
A Novel Combinational ATP Based on Contradiction Separation for First-Order Logic
 , Yang Xu2, Feng Cao1, 2,
, Yang Xu2, Feng Cao1, 2, - DOI
- 10.2991/ijcis.d.200521.001How to use a DOI?
- Keywords
- First-order logic; Theorem proving; Prover9; Contradiction separation rule; Dynamic multi-clause synergized deduction
- Abstract
At present, most of the first-order logic theorem provers use a binary-resolution method, which can effectively solve the general first-order logic problems to a certain extent. However, the cooperative processing ability of this method for multiple clauses is insufficient, and it is easy to cause rapid expansion of clause set in the deductive process. In this paper, we propose a novel first-order logic theorem prover based on the standard contradiction separation (S-CS) rule. This prover can realize the dynamic cooperative deduction of multiple clauses in each deduction process, as well as it can effectively learn and control the deduction process. This paper incorporates the S-CS rule with the well-known prover Prover9, to build a combined system, which effectively integrates the advantages of the two methods, not only improves the binary-resolution prover's ability, but also solves more than 100 problems that cannot be solved by other provers.
- Copyright
- © 2020 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
As an essential branch of artificial intelligence, automated reasoning has always been a research hotspot, especially the development of formal verification puts forward higher requirements for the automated theorem prover (ATP) [1–3]. At present, most of first-order theorem (FOF) provers (in the sequel simply provers) are based on the resolution method proposed by Robinson [4]. Mainly adopt the saturation algorithm framework for proof search [5]. That is, given two sets of the P (processed set) and the U(unprocessed set), initializing all clauses into the U and selecting one clause from U each time. Then making a binary resolution with the clauses in process, and putting the resolvents into U. This method inevitably produces a large number of resolvents, and hence bring a rapid expansion of the proof-search space.
Furthermore, only two clauses are resolved at a time. Not only the processing efficiency is low, but the correlation between multiple clauses is ignored. Modern provers introduces hyper-resolution [6] into the saturation algorithm framework, and achieves the resolution of one clause and multiple unit-clauses. To some extent, the collaborative processing ability between multiple clauses is considered, and excellent results have been achieved in practice. However, multiple nonunit clauses cannot be processed cooperatively. In 2018, Xu et al. [7] proposed a standard-contradiction-separation rule (in the sequel simply S-CS, also see Section 2)-based dynamic multi-clause synergized automated deduction. The standard contradiction separation (S-CS) rule is a novel inference rule. Unlike binary resolution, the S-CS rule allows multi-clause to deduction together (also call synergy). And the rule implies the thought of dynamic control of the deduction process, which has higher deductive efficiency. In the paper [8] shown this point.
In this paper, our contribution is, firstly, we propose an architecture of prover based on S-CS Rule. We were discussing some problems of applying the S-CS rule to proof-search. Then analyzed the characteristics of heuristic strategy based on S-CS rule. Finally, we proposed and implement a novel combinational system, CoProver, which integrates the advantages of the S-CS rule and traditional binary resolution. Experimental results show that the S-CS rule has better poof-search ability than traditional binary resolution. Furthermore, the CoProver solves more than 100 problems with rating = 1 that cannot be solved by other existing provers in the TPTP library.
The structure of this paper is as follows: Firstly, we review the current development of ATP and analyze the problems of the traditional binary resolution methods.
Section 2 introduces the basic concepts of the Contradiction Separation rule and notations and conventions of ATP.
In Section 3, we describe the specific design strategy of our proposed prover based on S-CS rule and describe the key technologies for implementing this prover.
Section 4 introduces the construction of a hybrid system based on our proposed provers.
In Section 5, a series of experiments are conducted, and the experimental results are evaluated.
Finally, in Section 6, we give conclusions and our future research directions.
2. PRELIMINARIES
In this paper, we are primarily interested in the first-order formula in conjunctive normal forms (CNF). We assume the following notations and conventions.
Definition 2.1.
[9] (Term). A term is defined inductively as follows:
Each free variable and each constant is a term.
If t1, ‥, tn are terms and f is an n-ary function symbol, the
The set of all terms is called T. We write the
A term is written as lower-case with a number, e.g., “t1, s1,” especially, term
Definition 2.2.
[10] (literal). A literal is an expression A (a positive literal) or ~A (a negative literal), where A is an atom.
An atom (or atomic formula) is an expression P(t1, …, tn) where P is a predicate symbol of arity n and t1, …, tn are terms. Two literals A and ~A are said to be complementary.
