
Context-Based User Typicality Collaborative Filtering Recommendation
- DOI
- 10.2991/hcis.k.210524.001How to use a DOI?
- Keywords
- Knowledge granulation; contextual information; user typicality; recommendation; granular computing
- Abstract
Since contextual information significantly affecting users’ decisions, it has attracted widespread attention. User typicality indicates the preference of user for different item types, which could reflect the preference of user at a higher abstraction level than the items rated by user, and can alleviate data sparsity. But it does not consider the impact of contextual information on user typicality. This paper proposes a novel context-based user typicality collaborative filtering recommendation algorithm (named CBUTCF), which combines contextual information with user typicality to alleviate the data sparsity of context-aware collaborative filtering, and extracts, measures and integrates contextual information. First, the items are clustered and classified into different item types. For different users, the significance of contextual information for different item types is defined and measured via knowledge granulation. Then, the contextual information is combined with user typicality to measure the context-based user typicality; subsequently, the ‘neighbor’ users are determined. Finally, the unknown ratings under a single context are predicted, and the unknown ratings under multi-context are predicted according to the weighted summation of the significance of contextual information. The experimental results demonstrate that CBUTCF can effectively improve the accuracy of recommendation and increase coverage.
- Copyright
- © 2021 The Authors. Publishing services by Atlantis Press International B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
With the advent of Web 2.0, data on the internet have grown exponentially, and traditional information retrieval has failed to satisfy the users’ needs. To gain insight about users’ interests and present corresponding information to them, recommender systems have become the most potential tool.
Collaborative filtering (CF) is a classic and popular technology for recommender systems. It includes user-based CF [28] and item-based CF [29]. The idea of CF is to find ‘neighbors’ of all users (or items) according to the historical ratings, and recommend highly related items to the target user. Therefore, finding the ‘neighbors’ of users (or items) is an important step in CF. Currently, most CF algorithms measure the similarities between users (or items) based on user historical ratings to find ‘neighbors’. However, CF is not suitable for users (or items) with few or no rating, called the data sparsity problem [14]. To address this problem, Ren et al. [27] used the rule extraction algorithm based on rough sets to extract the user & item attributes from the core value decision rules to fill in the rating table. Zhang et al. [36] integrated the social information of users with their rating information to fill in the expert ratings. Hawashin et al. [12] proposed a new efficient mixed similarity measure method for user interest-based recommender systems. Cai et al. [5] borrowed the idea of object typicality from cognitive psychology and proposed a typicality-based CF recommendation method. Cai’s method, different from the matrix filling method, could solve the data sparsity problem. However, in some cases, it is not accurate to only consider the user’s interaction with the item, and the contextual information may also have an impact on the user’s decision-making.
In the field of recommender systems, Adomavicius et al. [2] believed that it is unreasonable to only rely on the user-item matrix to capture the preference relationships between users. Chen [6] believed that ‘neighbors’ of user have the same preference in similar environments. For example, some users originally like horror movies, but they watch cartoons with their children. Owing to the popularization of mobile network equipment, recommender systems can better obtain and collect more contextual information. Correspondingly, the researches on the context-aware recommendation theory have been further developed [7,9,17,20,22,33]. In previous researches, Yep et al. [35] combined the context attributes with Bayesian networks for prediction. Setten et al. [30] proposed the travel application COMPASS. Lee et al. [18] combined the contextual information with decision trees for a restaurant recommender systems. However, these algorithms considered all contextual factors together and did not distinguish the significance of different contextual information. Huang et al. [15] proposed a context-aware recommendation method using rough sets and CF to recommend suitable items in a specific context. This method considered the contextual dependencies of the items; however, it did not consider the differences in the dependencies of the items between users, and user-based CF method was inflicted the effects of data sparsity problem, which inspired our study.
Knowledge granulation which is a new uncertainty measure formula proposed by Liang [19]. It can be used to measure the significance of attributes in complex information. Zhang [37] proposed a utility function with both knowledge space granularity and approximation accuracy for automatically searching optimal knowledge space according to user’s requirement. Jing [16] introduce incremental mechanisms to compute new knowledge granularity and developed the corresponding incremental algorithms for attribute reduction. Xu [34] considered relationship between knowledge granulation, knowledge entropy and knowledge uncertainty measure, and introduce definition of rough entropy of rough sets in ordered information systems, which is an application of knowledge granulation.
Therefore, for context-aware collaborative filtering affected by data sparsity, using user typicality instead of user ratings to express user preferences can effectively alleviate data sparsity. This paper combines user typicality with contextual information, which can not only consider user’s preferences in contextual information, but also alleviate data sparsity. The original algorithm did not explicitly distinguish the significance of information in different contexts, which does not conform to human cognition. Regarding the significance of distinguishing different contextual information, this paper introduces knowledge granulation, which can distinguish the significance of different contextual information in complex information. On this basis, this paper proposes a context-based user typical collaborative filtering recommendation algorithm, and a large number of experimental results illustrate that the algorithm in this paper can achieve a better recommendation effect.
Therefore, the main innovations of this paper can be summarized as follows:
- (1)
Combine user typicality with contextual information, and consider user preferences at a higher level under contextual information.
- (2)
The introduction of knowledge granularity is used to measure the user’s preference for item types under the context type.
The remainder of this paper is organized as follows. Section 2 introduces the related work and basic knowledge. Section 3 describes the formal definition and basic model of the context-based user typicality. Section 4 introduces CBUTCF in detail. The experimental results are presented in Section 5. Section 6 concludes the present work and outlines future research.
2. RELATED WORK
To further discuss the ideas of this study, this section reviews the relevant definitions of user typicality, context-aware recommender systems, and knowledge granulation. User typicality is a concept for describing preference of user. Context-aware recommendation is the integration of contextual information into recommender systems. Knowledge granulation describes the degree of subdivision of knowledge.
2.1. User Typicality
To solve the inaccurate measurement of similarities between users caused by data sparsity problem in traditional CF, Cai et al. [5] borrowed the concept of object typicality from cognitive psychology and proposed a typicality-based CF recommendation method named TyCo. First, items with similar attributes were grouped into a category called ‘item group’. Second, for each item group, there existed a corresponding group called the ‘user group’. The user group corresponding to the item group was considered as a fuzzy concept, i.e., ‘users who like the items which in the item group’; additionally, all users hava different degrees of user typicality in each user group. Third, a user-typicality matrix was constructed and the similarities between users were measured according to the degree of user typicality in all user groups; subsequently, a set of ‘neighbors’ was determined for the target user. Finally, the unknown rating of the target user was predicted based on the ratings of the ‘neighbors’ on the same item. User typicality indicates the preference of the user for different item types. Assume that in a CF recommender systems, there are a set U of users, and a set O of items, and its official definition can be given as follows.
Definition 1.
[Item group] [5] An item group ti is defined as:
Definition 2.
[User group] [5] A user group gi is defined as:
The measurement method of vi,x is as follows:
Definition 3.
[User typicality vector] [5] A user typicality vector
Definition 4.
[User-typicality matrix] [5] A user-typicality matrix, denoted by MT, is composed of user typicality vector of each user, and defined as follows:
2.2. Context-Aware Recommender Systems
In previous research, Adomavicius et al. [2] believed that combining contextual information with recommender systems could help in improving the accuracy of prediction, and proposed the concept of ‘context-aware recommender systems’ [3], referred to as CARS [1]. They extended the ‘user-item’ two-dimensional model, User × Item → rating, to a multi-dimensional model containing contextual information, User × Context × Item → rating. Currently, there is no standard definition of ‘context’. Dey [10] provided a relatively normative definition of context; context refers to the environment itself and the information expressed by the entities present in the environment. Entities denote users, geographic locations, or related objects that interact with users and applications.
Definition 5.
The formal definition of contextual information [3] is as follows:
The context of the user is defined as context combination c, such as a user is at night and at home at the same time. And the task of CARS [3] is to predict the user ratings under context combination c.
2.3. Rough Sets
The basic idea of the rough set theory is to form concepts and rules through the classification and induction of a relational database, and discover knowledge through the classification of indistinct relationships and approximation of targets [21]. In this chapter, the theory of rough sets and the measurement of knowledge granulation are briefly introduced.
Definition 6.
[Decision information system] [25] A decision information system can be expressed as S = (I, A, V, f), where I is the complete set of objects, also known as universe. A = C ∪ D is the complete set of attributes, and subsets C and D are called the conditional attribute set and decision attribute set, respectively. V = ∪r∈A Vr is the set of attribute values. f: I × A → V is an information function that specifies the attribute value of each object x in I.
Definition 7.
[Indiscernibility relation] [25] Given a decision information system S = (I, A, V, f), A = C ∪ D, for each attribute subset B ⊆ A, an indiscernibility relation IND(B) on universe I can be defined as:
Obviously, the indiscernibility relation satisfies reflexivity, symmetry and transitivity, so INB(B) is an equivalence relation in I. The equivalence relation INB(B) induces a partition of I. An object x ∈ I is described by its equivalence class of I/IND(B): [x]INB(B), or simply [x] and [x]B. The pair (I, IND(B)) is called an approximation space.
Definition 8.
[Knowledge granulation] [19,37] Given a decision information system S = (I, A, V, f), A = C ∪ D, I/IND(B) = {X1, X2,..., Xn}, the knowledge granulation of A, denoted by G(B), can be described as follows:
3. CONTEXT-BASED USER TYPICALITY
Some formal definitions of CBUTCF are introduced in Section 3.1, the mechanism of CBUTCF is described in Section 3.2, and the correlation between knowledge granulation and context attributes is discussed in Section 3.3.
3.1. Preliminaries
Assume that O = {o1, o2,..., on} is a set of items, U = {u1, u2,..., um} is a set of users, C = {c1, c2,..., cw} is a set of context attributes, and T = {t1, t2,..., tz} is a set of item groups. The items can be classified into different item groups; the items in a item group have similar attributes, and an item can only be classified into one item group. For example, all movie can be classified into horror, action, comedy movies, and so on. These items are classified into different groups with K-means [23], so the degree of one item belonging to one item group is only 1 or 0. Because the clustering method is not included in the scope of this study, it will not be discussed here. These formal definitions can be described as follows.
Definition 9.
