
Climbing the Hill with ILP to Grow Patterns in Fuzzy Tensors
 , Loïc Cerf*,
, Loïc Cerf*, - DOI
- 10.2991/ijcis.d.200715.002How to use a DOI?
- Keywords
- Disjunctive box cluster model; Fuzzy tensor; Hill-climbing; Integer Linear Programming; Forward selection
- Abstract
Fuzzy tensors encode to what extent
- Copyright
- © 2020 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Suppose an analyst wants to study the types of chocolate consumers like depending on the regions they live in. If she has the results of a survey where customers from different regions grade the different types of chocolate, she can scale those grades to
This article details the first method to fit a disjunctive box cluster model to an
The disjunctive box cluster model is actually a regression model: the patterns and their densities explain the values in the fuzzy tensor. Using ordinary least squares, fitting such a model to a fuzzy tensor aims to minimize the sum of the squared differences between every value in the fuzzy tensor (e.g., Table 1) and the analog value in the predicted tensor (e.g., Table 2). In that framework, Mirkin and Kramarenko prove [2] that the pattern that, alone, best summarizes the tensor is the one with the greatest area (the number of cells it contains) times density squared [2], hence a statistically founded formalization of the usual desire, in the pattern-mining community, to discover large and dense patterns in fuzzy (or simply 0/1) datasets.
| Bitter | Crunchy | Milky | Semisweet | Sweet | White | |
|---|---|---|---|---|---|---|
| South | 0.29 | 0.05 | 0.89 | 0.04 | 0.94 | 0.89 |
| Southeast | 0.69 | 0.76 | 0.83 | 0.84 | 0.98 | 0.87 |
| North | 0.82 | 0.96 | 0.15 | 0.49 | 0.87 | 0.51 |
| Northeast | 0.52 | 0.09 | 0.86 | 0.07 | 0.94 | 0.48 |
| West-Center | 0.91 | 0.81 | 0.05 | 0.73 | 0.33 | 0.39 |
A fuzzy matrix, a pattern (all grayed cells) and a fragment of this pattern (darker cells).
| Bitter | Crunchy | Milky | Semisweet | Sweet | White | |
|---|---|---|---|---|---|---|
| South | 0 | 0 | 0.85 | 0 | 0.85 | 0.85 |
| Southeast | 0.77 | 0.77 | 0.85 | 0.77 | 0.85 | 0.85 |
| North | 0.77 | 0.77 | 0 | 0.77 | 0.77 | 0 |
| Northeast | 0 | 0 | 0.85 | 0 | 0.85 | 0.85 |
| West-Center | 0.77 | 0.77 | 0 | 0.77 | 0.77 | 0 |
Fuzzy matrix predicted by the disjunctive box cluster model composed of the two highlighted patterns of densities
To discover patterns that are good explanatory variables for a disjunctive box cluster model, the present article proposes to first run an existing algorithm that provides many small high-density patterns. They are here called fragments because the second step grows each of these fragments, one by one, by hill-climbing in the space of the cardinalities of the pattern dimensions, until reaching a pattern having a locally maximal area times density squared. For example, the fragment of size
The main contributions of this article are
The disjunctive box cluster model is shown to generalize the Boolean CANDECOMP/PARAFAC (CP) decomposition;
The first pattern-based method to decompose fuzzy tensors is presented (existing approaches need to round the values in
Experiments show it discovers high-quality patterns in fuzzy tensors and outperforms state-of-the-art algorithms when applied to 0/1 tensors, a special case.
After a few basic definitions in Section 2, Section 3 discusses the related work. In particular, it presents the disjunctive box cluster model. Section 4 details the proposal to fit (but not overfit) such a model to a fuzzy tensor. Section 5 shows the proposal successfully identifies patterns in real-world and synthetic fuzzy tensors and outperforms existing algorithms when the tensor is 0/1. Section 6 concludes the paper.
