
H2Rec: Homogeneous and Heterogeneous Network Embedding Fusion for Social Recommendation
 , Cheng Liu
, Cheng Liu- DOI
- 10.2991/ijcis.d.210406.001How to use a DOI?
- Keywords
- Homogeneous information network; Heterogeneous information network; Network embedding; Social recommendation
- Abstract
Due to the problems of data sparsity and cold start in traditional recommendation systems, social information is introduced. From the perspective of heterogeneity, it reflects the indirect relationship between users, and from the perspective of homogeneity, it reflects the direct relationship between users. At present, most social recommendation is based on the homogeneity or heterogeneity of social networks. Few studies consider both of them at the same time, and the deep structure of social networks is not extensively exploited and comprehensively explore. To address these issues, we propose a unified H2Rec model to fuse homogeneous and heterogeneous information for recommendations in social networks. Considering the rich semantics reflected by metapaths in heterogeneous information and the wealth of social information reflected by homogeneous information, the proposed method uses a random walk strategy to generate node sequences in a homogeneous information network and a random walk strategy guided by metapaths to generate node sequences in a heterogeneous information network (HIN). Finally, we combine the two parts into a unified model for social recommendation. Extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed model.
- Copyright
- © 2021 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
With the rapid development of information technology and Internet technology, people have entered the era of information overload from the era of lack of information. The recommendation system and search engines plays an important role in finding the items that target users are interested in from a large amount of data [1]. The traditional methods (such as matrix factorization (MF) [2]) only utilize the user-item rating matrix for recommendation, that is, whether the user has interactive behavior to the items (such as browsing, attention, rating, etc.); its main purpose is to learn an effective prediction function to describe the user-item interaction record (such as the user-item rating matrix). Due to the problems of data sparsity, cold start, and system performance, these problems may have a negative impact on the recommendation results. To solve these problems, researchers integrate the social attribute information of users or items (such as social labels [3], interaction information between users [4], user’s individual click behavior [5], and trust relationships between users [6]) as important influencing factors into the traditional recommendation framework and thus propose a social recommendation method [7]. The existing research based on social networks is based on two aspects: social network homogeneity or heterogeneity. It has achieved performance improvement to a certain extent, but it still faces the following problems: how to extensively exploit and comprehensively explore the homogeneous and heterogeneous information in social networks for recommendations.
How to overcome these challenges to further improve recommendation performance has become one of the hot topics in recent studies [8–13]. Although recommender systems have been comprehensively analyzed in the past decade, the study of social-based recommender systems has just started. Aiming at providing a general method for improving recommender systems by incorporating social network information, Ref. [1] proposes a MF framework with social regularization. In view of the exponential growth of information generated by online social networks, social network analysis is becoming important for many Web applications. Following the intuition that a person’s social network will affect personal behaviors on the Web, Ref. [8] proposes a factor analysis approach based on probabilistic MF to solve the data sparsity and poor prediction accuracy problems by employing both users’ social network information and rating records. In Ref. [6], a social recommendation model, SocialMF, is constructed by using matrix decomposition technology, which integrates trust propagation on the basis of the matrix decomposition model. Although these existing studies have achieved good results, most of them utilize a single type of external relationship, and the deep structure hidden in social networks and rating patterns has not been fully explored.
To mine deeper structural information in social networks, as a promising direction, a heterogeneous information network (HIN), consisting of multiple types of nodes and links, has been proposed as a powerful information modeling method [10]. The major challenge of utilizing all different types of information in a HIN is to combine self-rating data with various external information or relationships and learn the importance of each factor. Ref. [11] proposes an MF-based recommendation framework to combine user ratings and various entity similarity matrices defined by meta-path-based similarity functions using the information network. In many scenarios, the entity recommendation problem exists in a HIN environment. Different types of relationships can potentially be used to improve the recommendation quality. In Ref. [12], the author studies the entity recommendation problem in HINs. Specifically, the author proposes combining heterogeneous relationship information for each user differently and aims to provide high-quality personalized recommendation results using user implicit feedback data and personalized recommendation models. To take full advantage of the relationship heterogeneity in information networks, the author first introduces meta-path-based latent features to represent the connectivity between users and items along different types of paths. Social recommendation methods tend to leverage social relations among users obtained from social networks to alleviate data sparsity and cold start problems in recommender systems. It employs simple similarity information of users as social regularization on users, that is to say, it only puts constraints on users without considering the impact of items for recommendation, and the similarity information of users only stems from social relations of related users; it may not work well for dissimilar users. To overcome the shortcomings of social regularization, Ref. [13] designs a novel dual similarity regularization to impose constraints on users and items with high and low similarities simultaneously. With dual similarity regularization, the author further proposes an optimization function to integrate the similarity information of users and items under different semantic metapaths.
Although HIN-based methods have achieved performance improvement to some extent, existing methods mainly learn a linear weighting mechanism to combine path-based similarities or latent factors without considering the implicit direct relationship between homogeneous information. To address these issues, we propose a unified H2Rec model to fuse homogeneous and heterogeneous information for recommendations in social networks. Considering the rich semantics reflected by metapaths in heterogeneous information and the wealth of social information reflected by homogeneous information, the proposed method uses a random walk strategy to generate node sequences in a homogeneous information network and a random walk strategy guided by metapaths to generate node sequences in a HIN. For each metapath, we learn a unique embedding representation for a node by maximizing its cooccurrence probability with neighboring nodes in the sequences sampled according to the given metapath. Finally, we combine the two parts into a unified model for social recommendation. Extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed model. Then, we take multiple embedding fusion as the output of network information embedding. Finally, we extend the classic MF framework by incorporating fused network information embedding. The prediction model and the fusion function are jointly optimized for the rating prediction task.
