
Tolerance Rough Set-Based Bag-of-Words Model for Document Representation
- DOI
- 10.2991/ijcis.d.200808.001How to use a DOI?
- Keywords
- Document representation; Tolerance rough set; Bag-of-Words
- Abstract
Document representation is one of the foundations of natural language processing. The bag-of-words (BoW) model, as the representative of document representation models, is a method with the properties of simplicity and validity. However, the traditional BoW model has the drawbacks of sparsity and lacking of latent semantic relations. In this paper, to solve these mentioned problems, we propose two tolerance rough set-based BOW models, called as TRBoW1 and TRBoW2 according to different weight calculation methods. Different from the popular representation methods of supervision, they are unsupervised and no prior knowledge required. Extending each document to its upper approximation with TRBoW1 or TRBoW2, the semantic relations among documents are mined and document vectors become denser. Comparative experiments on various document representation methods for text classification on different datasets have verified optimal performance of our methods.
- Copyright
- © 2020 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
With the explosive growth of the Internet, countless text data are accumulated constantly. In addition, unlike numerical data belonging to the structured data type, document or text data are unstructured data. Unstructured data are not appropriate to be directly applied in machine learning or deep learning algorithms. As the basis of natural language processing (NLP) and text mining tasks, efficient text or document representation is particularly important. The main challenges on document representation are the ways of transforming unstructured text data into structured data. For a good document representation, on the one hand, it should be able to truly reflect the content of the document, on the other hand, it should have the ability to distinguish different documents. Additional, it has optimal performance in some NLP applications such as text classification, information retrieval and text clustering.
The bag-of-words (BoW) model [1] is a representative document representation method, which has been widely used in information retrieval, text classification [2] and sentiment analysis [3]. In the BoW model, the word order, grammar and syntax of the document are ignored and every document is only regarded as a set of words, or a combination of words. The emergence of each word in the text is independent and does not depend on the appearances of other words. The BoW model takes all the non-repetitive words of all the documents in the dataset as basis terms. Each document is denoted by a fixed dimension vector, the length of which is equal to the number of the basis terms. Each component of the vector corresponds to the frequency of the basis word that appears in the document. The BoW model has the virtue of briefness and efficiency. However, it suffers from the defects of sparsity and lack of latent semantic relevance. These issues have been addressed many times in earlier research, but we are committed to solving this problem without any prior knowledge and without supervision. Hence, we apply tolerance rough set theory [4] to improve the traditional BoW model, and thus propose two new tolerance rough set-based BOW models, TRBoW1 and TRBoW2, which can expand the semantic space of documents. And they are unsupervised and not need any prior knowledge.
There are many researches have been done on document representation. Among them, the BoW model is one of the most classical method. Owing to that the BoW model is sparse, high-dimensional and lack of latent semantics, some other models emerge as the times require from distinctive perspectives, such as feature selection algorithms [5–8], weight calculation algorithms [9–12] and dimensionality reduction algorithms [13–18]. Text feature selection algorithms contain document frequency [7], Chi square (
Methods based on neural network and deep learning arose at the historic moment. However, majority of them are supervised or need prior knowledge. A sentence encoder-decoder model was proposed in [23], called Skip-Thought model, which learned the representation through predicting the following sentence. But it need a lot of training. Wu et al. [24] represented documents based on phrase embeddings by parsing, in which three Phrase2Vec methods are constructed on the basis of Word2Vec. To solve the problem of sparsity, Yao et al. [25] utilized word sematic similarity by constructing a neural probabilistic language model. Gao et al. [26] proposed the CCTSenEmb model by obtaining the association between adjacent sentences in the process of sentence prediction. The Hybrid-WikiBoC approach was proposed to improve the performance of BoW in [27], taking Wikipedia as the background knowledge. To overcome the limitation of sparsity and inability to dig out semantic significance behind words of the BoW model, Zhao et al. combined the fuzzy system with BoW, and proposed a novel fuzzy bag-of-words (FBoW) model [28]. FBoW model converted the original hard mapping into fuzzy mapping, representing the component of document representation vector as the similarity between words and basis terms. Furthermore, the fuzzy bag-of-word clusters (FBoWC) model was developed to solve the problem of high dimension by clustering the basis terms in [28]. However, it is based on the prior knowledge, which needs the word embedding to capture the semantic relevance.
