
Composable Instructions and Prospection Guided Visuomotor Control for Robotic Manipulation
- DOI
- 10.2991/ijcis.d.191017.001How to use a DOI?
- Keywords
- Composable instructions; Motion generation; Prospection; Imitation learning; Visuomotor control; Robotic manipulation
- Abstract
Deep neural network-based end-to-end visuomotor control for robotic manipulation is becoming a hot issue of robotics field recently. One-hot vector is often used for multi-task situation in this framework. However, it is inflexible using one-hot vector to describe multiple tasks and transmit intentions of humans. This paper proposes a framework by combining composable instructions with visuomotor control for multi-task problems. The framework mainly consists of two modules: variational autoencoder (VAE) networks and long short-term memory (LSTM) networks. Perception information of the environment is encoded by VAE into a small latent space. The embedded perception information and composable instructions are combined by the LSTM module to guide robotic motion based on different intentions. Prospection is also used to learn the purposes of instructions, which means not only predicting the next action but also predicting a sequence of future actions at the same time. To evaluate this framework, a series of experiments are conducted in pick-and-place application scenarios. For new tasks, the framework could obtain a success rate of 91.2%, which means it has a good generalization ability.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Robotic manipulation technology has been widely explored by robotics researchers in past decades. It mainly studies how the robot could move and manipulate objects for various purposes by actions including grasping [1], pushing [2], pouring [3], opening [4], picking [5], placing [6] and so on. Robotic manipulation technology does not focus on the specific robot platforms but rather concentrates on the general related methods of the robot interaction with objects [7]. It involves, traditionally, scene understanding and segmentation, object recognition, pose estimation, action plan, motion plan, task plan and so forth. Robots need to perceive the surroundings by sensors, make decisions based on the perception information and move to execute decision results. Obviously, it is an integration of related technologies to finish specified manipulation tasks. Great successes have been achieved by decomposing manipulation tasks into different stages and solving them separately. Due to the good reliability and high availability of this roadmap, robotic systems based on this roadmap have been widely deployed in various scenarios. However, the framework with separated stages is often time-consuming and less responsive to changes of surroundings rapidly. Besides, propagation of deviations between each stage would also weaken the performance of this framework [8].
With deep neural networks making great achievements in image processing, machine vision and natural language processing, deep learning method is increasingly used in robot research. As a new pipeline for robotic manipulation, end-to-end visuomotor method has been proposed in recent years [9,10]. Compared to these traditional multi-stage frameworks, this pipline does not require scene understanding, object recognition, pose estimation, action plan and motion plan. The end-to-end visuomotor method attempts to map the perception information got by sensors into motional action space directly just like a visual servoing style [9]. The perception information is typically RGB images or both RGB images and depth maps. Depending on different application scenarios, the motion action could be an absolute value or relative changes in Cartesian coordinate or joint coordinate system. The action of visuomotor control could also be joint torque in the case of force control or contact interaction.
This end-to-end framework is more time efficient than the traditional separated method, and it could adjust its action in real time based on dynamic changes in the environment [10]. Furthermore, end-to-end frameworks are easily integrated with learning-based approaches. It has been used for robotic manipulation in different situations such as grasping [11], picking up [12] and pushing [2]. In the past few years, robotics researchers and artificial intelligence (AI) scientists are actively exploring the visuomotor control approach for robotic manipulation to expand its application field, enhance its robustness, accelerate its learning speed and so on [12,13]. Some studies also have been done through this learning-based end-to-end visuomotor control for multi-task or multi-step situations [14,15]. Previous research has validated that end-to-end visuomotor control for multi-task manipulation is more sample-efficient and robust compared to methods applied to single tasks [14]. One-hot vector, which means only one item of the vector is one and others are all zeros, is often used as instruction to distinguish different purposes of the robot in the same or different surroundings. However, it is inflexible using one-hot vector to describe multiple tasks and transmit intentions of humans. Tasks described by one-hot vectors also ignore the correlation of different tasks, which is very useful for generalization in robotic manipulation.
This paper tries to explore the relation of different tasks via considering the basic units of tasks. It displaces the one-hot vector with composable instruction and combines it with end-to-end visuomotor control for robotic manipulation in multi-task situation. The proposed approach mainly consists of two modules: a variational autoencoder (VAE) and a long short-term memory (LSTM) recurrent network. Perception information of surroundings is encoded by VAE into a small latent space. The embedded perception information and composable instructions are combined by the LSTM module to guide robotic movement based on different intents. Lots of execution trajectories are recorded as labeled training data. VAE is trained with images captured during execution of robotic manipulation, and then LSTM network is trained with state-action pairs, which could be regarded as policy network. Obviously, the learning style of this approach is a pure Behavior Cloning. Most methods of Behavior Cloning train the policy network with pairs consisting of current state and next action. Nevertheless, it is found that prospection mechanism is very important to get goals of the instructions in multi-task scenarios. Prospection means not only predicting the next action but also predicting a sequence of future actions at the same time.
