY - 2021 DA - 2021/04/20 TI - Communication-Efficient Distributed SGD with Error-Feedback, Revisited JO - International Journal of Computational Intelligence Systems SP - 1373 EP - 1387 VL - 14 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.210412.001 DO - 10.2991/ijcis.d.210412.001 ID - Phuong2021 ER -