By integrating the above two parts together, this work presents a novel network information embedding-based recommendation approach, called H2Rec. We present an overall illustration of the proposed approach in Figure 1. Extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed approach. We also verify the ability of H2Rec to alleviate the cold start problem. The key contributions of this paper can be summarized as follows.
For the first time, homogeneous and heterogeneous information networks are considered at the same time, and the deeper relationships in network information are extensively and comprehensively mined.
We propose a novel network information embedding for recommendation models, called H2Rec. H2Rec can effectively integrate various kinds of embedding information in social networks to enhance recommendation performance.
Extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed model. Moreover, we reveal that the transformed embedding information from homogeneous and heterogeneous information networks can improve the recommendation performance.
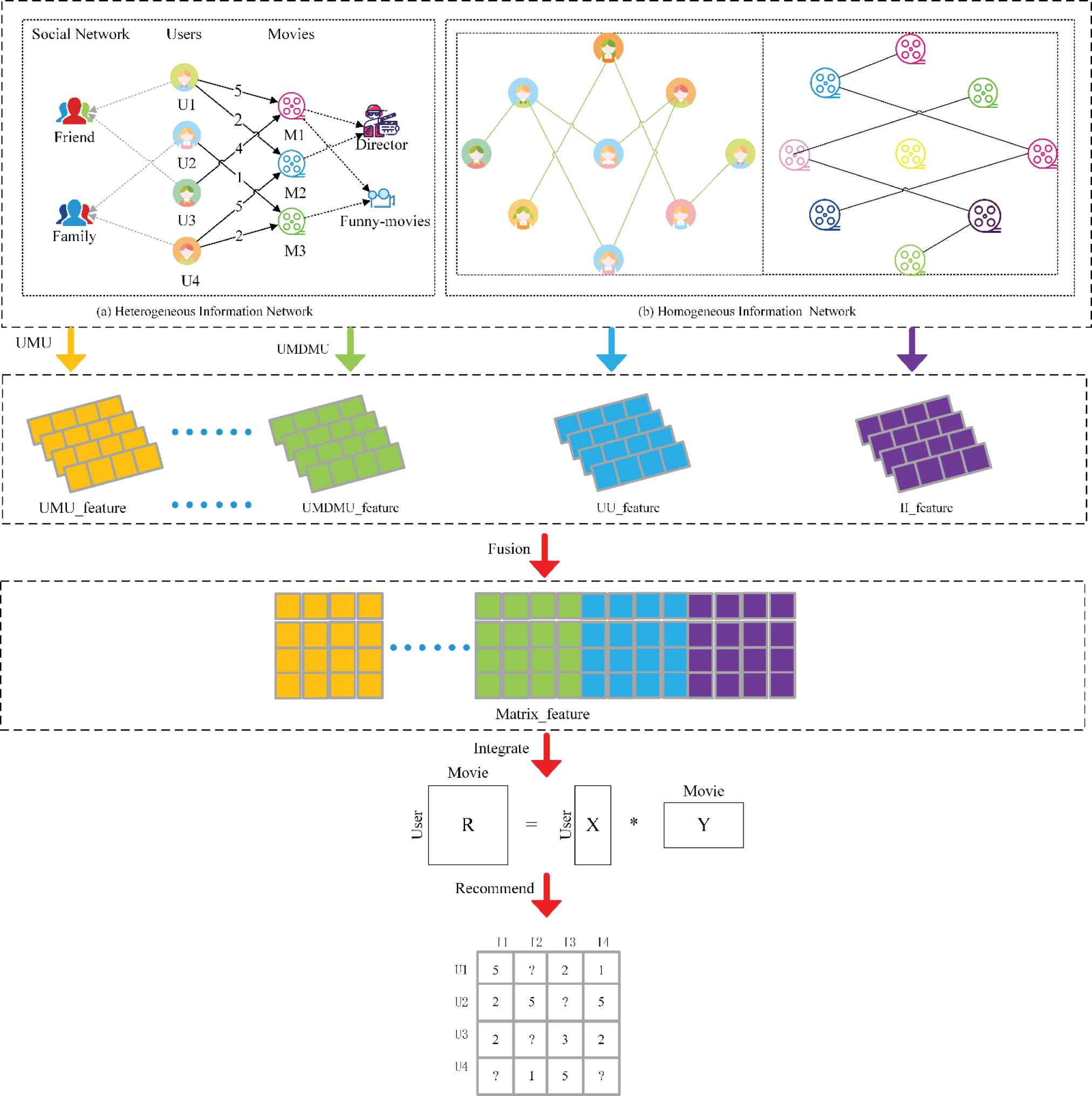
Schematic illustration of the proposed H2Rec approach.
2. RELATED WORK
Recommender systems belongs to a subclass of information system, and its popularity has increased rapidly in recent years. Although they were initially conceived to cover the field of e-commerce, today they have successfully expanded to various scenarios, such as e-government, e-business, e-commerce/e-shopping, e-library, e-learning, e-tourism, e-resource services, and e-group activities. The aim of recommendation system is to provide personalized recommendation for online products and services to overcome the increasingly serious problem of information overload [14]. Traditional recommendation systems mainly include content-based recommendation, collaborative filtering (CF) recommendation and hybrid recommendation [15]. Furthermore, recent surveys like the one conducted by Ref. [16] have enlightened us on the use of fuzzy techniques for supporting recommender systems.
