
A Formal Concept Analysis Approach to Cooperative Conversational Recommendation
 , Manuel Enciso2, , Ángel Mora1, , Manuel Ojeda-Aciego1, *, , Carlos Rossi2,
, Manuel Enciso2, , Ángel Mora1, , Manuel Ojeda-Aciego1, *, , Carlos Rossi2, - DOI
- 10.2991/ijcis.d.200806.001How to use a DOI?
- Keywords
- Formal concept analysis; Simplification logic; Conversational recommender systems; Group recommender systems
- Abstract
We focus on the development of a method to guide the choice of a set of users in an environment where the number of features describing the items is high and user interaction becomes laborious. Using the framework of formal concept analysis, particularly the notion of implication between attributes, we propose a method strongly based on logic which allows to manage the users' preferences by following a conversational paradigm. Concerning complexity, to build the conversation and provide updated information based on the users' previous actions (choices) the method has polynomial delay.
- Copyright
- © 2020 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Current information systems deal with big amounts of data. In these systems two issues have to be addressed: the management of high-dimensional data and the interaction with the users. In this paper we focus on the second one. When users search one or several items from sets with very high cardinality, they can become overwhelmed in many cases. Several techniques have been used to approach this problem: within the general area of Information Retrieval, techniques such as Information Filtering [1] help the user to locate items that meet her/his requirements. In a similar way, recommender systems [2] try to predict which items are more suitable for the user, thus saving her/him having to select the items.
This work focuses on a subproblem that arises when working with datasets of high dimensionality, i.e., datasets with a high number of attributes. This complicates the use of the applications, because the user is forced to choose from a high volume of information (attribute values) in order to complete the search for the items that meet their requirements. For example, if a dataset of diseases has one-hundred attributes (representing symptoms or signals), the user (physician or patient) will have to check dozens of such symptoms to get a diagnosis. In this work, we will approach the problem of dimensionality in the context of cooperative information systems. More specifically, we provide an algorithm for conversational cooperative filtering in high-dimensional datasets.
Another typical use case can be the selection of activities in a tourist destination by a group of travelers, or a process of cooperative diagnosis by a group of physicians. This is also the case, for instance, in e-commerce [2,3], or online travel agencies [4] among other areas. We refer the reader to Section 5 where we review the literature about conversational recommendation.
Our contribution uses formal concept analysis (FCA) as the underlying formal framework [5]. The solid mathematical basis of FCA is built on lattice theory and Galois connections, allowing to mathematically formalize the notion of “concept” (a general idea that corresponds to some type of entity and that can be characterized by some essential features of the class). The mechanisms used to extract these concepts from a dataset in FCA also allow us to hierarchically organize these concepts in the so-called “concept lattice.” An important aspect to emphasize is that the concept lattice captures all the implicit knowledge that can be deduced from a context, which can be described alternatively as a set of implications. The notion of implication is also used in many very different areas, for instance, implications are called functional dependencies in database theory, or the well-known if-then rules in logic programming, just to name a few. In essence, an “attribute implication” is an expression of type
In previous works [6–8], several logic-based algorithms have been introduced to efficiently manage implications with different purposes (redundancy removal, transformation of implicational sets, etc.). In this paper, given a dataset, we extract a knowledge-base in terms of attribute implications and the minimal generators of this knowledge-base are used to drive the recommendation process.
From the procedural point of view, we propose a conversational approach. In this sense, it should be explained that in “standard” (nonconversational) filtering or recommendation processes the user indicates all his preferences at the same time, in a single interaction with the system. On the other hand, in conversational filtering or recommendation processes [9,10], the user's requirements are elicited through an iterative procedure, so that in each step of the dialogue the user indicates his preferences in relation to one (or several) attributes of the dataset.
This conversational scheme is especially suitable when working with high-dimensionality datasets, since otherwise the user would have to provide in a single step the values of tens or hundreds of attributes, which is very laborious. In addition, if a community of users is involved in the recommendation, the so-called group recommendation, a more complex situation arises: we have to combine the different choices of all the users into a common selection.
This work is strongly based on the results provided in [11], where a logic-based algorithm to infer the minimal generators of an implicational system was introduced. These minimal generators are used to build an iterative dialogue. In each step, the members of the group indicate their desired values for some of the attributes of the items they are searching for. Concerning efficiency, although the computation of all minimal generators is NP-hard, the problem we are dealing with does not need all the minimal generators; our approach makes use of an on-demand computation of minimal generators by means of an algorithm with polynomial delay. The main advantage is that it significantly reduces the number of steps in the dialogue, saving users the need to specify their choices for many of the attributes, what makes it suitable to be applied in interactive systems.
Moreover, the algorithm includes aggregation functions to combine the preferences of each group member. A great variety of such functions exist in the literature; depending on the selected function, the behavior of the algorithm differs, e.g., giving greater or lesser relevance to possible extreme values in the preferences of some member of the group.