This paper is organized as follows: The tolerance rough set model is reviewed in Section 2. Section 3 presents our proposed tolerance rough set-based BOW models detailedly. Section 4 demonstrates the experimental results. The discussion and analysis of the experimental results is given in section 5. In Section 6, some conclusions are came to.
2. TOLERANCE ROUGH SET
In this section, the tolerance rough set model is reviewed in brief.
Rough set theory, put forward by Polish scholar Pawlak in 1982 [29], is applied to process the problem of uncertainty and fuzziness. It provides both theories and technologies for researchers in a broad variety of fields of artificial intelligence such as data mining, machine learning and NLP. Rough set, which is based on the equivalence relation, uses a pair of concepts, upper approximation and lower approximation, to measure the relationships of one certain object and a set
A tolerance space is represented by a quadruple
3. TOLERANCE ROUGH SET-BASED BOW MODELS
In this section, we describe the proposed TRBoW models in detail. Now we introduce the definition of the triple of tolerance rough set in document representation. The notations in this section are listed in Table 1, where the vectors and matrixes are written as bold formatting.
| Notation | Description | Notation | Description |
|---|---|---|---|
| The document corpus | The universe | ||
| Document size | Basis terms size | ||
| The vector representation of document |
The co-occurrence times of words |
||
| Co-occurrence threshold | n-dimensional unit vector | ||
| The tolerance space | The document representation matrix by BoW | ||
| The uncertainty matrix of the basis terms | The fuzzy membership matrix of the words and documents | ||
| The upper approximation set of the document |
The upper approximation set of the document |
||
| The upper approximation matrix of the documents | The lower approximation matrix of the documents | ||
| The document representation matrix by TRBoW1 | The document representation matrix by TRBoW2 |
Table of notations.
Suppose that
Let
Then the uncertainty matrix
For any two documents
And the fuzzy membership matrix of the whole corpus is represented by
Then the upper approximation
Hence the upper approximation matrix
As for the original BoW model, the representation matrix is defined as
Now, we propose two different tolerance rough set-based BOW models, called as TRBoW1 and TRBoW2 according to different weight calculation methods. In the TRBoW1 model we strengthen the weights of words exactly contained in the document. Thus the representation matrix is represented by
In the TRBoW2 model we take the membership matrix as the document representation matrix directly
Algorithm 1 is the detailed procedure of the proposed methods.
Algorithm 1: Tolerance Rough Set-Based Bag-of-Words Models
Input: A set of text data including
Parameters: The co-occurrence threshold:
Output: Document representation matrix:
1: Count the term frequencies of all the words occurring in the corpus, and choose the most frequent
2: Calculate the uncertainty function
3: The fuzzy membership degree
4: Acquire the upper approximation
5: if the BoW model is performed then
6: Let
7: else if TRBoW1 model is performed then
8: Apply formula (17) and (18) to compute the representation matrix
9: else if TRBoW2 model is performed then
10: Let
11: end
12: return
Example 1. Assume that the corpus is consisted of the following four documents.
The universe is the set of all the basis terms,
If the TF-IDF model is performed, the document representation matrix is
If the TRBoW1 model is performed, setting
Then the membership matrix is
And the upper approximation matrix is
So the document representation by the TRBoW1 model is
If the TRBoW2 model is performed, setting
Because each basis term appears no more than once in each document, the representation matrixes are the same by the TRBoW1 and TRBoW2 model in Example 1. For the practical corpus is large enough, a word often occurs many times in the same document, the representation matrixes by the two models will be different.
As can be indicated from Example 1, the TF-IDF model emphasizes the weight of each word more than the BoW model. Besides, by applying the rough set theory, our methods capture some latent semantic information. For example, the first two sentences are represented by the first two row vectors of the document representation matrixes, respectively. We can see that
In the BoW model, the document representation of the first document is expressed as
It is evident from the matrix above that the sparsity of BoW model is improved considerably. In fact, the sparsities of document representation matrixes in the TRBoW1 and TRBoW2 model are depended on the value of
4. EXPERIMENTS
In this section, in order to evaluate the performance of our methods, we compare our proposed models with the BoW model, TF-IDF model and average embeddings (AEs) by conducting some popular text classification tasks [1,12]. For better comparison, the dimension of BoW and TF-IDF is also set as 1000. AE is a neural network based method, which represents a document by averaging out the word embedding of each word included in the document. The pretrained word2vec word embeddings are used in the experiments [33], which are 300 dimensional. The other parameter settings are the same.