In the literature on recommender systems, early works mainly adopt CF methods to utilize historical interactions for recommendations [17]. Particularly, the MF approach [2,18] has shown its effectiveness and efficiency in many applications, which factorizes the user-item rating matrix into two low-rank user-specific and item-specific matrices and then utilizes the factorized matrices to make further predictions. In related research on recommendation systems, the early recommendation method is mainly CF [17], which uses historical interactions for recommendations. CF technology can be divided into memory-based CF and model-based CF according to whether machine learning is adopted. In model-based CF technology, MF [2] is the most popular because of its excellent scalability and easy implementation. It shows its effectiveness and efficiency in many applications by decomposing the user-item rating matrix into two small matrices containing hidden variables, one representing the user’s implicit characteristics and the other representing the implicit features of the item, and then utilizes the factorized matrices to make further predictions. Since CF methods usually suffer from cold start problems, many works attempt to leverage additional information to improve recommendation performance. Ref. [18] considers the information of both ratings and reviews and proposes a unified model to combine content-based filtering with CF for rating prediction tasks. Ref. [6] added a trust propagation mechanism to MF and proposed a recommendation matrix decomposition technology based on trust propagation. An increasing number of studies have begun to use friend relations among users. In Ref. [1], the additional social regularization term ensures that the distance of latent feature vectors of two friends with similar tastes becomes closer. Membership among users is also explored to boost CF [19].
On the other hand, the deep learning-based embedding technique has shown its power in many recommendation tasks with its capability of extracting hierarchical representations from raw data. Ref. [20] showed how to train distributed representations of words and phrases with the skip-gram model. Inspired by the success of word embedding models, Ref. [21] learned item embeddings using the sets of items each user had consumed and further proposed a cofactorization model to jointly decompose the user-item interaction matrix and the item-item cooccurrence matrix with shared item latent factors. As embedding methods have the capability of extracting hierarchical representations from raw data, many researchers have also tried to incorporate these extracted factors into recommender systems. For example, Ref. [22] presented a novel perspective to address the recommendation task by utilizing network representation learning techniques, which first transforms the adoption records into a k-partite adoption network and then applies the network embedding approach to learn vertex embeddings. Embeddings for different kinds of information are projected into the same latent space, where we can easily measure the relatedness between multiple vertices on the graph using some similarity measurements. In this way, the recommendation task has been cast into a similarity evaluation process using embedding vectors. To leverage the knowledge extracted from social networking sites for cross-site cold-start product recommendation, Ref. [23] learned both user and item feature representations from e-commerce websites using recurrent neural networks and then developed a feature-based MF approach to leverage the learned user embeddings for cold-start product recommendation. Most existing relation-based CF methods usually utilize information from single or multiple homogeneous networks that only have a single type of node and link. However, the widely available attribute information of users and items is useful for recommendations, which is seldom exploited in this kind of method.
To mine deeper structural information in social networks, as a promising direction, a HIN, consisting of multiple types of nodes and links, has been proposed as a powerful information modeing method. As a unique characteristic of HINs, metapaths not only represent rich semantics but can also be utilized to integrate different types of information in HINs. It is a challenge for the HIN to know how to deeply mine the semantic meanings of the information network. For meta-path-based data mining, researchers have performed much work, including clustering [24], classification [25], and link prediction [26]. Among these research works, the similarity measure in HIN is an important and basic function, so many methods based on path similarity measurement have been proposed. For example, the concept of metapath similarity is introduced in Ref. [27]; it defines a novel similarity measure called PathSim that is able to find peer objects in the network (e.g., find authors in a similar field and with similar reputations), which turns out to be more meaningful in many scenarios than random-walk-based similarity measures. Based on the idea that two objects are related if they are referenced by related objects, Ref. [28] proposes a general framework, called HeteSim, to evaluate the relatedness of heterogeneous objects in heterogeneous networks. HeteSim is a path-based relevance measure that can effectively capture the subtle semantics of search paths. Based on the pairwise random walk model, HeteSim treats arbitrary search paths in a uniform way, which guarantees the symmetric property of HeteSim.
Network embedding has shown potential in structural feature extraction and has been successfully applied to many data mining tasks. DeepWalk [29] is a relatively basic algorithm for network representation learning. It combines random walk and skip-gram to learn the vector representation of nodes in the network (w.r.t the structural feature of the learning graph w.r.t the attribute, and the number of attributes is the dimension of the vector) so that the traditional machine learning algorithm can be used to solve related problems. To embed HINs, Ref. [30] designed a meta-path-based random walk strategy to generate meaningful node sequences for network embedding. Ref. [31] presents a novel idea on network representation learning, termed heterogeneous network embedding (HNE), which jointly considers both the content and relational information. HNE maps different heterogeneous objects into a unified latent space so that objects from different spaces can be directly compared. Ref. [32] proposes a new representation learning framework HIN to vector (hin2vec). The core of this framework is a neural network model that aims to capture rich semantics embedded in HIN by using different types of relationships between nodes. Although these methods can learn network embedding in various heterogeneous networks, the traditional HIN-based recommendation does not consider the direct relationship between nodes implied in homogeneous information networks, which may be very important in some applications. This paper proposes a method based on the integration of homogeneous and heterogeneous networks and discusses its benefits to the recommendation system.
3. PRELIMINARY
The recommendation scenario in social networks is shown in Figure 2, which consists of two central elements: the network diagram of the social relationship between users and the network diagram of the relationship between items.
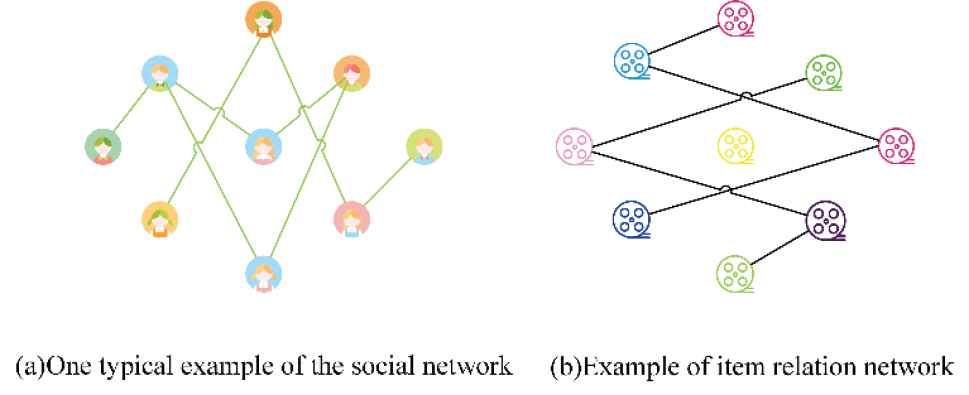
Example of the recommendation scenario in a social network.