2. BASIC DEFINITIONS
Given
Given an
3. RELATED WORK
The above definition of a pattern is purely syntactical. To be semantically relevant, a pattern must contain a “large” number of
3.1. Complete Algorithms
Given a 0/1 matrix, AC-Close [4] grows its all-ones sub-matrices, mined in a preprocessing step, into patterns with dense rows and columns: the proportion of 1 in every row must exceed a user-defined minimal density threshold and so does the proportion of 1 in every column (but the threshold may be different). Those patterns are forced to be closed too: any super-pattern has at least one row or column that is not dense enough. Poernomo and Gopalkrishnan use Integer Linear Programming (ILP) to output the same type of pattern [5] or a similar type of pattern [6] where the absolute number of 0 in any row/column is upper-bounded.
Given a 0/1 tensor, several algorithms, e.g., Data-Peeler [7], list its all-ones sub-tensors that are closed, i.e., any strict super-pattern includes an
multidupehack [11] generalizes Data-Peeler to fuzzy tensors:
Dense Cluster Enumeration (DCE) [12] is the only other complete algorithm to mine patterns in fuzzy tensors. Cerf and Meira show that DCE's definition catches patterns that are not sub-patterns of any pattern planted in a synthetic dataset, even if little noise affects that dataset [11]. In contrast, multidupehack's patterns do not go over the edges of the planted patterns, unless the tensor is very noisy. Moreover, multidupehack scales better than DCE. Yet, increasing its bounds
3.2. Heuristic Algorithms
Several algorithms [15–20] approximately factorize
BCP_ALS [19] heuristically seeks a good CP decomposition of a 0/1 tensor by Alternating Least Squares. Distributed Boolean Tensor Factorization (DBTF) [20] distributes that method on the Spark framework and exhibits near-linear scalability w.r.t. the size of the 0/1 tensor, its density, the rank
Nonnegative tensor decomposition techniques can be applied to fuzzy tensors. Nevertheless, they model the data in a fundamentally different way: elements of the
Mirkin and Kramarenko map pattern mining in 0/1 tensors to a regression problem: [2] the set
Encoding
The TriclusterBox algorithm repeatedly searches for one single pattern
4. FITTING A DISJUNCTIVE BOX CLUSTER MODEL
Given a fuzzy tensor, the present proposal discovers patterns that heuristically minimize the residual sum of squares (2) of the disjunctive box cluster model (1). Three successive steps are taken:
Mine fragments of the patterns to discover;