This work further develops the approach introduced in [12], in which a technique to decrease dialog length in a conversational filtering system was presented. Two important contributions are introduced in this paper: firstly, our new algorithm is proactive, while the previous one was reactive, namely, the algorithm proposes promising directions in the search, instead of reacting to user's choices; secondly, the new algorithm devises a cooperative process oriented to a group of users, whereas the previous one implemented just an individual filtering process.
The structure of the paper is the following: Section 2 shows the theoretical background and introduces a logic-based method to enumerate minimal generators, which is a key point in our conversational process. Section 3 introduces the main contribution of the paper, i.e., the cooperative recommender method. In Section 4 its empirical evaluation, based on a collection of both synthetic and real datasets, is presented. In Section 5 a brief summary of related works is presented. We end the paper with conclusions and prospects for future work.
2. PRELIMINARIES
We recall below some basic notions of FCA (see [5]) which will be used in the extraction and management of knowledge from a dataset.
Datasets are interpreted in terms of formal contexts, i.e., triplets
Each formal context
For each
The pair of derivation operators form a Galois connection between
The main goal of FCA is to extract knowledge from the context allowing to reason about them. One of the ways to represent knowledge is by means of the concept lattice. Another equivalent alternative knowledge representation, more suitable to define reasoning methods, is given in terms of attribute implications.
Definition 1.
[Attribute implication] Given a formal context
The sets
The most reasonable way to handle attribute implications is in terms of logic, and we will work with the Simplification Logic
Definition 2.
[Syntax and Semantics of SL]
Given a non-empty finite alphabet
A context
As usual, for a context
We introduce the axiom system of
Definition 3.
[Axiom system] SL considers the reflexivity axiom
We use the standard notation
The axiom system given above is sound and complete [7], i.e., for all
Knowledge is represented by a set of implications
The inference rules of
In a previous work [11], we devised a method to enumerate all minimal generators. Their inherent order structure allows for managing information similar to that provided by a concept lattice, but in a more succinct form. Concept lattices hierarchically present how objects are grouped together, characterized by a set of common attributes, corresponding with a closed set of attributes. These closed sets can also be identified in the ordered structure of minimal generators, allowing a small representation to be used as the core of our method.
We close this section by formally introducing the notion of closure of a set of attributes which, by the soundness and completeness theorem, is strongly related with the closure in the concept lattice.
Definition 4.
Given
The mapping
Hereinafter, when no confusion arises, we omit the subscript (i.e., we write
Our contribution is strongly based on the following theorem and proposition.
Proposition 2.
[7] For all
Eq. I:
Eq. II:
Eq. III:
A linear algorithm for computing the closure
The following example illustrates the procedure to obtain closures and the corresponding reduced set of implications using the algorithm from [7].
Example 1.
Given
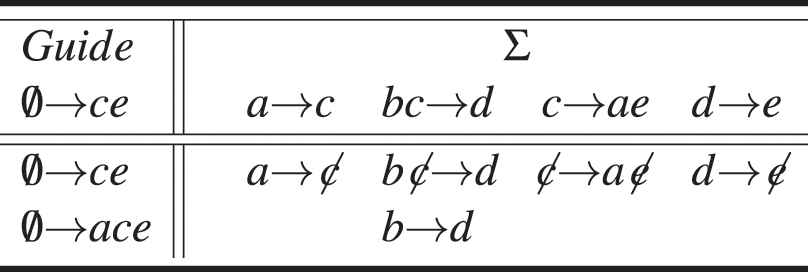
Example of the simplification closure method.
3. OUR PROPOSAL
As stated in the introduction, we introduce a group conversational recommender system following a cooperative paradigm. The usage scenario is that a group of users would like to get a common recommendation, for instance, a group of tourists would like to find a restaurant where gathering together for dinner. Our approach is based on a conversational paradigm, which allows to reach the recommended item by means of an interaction with the users who dialog with the system in order to get a recommendation. In the conversation, preference elicitation is carried out by asking directly to the users.

In this situation some problems arise: how to combine the different user preferences, how to guide the conversation, how to deal with a joint dialogue among the system and the users, how to manage the (possible) information overwhelming of users when offered to choose among a large number of attributes, etc.
To begin with, the information is structured in a binary table where items to be recommended correspond to rows (objects in FCA), and attributes of these items correspond to columns. FCA provides a set of efficient methods to extract a set of rules which represents the knowledge in a suitable way.
The general overview of our approach is the following: the system uses the implicit knowledge in the set of rules stated above, and applies an iterative process in which each iteration can be described, at a high level, as follows:
The system shows just a subset of attributes to avoid information overwhelming. For example, to decide a restaurant for having dinner the users are given a selection of attributes to choose from. These attributes are those which might better discriminate other attributes and shorten the conversation; for this, we focus on the attributes in the LHSs of the rules and, specifically, consider those that belong to some minimal LHS.
Each person in the group chooses a set of attributes that suits him best, adding a degree of preference to the selected items. Following with the previous example, if the items were restaurants, the attributes could be vegetarian cuisine, disabled access, parking, etc.
The preferences of all group members are aggregated taking into account the knowledge represented in the whole set of rules. The aggregation function can be independently customized for each problem.
