
An Advanced Deep Residual Dense Network (DRDN) Approach for Image Super-Resolution
- DOI
- 10.2991/ijcis.d.191209.001How to use a DOI?
- Keywords
- Deep residual dense network (DRDN); Single image super-resolution; Fusion reconstruction; Residual dense connection; Multi-hop connection
- Abstract
In recent years, more and more attention has been paid to single image super-resolution reconstruction (SISR) by using deep learning networks. These networks have achieved good reconstruction results, but how to make better use of the feature information in the image, how to improve the network convergence speed, and so on still need further study. According to the above problems, a novel deep residual dense network (DRDN) is proposed in this paper. In detail, DRDN uses the residual-dense structure for local feature fusion, and finally carries out global residual fusion reconstruction. Residual-dense connection can make full use of the features of low-resolution images from shallow to deep layers, and provide more low-resolution image information for super-resolution reconstruction. Multi-hop connection can make errors spread to each layer of the network more quickly, which can alleviate the problem of difficult training caused by deepening network to a certain extent. The experiments show that DRDN not only ensure good training stability and successfully converge but also has less computing cost and higher reconstruction efficiency.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Single image super-resolution reconstruction (SISR) is to reconstruct a corresponding high-resolution (HR) image based on a low-resolution (LR) image by a certain algorithm. The super-resolution reconstruction, implemented at the algorithm level, can help to break the limitations of some imaging devices. Therefore, it is widely used in medicine imaging [1], satellite images, security monitoring [2], and so on.
SISR is an ill-posed inverse problem. This indicates that there are many different solutions to reconstruct the HR image from the corresponding LR image. The early super-resolution reconstruction methods are mainly interpolation methods. Although this kind of method is relatively simple, the reconstruction effect is not so ideal. Other methods for image super-resolution reconstruction mainly include the method by using prior information of the image [3,4], internal patch recurrence method [5,6], and traditional learning-based reconstruction methods [7–9]. In recent years, with deep learning network showing strong learning ability, more deep learning effective reconstruction method has been widely used to solve the ill-posed problem of image super-resolution reconstruction.
Dong et al. firstly applied the deep learning network to realize image super-resolution reconstruction (SRCNN) [10]. SRCNN constructed a three-layer convolutional neural network for the mapping of LR image to HR image. Its reconstruction effect was significantly improved compared with the traditional learning algorithm.
With the success of deep neural network in ImageNet [11,12], the application of deep neural network in image super-resolution reconstruction has become an important research content. Accurate Image Super-Resolution (VDSR) [13] deepened the depth of convolutional neural network to 20 layers. In order to ensure the effective convergence of deep neural network in training, VDSR introduced global residual connection and gradient clipping technology. Inspired by the residual network model, deeply-recursive convolutional network (DRCN) [14] and deep recursive residual network (DRRN) [15] were proposed one after another. In addition to deepening the network, efficient sub-pixel convolutional neural network (ESPCN) [16] convolved directly on LR images, and finally used sub-pixel convolution layer to realize up-sampling process. Densely connected convolutional networks (DenseNet) [17] maximized the transmission of feature information between layers by densely connecting and the dense connection made full use of the feature maps obtained by each convolutional layer. Inspired by DenseNet, Tong et al. [18] firstly introduced dense network to realize super-resolution image reconstruction.
Besides deepening the network, many researchers also proposed other structures to get better reconstruction results. Dong et al. [19] proposed a compact hourglass-shape CNN structure, namely FSRCNN, for faster and better SR, and re-designed the SRCNN structure mainly in three aspects. Wei-Sheng et al. [20] proposed the Laplacian Pyramid Super-Resolution Network (LapSRN). They trained LapSRN with deep supervision using a robust Charbonnier loss function and achieved high-quality reconstruction. Namhyuk et al. [21] designed an architecture that implements a cascading mechanism upon a residual network, and also presented variant models of the proposed cascading residual network (CARN) to further improve efficiency. Xiangxiang et al. [22] proposed a fast, accurate, and lightweight super-resolution (FALSR) method to get the balance between the restoration capacity and the simplicity of models.