Theorem 1.
(Social Network) [33]: The social network is denoted as
Theorem 2.
(Item Relationship Network): The item relationship network is denoted as
HIN is a special information network, as shown in Figure 3. It contains multiple types of nodes and multiple types of links.
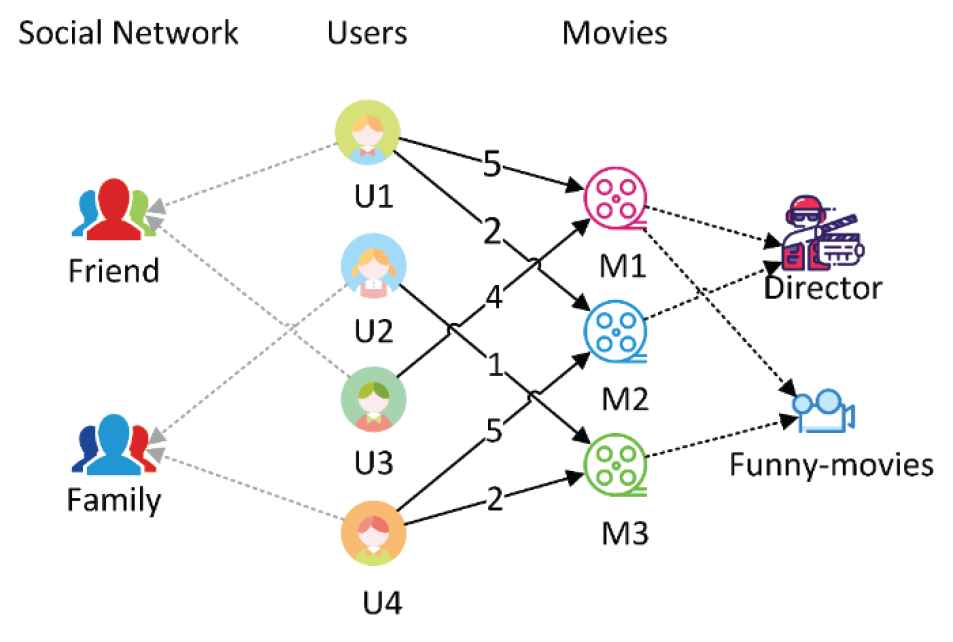
Heterogeneous information network.
Theorem 3.
(HIN) [34]: The HIN is denoted as
Theorem 4.
(Network Schema) [8,35]: The network schema is denoted as
As shown in Figure 4, we show the network schema on the three datasets used in our experiments.
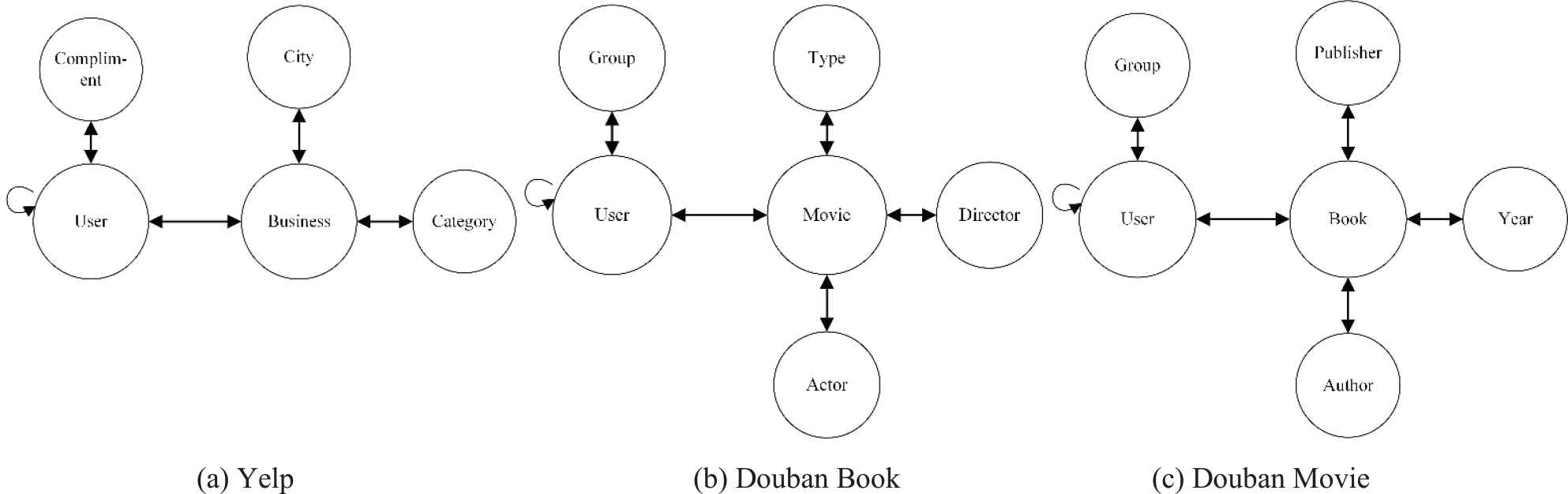
Network schemas of heterogeneous information networks for the three datasets.
Theorem 5.