The set of rules is refined, by using
The resulting items or objects (restaurants in our example) are shown. It is obvious that in each iteration of the dialog, the number of items is decreased.
If the number of the resulting items is acceptable for the users, they can decide to stop the process.
It is worth mentioning that we achieve two important benefits with this approach: on the one hand, we avoid users to express their preferences on large sets of attributes and, on the other hand, the length of the dialogue (number of steps of conversational recommendation process) is shortened with respect to the approach by [15]. These benefits are confirmed by the results obtained in the evaluation of our method (see Section 4).
In order to provide the specific details of the proposed method, the following key points need to be taken into account. The notion of minimal generator is the crux of our contribution in this paper, since they are used to obtain the selection of attributes to be shown to users in each iteration. The method uses Simplification Logic
As stated above, the input of the method is a binary dataset with the information of the items to be recommended. We consider a set of items
The workflow of the algorithm is described in Figure 2. It starts by inferring the implicational system
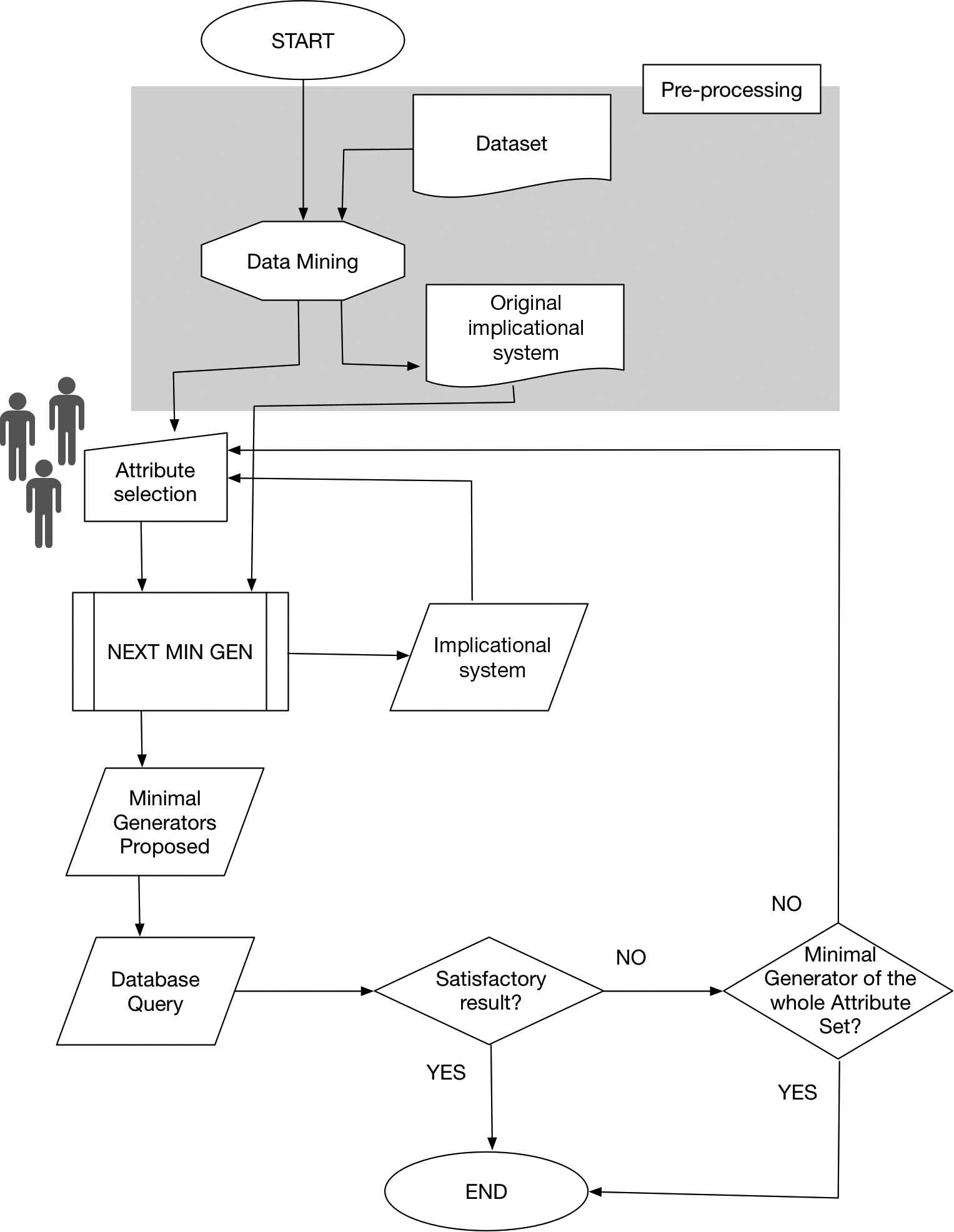
Workflow of the algorithm.
