
Online Handwritten Arabic Scripts Recognition Using Stroke-Based Class Labeling Scheme
- DOI
- 10.2991/ijcis.d.201024.001How to use a DOI?
- Keywords
- Beta-elliptic model; Fuzzy perceptual codes; Strokes classification; Spatial relations; Online handwriting recognition; Two-stage SVMs
- Abstract
With the increasing availability of pen-based user interfaces, we often come upon multiple data sets of online handwritten scripts such as letters, words, etc., that are collected based on a viable interface. In this paper, we set forward a new method for online handwritten Arabic scripts recognition. Departing from the assumption that handwritten scripts are encoded as a set of strokes, the proposed approach relies first upon classifying strokes contained on the script and then recognizes the whole script. For stroke classification, an support vector machine (SVM) is trained with stroke features vectors obtained from the Beta-elliptic model and fuzzy elementary perceptual codes to obtain class stroke probabilities. The output of this SVM is combined with spatial relation vectors feeding to a second SVM to provide scripts level recognition. The proposed model has been tested on MAYASTROUN dataset. In order to obtain additional insight into the efficiency of the proposed approach, we performed further experiments on ADAB data set. The experimental results highlight its relevance by comfortably outperforming state-of-art systems.
- Copyright
- © 2021 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
It is well established that handwriting recognition (HR) has been still a complicated and a challenging task for more than 30 years despite the rapid progress in terms of techniques used in the recognition [1,2]. Resting on input data, it is customary to distinguish between online and offline HR systems. The offline HR system obtains data in the form of image and applies image processing technique for its analysis [3,4]. On the contrary, online HR system obtains data as an ink composed of sequence of (x, y) coordinates [5,6]. For this reason, in the last decade, research on online HR has gained more interest owing to increasing pen-based user interfaces. Within this framework, several methods have been set forward for online HR in different languages such as Latin [7,8], Chinese-Japanese [9,10], Indian [11,12], Arabic scripts [13,14], etc. Compared to Indo-European scripts, Arabic ones are linguistically more different and richer. They allow only cursive style implying four different forms: isolated, initial, medial and final according to their appearance in the script. Diacritic signs such as dumma (’), fatha (-) or chadda (

Detailed architecture of the proposed recognition system.
Over the last decade, PerTOHS theory was performed on many tasks like writer identification and verification [23,24], handwriting generation [25,26]. It achieved good results compared to state of art works. Recently, PerTOHS theory has also fulfilled significant progress in HR. Among them, we state the system of [27]. In this system, the autors start with encoding handwriting strokes extracted from the Beta-elliptic step with EPCs. Thereafter, the basic operations of genetic algorithm are applied to obtain global perceptual codes (GPCs). Those CPGs are evaluated with decision tree classifier and achieved a recognition rate of 80% on a set of 120 examples of digits and Arabic letters collected on mobile application. In more recent systems, the same authors proposed a novel model based on F-EPCs and long short-term memory (LSTM) network for online HR. These are able to support both languages (Arabic and Latin) [28]. Experiments were performed on a 5 data sets and displayed very promising results. In 2019, Akouadi et al. combined BEM parameters with F-EPCs using convolution neural network (CNN) classifier. The test results on MAYASTROUN and ADAB data sets proved the effectiveness of this architecture [29]. The obtained results and findings encourage to design more online HR based on PerTOHS theory. Therefore, the obtained BEM parametrs and F-EPCs were studied using SVM to specify the class of that particular basic stroke. To this extent, additional features on spatial relationships between classified strokes together with an SVM output generate the features of the entire script that would be processed using second SVM to recognize the script. In order to model the spatial relation between strokes, we suggested the strategy extended from our previous work to portray them. This strategy produces directional and topological relations thanks to the use of geometric features and fuzzy logic. Spatial relationships exhibited among handwriting strokes play a significant role in the interpretation of a handwritten script. They permit to describe the spatial arrangement of two strokes in relation to each other. At this stage of analysis, we would assert that exploring the fuzzy logic concept is meant to evaluate the possible interpretations and precisions through a fuzzy set. Fuzzy sets need to introduce a linguistic designation to each spatial relation. Furthermore, since fuzzy rule-based systems simulate human reasoning, it is natural to use them in handwriting spatial relation description. The rest of this paper is organized as follows: Section 2 introduces the suggested method for modeling and classification of strokes within online Arabic scripts. Section 3 exhibits the details for developing the recognition system for Arabic scripts. Section 4 highlights experimental results along with the experimental setup as well as discussions regarding the performance of the proposed approach as compared to the state-of-the-art ones. Section 5 wraps up the conclusion and provides new perspectives for future works.
2. HANDWRITTEN STROKES MODELING AND CLASSIFICATION
Online handwritten scripts consist of multiple sequential units called strokes and the relationships between them. A stroke forms the building block that occurs between pen ups and pen downs and is composed of an ordered sequence of points. Each point is formulated as (x, y, p) where (x, y) is the initial coordinates and, p indicates the pressure with value 0 or 1. The binary indicator p is determined by judging that the pen is persistently touching the pad (value 0) or will be lifted from the pad after the point (value 1). As illustrated in Figure 2, the lowest hierarchy is the handwritten strokes, and the script is formed using one or more strokes.