[Context-based decision information table] Construct a context-based decision information table: RS = < R, C, T, V, f, ϕ, θ > using the historical ratings of a user, where
- •
RS denotes a non-empty finite set of ratings, R denotes one rating;
- •
C denotes a non-empty finite set of context attributes (set of conditional attributes), C = (C1, C2,..., Cw), where Ch denotes a context attribute, Ch,k denotes a variable of the context attribute (named context state);
- •
D denotes a non-empty finite set of item type (set of decision attributes), ti denotes a item type;
- •
ϕ: R → D denotes a function of the corresponding item type for rating R;
- •
θ: R → D denotes a function of the context attribute of rating R.
For example, Table 1 presents a context-aware recommendation in the form of a decision information table, wherein the rows contain a set of ratings RS{R1, R2,..., R6}. The columns consist of user u1, set of context attributes C (time, location, and companion), item type ti, and rating value. Context state Ch,k refers to the variable of a context attribute, such as ‘Weekday’ or ‘Weekend’ in time. The rating value of a user depends on these context states; correspondingly, the rating predictions depend on other user ratings under the same context state.
| Ratings | User | Time | Location | Companion | Item type (Item) | Rating value |
|---|---|---|---|---|---|---|
| R1 | u1 | Weekend | Home | Friend | 3(I1) | 5 |
| R2 | u1 | Weekend | Home | Friend | 3(I18) | 3 |
| R3 | u1 | Weekend | Theater | Friend | 3(I100) | 5 |
| R4 | u1 | Weekend | Theater | Alone | 3(I56) | 4 |
| R5 | u1 | Weekday | Theater | Family | 4(I30) | 4 |
| R6 | u1 | Weekday | Home | Friend | 1(I13) | 3 |
Examples of context-aware recommendation
These ratings can be divided into different decision classes according to different item type. For example, for ratings of item type 3, the decision class {R1, R2, R3, R4} can be obtained, and the decision class can be divided into 3 equivalence classes {R1, R2}, {R3}, and {R4} according to the context attributes. This indicates that ratings R1 and R2 are indistinguishable, while other ratings can be uniquely identified using the context states.
Under the same context state, users with similar interests in a item group could form a community, called a context-based user group. The context-based user typicality indicates the preference of a user for a specific item group under a context state. Under the same context state, users can have different context-based user typicality in different item groups; additionally, in different context states, users can have different context-based user typicality in the same item group.
Definition 10.
[Context-based user group] A context-based user group
The degree of context-based user typicality for ux in gi in Ch,k is measured by combination function
Definition 11.
[Context-based user typicality vector] In Ch,k, users can have different user typicality in different context-based user groups. The preference of a user can be denoted by a context-based user typicality vector. The context-based user typicality vector
Definition 12.
[Context-based user-typicality matrix] In Ch,k, the context-based user-typicality matrix can be obtained for all users, defined as
3.2. Knowledge Granulation of Context Attribute for Item Type
Knowledge granulation is used to measure the uncertainty between objects. When the knowledge granulation is larger, it indicates that the user makes more decisions in the current context attribute; thus, it can be considered as the significance of the context attribute. Therefore, the greater the knowledge granulation, the greater the significance of the context attribute. This algorithm aims to determine the correlation between the context attributes of different users and item types in context-aware recommendation. If Ch uniquely determines the item type, ti depends entirely on Ch. The significance of Ch for ti can be defined as:
3.3. Mechanism of CBUTCF
The mechanism of context-based user typicality CF recommendation includes three steps, as follows:
- (1)
The ratings of each user are separately constructed into a context-based decision information table, and each decision information table contains the ratings of only one user. First, the ratings are induced partitions based on ti to obtain the rating decision classes [o]ti. Second, [o]ti is divided according to Ch to obtain the rating equivalence classes; then, the knowledge granulation G(ti|Ch) is measured. Thus, the significance of context attributes for item type can be obtained.
- (2)
For each ti, there exists a corresponding context-based user group
In previous algorithms, the preference of users were inferred based on the contextual user-item rating matrix. Figure 2 illustrates a contextual user-item rating matrix. In CBUTCF, a user is denoted by a context-based user typicality vector, for whom each element can be considered as a feature of the user under the context state. This representation method can portray the preference of users under contextual information more accurately than the traditional context-aware CF algorithms.
- (3)
The unknown rating of the target user in Ch,k is predicted based on the ratings of ‘neighbors’ of the target user on the same item. Subsequently, according to the significance of the context attributes for the item types, the predicted rating of the complete context state for a user can be obtained by weighted summation.
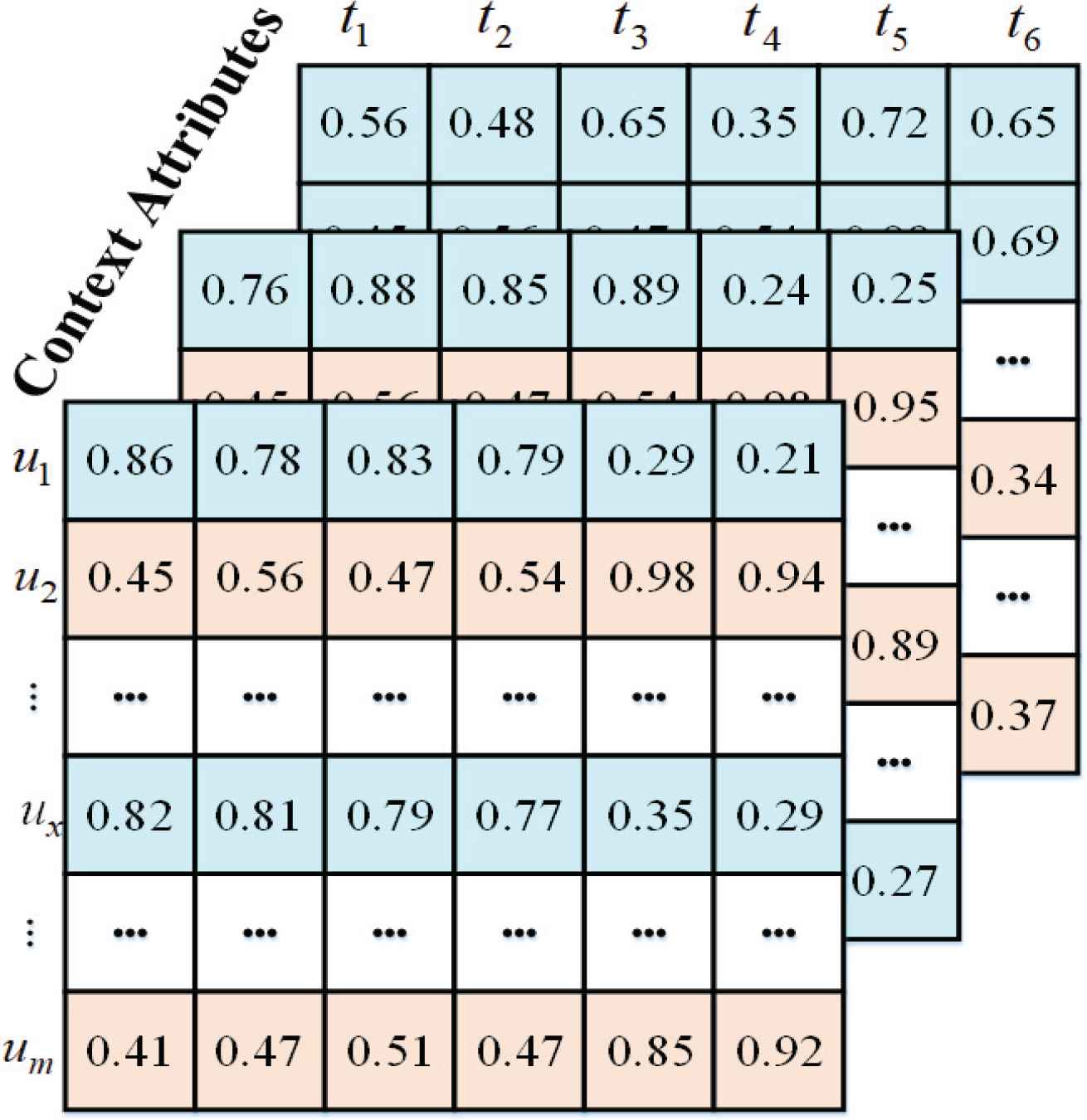
Example of context-based user-typicality matrix.
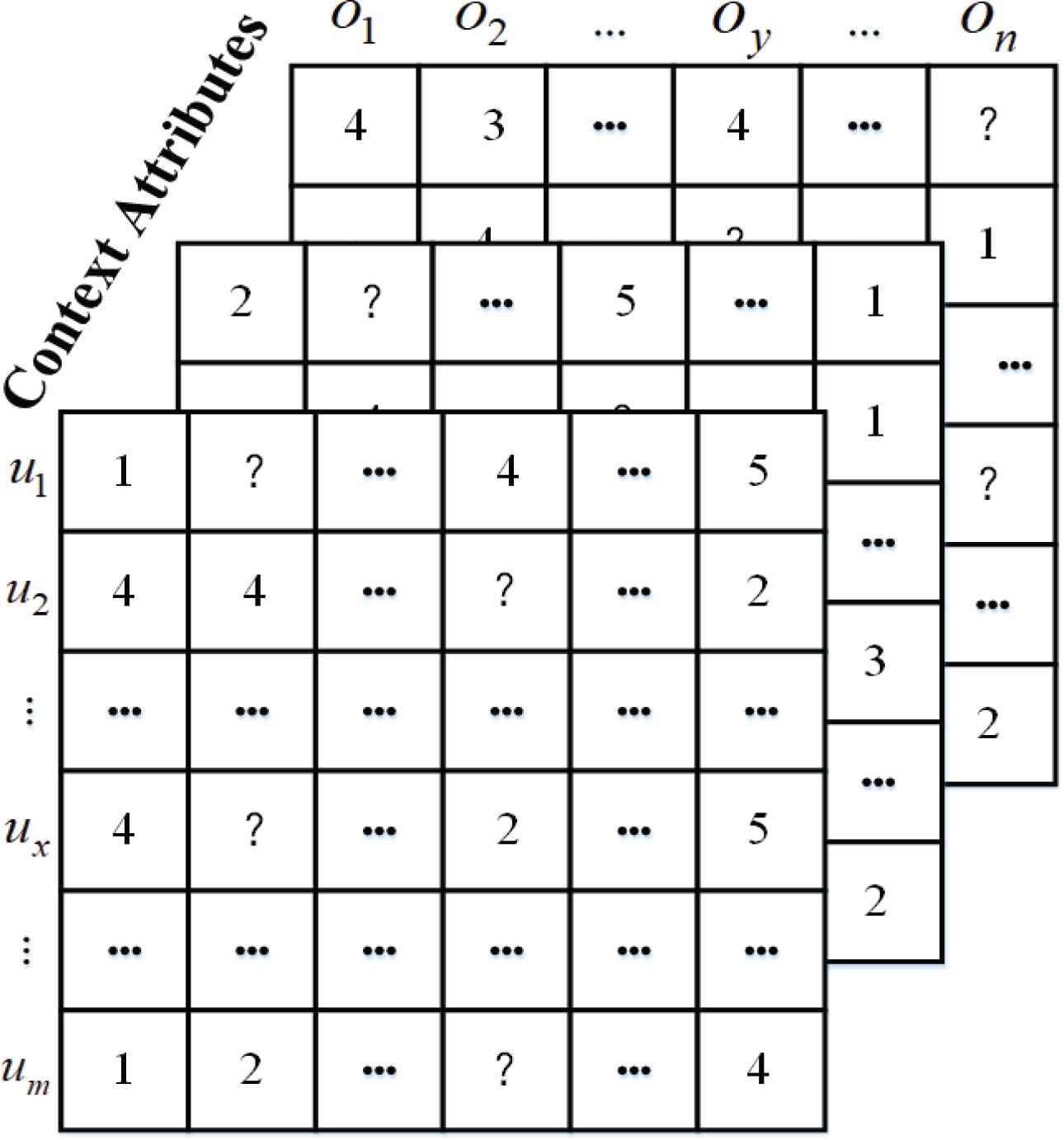
Example of contextual user-item rating matrix.