On the whole, the primary contributions of the proposed method are twofold: (1) Considering the basic units of tasks, one-hot vector is replaced by composable instructions in the multi-task situations. As far as I know it is the first time that composable instructions are used to describe multiple tasks for robotic manipulation in the learning-based end-to-end visuomotor framework. (2) Different from the traditional BC framework, prospection mechanism is used in the training phase of the control network. Prospection mechanism tries to predict a sequence of future actions at the same time, which allows the robot to focus on the global characteristics and makes it easier to learn the intent of the instructions.
A typical multi-object pick-and-place application scenario is chosen for validation and it is similar to tasks of table clean-up or object sorting [16] for service robots in daily life. With the wide variety of manipulation tasks, learning-based methods are important ways to give robots diverse manipulation skills. Based on the proposed framework, the robot could get different skills with good generalization ability. In addition, the framework can be also used in other multi-step application scenarios including but not limited to cooking.
2. RELATED WORK
Robotic manipulation has always played an important role in the development of robotics and automation technology. Mason et al. surveyed the technologies of robotic manipulation and compared them with abilities of manipulation of humans [7]. Roboticists have been working to enable robots to perform manipulation tasks as intelligent and skillful as humans. Traditionally, robotic manipulation technology is divided into several parts such as perception, decision-making, motion plan and robot control. They are orderly combined after being processed separately to accomplish different manipulation tasks. Related technologies mainly include scene understanding and segmentation [17], object detection [18] and recognition [19], pose estimation [20], camera calibration [21], action plan [22], motion plan [23] and task plan [24]. Based on this technical roadmap, robots are used successfully for grasping objects [1], tidying up objects [6], cleaning up boxes [25], pouring waters [3], opening doors and drawers [4,26], picking fruits and vegetables [5], cooking [27] and so on. Due to the dynamic changes of the surrounding environment, the diversity of objects and the complexity of manipulation tasks, it is becoming harder and harder and even impossible to pre-determine every step in different robotic manipulation tasks. Various manipulation skills are gained by robots via learning-based methods, which include learning from demonstrations (LfD) [28], behavior cloning (BC) and imitation learning (IL) [29], reinforcement learning (RL) [30] as well as the combination of them.
With the great ability of feature self-extracting and powerful cross-modal mapping capability, deep neural networks have achieved a great success in scene understanding, object detection and recognition [31,32]. Similar methods are also used in the perception and decision stages of manipulation tasks and then they are combined with traditional motion plan and control methods to achieve different robotic manipulation tasks. Lenz et al. applied deep neural network to detect the robotic grasping points with RGB-D sensors for picking-up tasks [11]. Pinto et al. proposed a self-supervised grasping detection method which could obtain training data online [33]. Zeng et al. used an online self-learning method to combine pushing action and grasping action together for object grasping in dense clutter [2]. Zhen et al. used RCNN networks for object recognition and combined it with traditional pose estimation to build a scene graph, and then these scene graphs was used as goal states for high-level task plan [34]. Xu et al. applied a framework of neural task programming to acquire high-level semantic plan with video demonstrations [16]. As mentioned above, they are all still multi-stage pipelines, which are time-consuming and propagating uncertainty between each stage. As an alternative framework, learning-based end-to-end visuomotor methods were proposed [9,10,35]. Different from the multi-stage pipelines, these approaches combined perception and control together and mapped the perception information into robotic control actions directly via neural networks. Visuomotor control methods for robotic manipulation are often trained using IL, RL and their combinations. Levine et al. integrated deep neural networks with guide policy search (GPS) that was an RL method for learning contract-rich manipulation skills [35,36]. Pinto et al. applied an asymmetric actor-critic framework for the robot picking-up tasks and transferred it directly from simulation to real [37]. Levine et al. used an online visuomotor framework for grasping cluttered objects without hand-eye calibration. However, it needed 6 to 14 robots for months to collect labeled data [12]. Combining visuomotor methods with RL is normally data-inefficient and some works have been done to improve the efficiency. Finn et al. proposed a deep spatial autoencoder to compress the visual images and promoted the learning speed of RL in several simple robotic manipulation tasks [38]. Gu et al. proposed an asynchronous off-policy update tricks in 3D dimensions and obtained a higher efficiency with multiple robots learning at the same time [13]. James et al. used domain randomization for robot learning in simulation and transferred the manipulation skill from simulation to the real world [8]. A deep RL framework was used for peg-in-hole tasks by combining visual inputs, proprioceptive information and torques of end effector [39].