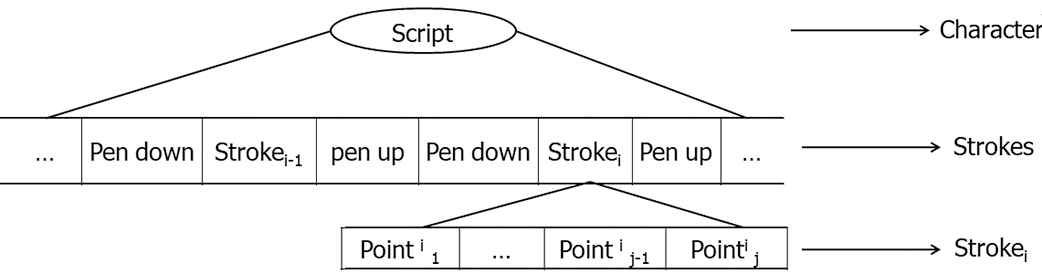
Online character formation hierarchy.
Character = Stroke. Stroke.
Stroke =
where “+” denotes repetition and “.” indicates concatenation. In our approach, using MAYASTROUN and ADAB data sets, we construct a dictionary of forty seven strokes as illustrated in Figure 3.

Dictionary of forty seven strokes from MAYASTROUN and ADAB data sets.
Noting that, strokes numbered from
2.1. Stroke Classification Using Static, Dynamic and Perceptual Features with a Gaussian Kernel
In order to classify strokes, a feature vector representation is needed. Thus, two types of features are distinguished: Beta-elliptic features and perceptual ones. The full obtained feature vector feeds an SVM classifier to obtain the class probability of stroke.
2.1.1. Beta-elliptic features
Beta-elliptic model is designed essentially for understanding and generating simple and complex handwriting movements. Recently, it has been used for many online HR tasks and permits to obtain efficient results. In those approaches, Beta-elliptic parameters are extracted and transformed into feature representation for input script. From this perspective, we tend to explore Beta-elliptic feature representation for our stroke classification. Beta-elliptic approach start by segmenting each input signal into a smaller unit called Beta strokes which are the output of a superimposition of time-overlapped of velocity [30,31]. The beta function defining a velocity profile is expressed as
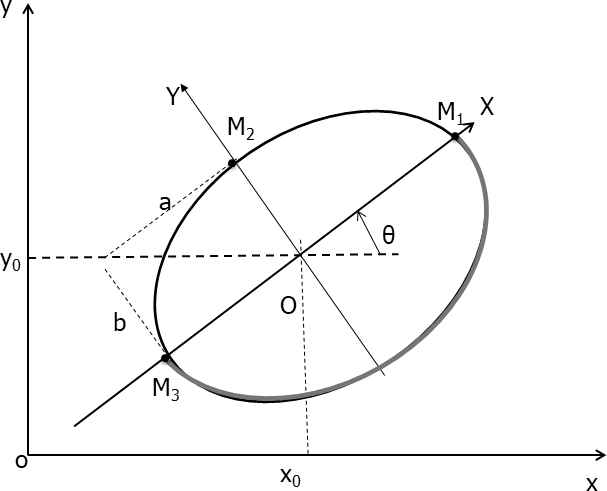
Different elliptic parameters.
The deviation angle
Basically, using BEM each script is modeled in the static and dynamic domain by a series of elliptic arcs and Beta profiles respectively. The latter denote the set of strokes constituting the script. As a matter of fact, for each stroke we have ten parameters (
2.1.2. The EPCs extractor
By means of the BEM for the segmentation of handwriting movements, each handwritten script is modeled by a series of elliptic arcs in the trajectory domain.
Each elliptic arc will be coded by a set of five parameters (respectively: a, b,
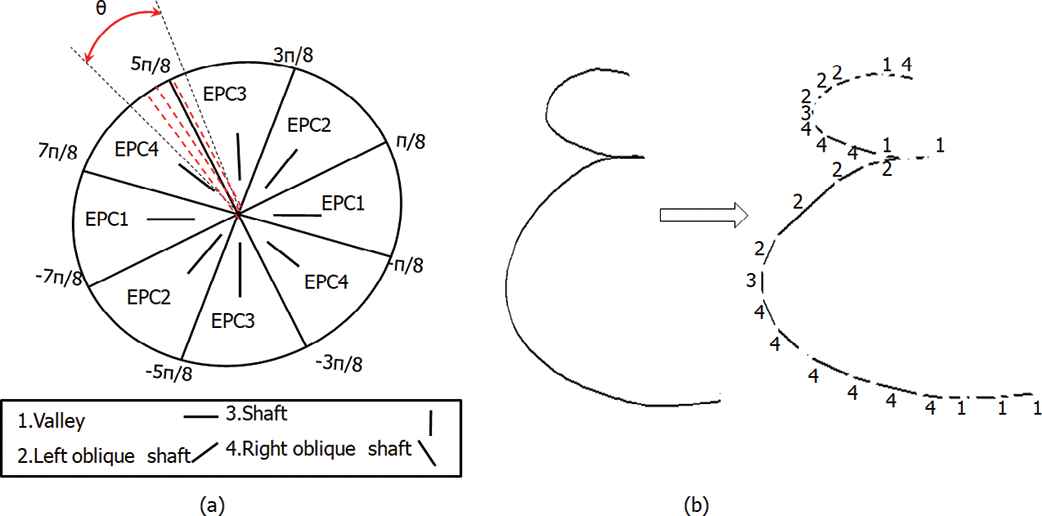
(a) Different elementary perceptual codes (EPCs) on the trigonometric circle and (b) stroke and produced sequence of EPCs.