Although the above methods have achieved good reconstruction results, with the deepening of network layers, the network parameters will increase dramatically and the network itself becomes more difficult to train and converge. On the other hand, many useful features obtained in each layer are often neglected in above networks. Moreover, information of each layer is often fused to a certain middle layer, rather than directly used for the final reconstruction, which will affect the utilization of layer's featureinformation.
Aiming at the above problems, this paper proposes a deep residual dense network (DRDN), which can effectively utilize feature information in and between the layers by connecting dense blocks (DB) to deepen the network. The main contributions of our paper are as follows:
Residual dense connection. Dense connection can make full use of local hierarchical information and provide more hierarchical feature information for final reconstruction. At the same time, the residual learning of each dense connected network block through the skip connection can alleviate the problems such as the training difficulty when deepening the network.
Fusion reconstruction. When deepening the network, the intermediate reconstruction results of each DB can be obtained by introducing residual skip connection to each DB, and the intermediate results of each DB can be fused and reconstructed, so as to obtain the final reconstruction results. At the same time, Multi-hop connection can make errors spread to each layer of the network more quickly, which can alleviate the problem of difficult training caused by deepening the network.
2. DRDN
Based on the comparison with DRCN and DRRN, this section first introduces the network structure of DRDN, and then analyzes the local feature fusion approach and the global residual fusion reconstruction approach in detail. In the analysis, we focus on the improvement of DRDN compared with DRCN and DRRN and why DRDN is superior to them.