4.1. Datasets and Preprocessing
In order to verify the validity of our methods and experiments, we will use the commonly used benchmark datasets, Reuters, BBC and BBCsport in text classifications.
Rueters: Reuters is a dataset of news documents generated from the Reuters news website, including 46 categories [34]. Due to the serious imbalance of the document size of per category, we choose the five top categories in our study, a total of 8157 documents. The dataset is beforehand cut into training set with 6533 articles and testing set with 1624 articles. Since we download the data from the toolkit of Keras, and the data is represented in the form of arrays, we firstly converted it into the form of original text.
BBC: BBC dataset is a corpus of 2225 documents containing 5 different categories, which is crawled from the BBC news website [35]. Business, entertainment, politics, sport and tech are respectively the labels of each category. Since the training set and testing set have not been given, we split the corpus into training set with 1225 documents and testing document with 1000 documents randomly.
BBCsport: BBCsport is a collection of 737 documents from the BBCsport website including athletics, cricket, football, rugby and tennis in total of 5 categories [35]. Since the training set and testing set have not been given, we split the corpus into training set with 400 documents and testing set with 337 documents at random.
Table 2 shows the statistical information of the three datasets above. As for the preprocessing of the datasets, the headers and footers of every document have been removed. Then the punctuation and stop words with no practical sense in the document, have also been deleted. The stop words list is obtained from the library
| Statistics | Reuters | BBC | BBCsport |
|---|---|---|---|
| Document number | 8157 | 2225 | 737 |
| Class number | 5 | 5 | 5 |
| Training/Testing splits | 6533/1624 | 1225/1000 | 400/337 |
Statistical information of the three datasets.
4.2. Experiment Setup
We carry out the experiments to compare our proposed TRBoW1 model and TRBoW2 model with BoW model and TF-IDF model and AE method. In order to get the best result, we set the parameters of each classifier in a reasonable range, and the program automatically selects an optimal one. Since the most frequent based keyword extraction method (MF) was verified to be more efficient than other keywords extraction methods, such as term frequency inverse sentence frequency (TF-ISF) and co-occurrence statistical information (CSI) [36], we set the most 1000 frequent words in the corpus as the basis terms in all the experiments. Therefore, the representation vectors in this paper are set as 1000 dimensional.
After learning the document representation, the following four different popular machine learning classifiers are applied for classification tasks:
Support vector machine (SVM): In the SVM theory [37], a linear and a nonlinear kernel can be chose to classify linear data and nonlinear data, respectively. We use the linear one, which is called as linear SVM. We set the parameter C as
K-nearest neighbor (KNN): In the KNN algorithm [38], one certain document belongs to the category that the most of the nearest
Random forest (RF): RF algorithms [39] are a set of classification and regression trees derived from the guided samples of training data. The connection among trees and the efficiency of a single tree influence generation error of the classifiers. The depth of RF is searched from 6 to 12.
Ridge regression (RR): RR algorithm [40] is a nonlinear partial estimation method. And it is a biased estimator regression method specially used in the analysis of collinear data.
The other hyper-parameters are set as the default values of the system. To make a comprehensive comparison of the performance of our proposed TRBoW1 and TRBoW2 model for document representation, we use the five-fold cross validation in all the experiments to obtain the best result of every single experiment.
4.3. Evaluation Metrics
In this section, we exploit precision rate, recall rate and F-measure to measure the performance of text classification.