We write the letter “l” with a number for literal, e.g., l1, l2.
Definition 2.3.
[9] (clause). A clause C is a finite set of literals and their disjunction, written as
Let S is a clause set, usually, is written
Definition 2.4.
[9] (substitution). A (variable) substitution is a mapping
Xu [7] proposed the new reference rules standard contradiction separation rule (S-CS).
Definition 2.5.
[7] (Contradiction) Suppose a clause set
Definition 2.6.
[7] (S-CS Rule in First-Order Logic) Suppose a clause set
For each
3. PROVER BASED ON S-CS RULE AND KEY TECHNOLOGIES
This section will discuss the design strategy of a novel prover based on the CS rule and the solutions to critical technologies. From Section 2, we can see that the core of CS rule is constructing the SC and obtaining the contradiction separation clause(S), which is the
3.1. The Architecture of Provers Based on the S-CS Rule
We build two sets of U (unprocessed clause set) and P (processed clause set) by using the current mainstream given-clause framework. We initialize the clauses and put all of them into U to present an improved architecture, as shown in Figure 1.
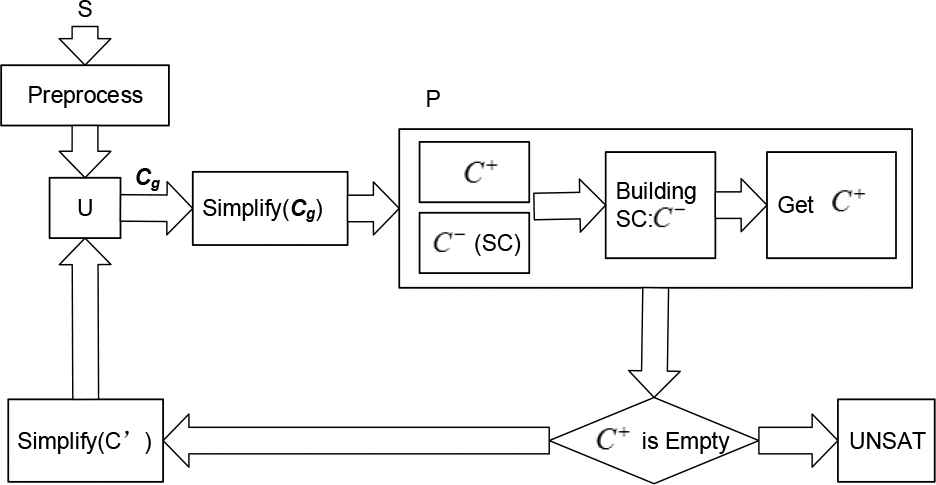
The architecture of provers based on standard contradiction separation (S-CS) rules.
The workflow is as follows:
Step 1. Initializing and preprocessing all clauses in S and put them into U.
Step 2. Obtaining the given-clause Cg according to heuristic strategy.
Step 3. Simplifying Cg, according to some simplified rules and puts the result into set P.
Step 4. Applying the S-CS Rule to Cg to divide it into
Step 5. Applying CS Rule to obtain the contradiction separation clause
Step 6. If
Step 7. Obtaining a new clause C' from
Step 8. Repeating Step 1.
As can be seen from the above framework process, implementing the ATP based on the S-CS Rule needs to solve the following key points:
Constructing the SC
Obtaining the given-clause Cg.
Employing dynamic learning heuristics strategy in deduction
3.2. Dynamic Construction of the SC
3.2.1. The process of separating SC
Unlike a traditional binary resolution, the CS rule is essentially a dynamic, multi-clauses deduction rule. It should be noted that the contradiction separation clause
The SC is separated from multi-clauses in the P. Intuitively, the deductive based on S-CS Rule is the process of obtaining
According to Definition 2.1, the contradiction is a cartesian set. The core of applying the S-CS rule is effectively separating CS from multi-clauses to obtain the contradiction separation clause
Thus, we propose a method to obtain
Step 1. Obtaining given-clause Cg =
Step 2. Find a substitute
Step 3. If
Step 4. Finding a substitute
Step 5. Repeating Step2 until no substitute
Step 6. Putting
The pseudo-code in Figure 2 is correspond to the above process of build SC, when Cg added to P, we can obtain a new contradiction separation clause C+ in the deduction. This process is dynamic. Finally, C+ is the result of multi-clauses cooperating.

The pseudo-code for Bulid standard constradiction algorithm.