As a supervised learning framework, BC mainly has a high data-efficiency and could make robots obtain various manipulation skills rapidly. BC directly learns control policies from demonstrations while LfD may more emphasize learning from other's demonstrations, especially from humans. A more generalized demonstration-based learning framework is known as IL. Integrating IL with visuomotor control is also widely applied for robotic manipulation. Zhang et al. used virtual reality headsets with hand-tracking equipment to teleoperate the manipulator for manipulation demonstration data collection and validated the efficiency of IL in complex robotic manipulation tasks [40]. Generally, the IL framework was trained with the state-action pairs. For another way, Torabi et al. made a preliminary exploration about behavior cloning from observation (BCO) [41]. The framework just used the trajectories of observations or states without the information of action of each state. Similar to the objective of LfD, it has a great significance that the robot could observe others accomplishing a task to get manipulation skill, which is just like humans. There are also some articles focusing on reducing numbers of demonstrations for learning a new manipulation skill rapidly, named few-shot learning or one-shot learning. Finn et al. applied Meta-Learning for one-shot IL, which could efficiently adjust the parameters of the policy network based on new demonstration with few-shot learning [42]. Yu et al. proposed a domain-adaptive meta-learning method and make the robot learn a new pick-and-place skill from one human demonstration [43].
However, these meta-learning methods adjusted the whole parameters of the policy network for new demonstrations and would forget the previous manipulation skills. James et al. proposed a new few-shot learning framework via a task-embedded space [44]. This approach fixed the parameters of control network and performed new demonstration task via a task-embedded vector that was like instructions that is used to transmit intentions of humans. For multi-task situation, one-hot vector was often used as instruction to distinguish different purposes of the robot in the same or different surroundings. Rahmatizadeh et al. validated its efficiency and robustness of learning multi-task demonstrations at the same time by using end-to-end visuomotor framework [14]. One-hot vector was used to stand for different tasks. It was also used for motion switching in multi-step task such as cloth-folding [45]. Abolghasemi et al. improved the robustness of this multi-task approach via task-focused visual attention [15]. Hausman et al. also combined an embedding task space with RL to learn transferable robot skills [46]. Motivated by these related articles, in this paper, an end-to-end visuomotor framework with composable instruction is used for multi-task learning to get interpretable and extensible robot skills.
3. METHODOLOGY
The proposed framework is based on BC, which is a direct IL framework. There are some notations of end-to-end BC for multi-task robotic manipulation. The robot tries to learn a map from its state
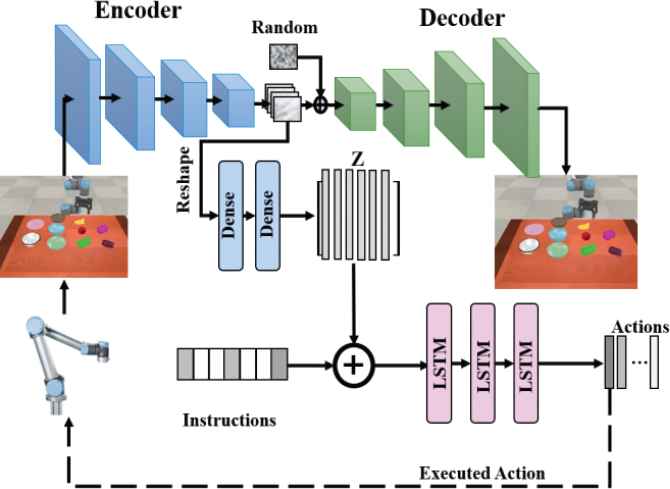
The framework of the proposed approach.