Precision rate refers to the proportion of the number of texts to the total number of texts correctly classified by the classifier, which is defined as
Recall rate refers to the proportion of the number of correct texts classified to all documents of the category, which is defined as
Precision rate and recall rate are contradictory measures. In general, the improvement of precision rate will lead to the depression of recall rate, and vice versa. So F_measure, harmonic mean of precision and recall, is proposed to make the comprehensive assessment, given as
4.4. Experimental Results
The experimental results are illustrated in this subsection. The experimental results of precision, recall rate and F_measure of document categorization on the BBCsport dataset obtained by the original BoW model, TF-IDF model, AE method and the proposed TRBoW1 and TRBoW2 are respectively described in Tables 3–5. Table 6 describes the classification precision of the four methods and four classifiers on the BBC dataset. Table 7 shows the recall and Table 8 shows the F_measure. Tables 9–11 present the study results on the dataset of Reuters. They are individually the precision, recall and F_measure.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 78.64 | 86.65 | 92.56 | 92.58 | 92.58 |
| RR | 96.44 | 96.71 | 97.02 | 97.33 | 97.63 |
| RF | 94.96 | 93.18 | 89.91 | 95.85 | 95.25 |
| SVM | 97.63 | 97.33 | 96.44 | 98.22 | 97.63 |
Precision (%) of four methods on the BBCsport dataset.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 80.16 | 86.84 | 93.65 | 93.59 | 94.04 |
| RR | 96.70 | 96.66 | 97.20 | 97.70 | 98.07 |
| RF | 95.28 | 95.18 | 90.33 | 96.34 | 95.60 |
| SVM | 97.79 | 96.37 | 97.51 | 98.37 | 98.18 |
Recall (%) of four methods on the BBCsport dataset.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 79.37 | 87.03 | 93.11 | 93.08 | 93.31 |
| RR | 96.57 | 96.68 | 97.11 | 97.52 | 97.85 |
| RF | 95.56 | 95.56 | 90.12 | 96.09 | 95.72 |
| SVM | 97.71 | 96.85 | 96.97 | 98.30 | 97.90 |
F_measure (%) of four methods on the BBCsport dataset.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 69.30 | 69.60 | 94.70 | 91.80 | 94.10 |
| RR | 94.00 | 88.60 | 95.60 | 95.20 | 95.80 |
| RF | 91.40 | 92.10 | 94.20 | 93.80 | 94.40 |
| SVM | 94.20 | 94.80 | 96.40 | 96.10 | 95.30 |
Precision (%) of four methods on the BBC dataset.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 66.66 | 66.82 | 92.64 | 90.98 | 93.66 |
| RR | 93.65 | 87.85 | 95.49 | 94.90 | 95.54 |
| RF | 91.43 | 91.47 | 93.87 | 94.08 | 93.96 |
| SVM | 93.82 | 94.40 | 96.22 | 95.85 | 95.34 |
Recall (%) of four methods on the BBC dataset.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 67.96 | 68.18 | 93.66 | 91.39 | 93.88 |
| RR | 93.82 | 88.22 | 95.55 | 95.05 | 95.67 |
| RF | 91.76 | 91.78 | 94.03 | 93.54 | 94.18 |
| SVM | 94.01 | 94.60 | 96.31 | 95.47 | 95.16 |
F_measure(%) of four methods on the BBC dataset.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 74.97 | 68.84 | 76.97 | 80.36 | 79.43 |
| RR | 86.51 | 86.58 | 86.45 | 86.02 | 87.99 |
| RF | 79.06 | 79.56 | 74.88 | 87.07 | 86.15 |
| SVM | 88.18 | 90.21 | 86.45 | 89.10 | 88.55 |
Precision (%) of four methods on the Reuters dataset.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 63.97 | 54.77 | 67.28 | 70.38 | 67.36 |
| RR | 78.15 | 80.06 | 76.07 | 77.78 | 81.92 |
| RF | 63.76 | 63.85 | 48.39 | 79.24 | 78.24 |
| SVM | 81.88 | 84.48 | 78.67 | 84.66 | 83.62 |
Recall (%) of four methods on the Reuters dataset.
| BoW | TF-IDF | AE | TRBoW1 | TRBoW2 | |
|---|---|---|---|---|---|
| KNN | 69.02 | 61.01 | 71.80 | 75.04 | 72.90 |
| RR | 82.12 | 83.19 | 80.93 | 81.69 | 84.85 |
| RF | 70.59 | 70.84 | 58.78 | 82.97 | 82 |
| SVM | 84.91 | 87.25 | 82.38 | 86.82 | 86.01 |
F_measure (%) of four methods on the Reuters dataset.
5. DISCUSSIONS
In this section, we discuss the precision rate, recall rate and F-measure of the BoW model, TF-IDF model, AE method and our proposed TRBoW1 model and TRBoW2 for document representations on document categorization tasks by utilizing the KNN, RF, SVM and RR classifier on the BBCsport, BBC and Reuters corpus.