Stroke =
2.2. Stroke Classification
Ultimately, the plan was to classify an input stroke for a script based on the feature vector computed as indicated in the previous section. More formally, each stroke
In this expression, the feature vector
In order to address the multi-classification problem, binary SVM classifiers opt to use a one-against-one technique that constructs N(N-1)/2 classifiers, where N is the number of classes. When an input stroke S is given, the output values in Equation (5) are computed from the N SVMs and the stroke is classified as one of the N classes providing the maximum output value. Overall, an input stroke
3. STROKE CLASSIFICATION EXTENSION TO SVM-BASED SCRIPT RECOGNITION
In this section, the proposed approach for recognizing handwritten script is handled. The approach begins with grouping an input script to the number of strokes it involves. Let’s consider for example, the scripts illustrated in Figure 6 composed of one, two, three and four strokes respectively, where each stroke is denoted as a dashed-colored rectangle.
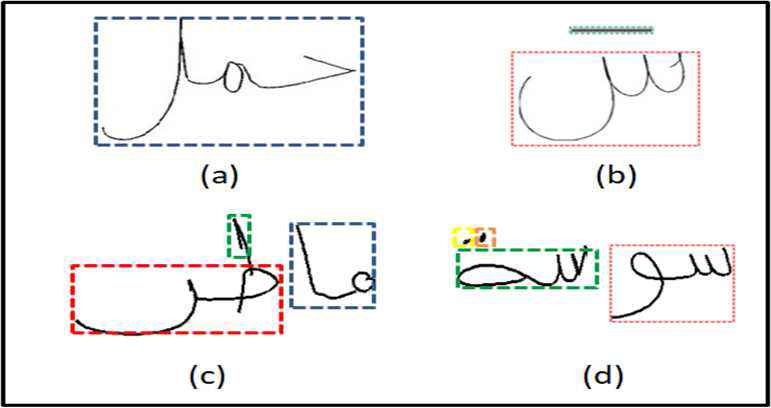
Samples of handwritten scripts.
Subsequently, the system classifies the handwritten scripts inside each of the groups through the use of appropriate method. While in previous methods only the classification stroke result is considered in script recognition steps in our method the spatial relation among the classified strokes is additionally considered. This helps to capture spatial structure, order and script shape.
3.1. Spatial Relationships Description via Fuzzy Rule-Based Approach
Spatial relationship identification is a very basic problem, which makes it widely applicable to online [34] as well as other offline tasks [35]. Within handwriting processing domain, spatial relations between handwritten strokes can play an intrinsic role to ease handwriting description and understanding. For example, same strokes can appear differently in different scripts and can be placed in different positions, which may change the scripts meaning. Figure 7 highlights an example of two Arabic scripts that share the same number of strokes, diacritic (number and type) and shape.

The same Arabic script with different diacritic signs position (colored in red).
Yet, these scripts differ in meaning (stroke number 3 has the position number 1 in scripts to scoop up and position 4 in script to play). Basically, spatial relations can be subdivided into three major categories: topological relations, directional relations and metric relations. Nevertheless, there are many works that only use directional relations or topological ones and others that combine them together. Their choice depends on the kind of application used. In previous works, spatial relation is often defined by computing some geometric features such as, angle computation, centroids point, minimum bounding box of hand-drawn primitives, etc. For instance, an attempt to express complex spatial relations by means of geometric features and bounding box is recorded by Simistira [36]. This information is used to check the structure within mathematical symbols. The relationships are then expressed in a quantitative way and it might be easy to compute similarities between them. Nevertheless, these spatial relations come often without capturing their imprecision or their expression. In this context, some methods based upon fuzzy logic are proposed for the treatment of the relations where a fuzzy membership value reflects the measure of satisfaction in a fuzzy region [34,37].