Grow every fragment into a super-pattern that locally maximizes
Select a subset of the grown fragments so that Model (1) fits but does not overfit the data.
In the experimental section, multidupehack [11] (see Section 3.1) provides the so-called fragments: small patterns that are sub-patterns of those in the desired disjunctive box cluster model. Another algorithm can be used though. The algorithmic contributions of this article deal with Steps 2 and 3. Sections 4.1 and 4.2 detail two different ways (that can be successively applied) to grow a fragment (Step 2). Section 4.3 proposes a forward selection for Step 3.
4.1. Bigfoot
Like TriclusterBox [2], the algorithm proposed in this section repeatedly searches by hill-climbing for one pattern that locally minimizes the residual sum of squares (2) of the disjunctive box cluster model (1), i.e., that locally maximizes
The fuzzy tensor
Computing
The fragment
Algorithm 1's efficiency mainly depends on the time it takes to find the pattern

Constraints (7) and (8) force all variables
However, according to Problem (3),
The reason why
Finally, at line 11 of Algorithm 1, giving
4.2. Bigfoot-LR
To maximize
Taking the
Given the inputs of Algorithm 1, the innermost sums (one sum for each element

Bigfoot-LR is the name given to Algorithm 1 when
Nevertheless, Bigfoot can further grow those patterns. They become the argument
4.3. Forward Selection
The disjunctive box cluster model composed of all the patterns that Bigfoot, Bigfoot-LR or Bigfoot-LR+Bigfoot outputs overfits the fuzzy tensor. A well-chosen subset of those patterns usually makes a statistically more relevant model, i.e., a simpler (with fewer patterns) disjunctive box cluster model (1) whose residual sum of squares (2) is not significantly higher. Stepwise regression aims to heuristically select such a subset of the candidate explanatory variables (the computed patterns). The search of a trade-off between the goodness of fit and the simplicity is formalized as the minimization of a measure, e.g., the Akaike information criterion (
That formula considers that the models, the subsets of
Algorithm 3 formalizes the recursive forward selection (the chosen stepwise regression technique) of the disjunctive box cluster model

5. EXPERIMENTAL VALIDATION
multidupehack [11], Bigfoot, Bigfoot-LR and TriclusterBox [2] are all distributed under the terms of the GNU GPLv3. They are implemented in C++ and compiled by GCC 5.4.1 with the O2 optimizations. The implementation in C of W
5.1. Real-world Tensors
5.1.1. A 3