Figure 3 shows the activity diagram (using UML notation) of the implementation of the recommender system based on our algorithm, which is described below:
Activity diagram of the recommender system.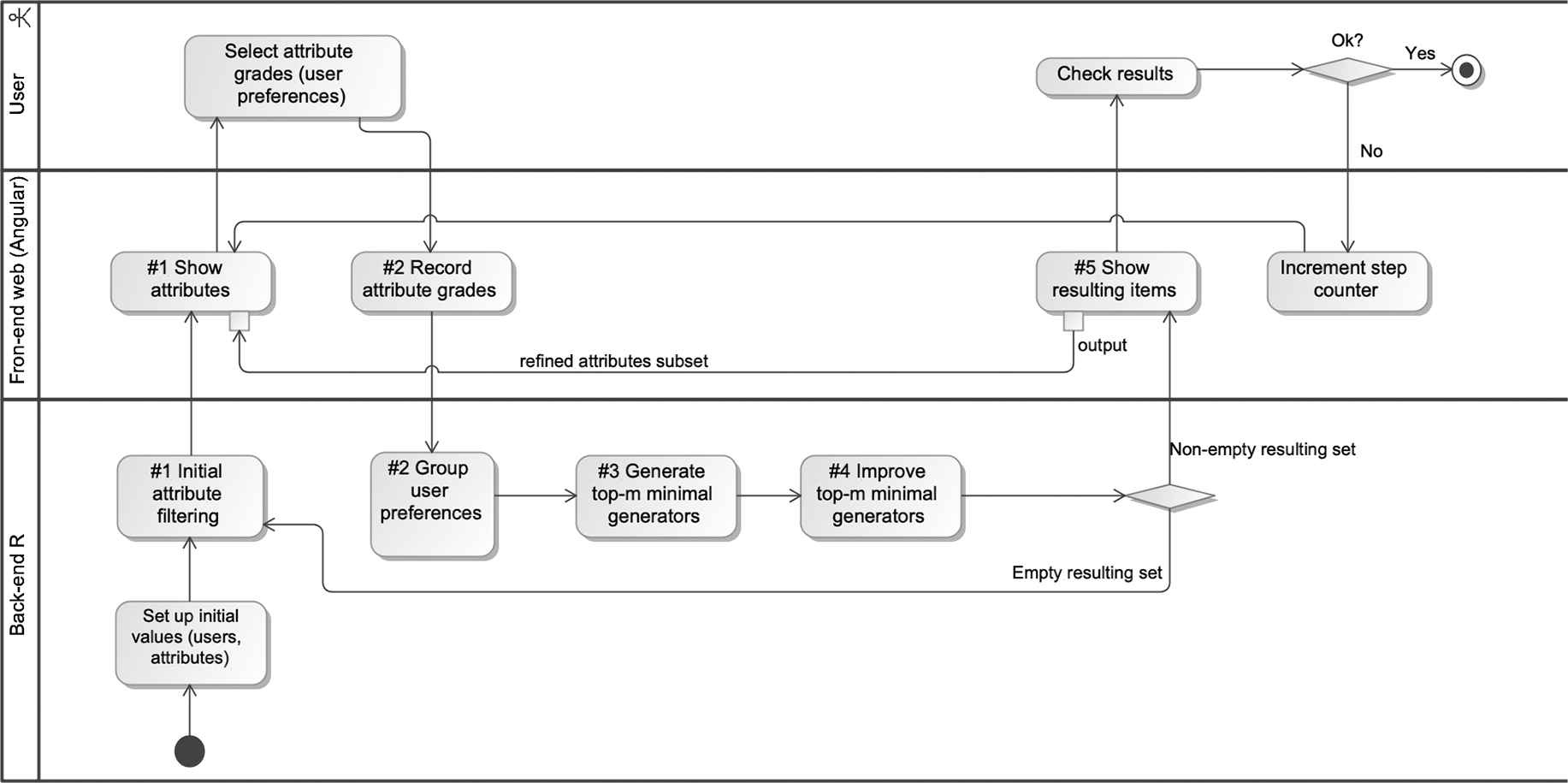
Step #1: attribute filtering.
The method filters the attributes to be presented to the user by selecting just the minimal LHSs (with respect to set inclusion) of the basis
We write
Assume that each user
Step #2: grouping user preferences.
In this step, all the personal preferences provided by the users (
Step #3: top-m minimal generators.
For all
Step #4: top-m minimal generators improved.
These top-m minimal generators could be a good solution to guide the search, but we further improve them by considering the closure of each minimal generator. The goal of this step is to increase the degree
Now, the method considers the set of attributes
Step #5: Resulting items.
If the users consider that the cardinality of
Otherwise, the recommender system initiates another iteration from Step#1, in which NextMinGen reduces the possible choice of attributes to
Complexity considerations.
Steps#4 and #5 make use of the function NextMinGen which, as mentioned above, is linear with respect to the size of the set of implications. The rest of steps have all linear complexity.
We finish the section with an illustrative toy example:
Example 2.
Let
The set
The set of unified degrees (Step#2) is
Since
The closure of the two first minimal generators is computed in Step#4:
The stage for the new iteration (Step#5) is
In (Step#4) we obtain the closure
Therefore, the output of the recommender is the set of objects holding the attributes
4. EVALUATION
The recommender introduced in this paper has been named Cooperative Filtering.2 This section describes the experiments designed to show the advantages of our proposal and evaluate the obtained results. The recommender system has been tested in two different contexts, considering synthetic and real datasets.