Inspired from these works, we propose a fuzzy logic approach where a set of feature inputs that affect specific outputs are identified for given strokes. In this work, we deliberately choose to exclude a set of 6 geometric features
F1:angle computed between two bounding boxes’ centroid denoted
F2:distance between the y-coordinates of two centroids denoted
F3:distance between the x-coordinates of two centroids denoted
F4:distances between bottom right boundaries of bounding boxes denoted
F5: distance between top left boundaries of bounding boxes denoted
F6: The intersection between two strokes denoted by 0 or 1
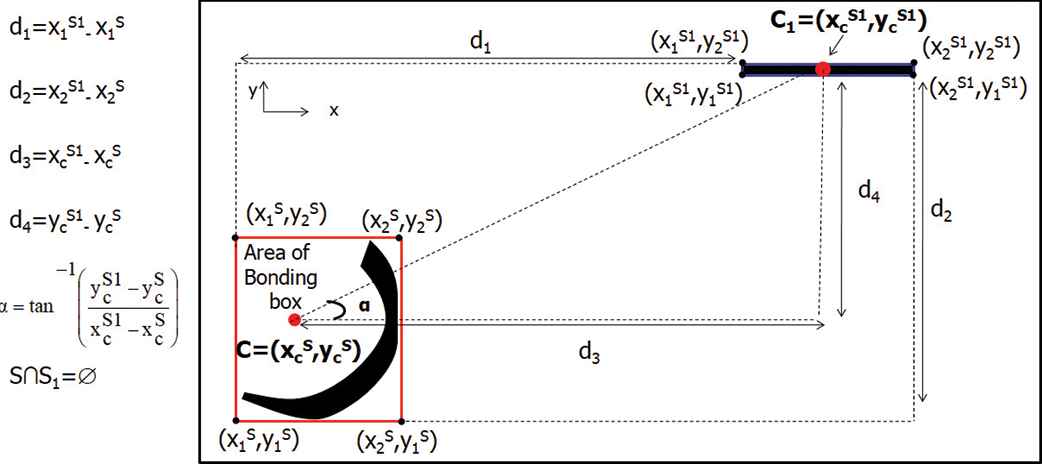
Geometrical features between two handwritten strokes S and of Arabic character with diacritical marks.
Noting that a bounding box coordinates of stroke are computed as
Basically, we developed a set of linguistic variables for the six features inputs and their fuzzy sets (e.g., Negative Big, Negative Small, Zero, Positive Small and Positive Big for angle feature “F1,” Far or Near for “F5,” etc.) as well membership functions to initiate the fuzzification process. Therefore, the rule blocs is done by combining these inputs. In our case, we identified 10 rules for the designed system, whereby different combinations of inputs features asses the degree of satisfaction of a spatial output. As a result, each spatial relation will be codified with a vector of 6 values. As a matter of fact, an online handwriting will be scripted by a matrix of different membership degrees of all spatial relations existing within strokes.
These relations are portrayed in Figure 9. For more details about calculation of spatial relations, we refer the reader to our previous work [38].

Ten kinds of spatial relationships between two strokes.
3.2. Script Recognition
Based on the stroke classification result and spatial relation modeling, the i-th stroke will be represented as (
Once all scripts have been embedded into a vector, the corresponding vector can be used as input to an appropriate SVM. For this reason, we start with classifying automatically all the input scripts into a sub set based on the number of strokes N. Eventually, for each value of N, multiple SVMs are trained as depicted in Section 2.2 and the details shall be described in Section 4.
4. EXPERIMENTAL RESULTS AND EVALUATION
In this section, the experiments that were carried out in order to assess the designed system are portrayed. Both stroke classification and script recognition are performed on ADAB and MAYASTROUN data sets. It is worth noting that, all experiments in this paper were performed using python running on a 2.80 GHz with Intel(R) Core i7-7500, 64 bits laptop with 8 GB running on windows 10. In what follows, the details of datasets are described; experimental setups and the results are exhibited. Finally, a brief comparison with the state art models is established.
4.1. Data Set
For the purpose of experimental evaluation, two state of arts MAYASTROUN and ADAB datasets were used and will be described later in detail.
4.1.1. MAYASTROUN data set
MAYASTROUN is a large data set of online handwritten scripts, digits, western scripts in lower and upper case, Arabic texts and scripts, mathematical expressions, symbols and scripts in different languages and signatures. Some instances of this data set are illustrated in Figure 10. This data set was developed in the Research Groups in Intelligent Machines laboratory (REGIM-Lab). Further details are provided in [39]. It contains up to 1000 scripts written by more than 350 different writers mainly of Tunisian nationality. A subset was selected to perform stroke classification as well as script recognition. This subset is totally composed of 1500 scripts. We derived 3500 strokes from these scripts and chose nineteen basic strokes as displayed in Figure 10.
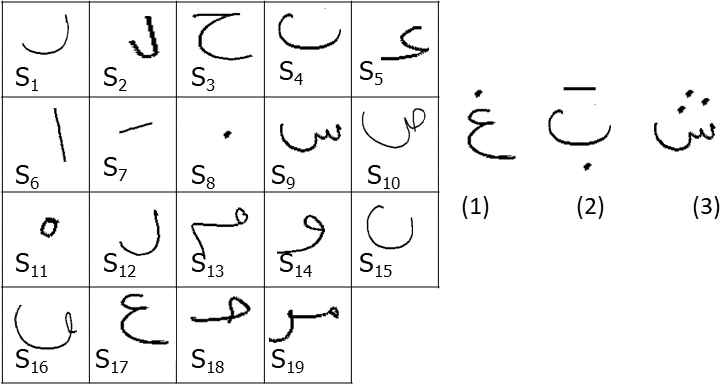
(a) Example of nineteen strokes and (b) example of the corresponding class of three scripts (for each class an example is shown).
The obtained stroke set is uniformly distributed over 19 classes, i.e., basic strokes and the resulting set is split into a testing set of size 1000 and a training set of size 2500. The obtained scripts sets are uniformly distributed over 3 classes. This implies that all scripts are divided into 3 groups varying from 2 to 4 according to the number of stroke. Finally, the resulting script set is split into a training sets of size 1000 and a testing set of size 500. Table 1 summarizes the main properties of these different data sets.
| Subsets | Classes | Size |
|
|---|---|---|---|
| Training | Testing | ||
| Strokes | 19 | 2500 | 1000 |
| Scripts | 3 | 1000 | 500 |
MAYASTROUN subsets details.