3.1. Perception Network
The perception of surroundings contains hardware of the robot, target objects and other disturbing objects. Normally, perception information are images obtained by a visual sensor, which are RGB images in this case. Images are very high-dimensional, especially in the case of a series of historical images and they are highly redundant for specific scenarios as well. It is very difficult to train these networks that map high-dimensional images to motion space from scratch and requires various kinds of labeled training data. Pre-training for networks that are used to process high-dimensional images information is very important, especially for networks composed of convolutional modules that could learn features for classification or regression by themselves. Compression processing is also widely used for redundant high-dimensional data such as images or video frames. Variational autoencoder [47] is often used to compress the perceptional information in field of robot vision [48–50]. It is verified that VAE has better generalization ability compared with traditional autoencoder (AE) in visuomotor framework [51]. Hoof et al. used VAE to process the high-dimensional tactile and visual feedback for stabilization task [48]. Hämäläinen et al. applied VAE to cope with the visual observation for affordance learning in a visuomotor control framework [49]. Piergiovanni compressed the image via a VAE for robot navigation [50]. Following this pipeline, a convolutional VAE module is also used for compression of the perceptual information in the proposed method, and it consists of a series of convolutional Resnet blocks [52,53]. VAE is a network that contains a bottleneck structure, which compresses high-dimensional images into a low-dimensional data. It is mainly separated into two modules: an encoder network
It assumes the restored
The reparameterization trick is usually utilized [47] for the non-differentiable sampling operation. It means auxiliary variables are used to replace the non-differentiable sampling operation:
The notations of these Gaussian distribution are shown:
The loss of VAE is followed:
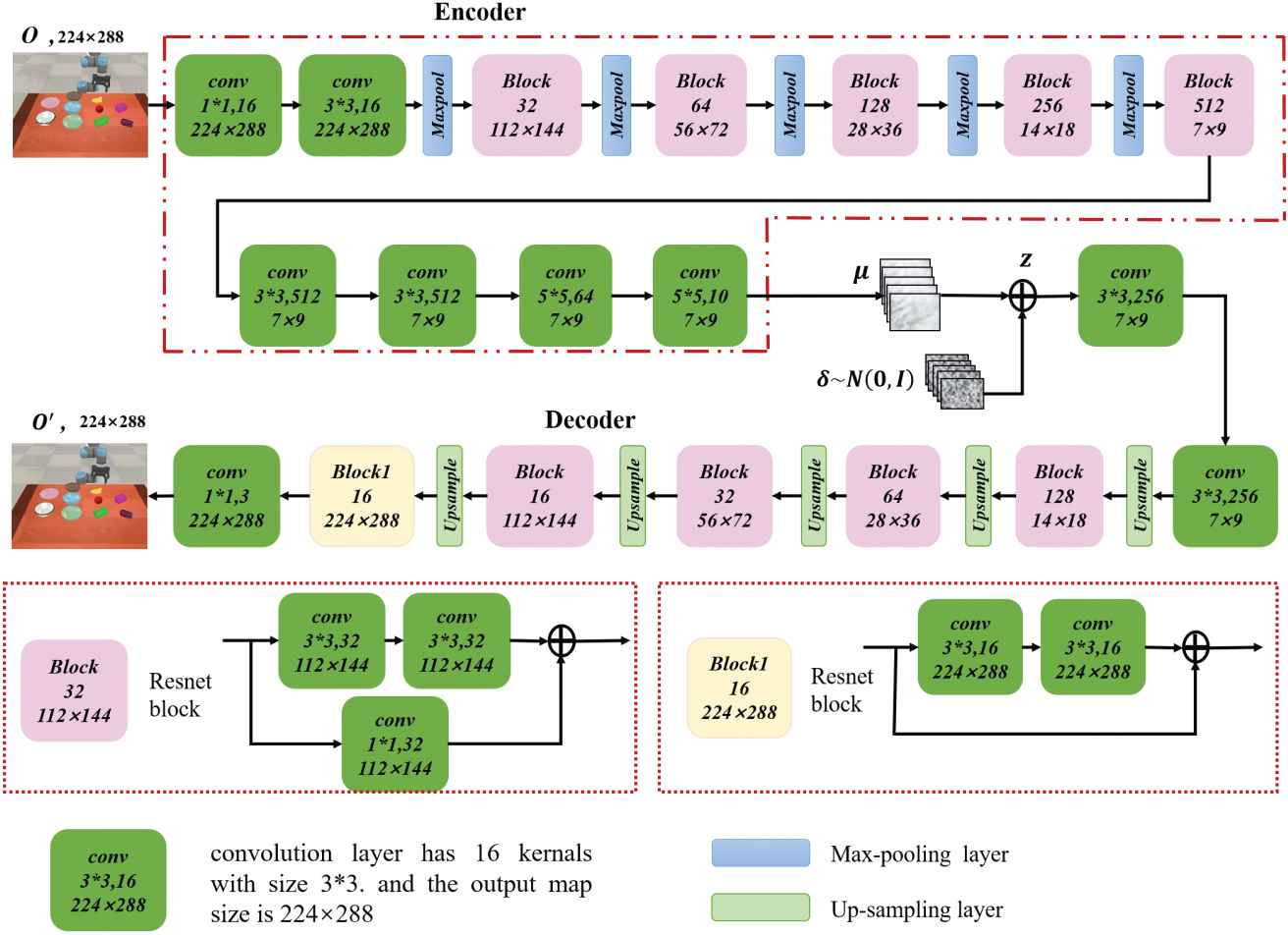
The detailed structure of variational autoencoder (VAE).
3.2. Control Network
Control network is primarily a LSTM recurrent network. It is used to guide the movement of the robot to accomplish specific manipulation task by merging embedding variable
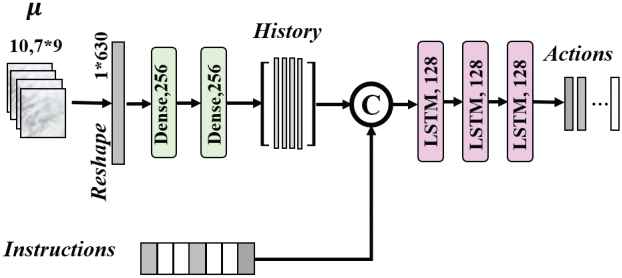
The structure of control network.