The synthetic datasets have been randomly generated in order to show how the method deals with datasets with different sizes. Thus, we have run 329 experiments, the number of attributes ranging from 30 to 80 with an average of 47.69. The number of implications extracted from the datasets ranges from 30 to 200 with an average of 100.
The interaction with the users has been implemented as follows: in each execution, we simulate that three users can choose up to three attributes. Moreover the users select how important these attributes are to them using a 4 point Likert Scale and, using this information about their preferences, the recommender prunes the set of implications and computes which are the attributes to be offered for choice in the next iteration.
The results for the synthetic datasets are very promising: the average length of the dialogue with the users is 3.86 steps. It is remarkable that in the 90% of cases, the length of the dialogue is less than or equal to 4 and the maximum obtained is 7 (see Figure 4).
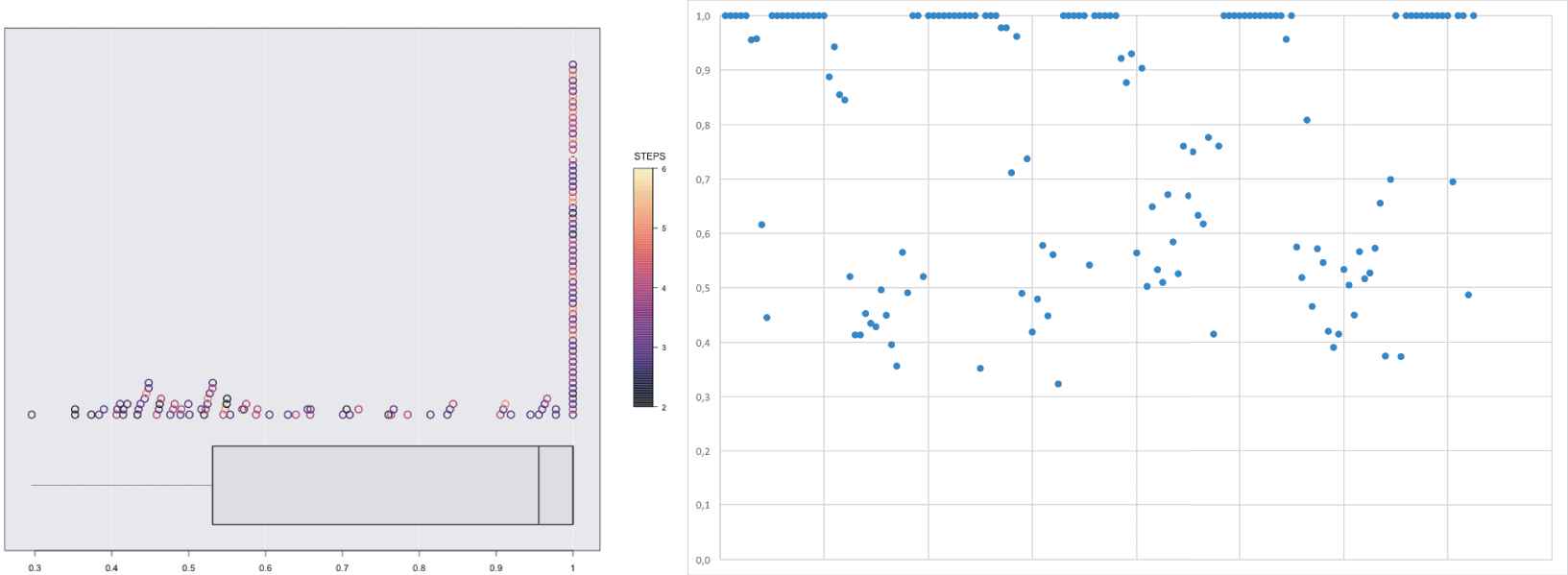
Accuracy with respect to the number of steps and average percentage of satisfied preferences per user.
We have also obtained that the length of the conversation is independent of several parameters related to dimension or size: number of objects, number of attributes, and number of implications. Specifically, the values obtained for Spearman's rank correlation are 0.03, 0.05, and 0.07 respectively. As a result, it seems that the number of steps in the dialogue is mostly related to the structure of the implications, as usual in this type of problems.
In addition to the length of the conversation, another important measure is the accuracy of the results provided by the recommender system. When the system provides a set of objects at the end of the process, we can check how far the characteristics of these objects fit the individual preferences given by the users.
As a general conclusion, the accuracy results are very successful. Figure 4 (right) shows the average of the percentages of satisfaction of preferences per user (the horizontal axis represents just the different experiments). The global average percentage of satisfaction of preferences is 0.7785 which, in our opinion, is a very good value, especially taking into account that it is for a group. The standard deviation is 0.2565 and the values determining the quartiles are the following: 0.219 (min), 0.5117 (25%), 0.8947 (50%), 1 (75%), and 1 (max).