2.1. Architecture of DRDN
Different from the cascade convolutional layer unit in DRCN and DRRN, DRDN adopts DB [17] (shown in Figure 1) as the basic block of network architecture. DRDN combines the ways of deepening the network in DRCN and DRRN, and connects each block in the same way through identical skip connection. Then after adding each basic block and identity connection, the outputs are taken as the intermediate results in reconstruction. Finally, all intermediate results are fused through the reconstruction layer (convolution kernel is 1 × 1) to obtain HR reconstructed images. The network structure of DRCN, DRRN, and DRDN is shown in Figure 2.

Dense Block (DB).
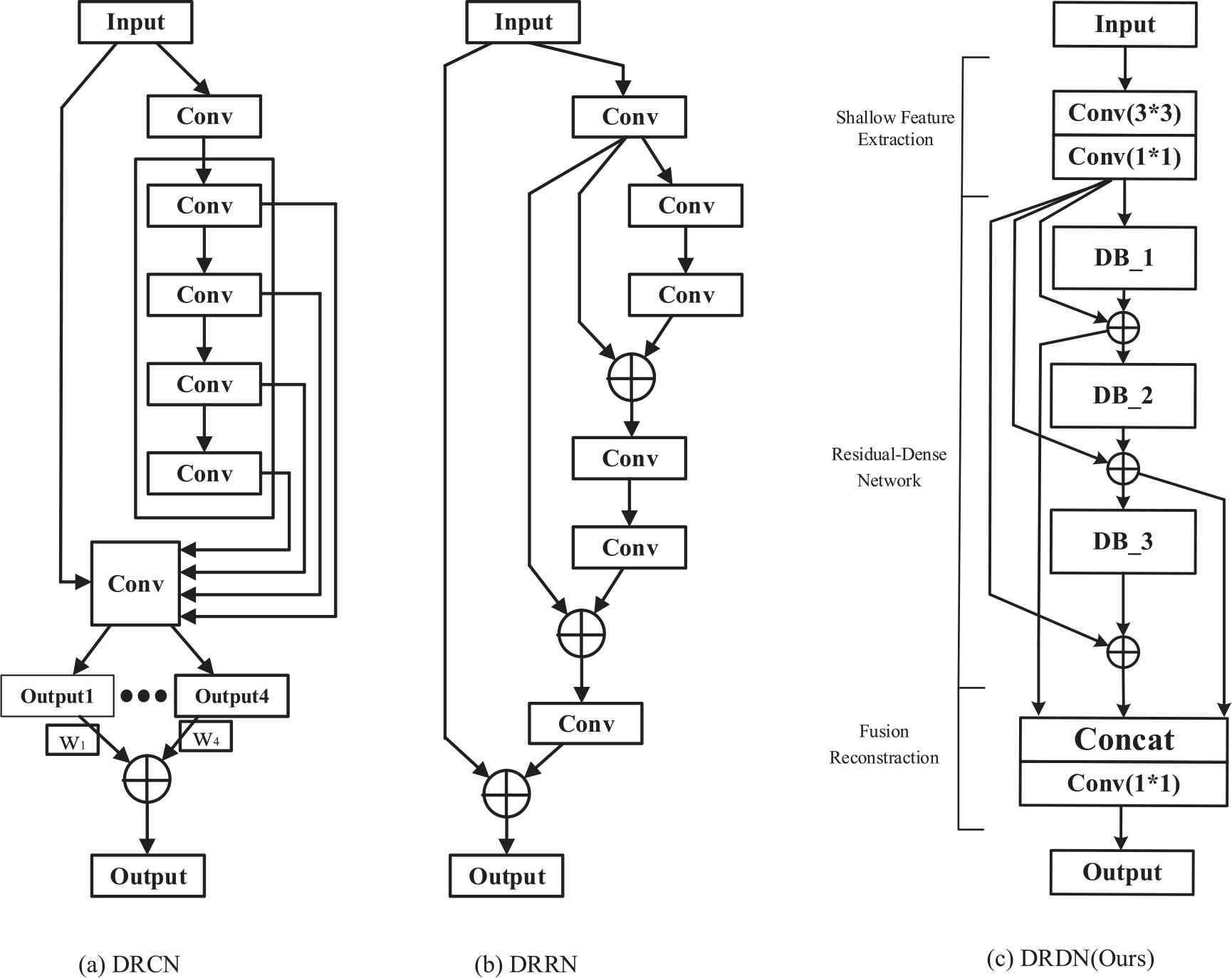
The diagram of network architecture.
DRDN mainly consists of three parts: shallow feature extraction, residual-dense network, and fusion reconstruction network. In the part of shallow feature extraction, two convolution layers with the convolution kernel size of 3 × 3 and 1 × 1 respectively are used to extract shallow features. Specifically, we use a multiple dense connected convolution layer (the convolution kernel is 3 × 3) and a feature contraction layer with the convolution kernel size of 1 × 1 as the basic block (also called DB) of the network. For residual learning, an identical skip connection is introduced between each DB and the shallow feature extraction layer. Multiple DBs are connected in the same way to deepen the network continuously. In the fusion reconstruction network, the results of each residual-DB are taken as intermediate results, and the final reconstruction results are obtained by weighting and summing these intermediate results.
2.2. Local Feature Fusion
In the reconstruction, we expect to make use of more LR image information, which needs the network reach a certain depth to obtain better reconstruction effects. When deepening the network, instead of taking two ordinary convolutional layers as the basic network block in DRRN, densely connected convolutional network is taken as the basic block in DRDN, as shown in Figure 3. In Figure 3,