4.1.2. ADAB Data Set
The second data set, called ADAB, was developed by research Groups in Intelligent Machines, Tunisia and Institut fuer Nachrichtentechnik (IfN). It was collected through the use of digital tablets connected to computers by more than 130 different writers, most of them of Tunisian nationality. This data set contains 21575 online Tunisian town and village names in Arabic languages [40] which are distributed in 6 subsets. It is noteworthy, each sample is registered in “UPX” file format containing its sequence of x-y trajectory and details about the writer, number of files, characters and word label (see Table 2).
| Number of Words | Number of Pseudo Words | Writers | |
|---|---|---|---|
| Set 1 | 5037 | 40269 | 56 |
| Set 2 | 5090 | 25450 | 37 |
| Set 3 | 5031 | 15039 | 39 |
| Set 4 | 4417 | 22085 | 25 |
| Set 5 | 1000 | 4000 | 6 |
| Set 6 | 1000 | 8000 | 3 |
| Total | 21575 | 114924 | 166 |
ADAB data set details.
Departing from this data set, two subsets are collected i.e. strokes and scripts as presented in Figure 11.
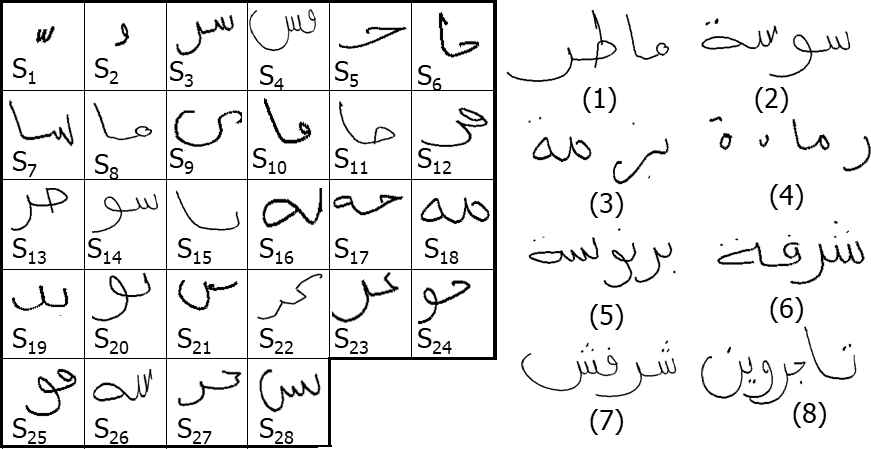
(a) Example of twenty eight strokes and (b) example of the corresponding class of eight scripts (for each class an example is shown).
The strokes data set is divided into 28 classes (Table 3). A testing set of size 2000 and a training size 3000 are used. Thus, there are totally 5000 strokes. Hence, these data sets contain 2 subsets training with 4000 scripts and testing with 3000 scripts collected randomly from different sets. Finally, the scripts set is uniformly distributed over the 8 classes, i.e., stroke number varying from 3 to 10 strokes.
| Subsets | Classes | Size |
|
|---|---|---|---|
| Training | Testing | ||
| Strokes | 28 | 3000 | 2000 |
| Scripts | 8 | 4000 | 3000 |
ADAB subsets details.
4.2. Stroke Classification Experiments
Experiments were carried out according to the previously introduced approach and are introduced in this section.
SVM parameters tuning
It’s noteworthy that we opted to use Gaussian kernel so it is interesting to observe how important the careful choice of the cost parameters C and the Gaussian parameter
As reported in Figure 12, it can be inferred that
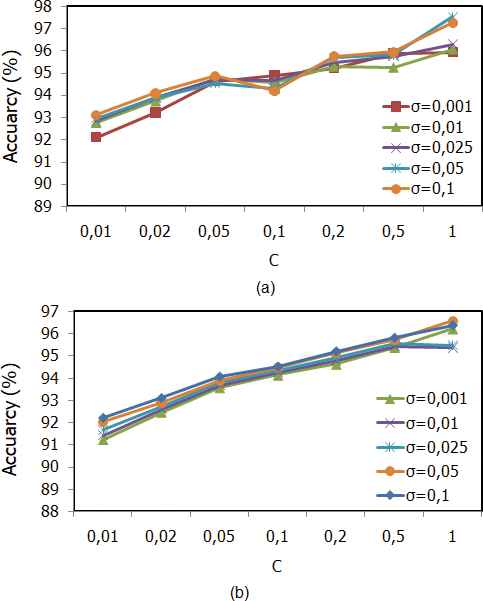
Classification accuracy: (a) MAYASTROUN data sets and (b) ADAB data set.