4. CONTEXT-BASED USER TYPICALITY RECOMMENDATION
To measure preference of users in contextual information, context-based user typicality recommendation algorithm was proposed, which combines contextual information with user typicality.
First, the importance of the context attribute to the item type is measured via knowledge granulation. Second, the similarity between users is measured according to context-based user typicality vector; subsequently, the ‘neighbors’ can be determined. Finally, the rating of item is predicted under context combination. And CBUTCF is described in Section 4.4.
4.1. Significance of Context Attribute for Item Type
Various types of contextual attribute appear in context-aware recommendation. However, some context attributes have a greater impact on users’ decisions, while others have little or no impact. To recommend suitable items in context combination, the significance of context attributes for different item types must be determined for each user.
Definition 13.
[Significance of context attribute for item type] Let C, Ch ∈ C, and ti be a set of contextual information, context attribute, and item type, respectively. For ux, a set of the significance of context attribute for item type
The significance of context attribute for item type refers to the degree of preference of a user for an item type under a context attribute. The measurement process of

Significance of context attribute for item type
4.2. Similarity Measure and Neighbor Selection
A set of ‘neighbors’ of ux in Ch,k is denoted by
If a candidate user uj has the K-highest similarity of target user ux, they will be selected as
4.3. Prediction Based on Context
After obtaining these ‘neighbors’ of the target user in Ch,k, the rating of target user ux on oy is predicted in Ch,k according to the ratings of other ‘neighbors’
Then, the predicted rating
4.4. Description of CBUTCF
To better present the logic and flow of the proposed algorithm in this study, the algorithm process of context-based user typicality CF recommendation can be described as follows (Algorithm 2), and the algorithm flow is illustrated in Figure 3.

Context-based user typicality CF recommendation
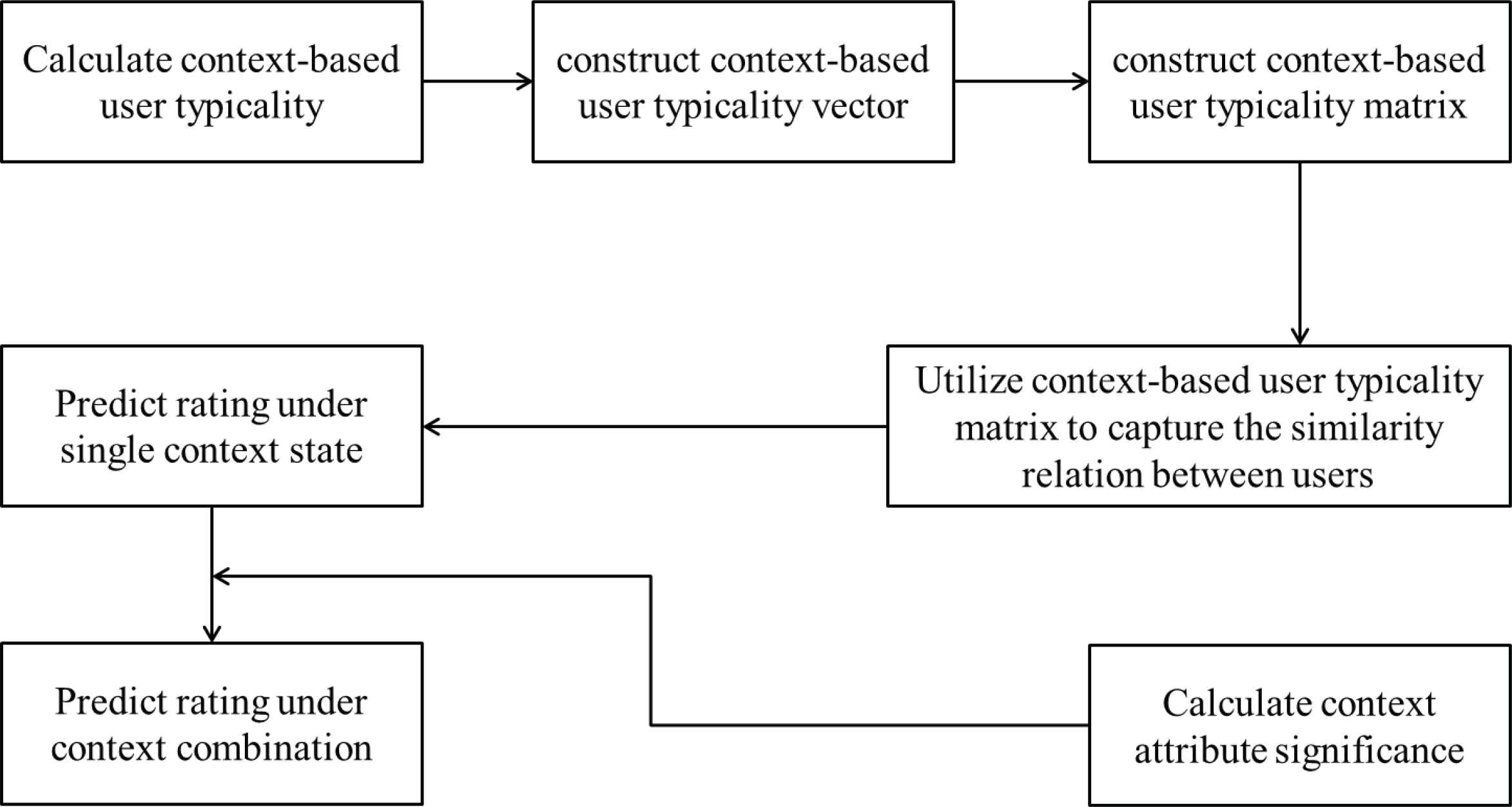
Flowchart of context-based user typicality CF recommendation.
5. EXPERIMENTS
To better demonstrate the effectiveness of CBUTCF, a series of experiments were conducted to compare CBUTCF with other CF algorithms. These experiments aimed to answer two questions: “an contextual information improve the accuracy?” and “an the proposed algorithm help in solving the data sparsity problem for recommendation?”
5.1. Data Set Description
In the experiments, three real data sets, LDOS-CoMoDa, Restaurant & Consumer and Filmtrust data sets, were used to evaluate performance of CBUTCF in this study. The LDOS-CoMoDa [4,24] contains 2296 ratings, assigned by 121 users on 1232 movies, and the ratings follow the numerical scale of 1 (bad) to 5 (excellent). The sparsity level of the data set is
In this study, by adding reasonable context generation rules to the two data sets Restaurant & Consumer and Filmtrust, the simulated real data sets named C-R&C and C-Filmtrust were constructed, so that C-R&C and C-Filmtrust have the same contextual information with LDOS-CoMoDa.
The following contextual information was used in the experiments,
- (1)
Time: time period for watching movies (morning, noon, evening, early morning).
- (2)
Day type: types of days to watch movies (weekdays, weekends, holidays).
- (3)
Season: types of season to watch movies (spring, summer, autumn, winter).
- (4)
Location: location of watching movies (home, public places, friend home).
5.2. Metrics
To evaluate the performance of recommendation algorithm, the mean absolute error (MAE), root mean squared error (RMSE), and Coverage [13,31] were used as the evaluation indicators.
MAE and RMSE indicate the average error between the predicted and actual values. The lower these values, the better the recommendation effect of the recommendation algorithm. The MAE and RMSE are as follows:
Coverage indicates the ratio of predictable items to all items that need to be predicted; it helps in evaluating the comprehensiveness of prediction. When the coverage is higher, the recommendation effect is more comprehensive. Coverage is as follows:
5.3. Experimental Results
The experiments extract four train set ratios, which 20%, 40%, 60%, 80% of the LDOS-CoMoDa as the train set, respectively, and the rest as the test set. In CBUTCF, the number of user groups depends on the number of item groups. To measure the effect of different numbers of user groups on the experimental results, the experiments were conduct on the number of user groups (i.e., i) from 5 to 25. Figures 4–6 illustrate the results for the MAE, RMSE, and Coverage in different train set ratios.