5.1. Performance on the BBCsport Dataset
As can be observed in all the tables of BBCsport dataset, in the comparison of these methods, the optimal results are labeled with bold fonts. And for the TRBoW1 and TRBoW2 method, the tables present the optimal results for the parameter
5.2. Performance on the BBC Dataset
Data emerged in Tables 6–8 are searched the best results, when parameter
5.3. Performance on the Reuters Dataset
Data in Tables 9–11 display that the TRBoW1 model outperforms the other models by the KNN, RF and SVM classifiers, and the TRBoW2 model outperforms the other models by the RR classifier. Because the theory of each classifier is different, it is acceptable that the experimental results of different classifiers are a little various. On account that we do not employ all the data of Reuters, the advantage of semantic mining may be not fully displayed. So compared with other datasets, performances of Reuters dataset do not have a more remarkable increment.
5.4. Co-occurrence Degree Threshold Value
In the tolerance rough set model, the co-occurrence threshold value
Figures 1 and 2 display the impacts of the value of
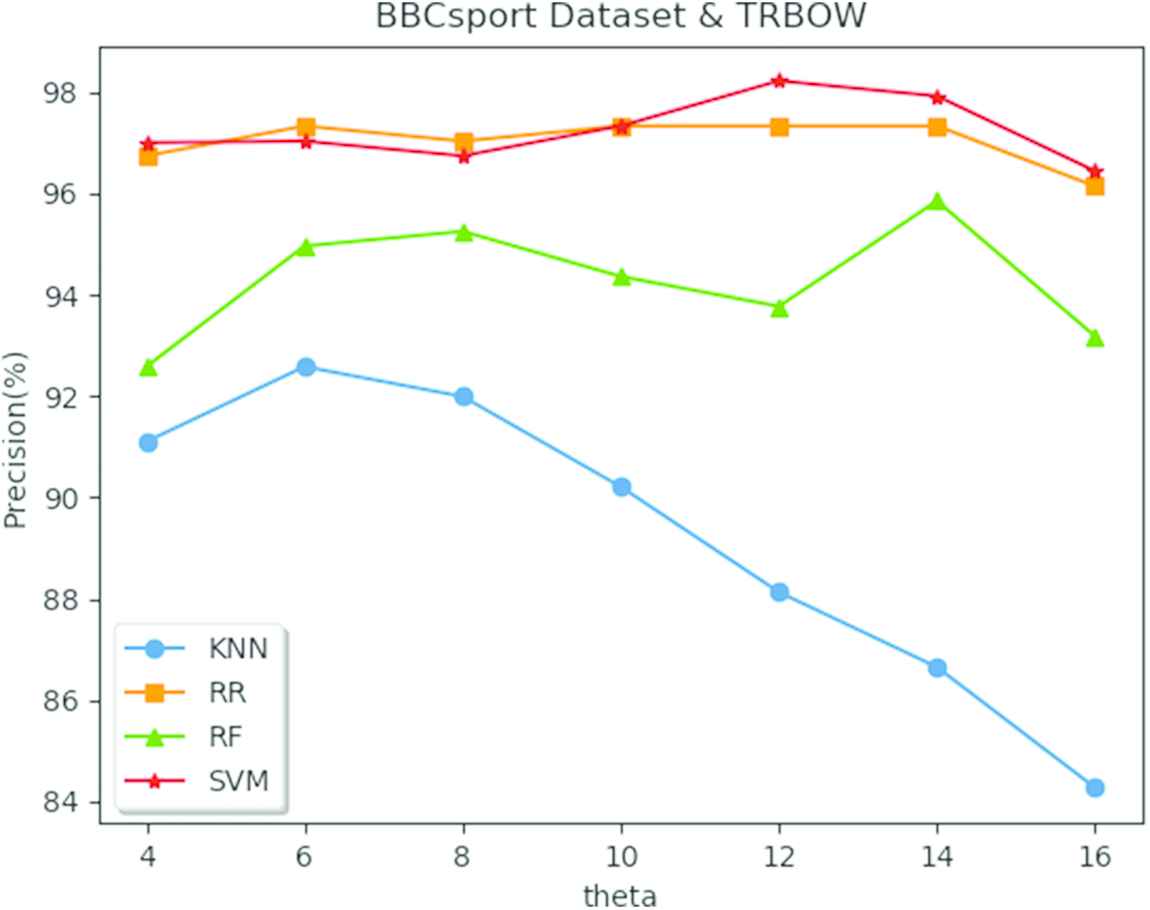
Precision using different classifiers with different threshold value θ.