The end of task is also very important for multi-step tasks and instruction-guided manipulation tasks. Therefore, action space is expanded by adding a generalized action STOP that stands for whether the task is finished or not. Nevertheless, the stop state is just in the end of each trajectory in the training data. The ratio of positive and negative samples in the training data is very unbalanced for generalized action. Weighted cross entropy loss is chosen to strengthen the impact of the positive samples.
In general, the total loss function of the control network is shown below.
4. EXPERIMENT AND RESULT
In order to validate this learning-based end-to-end visuomotor control method, a series of experiments are conducted in a multi-object pick-and-place application scenario in the simulation environment, as illustrated in Figure 4. The simulation setup uses a UR5 robot equipped with an RG2 gripper in V-REP platform [54] with Bullet Physics 2.83 for dynamics, and the remote API functions of V-REP is used for communication with the main Python program. There are five objects to pick up and five containers for placement. The objects are randomly placed in the right half of the table, and the containers placed randomly in the left half of the table, which is illustrated in Figure 5. Therefore, there are totally 25 tasks that represent different object-container pairs. The UR5 robot tries to pick up different objects and then puts them into different containers according to specified instructions. Composable instructions consist of object vectors and container vectors. The simulate RGB camera outputs an image of size

The multi-object pick-and-place application scenario in V-REP.
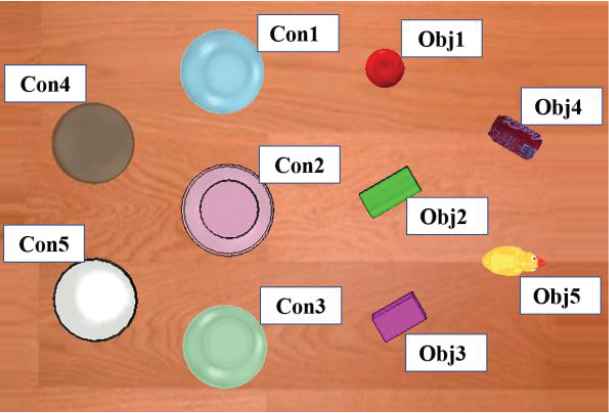
Objects and containers in pick-and-place manipulation task in V-REP.
2500 demonstration trajectories for pick-and-place tasks are collected in V-REP simulation environment, and each task has 100 demonstration trajectories. Images and poses of each trajectory are recorded at a frequency of 10 Hz. Each trajectory lasts six to eight seconds. The demonstrations are divided into two parts and the ratio of each task is 4 to 1. 2000 demonstrations are used as training datasets and the other demonstrations are used as validating datasets. Experiments are conducted to address following questions: (1) Could the robot execute pick-and-place manipulation tasks according to the specified composable instructions effectively based on this end-to-end visuomotor control framework? (2) Does the length
4.1. Training Perception Network
As forementioned, the proposed framework mainly includes two modules: a perception network and a control network. They are trained separately in the training phase. Perception network, VAE, is trained firstly and parameters of perception network are fixed while training the control network. The input of VAE is an image of size
4.2. Training Control Network
The latent tensor is obtained by the trained VAE, where the original image as the input is cropped at the center by a window of size
4.3. Testing the Proposed Framework
Two success rates are used to evaluate the performance of control networks with different parameter configurations. One is the success rate of completing the task with specified instruction, and the other is the success rate of picking up target objects. The first one is the main evaluation indicator, which represents the final performance of the proposed method. The successful pickup rate is used as an auxiliary index that could reflect some manipulation capacities of the robot system. For pick-and-place manipulations on the desktop, the pickup action has higher precision requirements while the action of placing objects into bowls has higher execution tolerances. Therefore, tasks are divided into five groups based on the target object to be picked up in the evaluation phase. Traditional one-hot vector-based framework is chosen as the baseline. We replace the composable instruction with a 25-dimensional one-hot vector in the control framework shown in Figure 3. Without prospection, the control network only predicts the next action rather than a series of future actions. Correspondingly, the loss of the BC
| Group | 1 | 2 | 3 | 4 | 5 | Avg | |
|---|---|---|---|---|---|---|---|
| Baseline | SR1 | 0.08 | 0.04 | 0.04 | 0.08 | 0.04 | 0.056 |
| SR2 | 0.28 | 0.20 | 0.24 | 0.24 | 0.20 | 0.232 | |
| Ours | SR1 | 0.96 | 0.88 | 0.76 | 1.00 | 0.84 | 0.888 |
| SR2 | 1.00 | 0.92 | 0.76 | 1.00 | 0.88 | 0.912 | |
The result of different frameworks.