The first real-world fuzzy tensor used in this section is
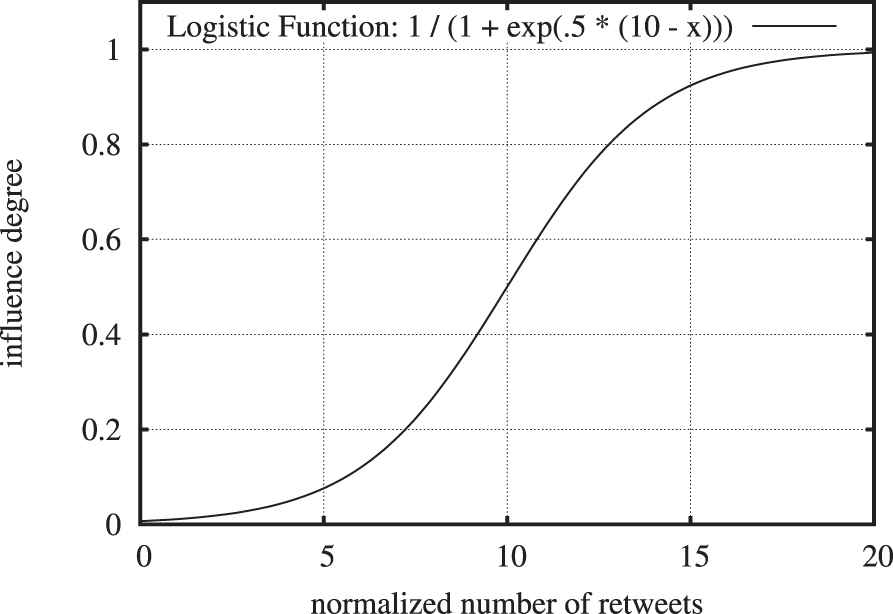
Curve of the logistic function chosen to turn normalized numbers of retweets into influence degrees: 10 normalized retweets map to “moderately influential.”
multidupehack [11] provides the fragments. Three minimal size constraints are enforced (see Section 3.1): at least eight users, three teams and four weeks. With the upper-bounds
However, Bigfoot can directly process, in a reasonable time, an alternative collection of fragments. By reducing the minimal number of teams in a fragment to two but forcing these fragments to be denser (with
| {Botafogo, Flamengo, | |||
| 31 | 12 | Fluminense, Vasco} | |
| 28 | 11 | {Corinthians, Palmeiras, Santos} | |
| 14 | 10 | {Avaí, Figueirense} | |
| 17 | 7 | {Grêmio, Internacional} | |
| 15 | 11 | {Flamengo, Fluminense} | |
| 17 | 12 | {Flamengo, Vasco} |
Disjunctive box cluster model, discovered by Bigfoot, of the
Every discovered pattern only involves teams from one single state. For example, the first pattern involves four teams from Rio de Janeiro. The explanation is simple: who is influential when writing about a given team is likely influential when writing about its rivals, in the same state. The identifiable users involved in a given pattern are either journalists, who are indeed influential, or supporters of one of the teams in the pattern. The first four patterns do not intersect, a property favored by the forward selection, as explained in the last paragraph of Section 4.3. The last two patterns intersect with each other and with the first pattern in the table. Yet, their addition to the disjunctive box cluster model makes it significantly more accurate (smaller
TriclusterBox [2], Walk'n'Merge [16] and DBTF [20] only handle 0/1 tensors. To use them, every membership degree in the fuzzy tensor is rounded to 0 or 1. It takes TriclusterBox ten hours of computation to only grow one single pattern out of
5.1.2. A 4
The second real-world application analyzes the usage of the bicycle sharing network in Lyon, France. That network consists of
To discover in the
The hill-climbing procedure has to be modified too: at line 9 of Algorithm 1, one single index stands for both the departure and the arrival stations and the related iterations increment/decrement both
With
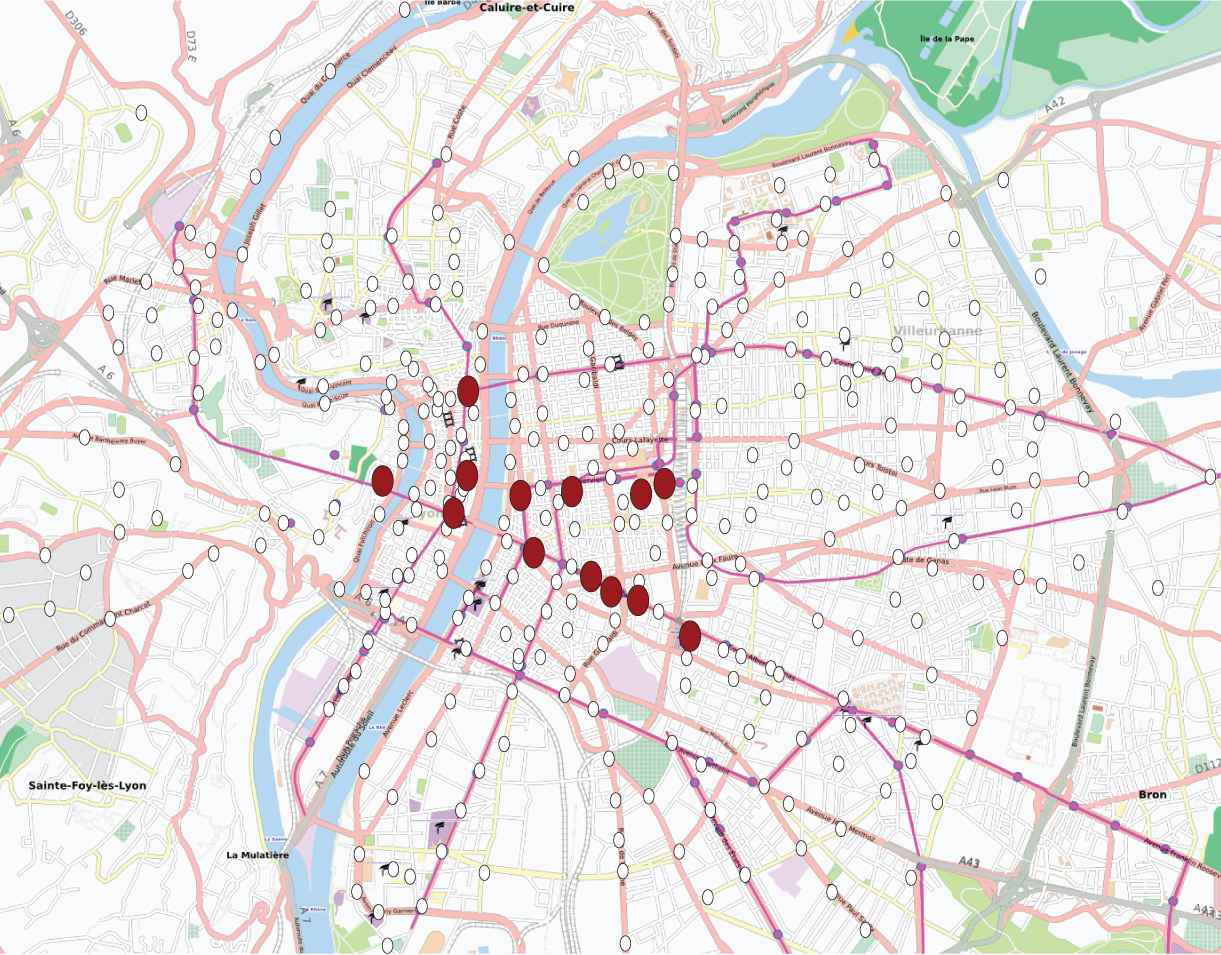
Thirteen large stations in the working and commercial districts of Lyon. They exchange many bicycles everyday from midday to 8pm, except on Sundays, when the shops are closed.