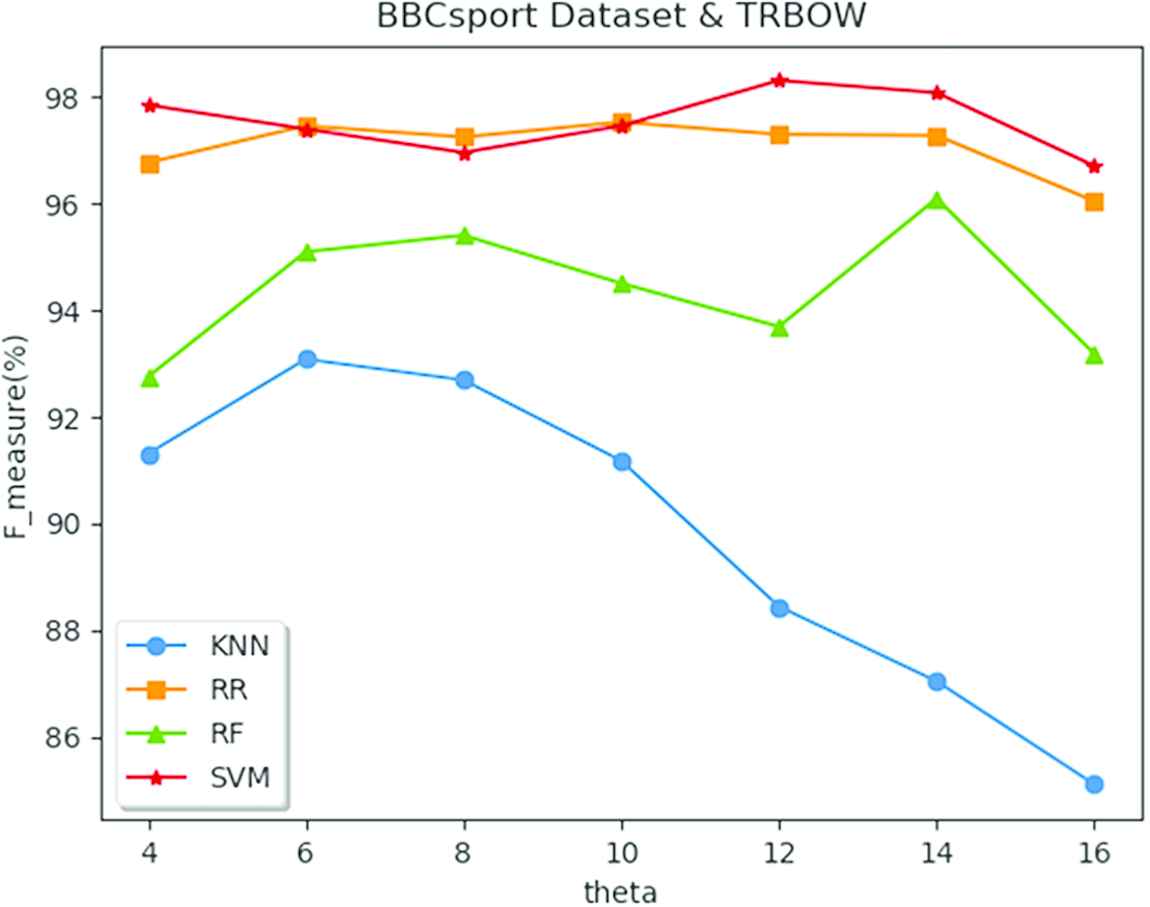
F_measure using different classifiers with different threshold value θ.