4.4. Different Length of History and Prospection
To explore the effect of length of observation histories
To evaluate the performance of these parameter pairs, 25 trials are performed in each group, and results are shown in Figure 6. Rectangular bar indicates the success rate of task completion. Dot represents the success rate of picking up target objects. It is found that the proposed robotic system has a success rate of zero when the length of observation histories
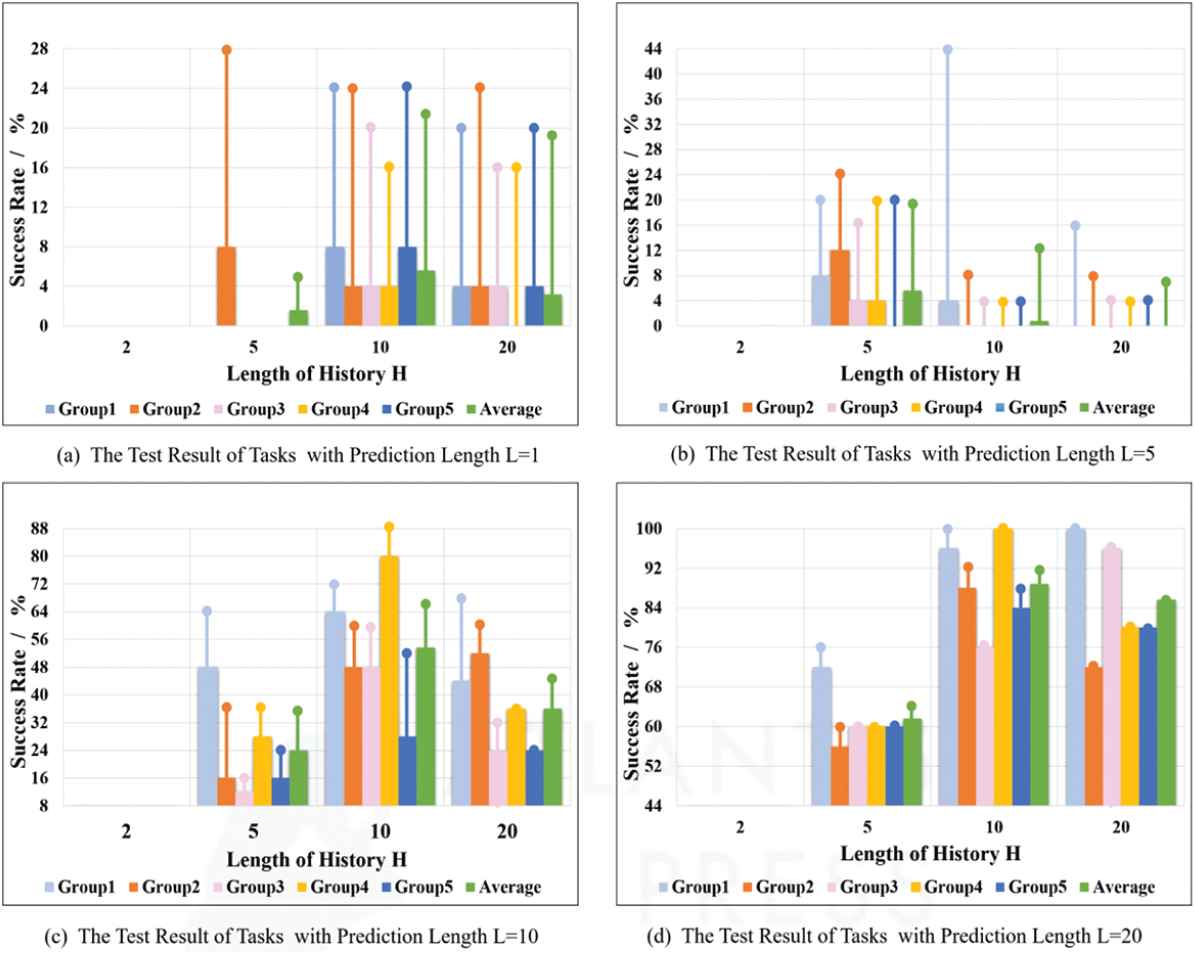
Test results with different historical lengths and predicted lengths.