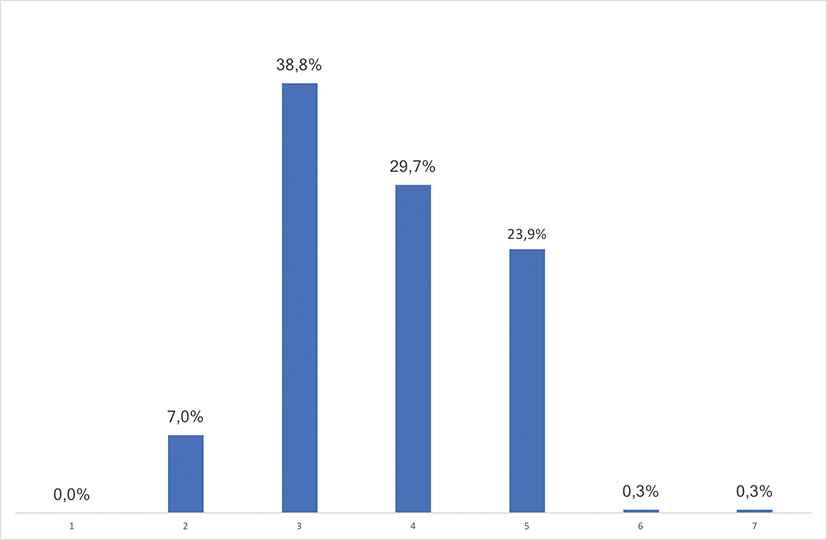
Distributions of the number of iterations of the dialogue in synthetic experiments.
It is worth noting that we have also analyzed the results of accuracy with respect to other dimensions, and we have found that there is no correlation between these values and other parameters of the experiment. Figure 4 (left) shows the relation between level of accuracy and number of steps in the dialog; although, visually, we could think of certain relation between these two dimensions, once again we found that there is no significative correlation between them.
As a second approach, we have also conducted experiments with real datasets.3 the following three public datasets suitable for treatment with our proposal (see Figure 6 for a summary of the features of each dataset):
Celeb.4 The CelebFaces Attributes Dataset (containing information about over 200k images of celebrities with 40 binary attribute annotations). This dataset is often used for training and testing models for recognizing facial attributes. The exact size of the dataset is 202599 rows (persons) and 40 columns (attributes of a person). The number of implications extracted is 63533.
DSK.5 The dataset Disease-Symptom Knowledge Database contains information about diseases and symptoms, with 398 rows (diseases) and 40 columns (symptoms). The number of implications extracted is 10013234.
HPO.6 Extracted from the Human Phenotype Ontology Consortium dataset and used in [12], also contains information about diseases and symptoms. Its size is 446 rows (diseases) and 985 columns (corresponding to symptoms). The number of implications extracted is 3678. 7
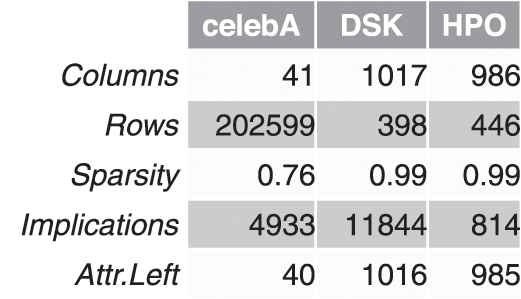
Information about the three real datasets.
The obtained results are summarized as follows: concerning the length of the dialogue, our recommender system, always finishes after a small number of steps independently from the characteristics of the datasets (either having many objects or many attributes, different sparsity in the dataset and different number of extracted implications). Figure 7 shows the number of experiments that finalized with a given length of dialogue. Summarizing, in most of the cases the length of the dialogue is two, 85.3%, 98.7%, and 54.4% for the Celeb, DSK, and HPO datasets, respectively. The cases of three interactions in the dialogue is significant just in the HPO dataset (43.7%) whereas in the other two datasets the percentage is 13.1% and 1.3% respectively. The dialogues four interactions long are just the 1% of the total number (in the three datasets) and the longest interaction was five steps, just in 0,17% of the cases, all of them in the Celeb dataset.