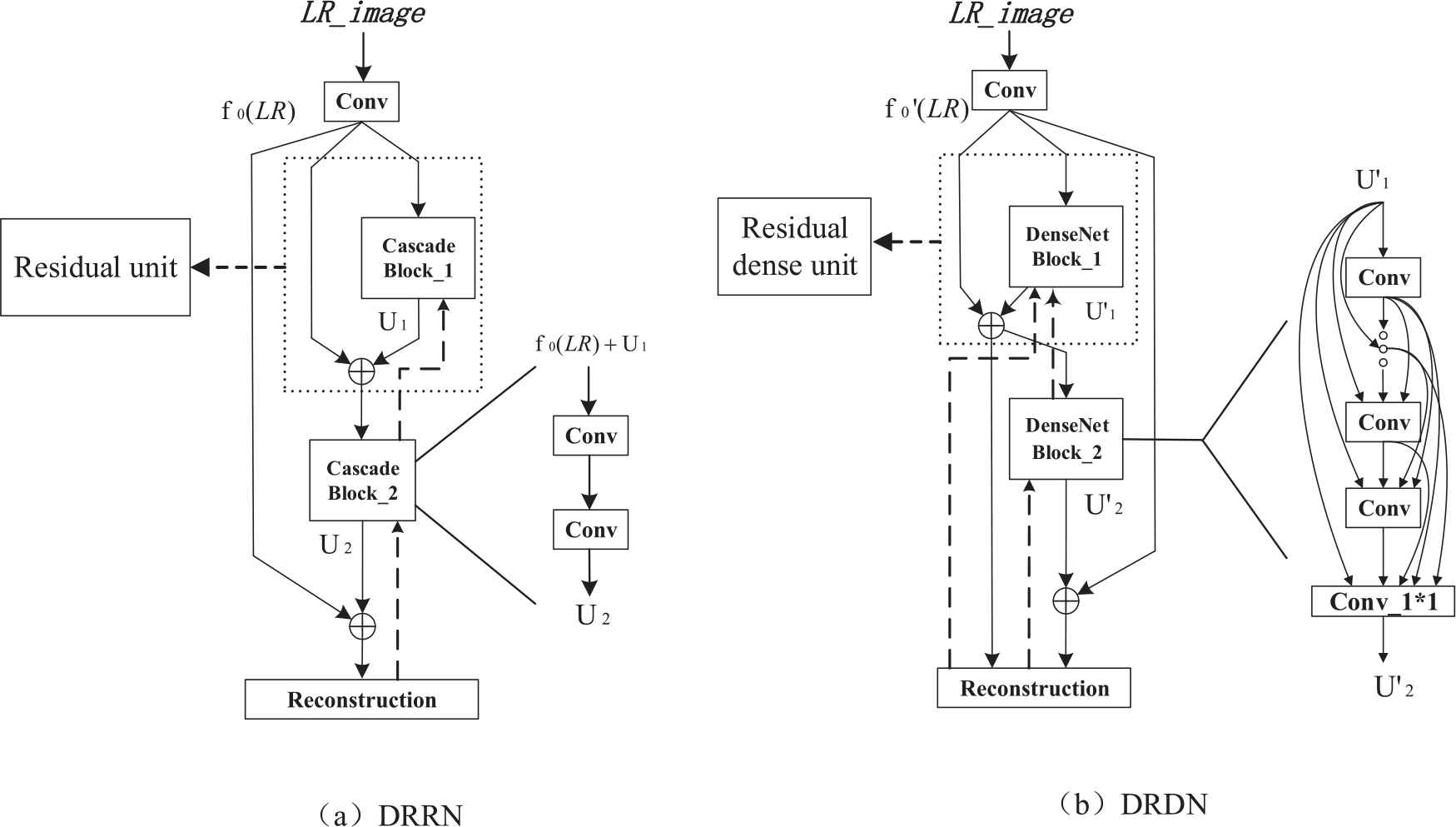
Simplified net architecture of deep recursive residual network (DRRN) and deep residual dense network (DRDN).
DBs are connected by multi-layer densely connected convolution layer and convolution layer with kernel size of 1 × 1, so that the DB can make full use of the feature information of each convolutional layer. Then, the intermediate result can be obtained via a convolution kernel with size of 1 × 1 from the feature information of the convolutional layer. Similar to DRRN, both the outputs of the above block in DRDN and the shallow feature are used as the inputs of the next block. The formula is expressed as:
In addition, for the diversity of feature information, different from DRRN adopting block weight sharing, DRDN trains the weight parameters in each block independently.
2.3. Global Residual Fusion Reconstruction
As shown in Figure 3, in DRRN, only the output of the last residual block is directly used to reconstruct the HR image, and the formula is expressed as:
At the same time, by these skip connections, the error in the deeper layer can be propagated to the shadow convolution layer faster and more directly. As shown in Figure 3, the dashed lines indicate the error backward propagation path. In DRRN, it can be seen that the reconstruction error needs to pass through all the blocks to reach the previous block. This is the main reason for gradient vanishing problem in deep networks. However, for DRDN, the identical skip connection can make the reconstruction error directly propagated to these blocks, which can alleviate the problems of gradient vanishing to a certain extent and accelerate the training. By using residual learning between DBs, the whole network can simultaneously complete local hierarchical features fusion and global features fusion, both of which provide rich hierarchical features information for final reconstruction.