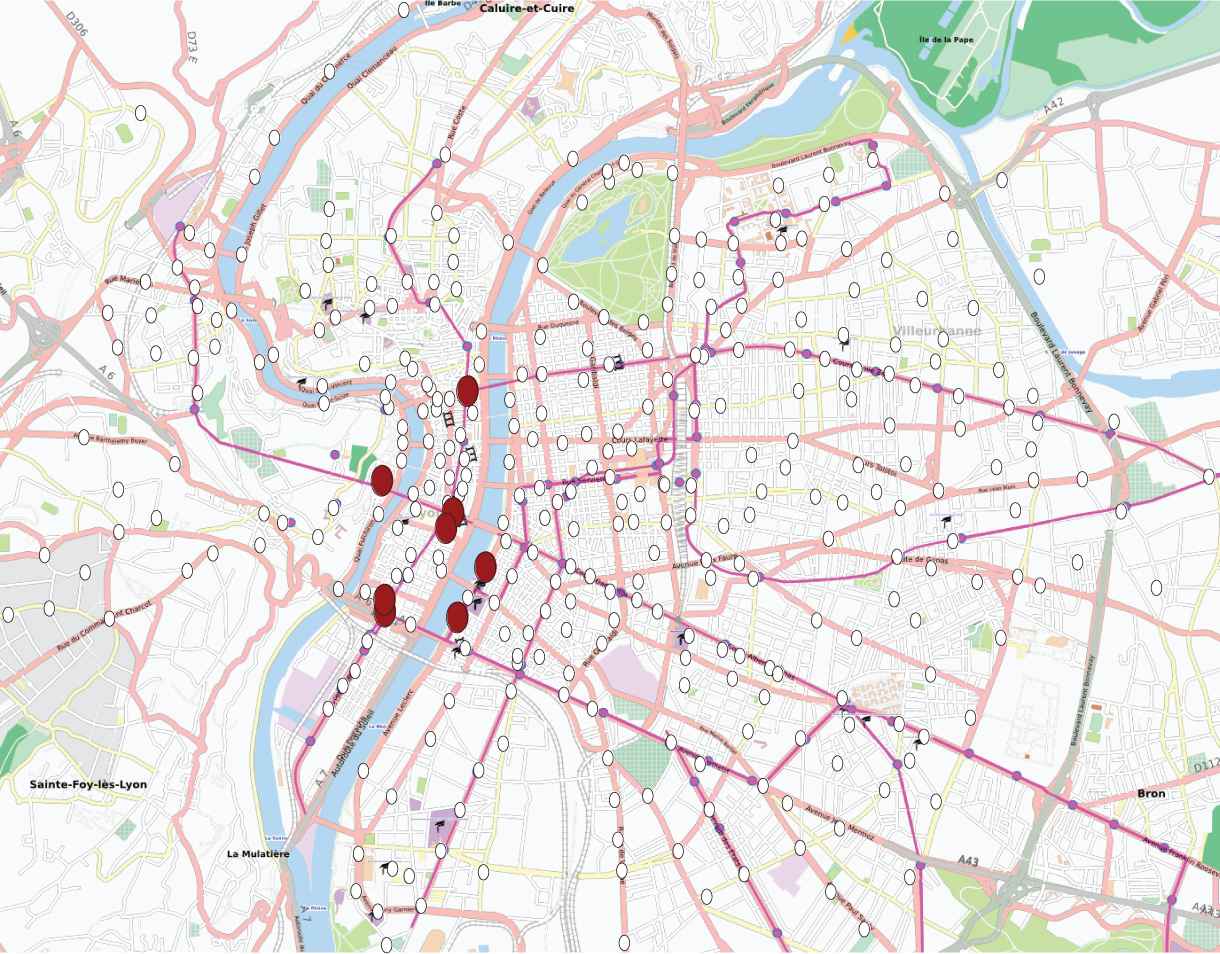
Eight large stations around the main squares of Lyon, in its historical center. Everyday, from 8am to 10am and from midday to 9pm, many users ride between those stations.