4.5. Combining Observation and Proprioception
Both the observation and the proprioception of the robot are used as inputs to the control network in many visuomotor control methods for robotic manipulation [42,43]. Some experiments are conducted by merging the observation and the proprioception of the robot in this application situation. The structure of changed control network is shown in Figure 7. The position and orientation of the end effector is used as the proprioception information. The compressed latent vectors, the vectors of position and orientation, and the composable instructions are used as inputs of the LSTM module. Length of observation and proprioception are chosen to be 10, 20, respectively. Other hyper-parameters are all the same as shown in Subsection 4.2. Tasks are also divided into five groups, each performing 25 trials, and results are shown in Table 2. “W Pro” means the method with proprioception information of the robot, and “W/o Pro” represents the method without proprioception information which is also shown in Table 1. It is found that inputs by merging observation information and proprioception information of the robot could not improve the performance of proposed end-to-end visuomotor control approach for robotic manipulation tasks. Using the LSTM network to simultaneously learn a time series of images and proprioception information may make the network pay more attention to the series of positions of the end effector, and weaken the influence of a series of observations that contain rich important environmental information.
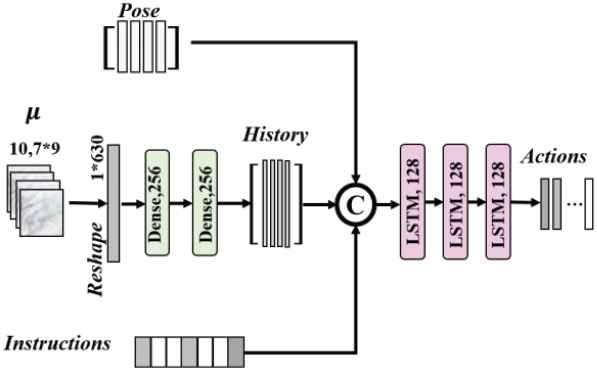
Control network structure combining observations with proprioceptive information.
| Group | 1 | 2 | 3 | 4 | 5 | Avg | |
|---|---|---|---|---|---|---|---|
| W/Pro | SR1 | 0.48 | 0.72 | 0.68 | 0.56 | 0.56 | 0.600 |
| SR2 | 0.48 | 0.72 | 0.68 | 0.56 | 0.60 | 0.608 | |
| W/o Pro | SR1 | 0.96 | 0.88 | 0.76 | 1.00 | 0.84 | 0.888 |
| SR2 | 1.00 | 0.92 | 0.76 | 1.00 | 0.88 | 0.912 | |
The test result of frameworks with/without proprioception information.
4.6. Generalization of Proposed Method
The generalization ability of the proposed framework is discussed in this subsection. Composable instructions are used for multi-task learning to get interpretable and extensible robot skills in this framework. There are 25 tasks, including 10 basic units, which are 5 target objects and 5 containers. The one-hot vector-based framework is also integrated with prospection mechanism, and it can be obtained by replacing the composable instruction with a 25-dimensional one-hot vector in the control framework shown in Figure 3. For both frameworks, length of observation and proprioception are set to 10, 20, respectively. Demonstrations of 20 tasks are used for training the control network and the left 5 tasks are reserved for testing. The performance of these different networks is shown in Table 3, which includes a network trained with partial datasets and a network trained with full demonstrations. “C/full” represents the framework with composable instruction, which is trained by the demonstrations of the total 25 tasks. “C/part” represents the framework with composable instruction, which is trained by the demonstrations of the 20 tasks. “O/full” and “O/part” mean the framework with one-hot vector-based instruction trained by corresponding demonstrations. “Task 1” represents the task with “Obj1” and “Con1” pairs, and there are similar meanings for Task 2 to 5. “Avg” means the average success rate of these five tasks. We can find that these two frameworks have similar performance in trained tasks. However, for the proposed framework, it is found that the network trained with partial demonstrations could also perform the Task 1 to Task 5 with an average success rate of 91.2%, even if they have not been trained before. The one-hot vector-based framework has no effect on the untrained tasks with a success rate of zero. In conclusion, it can be noticed that the proposed end-to-end visuomotor control framework with composable instruction has good generalization capabilities. Examples of execution of different tasks are shown in Figure 8. For the same surroundings, the robot executed different trajectories depending on different instructions.
| Task | 1 | 2 | 3 | 4 | 5 | Avg | |
|---|---|---|---|---|---|---|---|
| O/full | SR1 | 1.00 | 0.96 | 0.84 | 0.92 | 0.92 | 0.928 |
| SR2 | 1.00 | 0.96 | 0.92 | 0.96 | 0.92 | 0.952 | |
| O/part | SR1 | – | – | – | – | – | – |
| SR2 | – | – | – | – | – | – | |
| C/full | SR1 | 0.96 | 1.00 | 0.88 | 0.92 | 0.96 | 0.944 |
| SR2 | 0.96 | 1.00 | 0.96 | 0.96 | 0.96 | 0.968 | |
| C/part | SR1 | 0.96 | 1.00 | 0.80 | 0.80 | 1.00 | 0.912 |
| SR2 | 1.00 | 1.00 | 0.88 | 0.80 | 1.00 | 0.936 | |
The result of different frameworks trained by full/part demonstrations.