In the above process, there will be some cases of given-clause Cg:
All literals need to be removed from
Because they are complementary to
Because they are complementary to
No literal is removed from Cg.
No newly generated CS and Cg remain in P.
Some literals are removed from
It is the most common case, which means that the S-CS rule is successfully applied with Cg so that the new C+ can be obtained.
3.2.2. Restart
The technology for finishing the current CS construction process and starting a new deduction process is called the restart. Employing some restart strategies can avoid falling into a local search.
Restarting when all literals are removed from Cg in Step 4.
Obviously, in this case, the number of words in the C+ is the least. Thus, by removing some literals from C+ without adding new ones in it, we can restore all substitution (rollback) and put the Cg back to U.
Restarting when the clause cannot be selected from U.
In this case, either set U is empty, or each clause in U participating in the deduction is invalid.
Note that we say a clause is invalid has two situations: the case i) and some constraints are not met. For example, the maximum number of literals in C+ is 2, but when some given-clauses participate in deduction, this limit is exceeded.
The restart process is as follows:
Adding all clauses in P to U and clearing the set p.
Simplifying set U and removing redundant clauses.
Selecting clause Cg from U again and putting it into P according to the selection strategy to start a new round of deduction.
3.3. Clause Selection Strategy Based on S-CS Rule
A powerful ATP requires three elements [11]: 1). Powerful inference rules; 2). Good heuristic search strategy; 3). Efficient data structure.
The traditional binary resolution is due to the simple deduction rules: only two clauses for resolution. Therefore, most of the ATPs focuses on the research of heuristic search strategies. For example, vampire [12] has hundreds of different heuristic strategies. Furthermore, some articles [13,14] employ artificial intelligence or machine learning to generate different search strategies. These search strategies can improve the performance of ATPs to a certain extent. However, usually, too many strategies lead to too complicated heuristic strategies, or they are only useful for certain types of problems. These drawbacks make it difficult to find a generally good heuristic strategy.
In this section, firstly, we propose rules for formulating heuristic strategies based on the characteristics of the S-CS Rule, and then give the clause selection strategy based on the S-CS Rule.
3.3.1. Heuristic strategy based on S-CS rule
The traditional binary resolution based on saturate employs various heuristic strategies. These strategies usually come from two considerations:
Controlling the expansion of the proof-search space as much as possible to avoid too fast expansion of the clause set. However, such control is limited. In most cases, it is difficult to avoid the rapid expansion of the search space because the decision time increases.
Based on the goal-oriented strategy, employing the conjecture clause is preferred in the resolution process. It is a rough heuristic strategy, so the conjecture-clause participation in resolution will generate a large number of lemma clauses. Therefore, most of ATPs will generally combine the goal clause with the minimum age of the hybrid strategy.
Compared with the binary resolution method, the deduction method based on the S-CS rule comes with an outstanding feature: If and only if the contradiction separation clause C+ is empty, the clause set S is UNSAT. Therefore, for the heuristic strategy based on S-CS rule, the following two rules are followed:
Rule 1: The literals in the contradiction separation clause C+ is as little as possible.
Rule 2: The effect of unification/substitution on literals in
For rule 1, there are two meanings. The first is to make the most use of the unit clause. The priority to use the unit clause must satisfy rule 1. Secondly, make full use of the coordination of multi-clause when there are more than two clauses in P. The more synergized effectors of all clauses are involved, the more literals will be removed from given-clause Cg.
For rule 2, the literal P(x) has better synergy than literal P(a). So we do not want the literal instanced too early, which will be discussed in Section 3.4.
Compared with the traditional binary resolution, the above two rules make the heuristic strategy based on the S-CS rule pay more attention to dynamic control of the deductive process, as well as are comfortable to be implemented.
3.3.2. Clause selection
Clause selection is the most crucial choice point of resolution-based provers [5]. The VAMPIRE prover was the CASC (Conference on Automated Deduction ATP System Competition) winner in recent years, which uses two parameters for clause selection: the age and the weight of a clause [12]. Another powerful purely equational theorem prover E prover uses some heuristic strategiesy [5]: first-in/first-out FIFO, symbols count, and goal-directed evaluation function. GKC [15] is a fresh resolution prover, which uses a 2-layer clause selection queues algorithm. The first layer uses the common ratio-based algorithm. Further, the second layer uses four separate queues based on the clause's age.