5.2. Synthetic Tensors
The actual patterns to discover in real-world tensors are unknown. To assess to what extent Bigfoot and its variations can recover patterns, this section uses synthetic tensors affected by controlled levels of noise. Four “perfect” patterns (i.e., only containing
Considering every 0 or 1 in a “perfect tensor” as the output of a Bernoulli variable with parameter
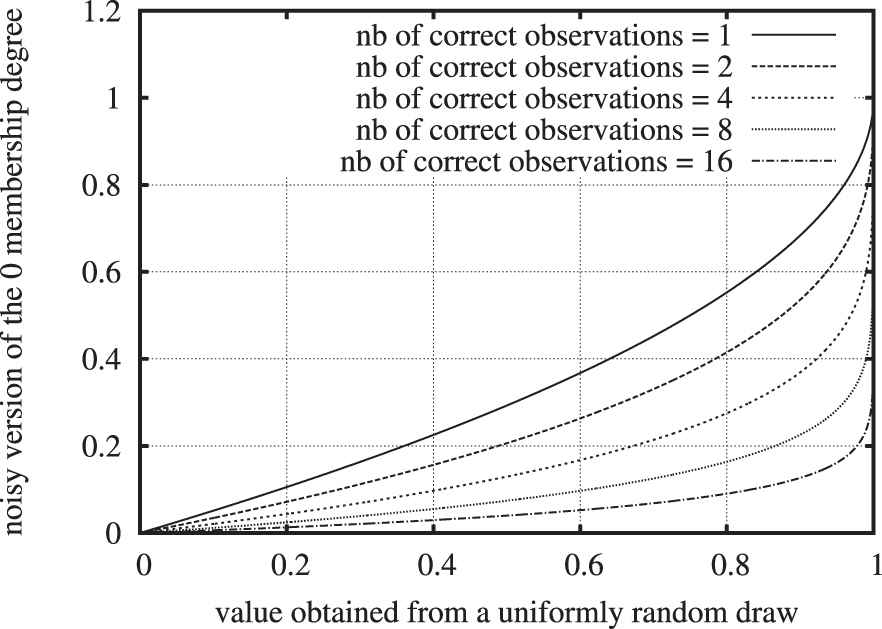
Inverses of cumulative beta distributions used to noise a membership degree at 0 in a “perfect” tensor. More “correct observations” mean less noise.