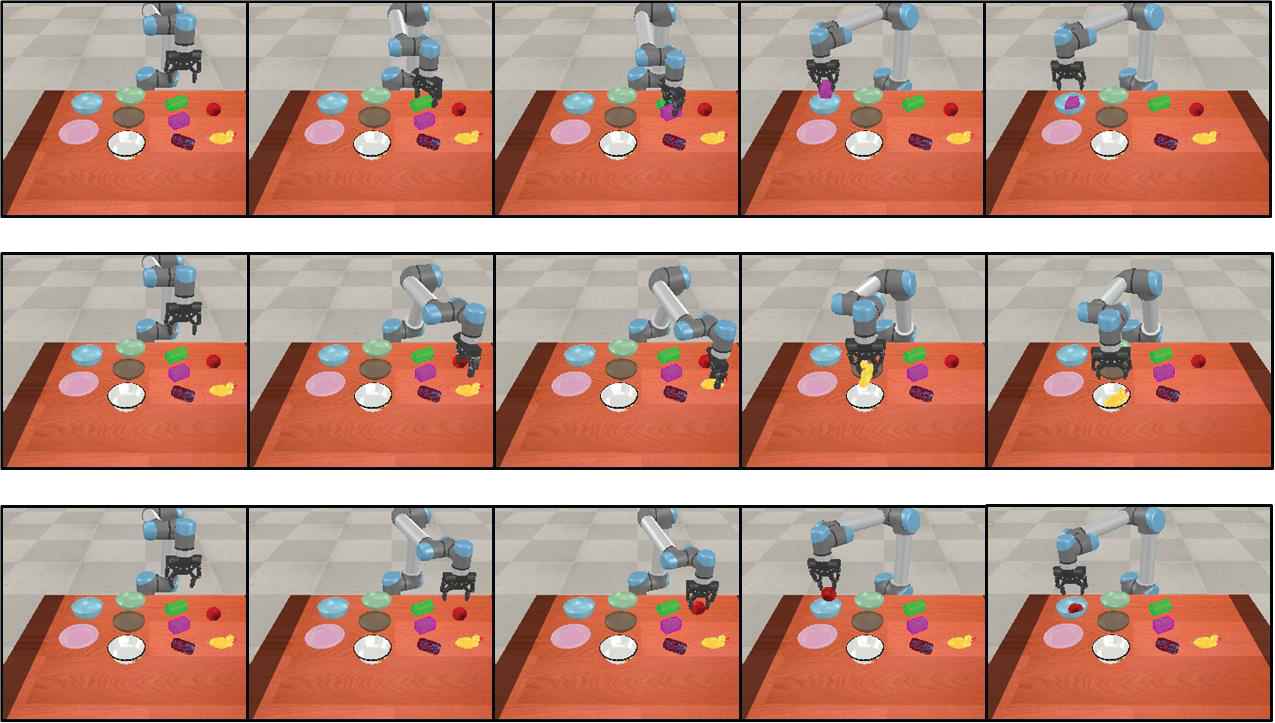
Trajectories of execution of different tasks based on different instructions.
5. CONCLUSION AND FUTURE WORK
This paper proposes a method for robotic manipulation by combining composable instructions with learning-based end-to-end visuomotor control framework for multi-task problems. Composable instructions are used to explore the relations of different tasks via learning the basic units of tasks by itself. Prospection strategy is also used in this framework, which means that the control network predicts not only the next action but also a sequence of future actions simultaneously. Prospection makes the robot pay more attention to the global characteristics and makes it easier to learn the intents of the instructions. Different experimental results demonstrate the effectiveness of this proposed method. Having said that, the application scenario of this method is still relatively simple and it would be explored with more manipulation actions such as pushing, rotating and so on in the future. Long series of high-level instructions is also worth exploring further.
ACKNOWLEDGMENT
This research is mainly supported by Special Program for Innovation Method of Ministry of Science and Technology of China (2018IM020100), National Natural Science Foundation of China (51775332, 51975360, 51975350) and the Cross Fund for medical and Engineering of Shanghai Jiao Tong University (YG2017QN61).
REFERENCES
Cite this article
TY - JOUR AU - Quanquan Shao AU - Jie Hu AU - Weiming Wang AU - Yi Fang AU - Mingshuo Han AU - Jin Qi AU - Jin Ma PY - 2019 DA - 2019/10/30 TI - Composable Instructions and Prospection Guided Visuomotor Control for Robotic Manipulation JO - International Journal of Computational Intelligence Systems SP - 1221 EP - 1231 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.191017.001 DO - 10.2991/ijcis.d.191017.001 ID - Shao2019 ER -