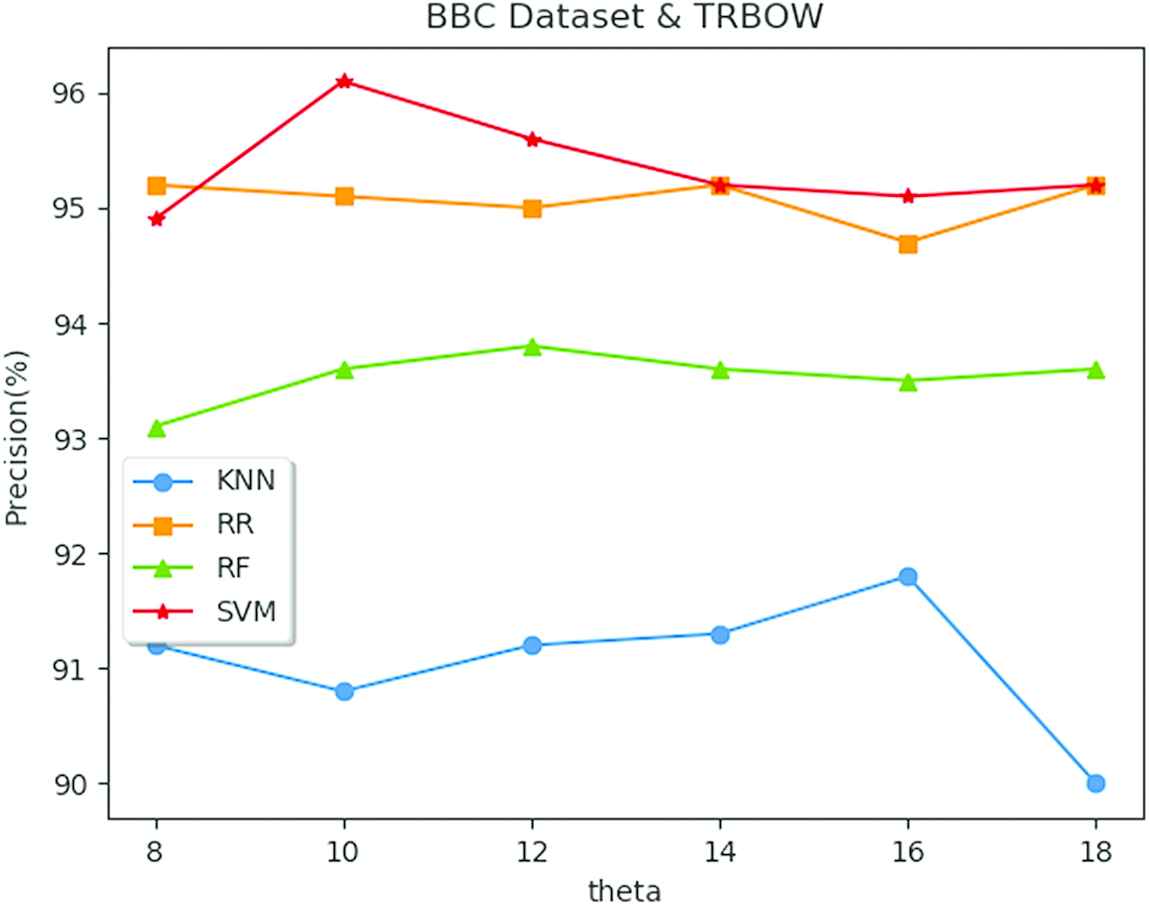
Precision using different classifiers with different threshold value θ.