Given a planted pattern
That measure, in
Figure 5 shows the quality of the discovered patterns, their numbers, and the run times, in function of the level of noise in the
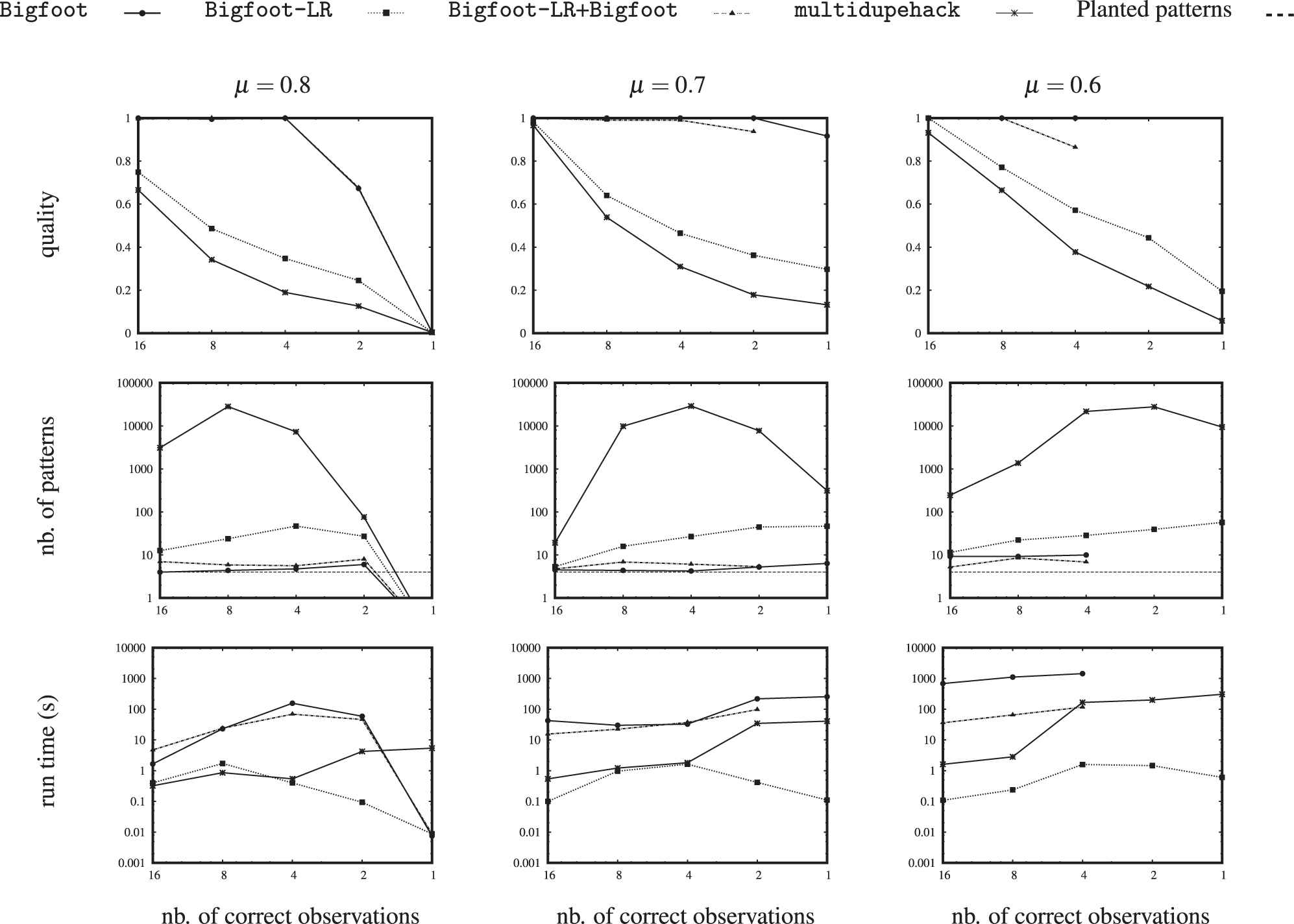
Qualities, numbers of patterns and run times of multidupehack, Bigfoot, Bigfoot-LR and Bigfoot-LR+Bigfoot mining noisy 3-way tensors (the level of noise increases from left to right).
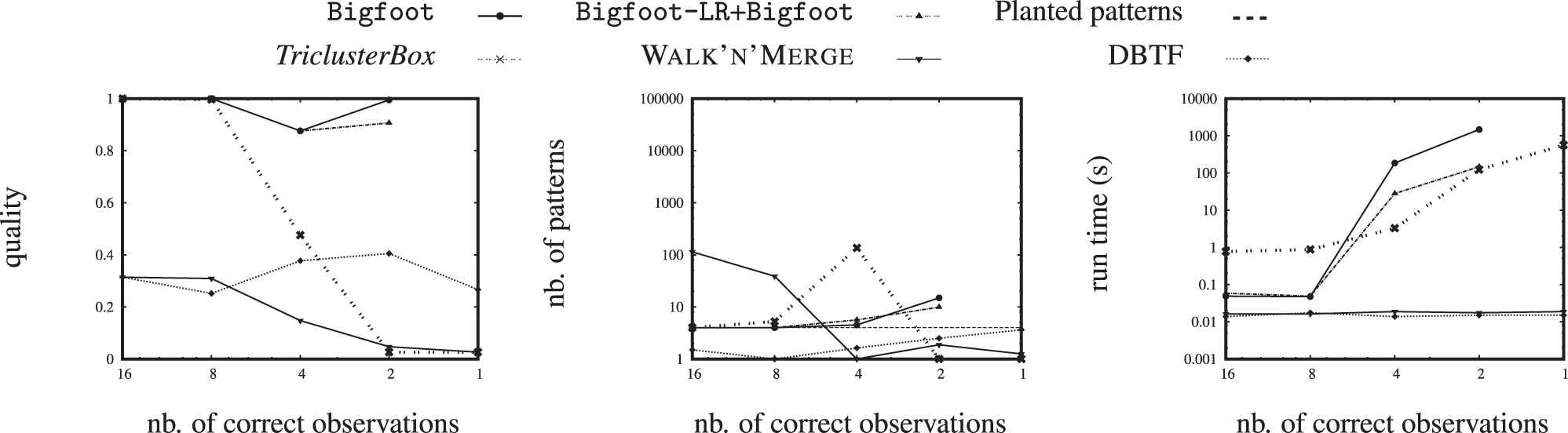
Qualities, numbers of patterns and run times of the competing methods mining noisy 3-way 0/1 tensors (the level of noise increases from left to right).