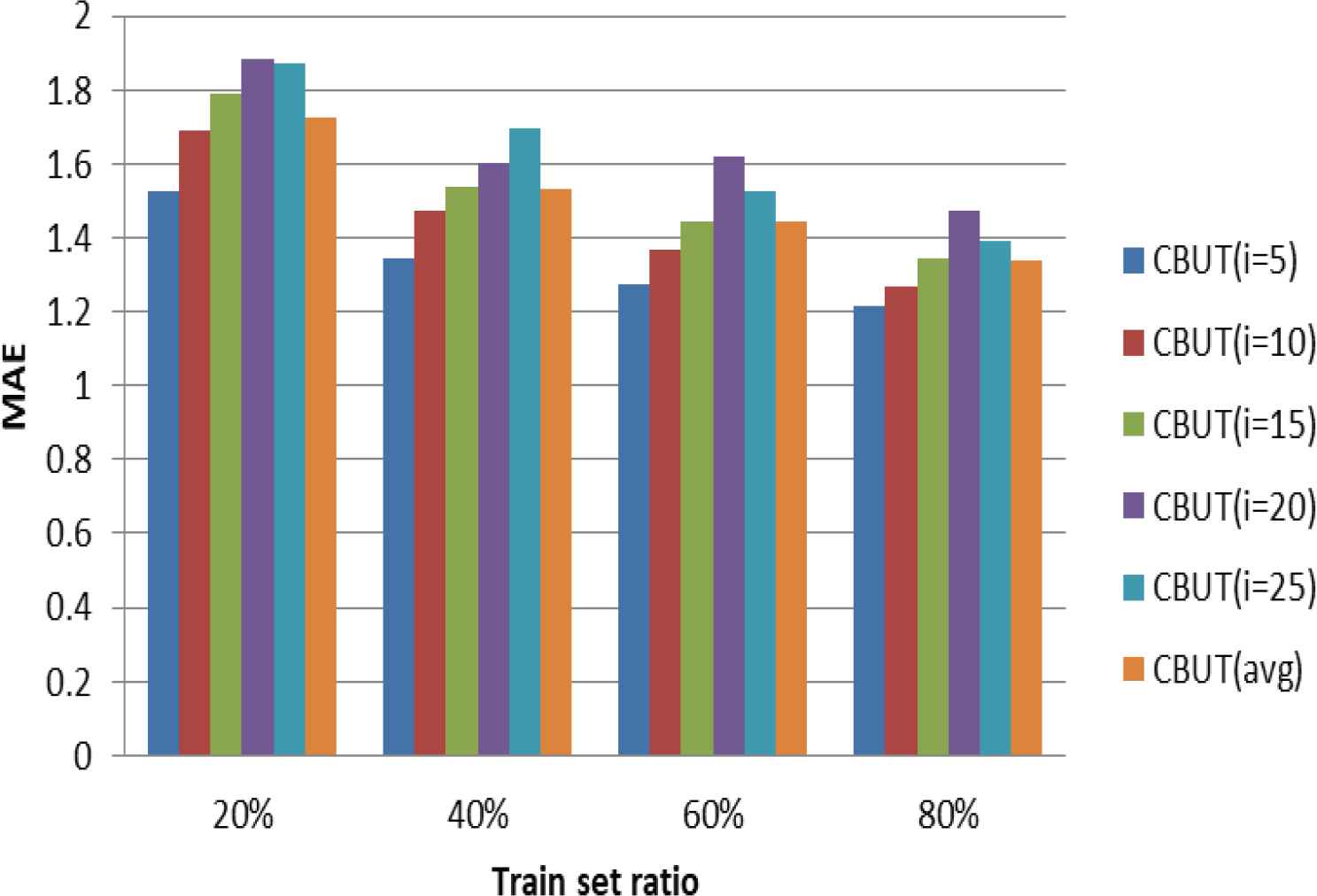
Effect of i on MAE in different train set ratios.
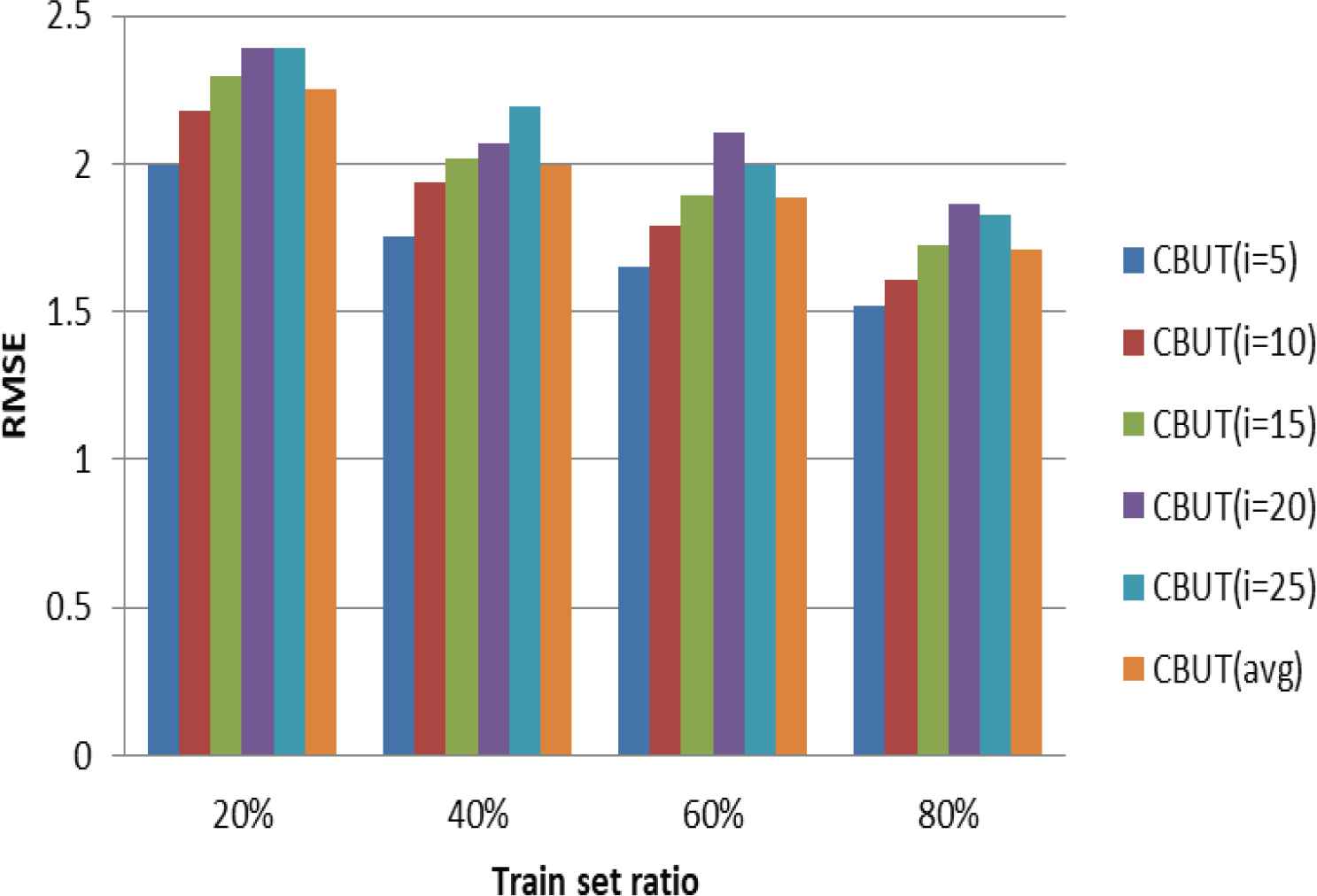
Effect of i on RMSE in different train set ratios.
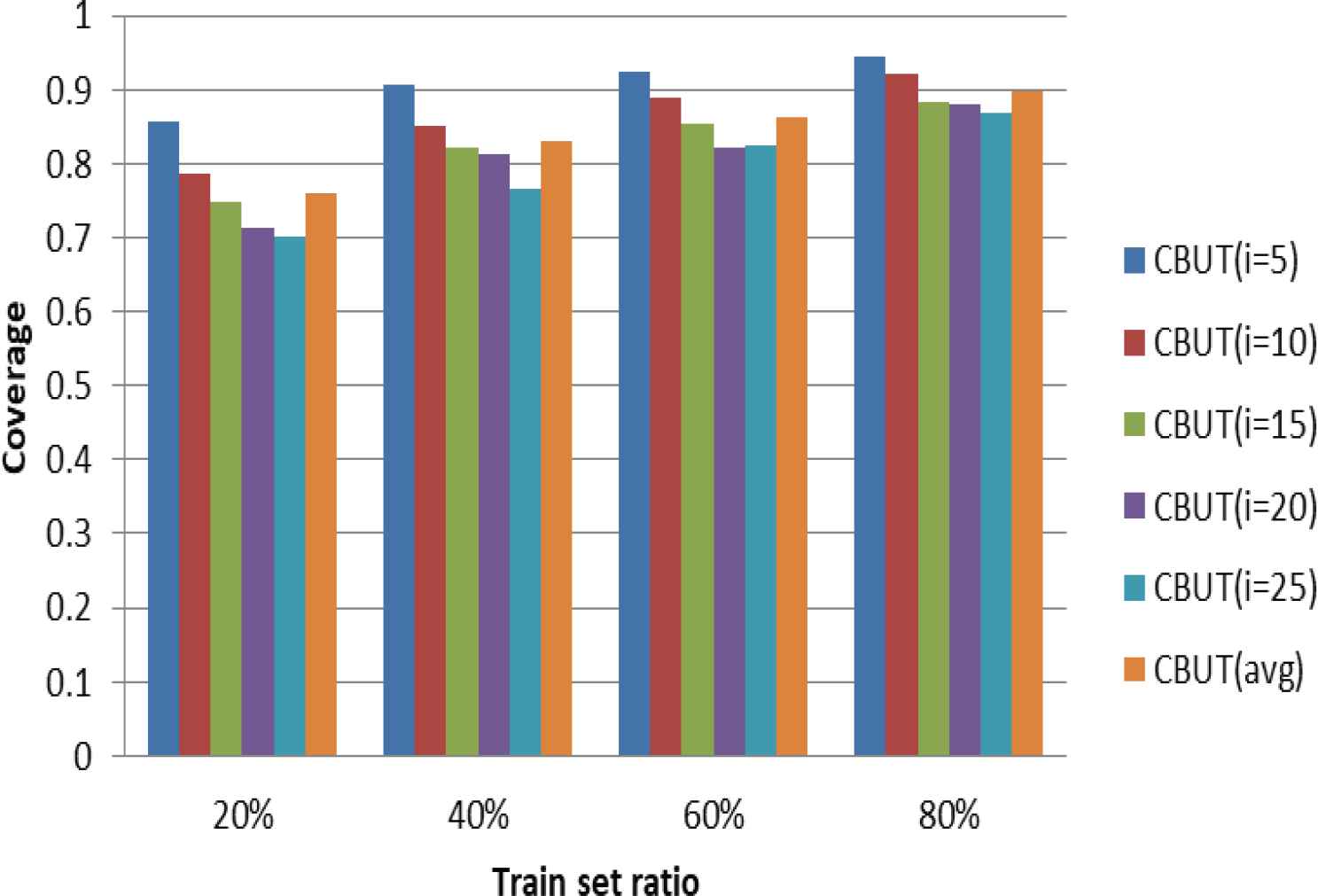
Effect of i on Coverage in different train set ratios.