(Metapath) [27]: Metapath ρ is defined on the network schema
The HIN contains many types of nodes and links. The meaning of the connection of two nodes of the same type can be changed due to the different connection paths. The metapath is composed of a sequence of relationships of different objects, which defines the complex relationship from the first node to the last node in the sequence path. For example, the path User-Movie-User (UMU) represents the user watching the same movie as the target user, while the path User-Movie-Type-Movie-User (UMTMU) represents the user watching the same type of movie as the target user. In Table 1, we give the definition and semantic description of metapaths under the three data types used in this paper.
| (a) Yelp | |
|---|---|
| Meta-paths | Semantic Meaning |
| UBU | users who review the same business with the target user |
| UBCiBU | users who review businesses in the same city with the target user |
| UBCaBU | users who review the same type of business with the target user |
| BUB | businesses reviewed by the same user with the target business |
| BCiB | businesses in the same city with the target business |
| BCaB | businesses of the same type with the target business |
| (b) Douban Movie | |
| Meta-paths | Semantic Meaning |
| UU | friends of the target user |
| UMU | users who view the same movies with the target user |
| UMTMU | users who view the movies having the same types with that of the target user |
| UMDMU | Users who watch movies directed by the same director with the target user |
| MUM | movies watched by the same user with the target movie |
| MDM | movies directed by the same director with the target movie |
| MAM | movies played by the same actor with the target movie |
| MTM | movies of the same type with the target movie |
| (c) Douban Book | |
| Meta-paths | Semantic Meaning |
| UBU | Users who read the same book as the target user |
| UBPBU | Users who read books published by the same publisher as the target user |
| UBYBU | Users who read books published in the same year as the target user |
| UBABU | Users who read books written by the same author as the target user |
| BUB | Books read by the same user as the target book |
| BPB | Books published by the same publisher as the target book |
| BYB | Books published in the same year as the target book |
The semantic meanings of different meta-paths for the used three datasets.
4. COMBINED WITH NETWORK EMBEDDING FACTORS
Learning useful representations from highly structured objects is useful for various machine learning applications. In addition to reducing engineering workload, these representations can also lead to greater predictive power. Inspired by the recent progress in network embedding research, we use representation learning methods to extract and represent useful information in the information network for recommendation. Ref. [36] proposed an algorithm framework, node2vec, for graph representation learning. For any given graph, the framework can learn the continuous feature representation of nodes, which can then be used for various downstream machine learning tasks.
4.1. Node2vec Algorithm
4.1.1. Random walk
To generate meaningful node sequences, the key is to design an effective random walk strategy that can capture the complex semantics reflected in the network. Formally, given a source node
4.1.2. Optimization objective
Let
4.2. Embedding of Homogeneous Information Networks
4.2.1. Generate node sequence based on random walk
First, we propose a basic recommendation model based on homogeneous networks, which is based on the embedding of connected users (items). Since the output of node2vec can be interpreted as a high-level representation of network nodes, we pretrain node2vec to mine the deep social structure of a given social network
4.2.2. Node embedding representation
According to node2vec, we can learn the representation of nodes by optimizing Eq. (2). Let
4.3. Embedding of HINs
4.3.1. Meta-path-based random walk
To generate meaningful node sequences, the key is to design an effective walking strategy that can capture the complex semantics reflected in HINs. Therefore, we adopt a random walk method based on metapaths to generate node sequences. Given a HIN
4.3.2. Remove noise nodes
Since we are concerned about improving recommendation performance, we only need to focus on learning the effectiveness of users and the items themselves. For other types of nodes, we do not pay much attention to the improvement of our recommendation performance. Therefore, we need to denoise after forming the metapath. In this way, the final sequence we obtain is only composed of user node types or item node types, that is, a sequence composed of homogeneous nodes. The connection between homogeneous nodes is essentially constructed through heterogeneous neighboring nodes. As shown in Figure 5, we show the specific denoising process. To learn the effective representation of users and items, only metapaths whose starting type is user type or item type are considered. In this way, some metapaths can be derived, such as UMU, UMDMU, and MUM; taking the metapath of UMU as an example, a sampling sequence can be generated
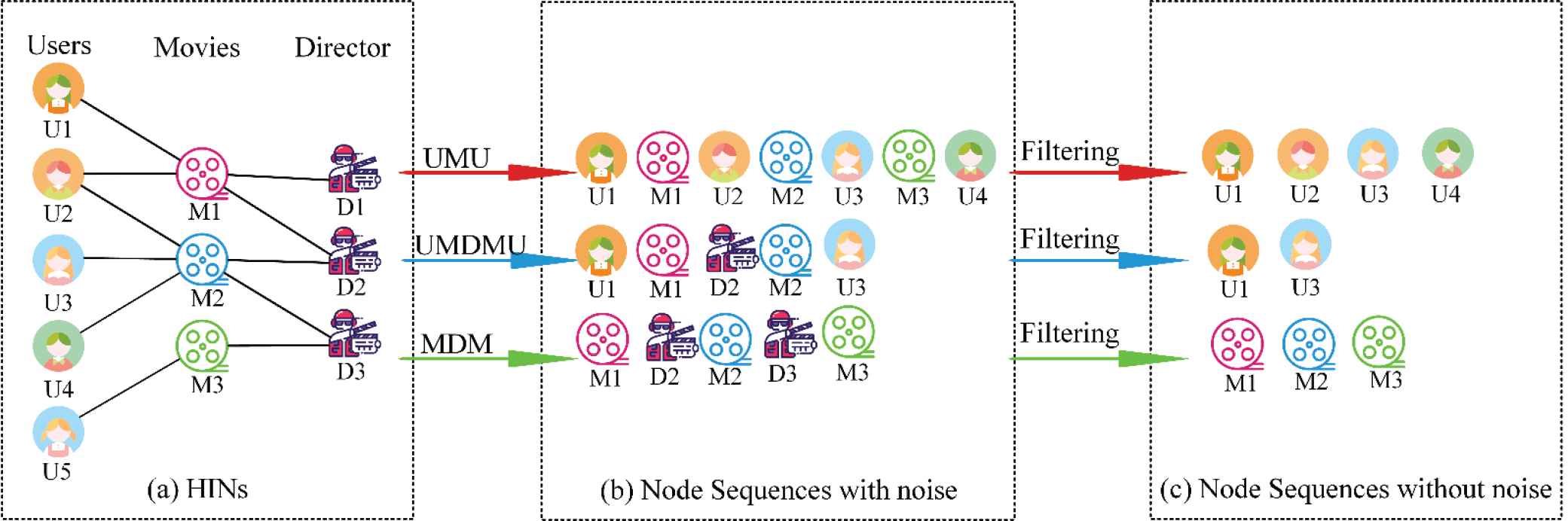
The process of removing noise nodes.