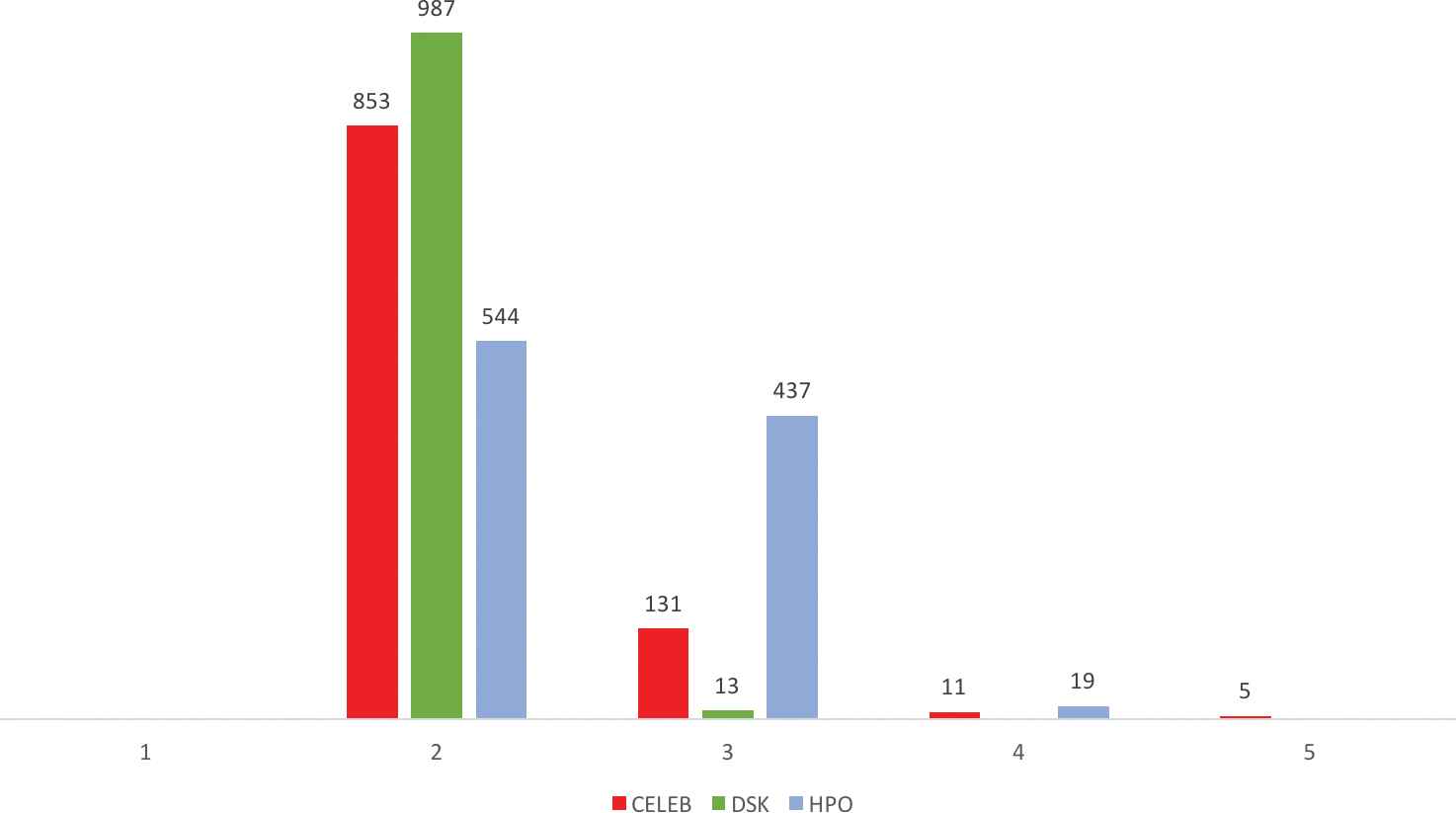
Distributions of the number of steps of the dialogue in real datasets.
Another interesting conclusion inferred from these experiments is the evolution of the number of attributes, objects, implications, and closure sizes while the conversation is being developed. Figure 8 shows that the first three items decrease and the fourth one increase for the Celeb, DSK, and HPO datasets. Cooperative Filtering significantly reduces the number of objects which are filtered and shown to the user. It is also worth mentioning that the method scales adequately in high-dimensions (one thousand attributes for a recommender system). Figure 8 shows how the number of attributes suggested to the users considerably decreases for the three datasets.
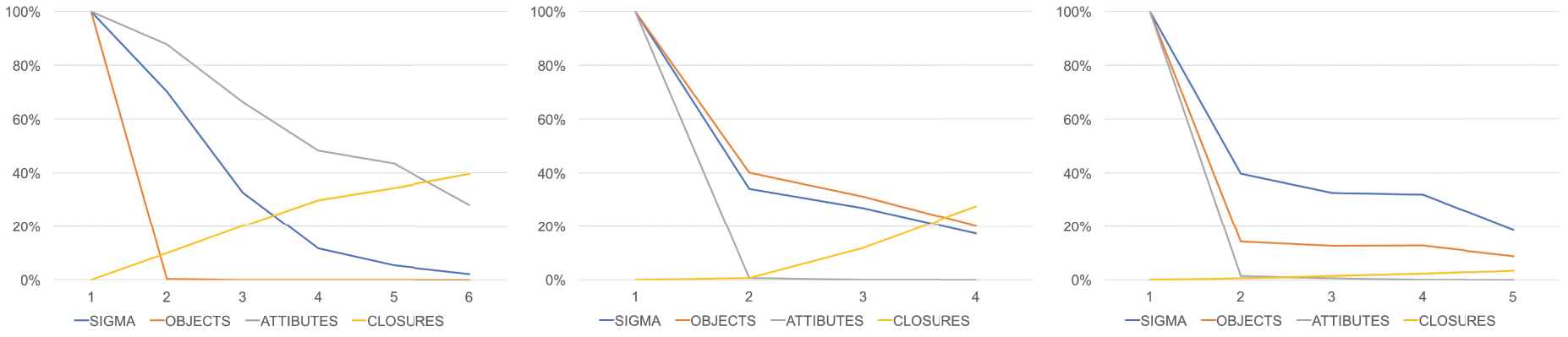
Evolution of the number of attributes, objects, implications, and closure sizes in the Celeb, DSK, and HPO datasets.