Figures 4–6 illustrate the influence of the number of different user groups in four train set ratios on the three recommendation metrics. The experiments illustrated that the number of user groups has little effect on the recommendation results under the same train set ratios. Therefore, the recommendation effect is considered to be stable under different user groups.
To illustrate the recommendation performance of CBUTCF, it was compared with the following three algorithms using the same similarity function (Cosine similarity),
- (1)
User-based CF algorithm (UBCF) [28]. The UBCF first finds out a set of nearest ‘neighbors’ (similar users) for each user, then the rating of a user on an unknown rating is predicted based on the ratings given by the target user ‘neighbors’ on the item.
- (2)
Context-aware recommendation using rough set model and CF (CARS-RSCF) [15]. The dependencies of items on the context attributes are measured according to attribute reduction; then, the similarities between users under the context are measured and IBCF is adopted to recommend appropriate items.
- (3)
Typicality-based CF recommendation (TyCo) [5]. A user is represented by a user typicality vector which could indicate the preference of user on each kind of items; then, the ‘neighbors’ of target user could be determined by measuring similarities between users based on their typicality degrees instead of corated items by users.
- (4)
CF hybrid filling algorithm for alleviating data sparsity (HFCF) [26]. From the project point of view, the sparse matrix is filled according to the rating information of similar items. At the same time, starting from the user’s point of view, use the filled matrix to calculate the neighboring users of the target user. Select the item with the most common scores to further fill in the matrix.
- (5)
Mode Filling CF (MFCF) [32]. Calculate the user’s average rating of the item and fill in the rating matrix.
- (6)
Mean value CF (MVCF) [32]. Fill the scoring matrix with the scores with the most user reviews.
Four train set ratios, i.e., 20%, 40%, 60%, and 80% were extracted from the three data sets in the experiments, and the aforementioned six algorithms were compared with CBUTCF (when the number of ‘neighbors’ was 20). UBCF, TyCo, HFCF, MFCF and MVCF did not consider the contextual information, and only used the user-item rating information from the three data sets. The experimental comparison results are shown in Figures 7–15.
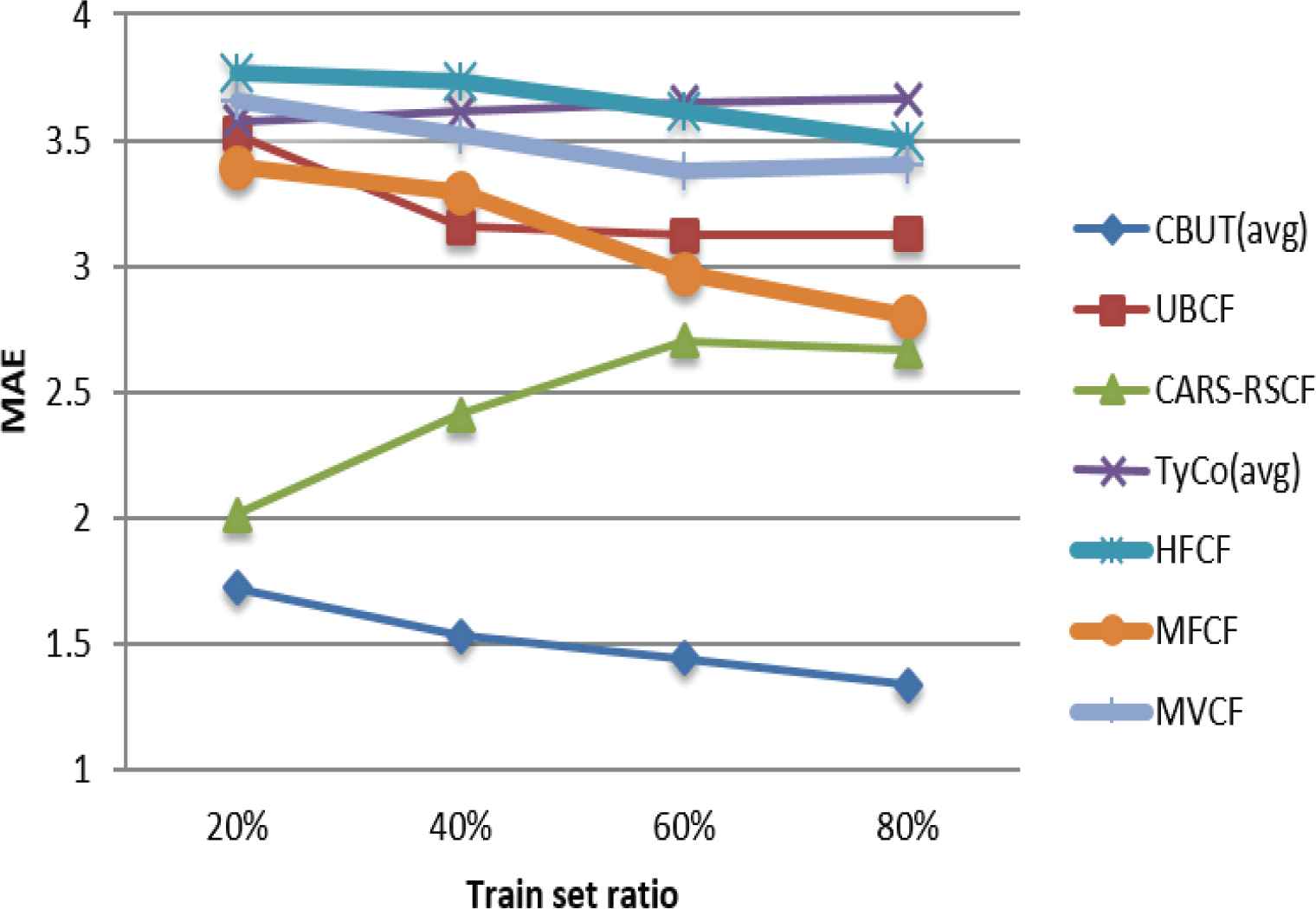
Comparison of MAE using LDOS-CoMoDa in different train set ratios.
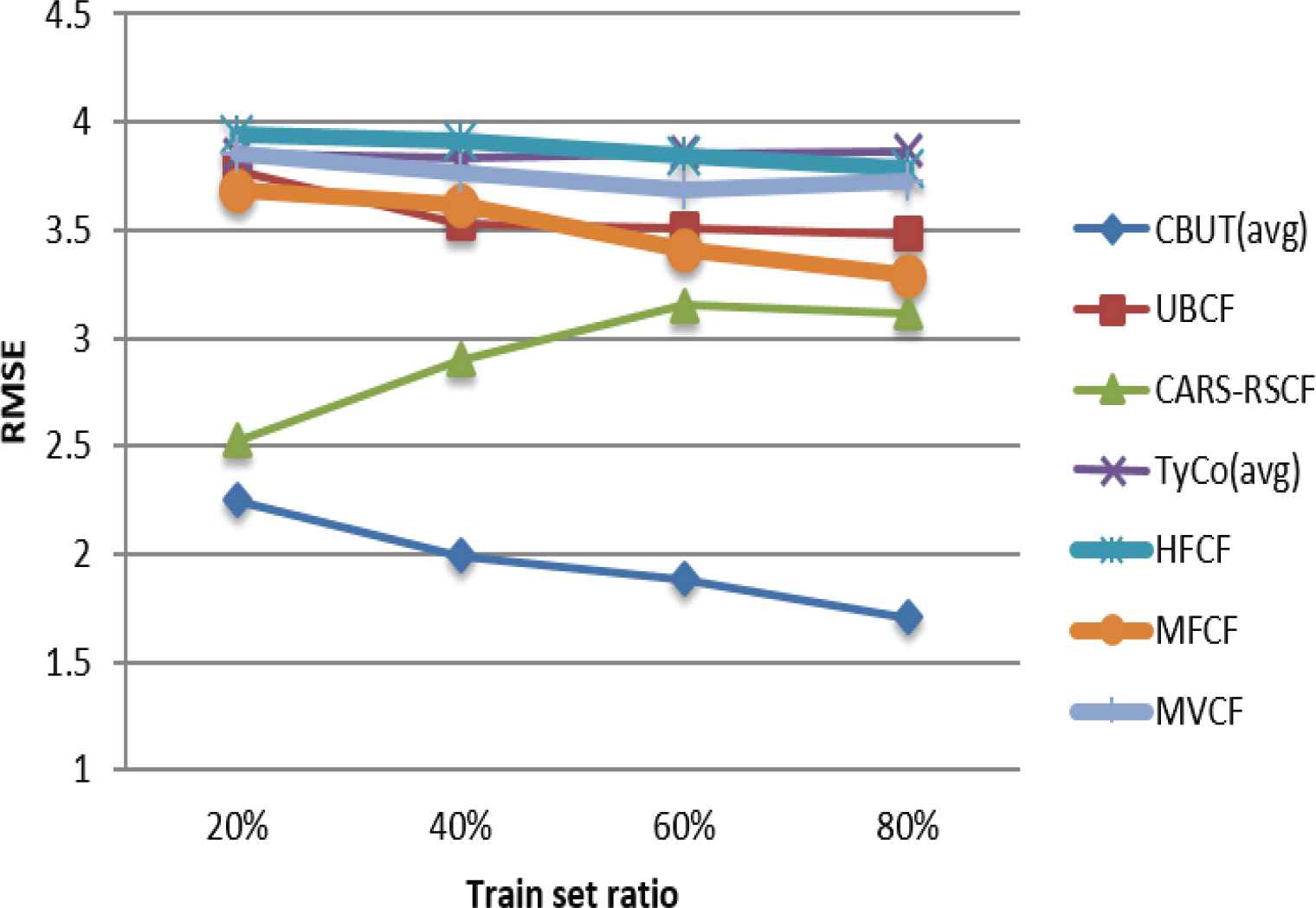
Comparison of RMSE using LDOS-CoMoDa in different train set ratios.