3. EXPERIMENTS AND RESULTS ANALYSIS
3.1. Training
As in VDSR [13] and DRRN [15], MSE is taken as the loss function in training. Given a train set
3.2. Experiments Settings
As in VDSR, DRCN, and DRRN, the experiments also use the same data set containing 291 images [13–15] as the training data set, Set14, Urban100, BSD100, and other commonly public data sets are adopted as the test data set. Some graphic examples of the train dataset are shown in Figure 4.

Examples of train data sets.
In the stage of data preparation, the training data is artificially expanded by rotating and flipping the 291 images in 4 directions respectively, as shown in Figure 5(a). Data preprocessing is required before training, and the specific operation is as follows:
The RGB images are converted into YCbCr images, and only Y-channel is used for training and testing, as well as in SRCNN [10], DRCN [14], and DRRN [15].
Scale transformation and degradation processing are carried out on the images obtained in step (1) to obtain the LR images and the corresponding tag images with different magnification multiples (×2, ×3, ×4), as shown in Figure 5(b).
The images obtained in step (2) are cropped into image blocks with a size of 40 × 40 for network training, which is shown in Figure 5(c). These LR images with different magnification scales and label image pairs are used to train the same network model, so that the network model is suitable for reconstruction with different magnification scales.

(a) Training data expansion diagram, (b) Low-resolution image (left) and high-resolution image (right), and (c) Low resolution image patches (40 × 40) and label image patches (40 × 40).
So, the dataset containing 291 images is rotated and flipped to 291 × 8 = 2328 images. Among them, 2164 are training images and 164 are test images. After the processing in step (2), we can get 2164 × 3 = 6492 training images and 492 test images. After the tailoring in step (3), we can get about 648,000 image patches for training.
The specific operations of image reconstruction are as follows:
The size of the LR image is adjusted to 320 × 240, and then it is cut to 40 × 40 image patches.
DRDN is used to reconstruct image patches, and the reconstructed image patches are spliced according to the original locations to get the reconstructed HR images.
For experimental comparison, we trained the two networks (DRRN and DRDN) in the same hardware and software environment. The specific hardware and software environment configuration are shown in Table 1. Specially, when training DRRN, we carried out the training completely according to the network structure and parameter settings in Reference [15].
| Configuration | Parameter |
|---|---|
| OS | Ubuntu 16.04 |
| CPU | Intel i7 3.30GHz |
| GPU | GTX1080Ti (11G) |
| RAM | 16G/DDR3/2.10GHz |
| cuDNN | CuDNN 7.0 |
| CUDA | CUDA9.0 |
| Frame | Caffe |
Experimental environment configuration.
3.3. Experiments Analysis
Comparison of network parameters and reconstruction time
Table 2 shows the comparison of the two network parameters. DRRN deepens the network to 52 layers by introducing recursive units, and ours DRDN makes the network depth reach 50 layers by stacking multiple DBs. Meanwhile, the size of convolution kernel of each layer in the two networks is mainly 3 × 3. Under the same hardware and software environment, the average reconstruction time of the two networks on Set14 is as follows: DRRN takes 3.942s and DRDN takes 2.824s. This reflects that DRDN has less computing cost compared with DRRN.
Network robustness and convergence speed
Through repeated training of DRRN and DRDN, we find that under the same training environment, the training of DRRN is unstable, and often difficult to converge. There is only about one successfully converge among 4 times training. By contrast, DRDN can ensure good training stability and successfully converge among 4 training. Figure 6 shows the curves of peak signal to noise ratio (PSNR) with different iterations on Urban100 and BSD100 datasets. It can be clearly found that DRDN has a significantly faster convergence rate than that of DRRN. DRDN tends to converge after about 200,000 iterations, while DRRN gradually converges after about 400,000 iterations. This fully demonstrates that the introduction of multi-path reconstruction of DRDN with skip connection is conducive to accelerating network convergence. In addition, the experimental results also show that DRDN achieves better reconstruction effects.
Fusion reconstruction
Figure 7 shows the intermediate results obtained by each residual-DB, and the final HR image is obtained through fusion reconstruction. In Figure 7, the above images from left to right are 5 intermediate results, obtained from the 1–5 residue-intensive blocks, which named result_1- result_5, respectively. As can be seen from the figure, the result_1 obtained by the first residue-intensive block at the lower level is still fuzzy. With the stacking of network blocks, the feature information is more abundant, and the intermediate result obtained by the residual-DB at the deeper level is clearer. In the end, the residual-DBs of different depths can improve the feature information of different levels for reconstruction, so that the final reconstructed image has clearer and richer information.