4.3.3. Node embedding representation
Given the metapath, we can construct the domain node set
4.4. Fusion of Homogeneous and Heterogeneous Network Embedding
After learning about the node representations of homogeneous networks and heterogeneous networks, the next step is to fuse these learned node representations. In our model, we designed a function
5. THE PROPOSED APPROACH
5.1. Matrix Factorization
CF is one of the most popular and classic technologies in recommender systems. It is based on the assumption that if users have been interested in some items in the past, they may still be enthusiastic about them in the future. CF technology can be divided into memory-based CF and model-based CF according to whether machine learning is adopted. Among the model-based CF technologies, MF [2] is the most common and popular technology. Because of its excellent scalability and easy implementation, to learn potential factors from user rating data, we introduce MF as our basic recommendation framework.
The MF model maps users and items to a joint latent factor space of dimension f so that user-item interactions are modeled as inner products in this space. Correspondingly, for each item
5.2. H2Rec Model
After we learned the node embedding representation of the information network, according to the node embedding, we can further obtain the user’s embedding representation
5.2.1. Integrating MF with network embedding for recommendation
MF decomposes the user-item rating matrix into two small matrices containing hidden variables, one representing the hidden features of the user and the other representing the hidden features of the item, and then uses the decomposed matrix to make further predictions. In MF, the score prediction of user
We blend the fusion function into a MF framework for learning the parameters of the proposed model. The objective can be formulated as follows:
6. EXPERIMENT AND RESULTS
In this chapter, we use three real datasets (Yelp,1 Douban Movies2 and Douban Book3) to experiment with our H2Rec model to verify the effectiveness of the model.
6.1. Datasets
To verify that our model can demonstrate its effectiveness in different fields, we used three datasets from different fields, including the Yelp dataset from the business field, the Douban book dataset from the book field, and the Douban movie ratings dataset from the movie field. The Yelp dataset records the user ratings of local businesses and contains the social relationship and attribute information of the businesses, including 16,239 users and 14,282 local businesses, and 198,397 rating datapoints from 1 to 5; the Douban Books dataset, which includes 13,024 users and 22,347 books and 792,026 ratings datapoints from 1 to 5; and the Douban movie dataset includes 13,367 users and 12,677 movies and 1,068,278 movie ratings datapoints from 1 to 5. In addition, in Table 2, we provide a detailed description of the three datasets in the experiment.
| Dataset | Density (%) | Relations (A-B) | Number of A | Number of B | Number of (A-B) |
|---|---|---|---|---|---|
| Yelp | 0.08 | User-Business | 16239 | 14284 | 198397 |
| User-User | 10580 | 10580 | 158590 | ||
| User-Compliment | 14411 | 11 | 76875 | ||
| Business-City | 14267 | 47 | 14267 | ||
| Business-Category | 14180 | 511 | 40009 | ||
| Douban Book | 0.27 | User-Book | 13024 | 22347 | 792026 |
| User-User | 12748 | 12748 | 169150 | ||
| Book-Author | 21907 | 10805 | 21905 | ||
| Book-Publisher | 21773 | 1815 | 21773 | ||
| Book-Year | 21192 | 64 | 21192 | ||
| Douban Movie | 0.63 | User-Movie | 13367 | 12677 | 1068278 |
| User-User | 2440 | 2294 | 4085 | ||
| User-Group | 13337 | 2753 | 570047 | ||
| Movie-Director | 10179 | 2449 | 11276 | ||
| Movie-Actor | 11718 | 6311 | 33587 | ||
| Movie-Type | 12678 | 38 | 27668 |
Statistics of the three datasets of our experiment.
6.2. Evaluation Metrics
In the recommendation system, there are three main experimental methods to obtain different indicators, namely, offline experiments, user studies, and online experiments. In the application, the recommendation system can be divided into top-N recommendations and scoring recommendations according to the scene. The scoring recommendation is generally calculated by root mean square error (RMSE) and absolute average (MAE). Among them, RMSE has increased the penalties for inaccurate items, and the evaluation has become more stringent. In this experiment, we mainly use RMSE and MAE to evaluate the recommended performance of different models. The metrics MAE and RMSE are defined as follows:
6.3. Models for Comparison
We consider the following methods to compare:
PMF [33]: This algorithm is a CF recommendation algorithm based on MF. It explicitly decomposes the rating matrix into two low-dimensional matrices.
SoMF [1]: This method aims to provide a general approach for improving the recommendation system by combining social network information and proposes a MF framework with social regularization.
HeteMF [34]: This method proposes a recommendation framework based on MF to combine user ratings and use information networks to define various entity similarity matrices based on meta-path-based similarity functions.
SemRec [35]: This is a CF method on a weighted HIN, which is constructed by connecting users with items of the same level. It can not only flexibly integrate heterogeneous information but also obtain priority and personalized weights that represent user preferences on the path.
DSR [13]: This method designs a novel dual similarity regularization to impose constraints on users and items with high and low similarities simultaneously.
H2Rec: This is the proposed recommendation model based on the embedding fusion of homogeneous and heterogeneous information networks.