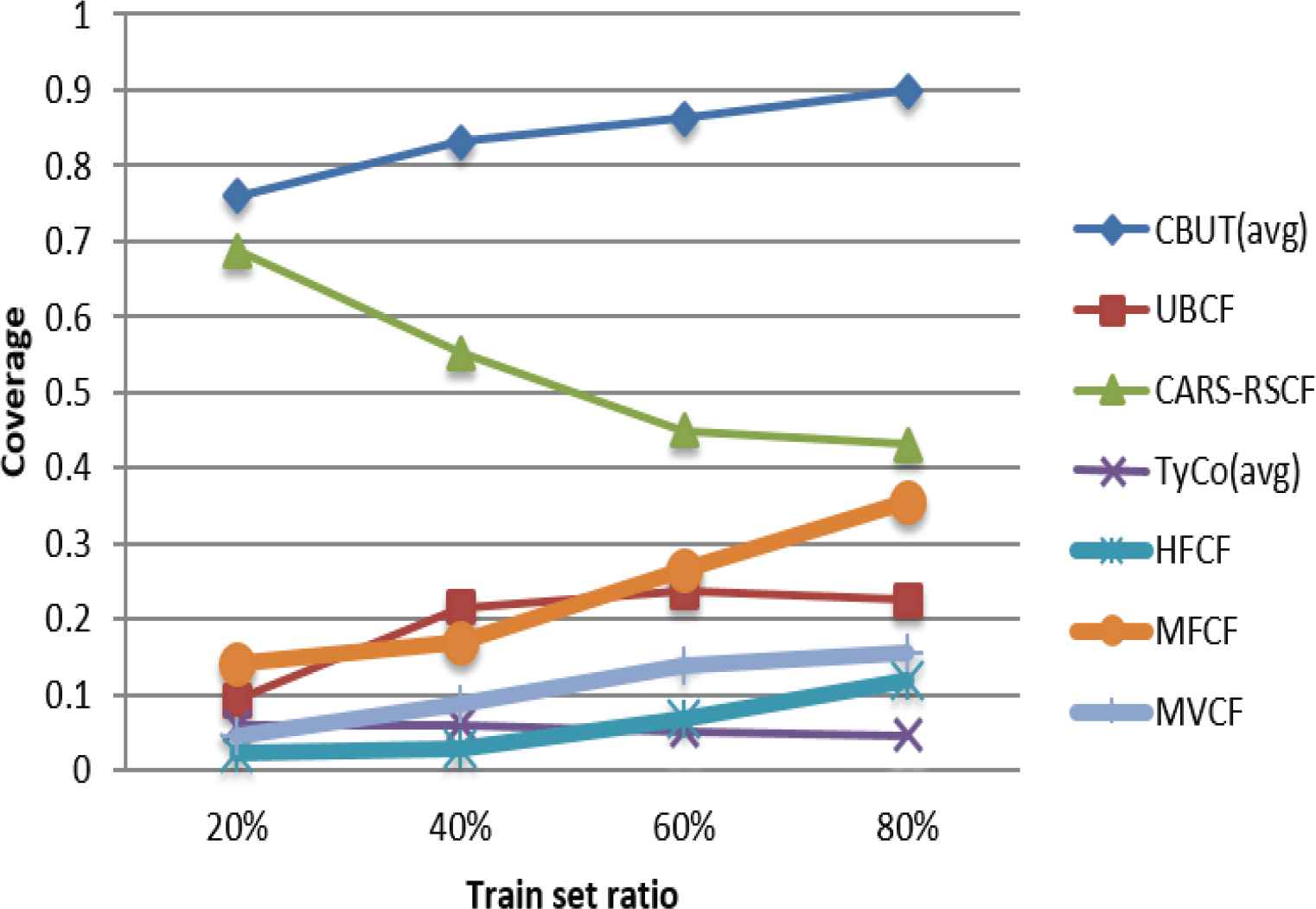
Comparison of Coverage using LDOS-CoMoDa in different train set ratios.
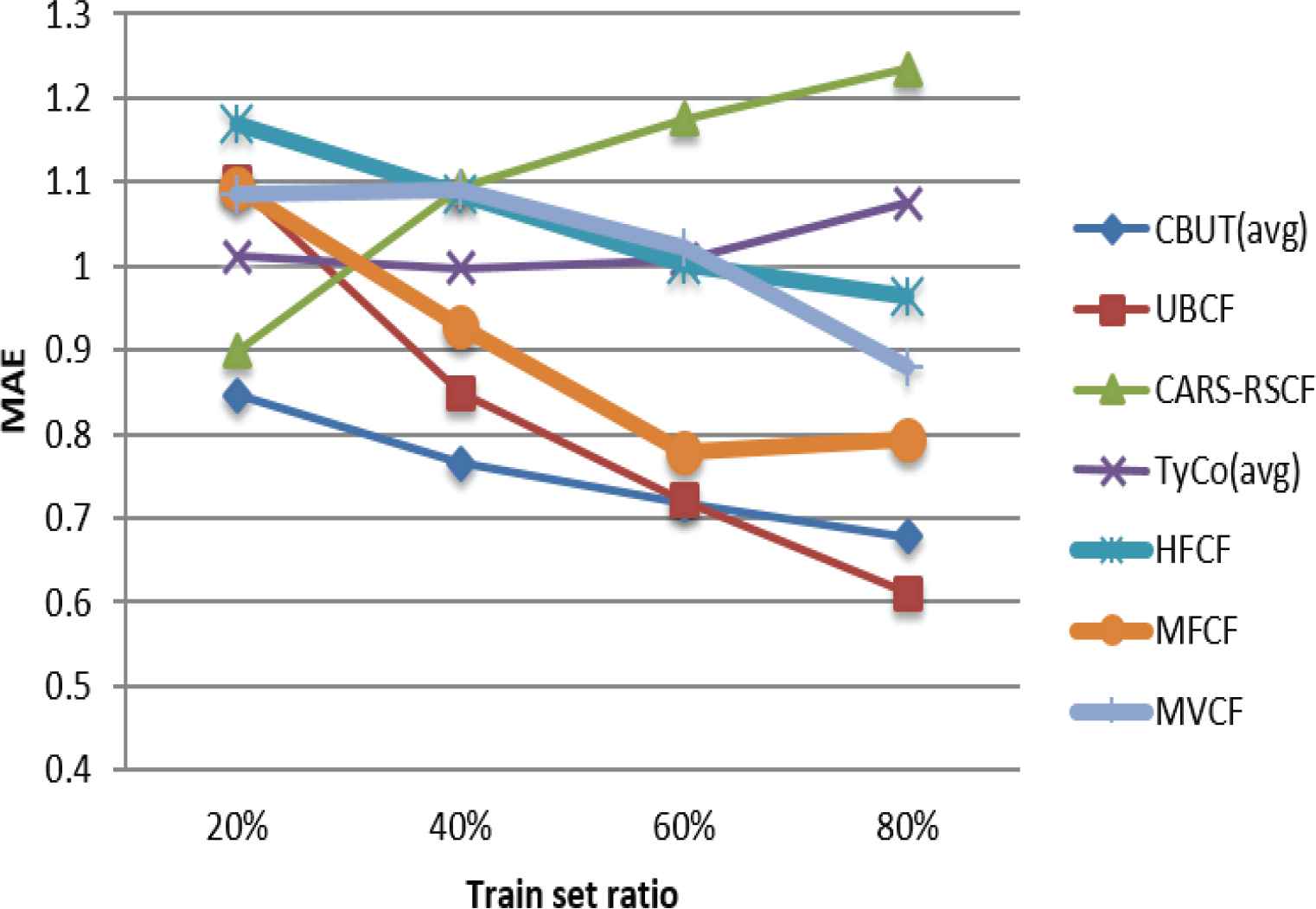
Comparison of MAE using C-R & C in different train set ratios.
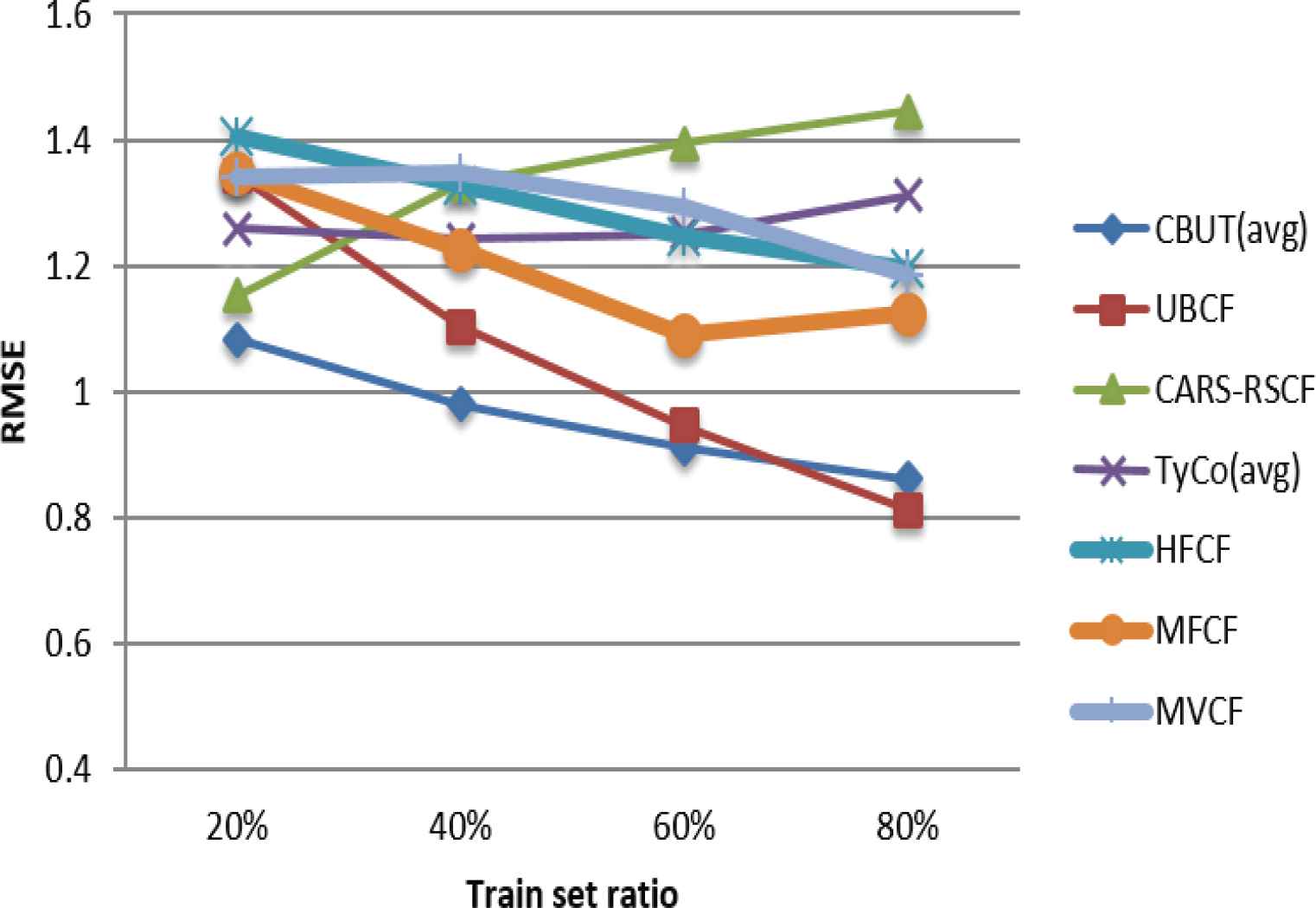
Comparison of RMSE using C-R & C in different train set ratios.