Visual effect comparison of reconstructed images
Figure 8 shows the reconstructed images of VDSR, DRRN, and DRDN. Their PSNRs are shown in Table 3. In Figure 8, there are 3 test images. The images from left to right are the LR image, the reconstruction result of VDSR, the reconstruction result of DRRN, and the reconstruction result of DRDN, respectively. Because the LR image in Figure 8(b) contains more image details and textures, the results in Figure 8(b) reconstructed by 3 methods are better than those in Figure 8(a) and 8(c). Compared with other methods, DRDN achieves the best reconstruction effect, both in visual effect and PSNR value. This indicates that the rich feature information extracted by DNDN is helpful to improve the reconstruction effect.
Figure 9 shows detail parts corresponding to the images of Figure 8. It can be seen from the figure that the edge details of the reconstructed image obtained by DRDN are clearer and the lines are smoother.
| DRRN | DRDN | |
|---|---|---|
| Network layers | 52 | 50 |
| Convolution kernels size | 51 (3 × 3) + 1 (1 × 1) | 49 (3 × 3) + 1 (1 × 1) |
| Reconstruction time (Set14) | 3.942 s | 2.824 s |
DRDN = deep residual dense network; DRRN = deep recursive residual network.
Network parameters and reconstruction time.
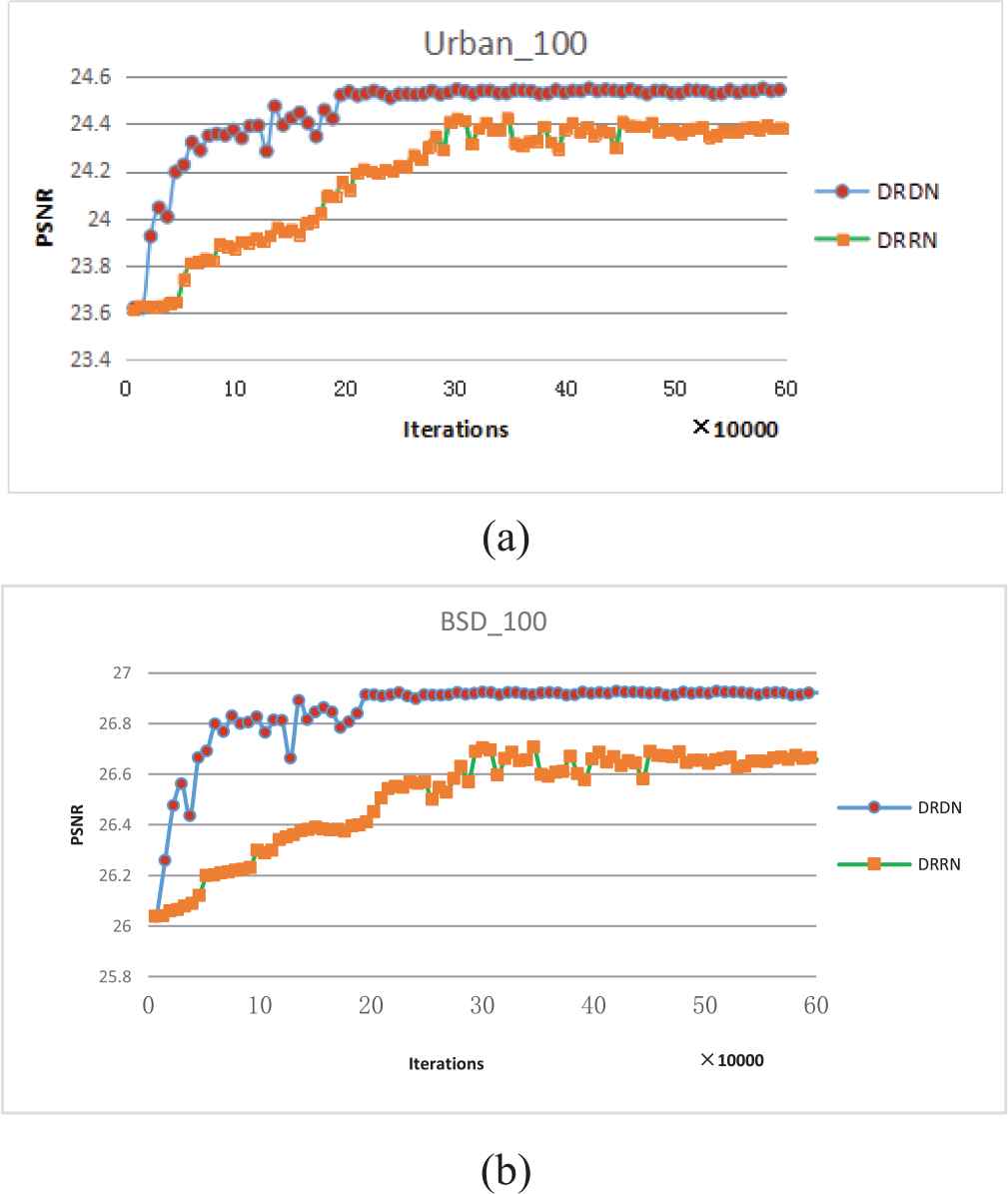
(a) The curves of peak signal to noise ratio (PSNR) values and iterations on Urban100, and (b) the curves of PSNR values and iterations on BSD100.
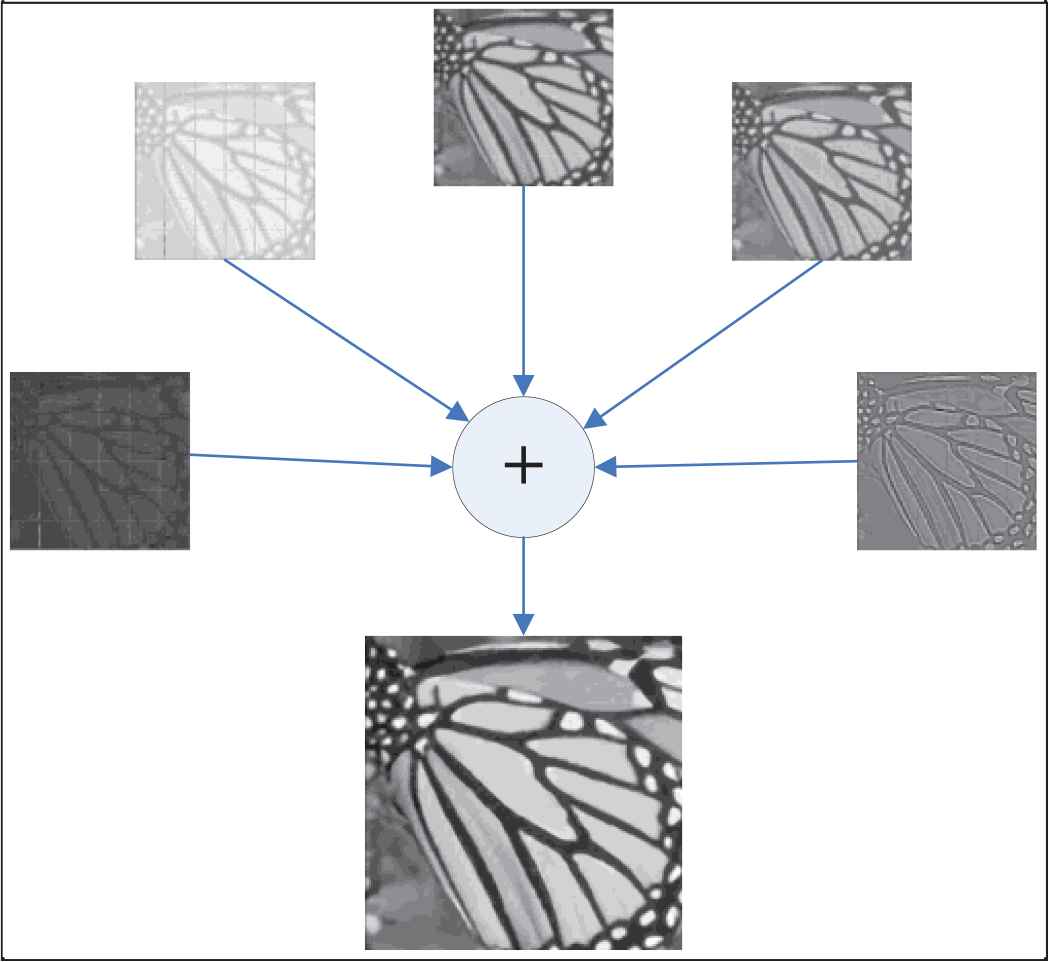
Fusion reconstruction result.