6.4. Results
First, we divide the three datasets into a training set and a test set and set the five training ratios of the datasets Douban Movie and Douban Book to {20%, 40%, 60%, 80%}. Since the Yelp dataset is very sparse, its five training ratios are set to {60%, 70%, 80%, 90%}. For each ratio, we randomly generate ten evaluation sets. We average the results as the final performance. The experimental results are shown in Table 3. For conducting a more intuitive analysis, the line chart (see Figure 6) was drawn based on the data from Table 3.
| Dataset | Training | Metrics | PMF | SoMF | HeteMF | SemRec | DSR | H2RecHIN | H2RecHON | H2Rec |
|---|---|---|---|---|---|---|---|---|---|---|
| Yelp | 90% | MAE | 1.0412 | 1.0095 | 0.9487 | 0.9043 | 0.9054 | 0.8304 | 0.8431 | 0.8213 |
| RMSE | 1.4268 | 1.3392 | 1.2549 | 1.1637 | 1.1186 | 1.0861 | 1.102 | 1.0556 | ||
| 80% | MAE | 1.0791 | 1.0373 | 0.9654 | 0.9176 | 0.9098 | 0.849 | 0.8418 | 0.8265 | |
| RMSE | 1.4816 | 1.3782 | 1.2799 | 1.1771 | 1.1208 | 1.1109 | 1.1053 | 1.0642 | ||
| 70% | MAE | 1.1170 | 1.0694 | 0.9975 | 0.9407 | 0.9429 | 0.8576 | 0.859 | 0.8416 | |
| RMSE | 1.5387 | 1.4201 | 1.3229 | 1.2108 | 1.1582 | 1.124 | 1.1302 | 1.0836 | ||
| 60% | MAE | 1.1778 | 1.1135 | 1.0368 | 0.9637 | 1.0043 | 0.8741 | 0.8687 | 0.8523 | |
| RMSE | 1.6167 | 1.4748 | 1.3713 | 1.238 | 1.2257 | 1.1498 | 1.1405 | 1.0951 | ||
| Douban Movie | 80% | MAE | 0.5741 | 0.5817 | 0.5750 | 0.5695 | 0.5681 | 0.5611 | 0.5616 | 0.5511 |
| RMSE | 0.7641 | 0.7680 | 0.7556 | 0.7399 | 0.7225 | 0.7158 | 0.7164 | 0.6889 | ||
| 60% | MAE | 0.5867 | 0.5991 | 0.5894 | 0.5738 | 0.5831 | 0.5658 | 0.566 | 0.5549 | |
| RMSE | 0.7891 | 0.7950 | 0.7785 | 0.7551 | 0.7408 | 0.7222 | 0.7224 | 0.6935 | ||
| 40% | MAE | 0.6078 | 0.6328 | 0.6165 | 0.5945 | 0.6170 | 0.5706 | 0.5709 | 0.559 | |
| RMSE | 0.8321 | 0.8479 | 0.8221 | 0.7836 | 0.7850 | 0.7303 | 0.7306 | 0.6995 | ||
| 20% | MAE | 0.7247 | 0.6979 | 0.6896 | 0.6392 | 0.6584 | 0.5899 | 0.5899 | 0.5737 | |
| RMSE | 0.9440 | 0.9852 | 0.9357 | 0.8599 | 0.8345 | 0.7626 | 0.7627 | 0.7198 | ||
| Douban Book | 80% | MAE | 0.5774 | 0.5756 | 0.5740 | 0.5675 | 0.5740 | 0.554 | 0.554 | 0.5459 |
| RMSE | 0.7414 | 0.7302 | 0.7360 | 0.7283 | 0.7206 | 0.702 | 0.702 | 0.6796 | ||
| 60% | MAE | 0.6065 | 0.5903 | 0.5823 | 0.5833 | 0.6020 | 0.5614 | 0.5615 | 0.5528 | |
| RMSE | 0.7908 | 0.7518 | 0.7466 | 0.7505 | 0.7552 | 0.7117 | 0.7115 | 0.6883 | ||
| 40% | MAE | 0.6800 | 0.6161 | 0.5982 | 0.6025 | 0.6271 | 0.5768 | 0.5767 | 0.565 | |
| RMSE | 0.9203 | 0.7936 | 0.7779 | 0.7751 | 0.7730 | 0.7361 | 0.7357 | 0.7049 | ||
| 20% | MAE | 1.0344 | 0.6327 | 0.6311 | 0.6481 | 0.6300 | 0.6381 | 0.6384 | 0.6115 | |
| RMSE | 1.4414 | 0.8236 | 0.8304 | 0.8350 | 0.8200 | 0.8348 | 0.8358 | 0.7677 |
The experiment data of MAE and RMSE on Yelp, Douban Movie, and Douban Book. A smaller MAE or RMSE value indicates a better performance.