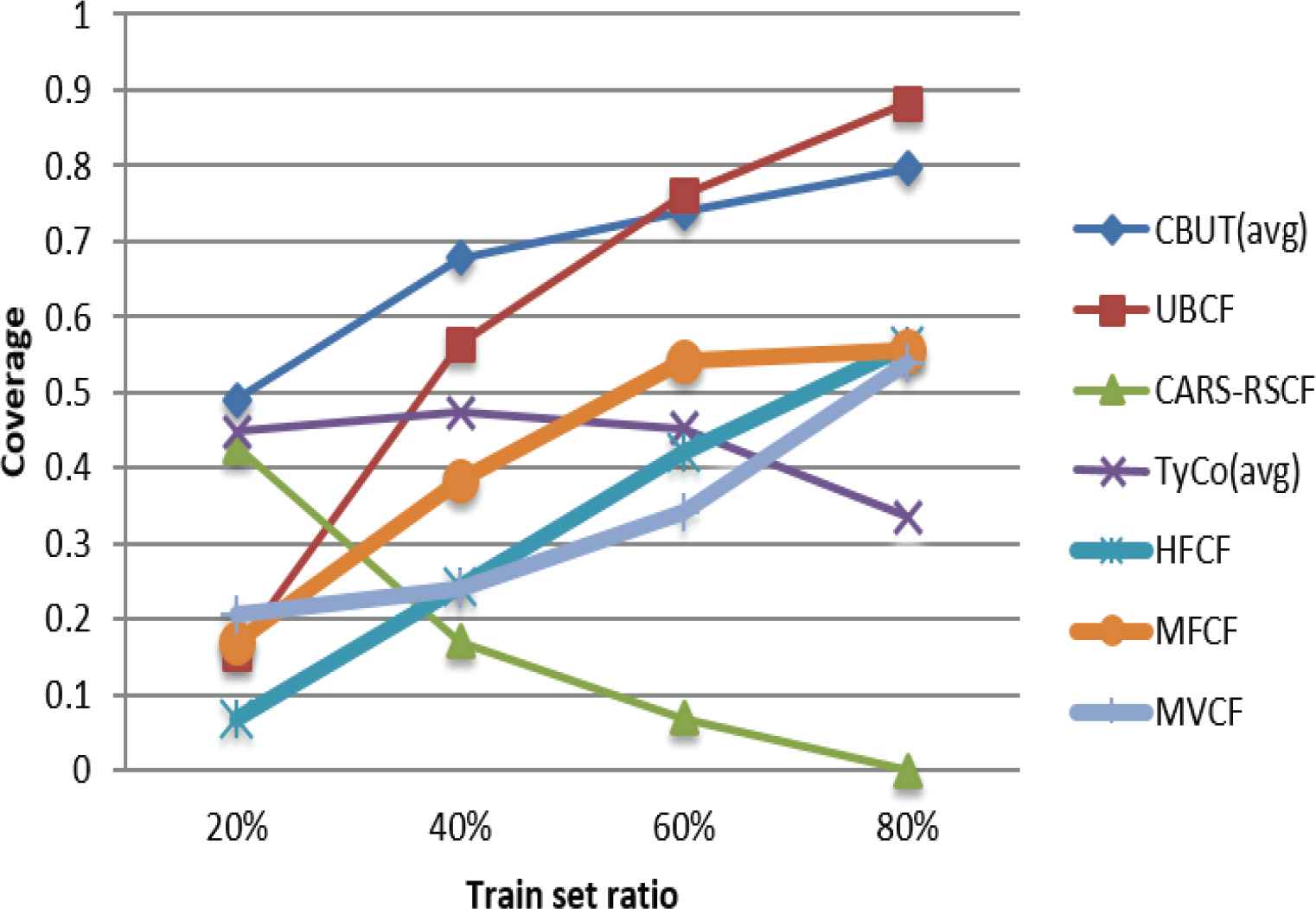
Comparison of Coverage using C-R & C in different train set ratios.
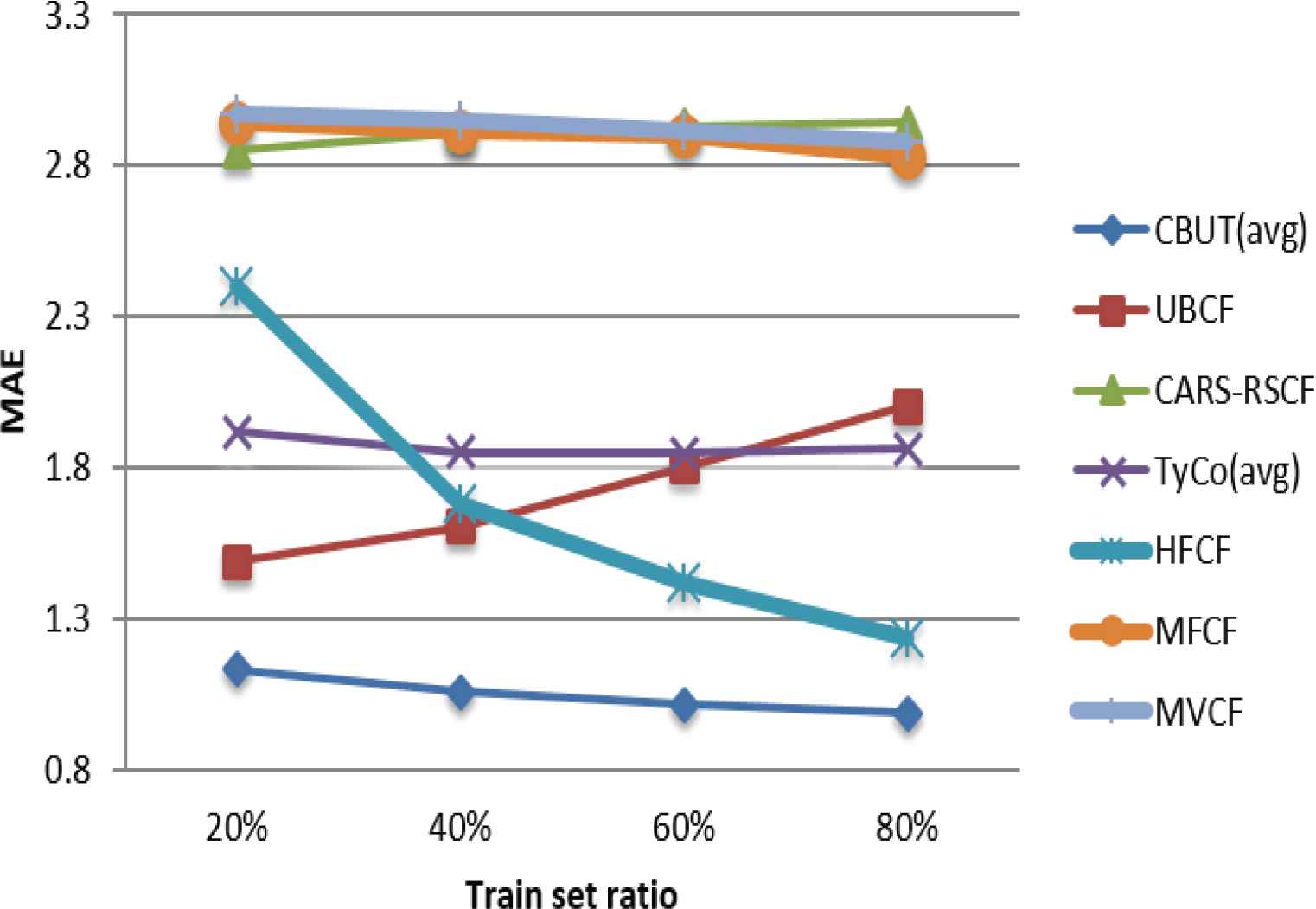
Comparison of MAE using C-Filmtrust in different train set ratios.