| C | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| 0.01 | 10.1 | 8.77 | 9.62 | 8.57 | 8.56 | 8.33 | 8.23 | 7.96 | 7.91 | 7.77 |
| 0.02 | 7.86 | 7.54 | 8.23 | 7.42 | 7.83 | 7.29 | 7.84 | 7.11 | 6.93 | 6.88 |
| 0.05 | 6.8 | 6.44 | 6.71 | 6.32 | 6.75 | 6.19 | 6.73 | 6.1 | 6.2 | 5.92 |
| 0.1 | 6.23 | 5.87 | 5.9 | 5.73 | 6.2 | 5.65 | 5.81 | 5.52 | 5.73 | 5.48 |
| 0.2 | 6.12 | 5.38 | 6.03 | 5.22 | 5.82 | 5.09 | 5.21 | 4.86 | 5.2 | 4.79 |
| 0.5 | 4.87 | 4.62 | 5.71 | 4.58 | 4.73 | 4.44 | 4.42 | 4.27 | 4.68 | 4.18 |
| 1 | 4.4 | 3.79 | 4.83 | 4.64 | 4.8 | 4.52 | 4.12 | 3.43 | 5.19 | 3.62 |
Error rates on MAYASTROUN data set.
| C | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| 0.01 | 8.1 | 7.9 | 7.4 | 7.25 | 7.31 | 7.17 | 7.19 | 7.04 | 7.23 | 6.9 |
| 0.02 | 7.32 | 6.8 | 6.6 | 6.28 | 6.42 | 6.14 | 6.52 | 6.1 | 6.34 | 5.93 |
| 0.05 | 6.3 | 5.4 | 5.81 | 5.27 | 5.49 | 5.33 | 5.7 | 5.47 | 5.6 | 5.14 |
| 0.1 | 5.7 | 5.14 | 5.7 | 5.43 | 5.7 | 5.35 | 5.93 | 5.71 | 6.1 | 5.81 |
| 0.2 | 5.1 | 4.8 | 5.01 | 4.73 | 4.8 | 4.54 | 4.7 | 4.32 | 4.73 | 4.27 |
| 0.5 | 4.81 | 4.12 | 4.9 | 4.77 | 4.62 | 4.26 | 4.62 | 4.17 | 4.61 | 4.08 |
| 1 | 4.3 | 4.09 | 4.32 | 3.96 | 4.28 | 3.73 | 2.93 | 2.48 | 3.31 | 2.76 |
Error rates on ADAB data set.
Experimentation on the feature involved in the stroke classification
Our classification method was also controlled by two different features: (1) BEM feature and (2) EPCs features that describe an input stroke. In order to clarify how these features control the performance of the system, we plotted the classification accuracy for each stroke class by using different combinations of these features. Departing from Figure 13, we notice that for both data sets, the proposed hybrid features improved the classification accuracy. Using BEM, the classification accuracy reaches 96.87% and 96.04% in MAYASTROUN and ADAB, respectively; whereas hybrid feature rised the classification up to 1%. Although the performance improvements were not as large in such classes as
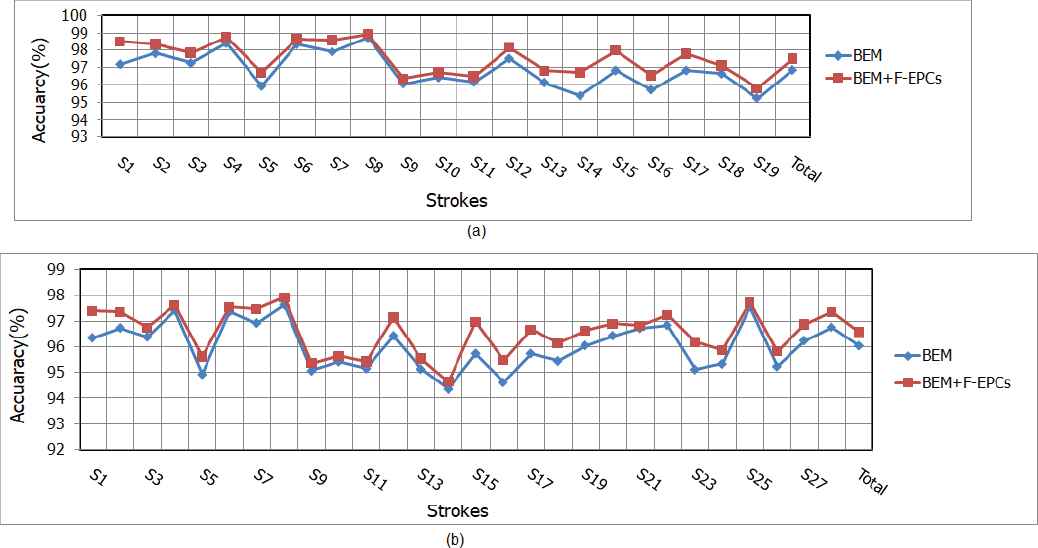
Performances of stroke classification for different combinations of the features: (a) MAYSTROUN data set and (b) ADAB data set.
4.3. Script Recognition
For the recognition stage of handwritten scripts, experiments were performed on scripts collected from both data sets. The concept was to gather the output probability of stroke of the same scripts jointly with spatial relations between them in order to recognize the script label. Experiments were carried out on SVM with Gaussian basis function kernel. The details analysis of the script recognition performance using SVM is presented in Table 6. It can be inferred that both data sets highlight an impressive recognition rate which exceeds 90%.
| Data Set | Accuracy |
|
|---|---|---|
| Training (%) | Testing (%) | |
| MAYASTROUN | 99.78 | 99.24 |
| ADAB | 99.14 | 98.53 |
Script recognition results using support vector machine (SVM).