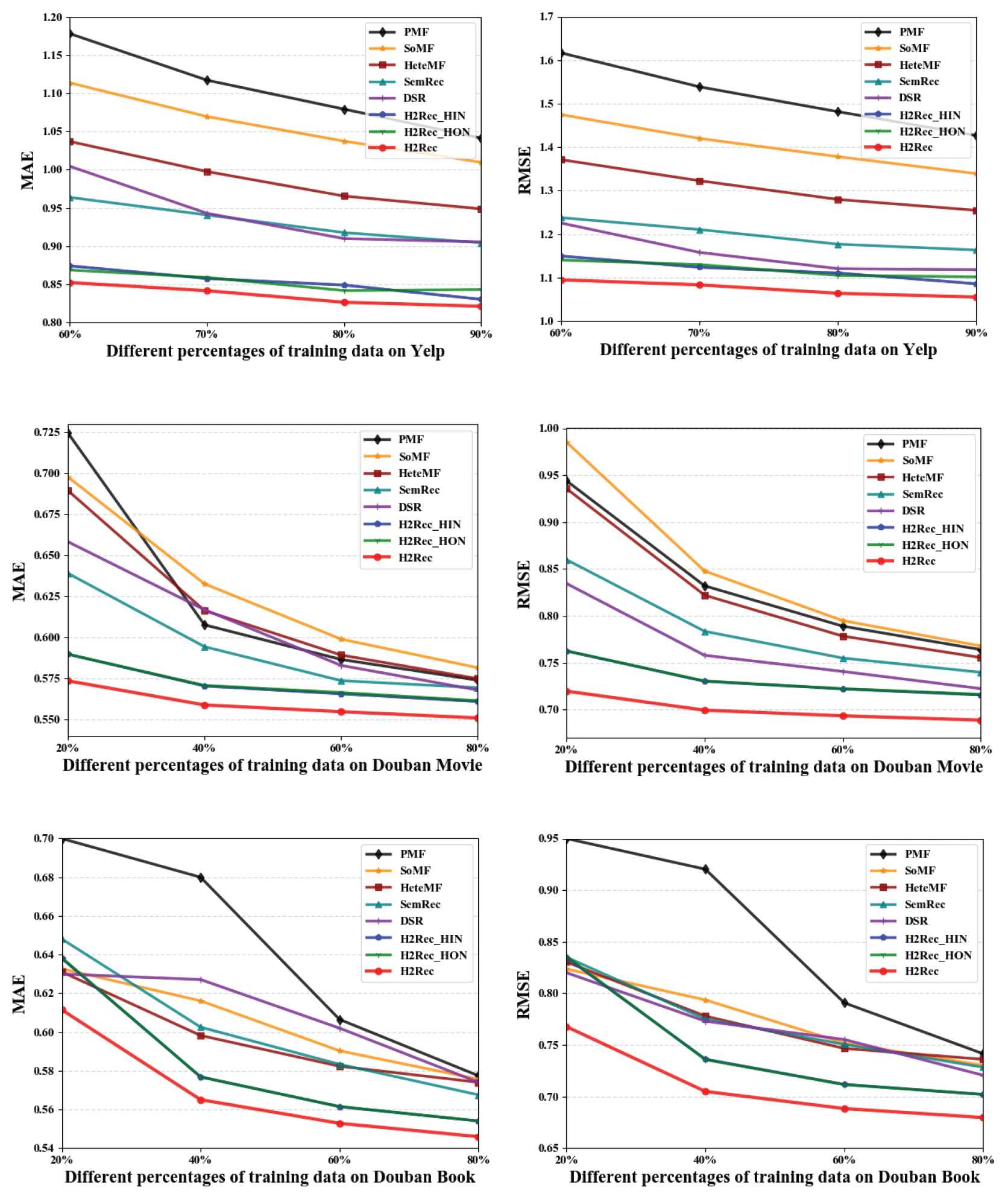
Results of effectiveness experiments on three datasets.
We set parameters for H2Rec as follows: the embedding dimension number
In this study, PMF is regarded as the baseline model due to its being one of the most classic algorithms in the recommendation field. On the whole, compared with the most basic MF model, our model shows an improvement of more than 20%, which proves the effectiveness of adding information network embedding. Compared with other models such as SoMF and HeteMF that use social information or heterogeneous information, H2Rec performs better with regard to RMSE and MAE indicators, proving that the fusion of homogeneous and heterogeneous information network embedding can effectively mine useful information in the information network. However, we can see that for the two evaluation indicators of MAE and RMSE, the performance of all models in the Yelp dataset is worse than that in the other datasets, which is due to the extremely sparse data in the Yelp dataset. The major findings from the experimental results are summarized as follows.
Compared with the most basic MF model PMF, which does not add any auxiliary information, all other models that add auxiliary information (such as social information, tag information, attribute information, etc.) show better performance, which fully illustrates the effectiveness of adding auxiliary information.
Comparing the model based on metapath similarity with H2RecHIN, which only uses HNE and H2RecHON, which only uses homogeneous network embedding, we can see that the performance of network embedding guided by metapaths is better than that based on metapath similarity.
In addition, comparing our H2Rec model with its two variant models H2RecHIN and H2RecHON, we find that H2Rec performs better on both evaluation indicators, which shows that the fusion of heterogeneous and heterogeneous networks can more fully utilize the deep relationships hidden in the information network.
7. CONCLUSION
In this paper, we propose a unified H2Rec model to fuse homogeneous and heterogeneous information for recommendations in social networks to extensively exploit and comprehensively explore the homogeneous and heterogeneous information in social networks for recommendations in social networks. Considering the rich semantics reflected by metapaths in heterogeneous information and the wealth of social information reflected by homogeneous information, the proposed method uses a random walk strategy to generate node sequences in a homogeneous information network and a random walk strategy guided by metapaths to generate node sequences in a HIN. Finally, we integrate MF with network embedding for recommendation. Extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed model. Moreover, we reveal that the transformed embedding information from homogeneous and heterogeneous information networks can improve the recommendation performance.
In future work, we will study how to apply deep learning methods (such as convolution neural networks and auto-encoders) to better integrate homogeneous and heterogeneous network embedding.
CONFLICTS OF INTEREST
The authors declare that there are no conflicts of interest.
AUTHORS' CONTRIBUTIONS
Yabin Shao established the research direction and content. Cheng Liu conducted the literature review and wrote the entire manuscript. All authors have read and agreed to the published version of the manuscript.
ACKNOWLEDGMENTS
This work is supported by the National Nature Science Foundation of China (Grant No.61876201, 61806030, 61936001).
REFERENCES
Cite this article
TY - JOUR AU - Yabin Shao AU - Cheng Liu PY - 2021 DA - 2021/04/13 TI - H2Rec: Homogeneous and Heterogeneous Network Embedding Fusion for Social Recommendation JO - International Journal of Computational Intelligence Systems SP - 1303 EP - 1314 VL - 14 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.210406.001 DO - 10.2991/ijcis.d.210406.001 ID - Shao2021 ER -