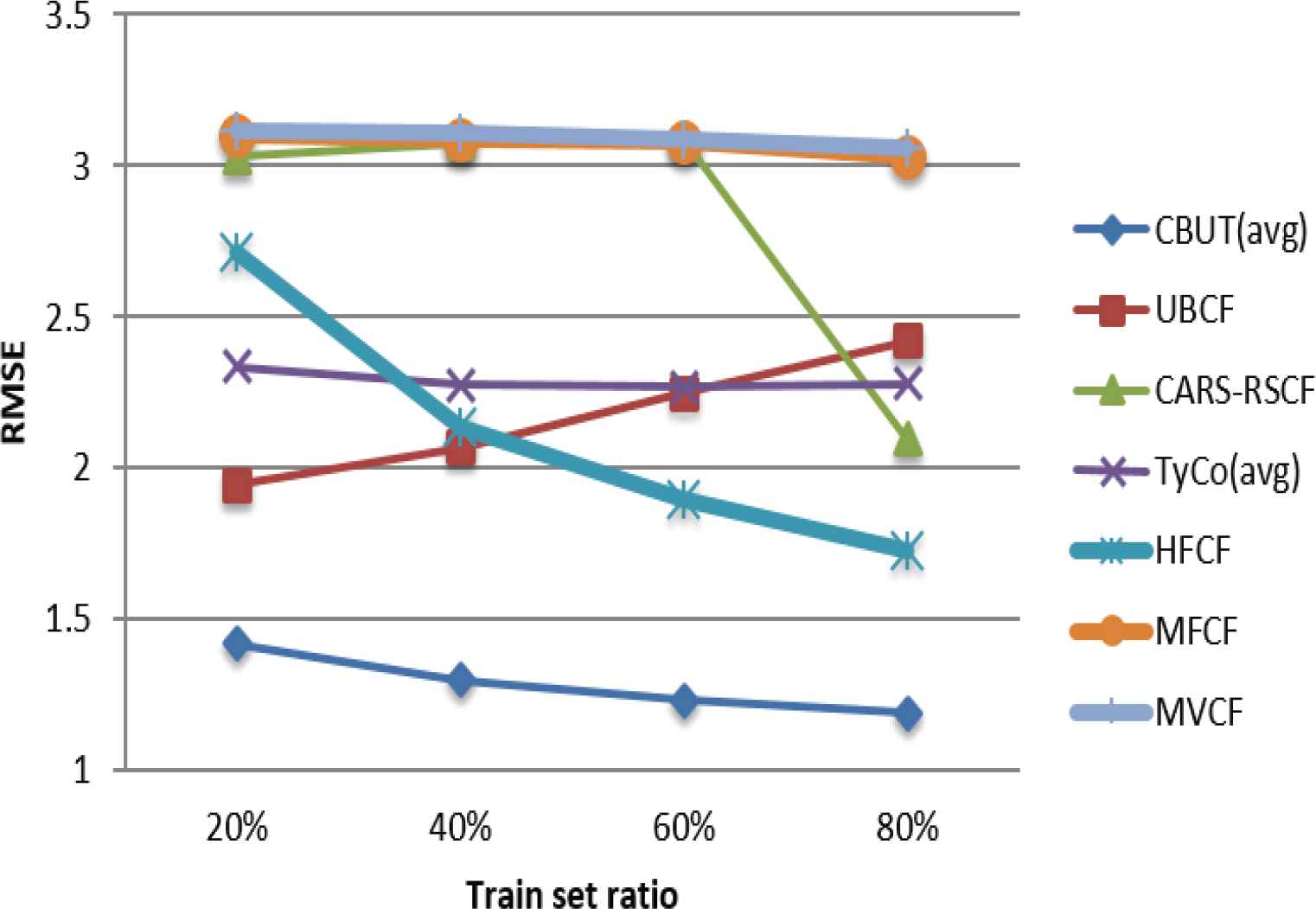
Comparison of RMSE using C-Filmtrust in different train set ratios.
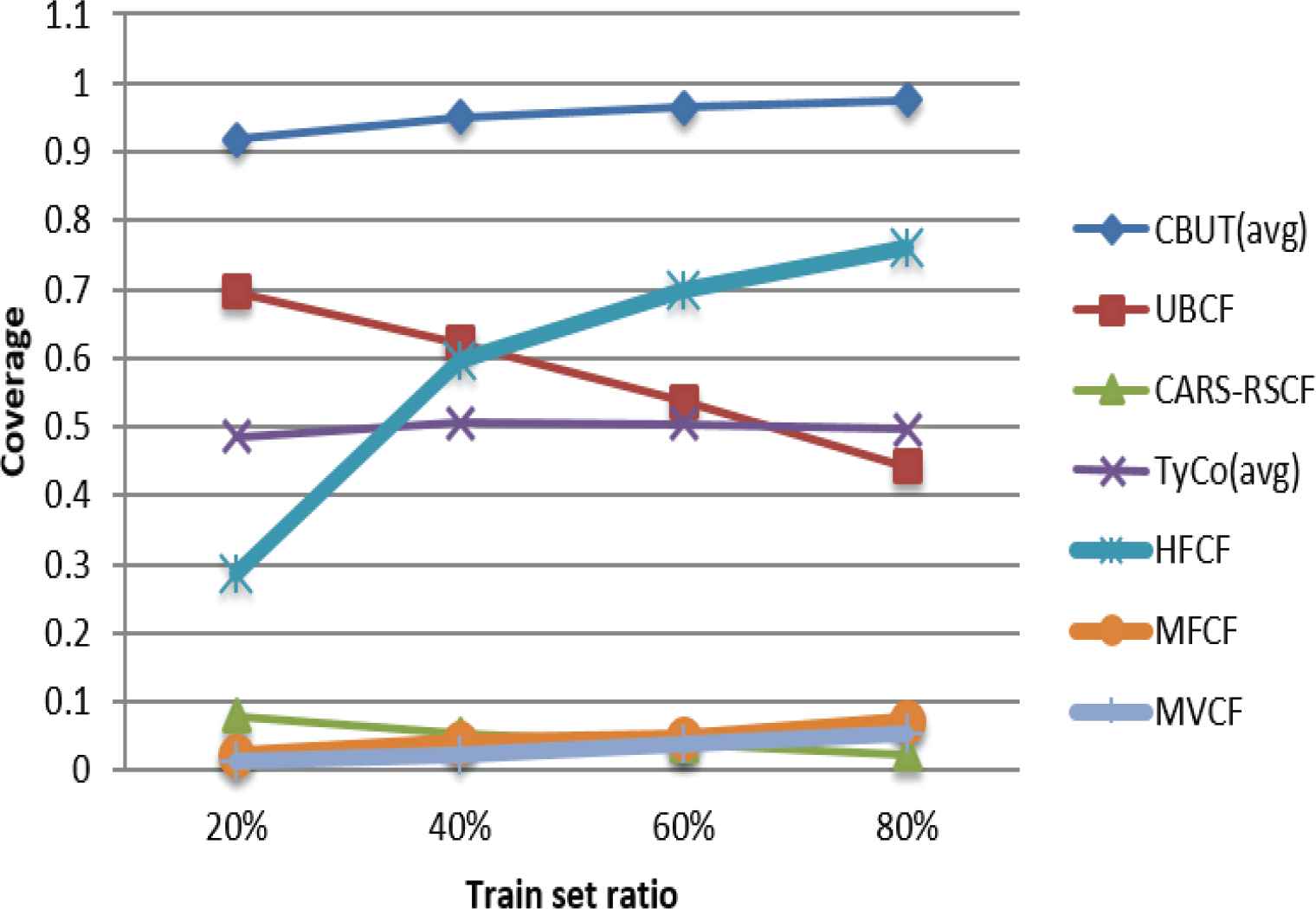
Comparison of Coverage using C-Filmtrust in different train set ratios.
Figures 7–15 illustrate the comparison results of MAE, RMSE, and Coverage for the seven algorithms in four train set ratios under the three data sets. First, the experimental results in Figures 7, 8, 13 and 14 validate that under the LDOS-CoMoDa and C-Filmtrust, the performance of CBUTCF is better than that of the other six algorithms in all train set ratios. Then, the experimental results in Figures 10 and 11, CBUTCF performs only slightly worse than UBCF in 80% train set ratio of the C-R & C; and better than other five algorithms in all train set ratios. This indicates that considering contextual information can effectively improve the recommendation effect, instead of solely relying on the user-item rating information. CBUTCF performs better than CARS-RSCF, which indicates that CBUTCF can effectively alleviate the impact of data sparsity problem. The results in Figures 9 and 15 validate that under the LDOS-CoMoDa and C-Flimtrust, the coverage of CBUTCF is superior to the other six algorithms in all train set ratios. The results in Figure 12 validate that the performance of CBUTCF is not much worse than that of UBCF in 60% and 80% train set ratios of the C-R & C; and in other train set ratios, its performance is better than other five algorithms in all train set ratios. This indicates that considering the contextual information can effectively improve the recommendation coverage. Additionally, CBUTCF is better than CARS-RSCF, which indicates that the combination of context information and user typicality can improve the coverage. The experimental results validate that CBUTCF has clear advantages in optimizing the prediction accuracy and improving item coverage, which confirms the effectiveness and better reliability of CBUTCF.
6. CONCLUSIONS
To consider the impact of contextual information on user typicality, this study proposed a context-based user typicality CF recommendation algorithm, named CBUTCF, considering the different preference of users for item types in different context environments. This algorithm combined user typicality with context to measure the preference of users within contextual information. Subsequently, the ‘neighbors’ of the target user can be determined based on context-based user typicality. Then, the significance of context attributes for item types can be to measure through knowledge granulation. Finally, the algorithm can predict the unknown ratings based on the context combination of the target user. The experimental results on two data sets demonstrated that CBUTCF could effectively improve the recommendation accuracy and coverage of sparse data.
For future work, we plan to incorporate users’ social information and rating information to better determine ‘neighbors’ of target users, thereby improving recommendation performance by alleviating data sparsity problem. Additionally, it is also interesting to consider items that users hate in common, which may be different from similar preference of users.
CONFLICTS OF INTEREST
The authors declare they have no conflicts of interest.
AUTHORS’ CONTRIBUTION
Jinzhen Zhang contributed in methodology, formal analysis, validation, data curation, coding, writing - original draft. Qinghua Zhang contributed in conceptualization, methodology, formal analysis, writing - review & editing. Zhihua Ai contributed in methodology, investigation and coding. Xintai Li contributed in methodology, investigation.
ACKNOWLEDGMENTS
This work was supported by the National Key Research and Development Program of China (No. 2020YFC2003502), the National Natural Science Foundation of China (No. 61876201), and the Foundation for Innovative Research Groups of Natural Science Foundation of Chongqing (No. cstc2019jcyj-cxttX0002).
ETHICAL APPROVAL
This article does not contain any studies with human participants or animals performed by any of the authors.
REFERENCES
Cite this article
TY - JOUR AU - Jinzhen Zhang AU - Qinghua Zhang AU - Zhihua Ai AU - Xintai Li PY - 2021 DA - 2021/06/20 TI - Context-Based User Typicality Collaborative Filtering Recommendation JO - Human-Centric Intelligent Systems SP - 43 EP - 53 VL - 1 IS - 1-2 SN - 2667-1336 UR - https://doi.org/10.2991/hcis.k.210524.001 DO - 10.2991/hcis.k.210524.001 ID - Zhang2021 ER -