Analysis under noisy condition
Performance evaluation of the designed recognizer system is evaluated by applying randomly noise signal. To address this issue, we proceeded by adding a Gaussian noise in training as well as testing sub sets. Note that Gaussian noise depends largely on the variability of the variance parameter called sigma

Handwritten scripts and the obtained ones with proportional additional noise.
Since
| Data Set | Accuracy |
|
|---|---|---|
| Training (%) | Testing (%) | |
| MAYASTROUN | 96.68 | 95.24 |
| ADAB | 94.32 | 93.82 |
Script recognition results using support vector machine (SVM) under noisy conditions.
Comparison with state of art works
As already stated, many research works are available for online Arabic script recognition. Thus, we have compared the recognition performance of the proposed method with the existing system on ADAB and MAYASTROUN datasets to obtain an idea of comparative performance analysis. The considered systems are reported in the following:
Tagougui et al.[41] set forward hybrid model based on hidden Markov models (HMMs) and multi-layer perceptron neural network (MLPNN) for online Arabic handwritten script recognition. Relying on the Beta-elliptic strategy, each input signal is subdivided into continuous strokes called segments. An MLPNN trained with different obtained segments is constructed to generate class script probabilities as an output. This output is encoded with HMMs to provide script level recognition. This architecture was tested on sets 4, 5 and 6 of ADAB data set and fulfilled a recognition rate around 96.45%.
Boubaker et al. [42] developed a modeling-recognition system for online Arabic handwriting scripts. A grapheme segmentation task based on baseline detection as well as median zone width estimation is used for modeling handwritten trajectories. Therefore, recognition is performed using HMM on ADAB data set and fulfilled recognition rate of 87.46% for learning and 85.37% for testing.
Khlif et al.[43] identified a new model for online Arabic handwritten word recognition with two levels of segmentation. The first one is a segmentation free-based system that relies on using the generative classifier HMM. The second level relies on explicit grapheme segmentation where both online and offline parameters are identified and classified with SVMs.
Hamdi et al.[44] proposed to combine MLPNN with a genetic algorithm for online HR model. The MLPNN is trained with a collection of grapheme obtained in segmentation stage using BEM. A search technique, i.e., a genetic algorithm is applied to generate the recognized graphemes code.
Elleuch et al.[45] constructed a system for online HR based on a hybrid BEM and convolution deep belief network (CDBN) offline feature extractor models.
Abdelaziz et al. [46] proposed an HMM-based system for online Arabic handwriting in which they attempt to handle delayed strokes. On a large vocabulary data set, HMMs are trained and tested with a collection of geometric features (chain code, aspect ratio,loops, hat, etc.) and reached a recognition rate around 97.13%.
Akouadi et al. elaborated in 2019 two online Arabic systems [28,29]. The first system was performed on 5 data sets and showed very promising results that exceed 98% while the second system was tested on two data sets (MAYASTROUN and ADAB) and reached a recognition rate of 98.90% and 98.41% respectively.
Zouari et al. [43] proposed to combine time delay neural network (TDNN) with SVM for online HR model. The TDNN-SVM is trained and tested with a collection of features vectors obtained in segmentation stage using BEM so as to describe continuous trajectories of scripts. The recognition system was tested on multi-languages online data set and achieved a recognition rate around 100%.
Maalej et al.[13] identified a new model for online Arabic HR based on deep long short-term memory (DBLSTM) that relying on two modes of Maxout integration. First, the authors added the Maxout function inside the LSTM nodes and set the size of maxout groups to 3. Thus, the error rate reduction reached 10.62%. Second, they proposed to stack Maxout layers after BLSTM layers. This architecture proved to outperform the first one as it permits a reduction of 10.99% in the label error rate.
The obtained results are summarized in Table 8. From the obtained results, we can infer how promising our system performance is compared to the state of-the-art systems. First of all, ten different classifier/feature combinations were tried on different sets of ADAB data set. The comparison reveals that our method has much better performance than some approaches relying on a single classifier (98.53% with SVM-based classifier(our approach) vs. 95.14% with MLP and 91.8% with SVM). This stands for an improvement of 3.39 % and 6.37 % respectively. In Refs [42,43,46] presented systems are using all the same classifier (HMMs) with different features as input; the recognition rate for the results of the systems mentioned does not exceed 97.2%, whereas the proposed system outperforms the results and achieves 98.53%. The obtained remains valid even though it is compared to hybridized classifier (98.53% with SVM vs. 96.45% with MLP-HMM, 90% with BCP-LSTM). However, we inferred that our system lost its first place against two recent systems [13,47] with a recognition rate around 100% for both. This can be accounted for in terms of using multi-language data set (contained scripts not only from ADAB data sets) as well as different sets on training and testing(different sets from ADAB) in Refs. [13] and [47] respectively which prevents performing a thorough comparison. Furthermore, Table 8 discloses a comparative study of the performance of our method on MAYASTROUN data set. This comparison resulted in overall accuracy of 94.50% with BCP-LSTM and 85.5% and 98.90% with Deep CNN whereas the proposed system outperforms the results and achieves 99.24%. Noting that, either we use the same data set and the same classifier as in [45]; our method achieves the best results. This proves that the features used do possess a discriminative power on recognition results.