To finish with, a recommender system was introduced in [12] where the HPO were also used to experiment with; however, that approach does not consider the collaborative paradigm. The table of Figure 9 shows a comparative with the results obtained there, just measuring the number of steps, the only one considered in that work. Cooperative Filtering reduces the number of steps obtained in this previous work: it does not need more than 3 steps in any execution.

Comparison with a previous work.
5. LITERATURE REVIEW
Similar approaches to this work have been adopted in the so-called conversational recommender systems [19–23], closely related to critiquing recommender systems [24,25]. In these systems, recommendations are incrementally generated by means of a dialogue with the user. In [22], the authors propose a dialogue system similar to ours, although based on different foundations; specifically, they train the recommender with the dialogue state, user information and item information and use the factorization machine (FM) methods.
The goal of decreasing the number of steps of a conversational filtering process also appears in works by Trabelsi et al. [23], using two models (quantitative and qualitative) of attribute dominance, whereas we use FCA and logic instead. With respect to previous works using FCA, we emphasize the approach of [26] using fuzzy information obtained from a locate-based social network and making recommendations according to the users interests. However, their approach is based on the concept lattice obtained from the dataset and neither does it use any implications or logic.
Jannach et al. [27] defend the adequacy of the knowledge-based approach in the conversational process, as we propose as well. Moreover, they use constraint-based reasoning techniques to design a query tightening strategy, similar to our proposal.
Our work is also related to feature selection, an area that has been widely studied in the literature [28]. As it is well-known, its main objective is to identify whether the attributes are meaningful or not. The techniques in this area constitute a good approach to tackle high-dimensionality datasets and they are widely being used to improve the performance of machine learning classification techniques. Different tools have been used in this area, such as mathematical techniques (principal component analysis, linear discriminant analysis, independent component analysis), association rules or evolutionary computing, among others.
Most of these tools follow some noninteractive processing schemes. However, in line with our proposal, other works define an iterative feature selection process. For instance, in [29] we can find a tree-based feature selection process strongly based on fuzzy modeling and fuzzy rules. They obtain good results, but with a significant number of required user interactions when applied to high-dimensional datasets. A similar work is [30], that uses support vector machine as the classification technique. An interactive process is also proposed in [31], where features are processed one by one. Their underlying framework is information theory (mutual information, conditional mutual information, and entropy).
6. CONCLUSIONS AND FUTURE WORKS
In this work, we propose a new framework to manage datasets with high dimensionality. Our approach is strongly based on formal techniques such as FCA and implication logic providing a solid basis and, also, a good performance.
We design a cooperative tool to collect the preferences of a set of users, providing a conversational process to reach a group recommendation. Our goal is to generate a conversation with a small number of dialogue steps. The semantic information stored in the minimal generators is used to drive the recommendation process and some aggregation functions are introduced to join the different preferences of the users.
We propose two lines as future works. On the one hand, some FCA extensions can be used to deal with complex information. As inspirational pieces, the work [32] generates recommendations based on association rules drawn from the concept lattice and [33] defines a collaborative recommendation process using fuzzy annotations in the lattice.
Last but not least, we intend to characterize a set of OWAs that can be used [34] to set up this method for different environments, providing in this way an adaptive tool for different group idiosyncrasies.
CONFLICT OF INTEREST
The authors certify that there is no actual or potential conflict of interest in relation to this article.
AUTHORS' CONTRIBUTIONS
All authors contributed equally to the publication.
ACKNOWLEDGMENTS
Partially supported by projects TIN2017-89023-P, CSO2017-82592-R, and PGC2018-095869-B-I00 of the Ministry of Science and Innovation of Spain, and projects UMA2018-FEDERJA-001 and UMA18-FEDERJA-158 of the Junta de Andalucía, all co-funded by the European Regional Development (ERDF).
Footnotes
The term “neutral” indicates the neutral element for the aggregation function we will use in the following steps.
The code is available in https://github.com/amorabonilla/CooperativeFiltering. In this repository, the file readme.md explains how to use this recommender (and how to install the R packages).
The code and some reproducible examples with the corresponding outputs are available as Rmd and Html files in https://github.com/amorabonilla/CooperativeFiltering. More specifically,
The number of implications depends of the sparsity of the dataset.
REFERENCES
Cite this article
TY - JOUR AU - Pablo Cordero AU - Manuel Enciso AU - Ángel Mora AU - Manuel Ojeda-Aciego AU - Carlos Rossi PY - 2020 DA - 2020/08/19 TI - A Formal Concept Analysis Approach to Cooperative Conversational Recommendation JO - International Journal of Computational Intelligence Systems SP - 1243 EP - 1252 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200806.001 DO - 10.2991/ijcis.d.200806.001 ID - Cordero2020 ER -