multidupehack returns up to hundreds of thousands of fragments. They poorly match the planted patterns, unless the level of noise is very low (16 correct observations). Nevertheless, Bigfoot and Bigfoot-LR+Bigfoot, which both process multidupehack's outputs, reach significantly higher qualities after the forward selection that keeps numbers of patterns that are close to four, the number of planted patterns. Bigfoot is always the best performer. That is, when it is actually given fragments to grow and when it runs within one hour, the chosen timeout. Bigfoot can indeed require much time, especially to grow fragments of low density in noisy tensors. Bigfoot-LR is very fast but it returns terrible patterns, enhanced fragments that need more growing. Using Bigfoot to further grow them, Bigfoot-LR+Bigfoot often outputs the same patterns as Bigfoot alone. When it does not, the obtained qualities are slightly lower. Given the least dense fragments (
Bigfoot and its variations handle
Figure 6 shows that Bigfoot does not always reach the qualities reported in Figure 5: rounding to 0/1 harms the ability to recover the planted patterns. Despite that, Bigfoot and, to a lesser extent, Bigfoot-LR+Bigfoot, are clearly better than TriclusterBox, Walk'n'Merge and DBTF at recovering the planted patterns from the noisy 0/1 tensors. The competitors are faster though, especially in the noisiest settings.
6. CONCLUSION
Discovering a disjunctive box cluster model is a problem that generalizes the Boolean CP tensor factorization: every pattern (rank-1 tensor) is weighted by a parameter to estimate. Searching for patterns one by one, the optimal weights simply are their densities. Such a disjunctive box cluster model therefore is more informative than a Boolean CP factorization but it remains easy to interpret. Moreover, it suits fuzzy tensors and not only 0/1 tensors.
This article has presented the first solution to decompose fuzzy tensors into patterns. It grows pattern fragments and selects a small number of grown patterns to fit but not overfit the fuzzy tensor. Various techniques have been combined. In particular, every pattern is grown by hill-climbing and an integer linear model has been defined to have an existing solver efficiently find the pattern at the next iteration. Since solving ILP problems may take exponential time, a linearly relaxed variation of the problem has been presented as well. The related algorithm is less effective but can be used in a preprocessing step. Finally, a recursive forward selection composes the returned model, a subset of the grown patterns, by greedily minimizing the AIC.
Experiments have shown that the method successfully recovers patterns in noisy synthetic tensors. It even outperforms state-of-the-art approaches when the tensor is 0/1, a special case. Relevant patterns have been found in two real-world fuzzy tensors with tens of millions of values. Future work includes extending the integer linear model and exploring other algorithmic approaches to even more accurately and efficiently fit a disjunctive box cluster model to a fuzzy tensor.
CONFLICTS OF INTEREST
The authors have no conflict of interest to declare.
AUTHORS' CONTRIBUTIONS
Lucas Maciel designed, implemented and evaluated most of the proposal. Jônatas Alves helped him with the experiments on synthetic tensors; Vinicius Fernandes dos Santos with the definition of the ILP problem; Loïc Cerf with the forward selection, the computation of
ACKNOWLEDGMENTS
The work has been partially funded by the Fundação de Amparo à Pesquisa do Estado de Minas Gerais under Grant number APQ-04224-16.
APPENDIX
This appendix deals with the efficient computation of
However, the worst patterns in
A lower bound of that sum is the sum of its negative terms. The term relating to the
The smaller
That lower bound is tight. It is reached when future iterations add to the model patterns at least as dense as
The patterns in

Footnotes
Bigfoot stands for Bigfoot Is Growing Fragments Out Of Tensors. It did not exist in nature. We designed it.
REFERENCES
Cite this article
TY - JOUR AU - Lucas Maciel AU - Jônatas Alves AU - Vinicius Fernandes dos Santos AU - Loïc Cerf PY - 2020 DA - 2020/07/29 TI - Climbing the Hill with ILP to Grow Patterns in Fuzzy Tensors JO - International Journal of Computational Intelligence Systems SP - 1036 EP - 1047 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200715.002 DO - 10.2991/ijcis.d.200715.002 ID - Maciel2020 ER -