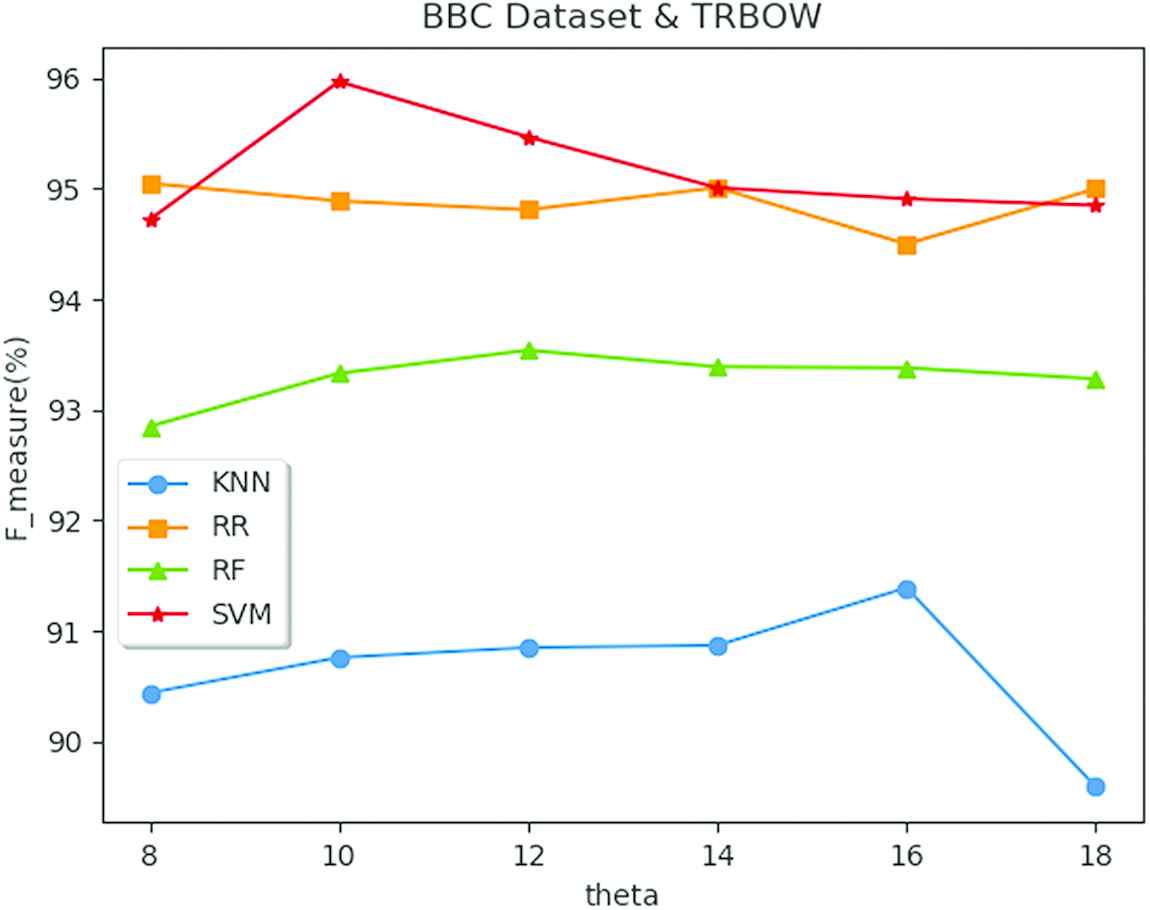
F_measure using different classifiers with different threshold value θ.
6. CONCLUSION
In this paper, we have proposed two novel document representation learning models, TRBoW1 model and TRBoW2 model, which adopt the tolerance rough set model to improve the traditional BoW model. The proposed TRBoW1 model and TRBoW2 model extend each document to its upper approximation. The extended upper approximation can mine the latent semantic relations behind documents, which solves the problems of lacking of latent semantics and the sparsity of the original BoW model. They can learn the document representation without any training or prior knowledge. The experiments have carried out on various document representation methods for text classification on different datasets using classifiers including KNN, RR, RF and SVM. The results of the experiments indicate that the performances have been improved remarkably and allow us to obtain the following conclusions: the highest F_measure of BBCsport is up to 98.30%; the proposed representation methods enrich the representation of BoW, making the improvement in performance up to 27%.
Except for text categorization tasks, the TRBoW1 and TRBoW2 model can be applied in other domains such as information retrieval and document clustering, which will be further studied in the future. Besides, we apply it in the sentence similarity calculation on the basis of this work.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
AUTHORS' CONTRIBUTIONS
These authors contributed equally to this work.
ACKNOWLEDGMENTS
The authors would like to thank the referee for his valuable remarks. This work was supported by The National Natural Science Foundation of China (Grant no. 11671001).
REFERENCES
Cite this article
TY - JOUR AU - Dong Qiu AU - Haihuan Jiang AU - Ruiteng Yan PY - 2020 DA - 2020/08/19 TI - Tolerance Rough Set-Based Bag-of-Words Model for Document Representation JO - International Journal of Computational Intelligence Systems SP - 1218 EP - 1226 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200808.001 DO - 10.2991/ijcis.d.200808.001 ID - Qiu2020 ER -