| Authors | Features Extraction | Classifier | Recognition Rate (%) | |
|---|---|---|---|---|
| ADAB | Tagougui [41] | Beta-elliptic features (Dynamic + static) | MLP-HMM | 96.45 |
| Boubaker [42] | Geometric parameters + Fourier descriptors | HMM | 85.37 | |
| Khlif [43] | Online + offline feature | HMM | 93.33 | |
| Hamdi [44] | Beta-elliptic model | MLP | 95.14 | |
| Elleuch [45] | Online + offline feature | SVM | 91.8 | |
| Abdelaziz [46] | Geometric features | HMM | 97.13 | |
| Akouadi [28] | Beta parameters + perceptual codes | BCP + LSTM | 90 | |
| Zouari [47] | Beta-elliptic parameters | TDNN-SVM | 100 | |
| Maalej [13] | x, y coordinates | BLSTM | 99.98 | |
| Proposed | Beta point + perceptuel codes + spatial relation | SVMs | 98.53 | |
| MAYASTROUN | Akouadi [29] | Coordinate (x, y, z) | Deep CNN | 85.5 |
| Akouadi [28] | Beta point + perceptual codes | BCP + LSTM | 94.50 | |
| Akouadi [29] | Beta parameters + CNN + perceptual codes | Deep CNN | 98.90 | |
| Proposed | Beta point + perceptuel codes + spatial relation | SVMs | 99.24 | |
MLP, multi-layer perceptron; HMM, hidden Markov model; SVM, support vector machine; LSTM, long short-term memory; TDNN, time delay neural network.
State-of-the-art results.
Moreover, segmenting each handwritten script into a sequence of stroke permits to calculate features of each stroke separately. This provides a local description of the script component and allows recognizing scripts by considering their stroke class labeling scheme. Furthermore, incorporating spatial relation features on the script recognition process empowers the obtained accuracy.
5. CONCLUSION AND FUTURE PERSPECTIVES
This paper elaborates a new architecture of online handwritten script recognition system. Our work proceeds by segmenting each input script into strokes denoting the block between pen up and pen down. Indeed, we suggested the incorporation of merits of both BEM and F-EPCs on modeling those strokes. Scanning through literature, many machine learning have been set forward. For training and classifying strokes SVM was chosen thanks to its ability to handle sequential data. To enhance the recognition performance, spatial relations within handwriting strokes were analyzed. Subsequently, the membership probabilities vector of spatial relationship belonging to the same script was reunited with stroke probability to transform the input data into a second SVM classifier so as to recognize the whole Arabic handwritten script. Comprehensive experiments using two Arabic handwritten scripts data sets ADAB and MAYASTROUN proved that the proposed combination approach can considerably brush up the classification accuracy. In fact, we can realize that our method has achieved a very promising recognition rate of 98.53% (Script error rate of 1.47%) and 99.24% (Script error rate of 0.76%) when practiced to the ADAB and MAYASTROUN data sets respectively. Resting on the results recorded in this work, it is worth noting that this framework is able to properly recognize handwritten Arabic scripts. First of all, we note that the incorporation of the sophisticated segmentation technique (i.e., BEM) allows not only improving the accuracy but also addressing the touching scripts problem. Second, integration fuzzy logic on perceptual elements permits to deal with variability of writing and uncertainty data. Furthermore, structural information can help enhance the initial Arabic recognition and spatial relations decisions. This property permits the use of any kind of data and makes it reproducible to any other PR task. In addition, in order to confirm the effectiveness and reliability of this approach a comparison established among various states of the art on both data sets is conducted and summarized in the following points: (1) In a series of experimental evaluations, we conclude that our method is better than the most state-of-the-art HR methods on both data sets. This is mostly substantial with reference to methods which are not based on BEM features (e.g., refs [42,43,45] achieving the highest ranging error rates between 6.67% to 14.63% vs, 1.47% obtained with our system on ADAB data set). (2) Compared to works [28,29,41,44] dealing with beta parameter/perceptual codes, our work still achieves the best recognition rate with an overall improvement between 2.08 and 8.53% on ADAB data set and between 0.34% and 4.74% on MAYASTROUN data set. This proves the effectiveness of spatial relations in HR systems. (3) With two participating systems [13,47], the recognition rates are slightly higher (around 100%) on ADAB data set. This stands for an improvement
CONFLICTS OF INTEREST
The authors declare that they have no conflict of interest.
AUTHORS' CONTRIBUTIONS
Rabiaa Zitouni: Conceptualization, Methodology, Software, Formal analysis, Writing - original draft. Hala Bezine: Methodology, Investigation, Writing - review & editing, Visualization. Najet Arous: Validation, Formal analysis, Supervision
Funding Statement
This research received no external funding.
ACKNOWLEDGMENTS
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions to improve the quality of the article
REFERENCES
Cite this article
TY - JOUR AU - Rabiaa Zitouni AU - Hala Bezine AU - Najet Arous PY - 2020 DA - 2020/10/30 TI - Online Handwritten Arabic Scripts Recognition Using Stroke-Based Class Labeling Scheme JO - International Journal of Computational Intelligence Systems SP - 187 EP - 198 VL - 14 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.201024.001 DO - 10.2991/ijcis.d.201024.001 ID - Zitouni2020 ER -