Visualization of reconstruction results.
| VDSR | DRRN | DRDN | |
|---|---|---|---|
| (a) | 26.5500 | 25.8549 | 26.6885 |
| (b) | 31.3138 | 30.4452 | 31.6819 |
| (c) | 30.3441 | 30.3072 | 30.4184 |
DRDN = deep residual dense network; DRRN = deep recursive residual network; PSNR = peak signal to noise ratio.
PSNR of the reconstructed images.

Details corresponding to the images in Figure 8.
In addition to the above experiments, we also test different approaches under our own experimental conditions, including SRCNN [10], FSRCNN [19], DRCN [14], LapSRN [20], DRRN [15], CARN [21], FALSR [22], and DRDN. The experimental results are shown in Table 4. PSNR is the average value of 200,000 iterations after the network is stable. The data sets used in the experiment are BSD100 and Urban100. As can be seen from Table 4, our method has achieved better results compared with other methods. On BSD100, the effect of DRDN is a little worse than that of FALSR, but better than those of other methods.
| Approach | Scale | BSD100 | Urban100 |
|---|---|---|---|
| SRCNN [10] | 4 | 21.12 | 20.13 |
| FSRCNN [19] | 4 | 21.14 | 20.21 |
| DRCN [14] | 4 | 22.23 | 21.08 |
| LapSRN [20] | 4 | 23.01 | 21.17 |
| DRRN [15] | 4 | 26.67 | 24.38 |
| CARN [21] | 4 | 26.72 | 24.52 |
| FALSR [22] | 4 | 26.86 | 24.55 |
| DRDN(ours) | 4 | 26.92 | 24.53 |
CARN = cascading residual network; DRDN = deep residual dense network; DRRN = deep recursive residual network; FALSR = fast, accurate and lightweight super-resolution; LapSRN = Laplacian Pyramid Super-Resolution Network; PSNR = peak signal to noise ratio.
PSNR of different networks.
4. CONCLUSIONS
In this paper, a new network structure named DRDN is proposed for image super-resolution. In DRDN, dense connection can make full use of local hierarchical information and provide more hierarchical feature information. Each DB can get an intermediate result, and the final reconstructed image can be obtained by weighted summation of all intermediate results. Reconstruction is the full fusion and direct utilization of the network's global hierarchical feature information. Furthermore, Multi-hop connection can make error spread to each layer of the network more quickly, which can alleviate the problem of difficult training caused by deep network to a certain extent. The experimental results show that both the reconstruction visual effect and PSNR of DRDN are better than those of CDSR and DRRN, and the details are clearer. Compared with the other 7 methods in Table 4, our DRDN approach also achieves good reconstruction results.
In the experiments, we found that different hardware/software and training methods have great impacts on the experimental results. Therefore, our future research is mainly about the adaptability of the methods to the environment and the further optimization of the network structure.
CONFLICT OF INTEREST
Authors have no conflict of interest to declare.
Funding Statement
National Defense Pre-Research Foundation of China (7301506); National Natural Science Foundation of China (61070040); Education Department of Hunan Province (17C0043); Hunan Provincial Natural Science Fund (2019JJ80105).
REFERENCES
Cite this article
TY - JOUR AU - Wang Wei AU - Jiang Yongbin AU - Luo Yanhong AU - Li Ji AU - Wang Xin AU - Zhang Tong PY - 2019 DA - 2019/12/14 TI - An Advanced Deep Residual Dense Network (DRDN) Approach for Image Super-Resolution JO - International Journal of Computational Intelligence Systems SP - 1592 EP - 1601 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.191209.001 DO - 10.2991/ijcis.d.191209.001 ID - Wei2019 ER -