In the ATP based on the S-CS rule, we perform the selection of a given clause by employing a dynamic-static combined strategy to satisfy the above rules, as has been proposed in Section 3.3.1.
Our clause selection strategy based on S-CS rule as follows:
Static clause selection strategy
Selecting clauses from one of the queues by Least literals priority.
Selecting clauses from one of the queues by employing a stability-weight ratio. That will be discussed in Section 3.4.
Dynamic clause selection strategy
Unlike the binary resolution, the dynamic strategy is one of the significant advantages of S-CS rule. The core idea is to guide the entire deduction process by the control strategy of the contradiction separation clause C+.
Dynamic strategy for controlling the number of literals in C+
Each deduction based on the S-CS rule will generate a C+. In order to make the literals in C+ be as little as possible, we set a threshold Nr. Let |C+| denote the number of literals in C+. If |C+| > N, contradiction separation fails, i.e., this inference is invalid. Rollback and put the Cg back to U, reselect given clause.
Setting the threshold N is also a dynamic learning process. For example, with an initial value N = 1, when all the given-clause Cg from U are invalid, then N = N + 1;
Least |C+| priority strategy
The dynamic strategy is different from the static strategy. When N > 1 and there are some candidate clauses C1, …, Cm with the same number of literals. We can try to inference with them separately, so the clause with the smallest
Older clause or goal clause priority strategy
Firstly, the older clause needs to be chosen; the two clauses are of the same age, choosing the goal clause or the descendants of the goal clause.
3.4. Dynamic Learning Heuristics Strategy
According to the analysis in Section 3.3.1, there are two guiding rules for the heuristic strategy based on the S-CS rule, where Rule 2 primarily refers to the control over the literal instances during the inference process.
In this section, we will propose a weight evaluation method and discuss a dynamic learning heuristics strategy based on Term Stability.
3.4.1. Weight function based on term stability
In the unification and substitution process, the variable in first-order logic probably replaces other variables and constants. Term stability is applied to evaluate how easy it is for a term to substitute for another term during the inference process, which reflects the complexity of the term's substitution. Thus we the term f(x) is more stable than x, and ground term f(a), a is the most stable.
Definition 3.1.
Let t be a term in first-order logic,
In (1) V is a finite set of variable symbols, G denotes the set of ground terms, Fv indicates a set of function terms with variables, and tf is a function term involve variables. Wx, Wg are the weight of variable and ground-term, respectively. They are fixed values and satisfy Wg> Wx> 0. W(tf) is the weight of tf:
t1 = f5(f(x1), f2(x2, x3), x4, f1(a1), a2). Then |t|g = 2,
Example 3.1.
Calculate the term stability of the following three terms:
Let Wg = 2, Wx = 1. Then
Definition 3.2.
(Clause stability) There is a clause
When selecting Cg, the clauses with smaller Sc are preferred to participate in the deduction.
In practice, if there are multiple literals with the same variable in a clause, then any variables instance will affect more than one literal. For example, for clause C1: P2(x1, x2)
We call this correlation between such kind of literals is literal-relational in the same clause.
Definition 3.3.
Let l be literal in clause C. literal-relational R(l) is defined as if
Example 3.2.
There is a clause
3.4.2. Literal selection
During the S-CS building process, it needs to find a substitute
Actually, we hope that literal selection strategies can achieve the following effects:
Keeping the literals as few as possible in Cg
Avoiding literal instance in
Therefore, we employ some literal-selection strategies as follows:
Literal-stability priority queues.
It gives higher priority to literal with smaller S(l).
Literal-relational priority queues.
It gives higher priority to literal with smaller R(l).
Dynamic information for literal priority queues.
The dynamic weight function is:
3.4.3. Other dynamic restriction strategies
According to the limitation of computing resources, such as CPU time, memory size, and storage space,we give the dynamic restriction strategies based on the S-CS rule.
The main idea is to set some thresholds, initially small values. When some property of a new clause exceeds these thresholds, discard this new clause. If the S-CS rule fails and the proof-search restart, these thresholds are increased.
These limits are as follows:
Limit the maximum function layer of clause.
At first, we count the maximum function nesting layer of the original clause, let
Limit the maximum size of clause.
As same, count the maximum length of clause in S, let |C|limit = [1, |C|max]. If |C+| > |C+|limit, the C+ is discarded
4. THE COMBINED ATP BASED ON S-CS RULES
The CoProver is a hybrid inference system constructed by SCS-Prover and Prover9. Figure 3 shows the main framework of CoProver.
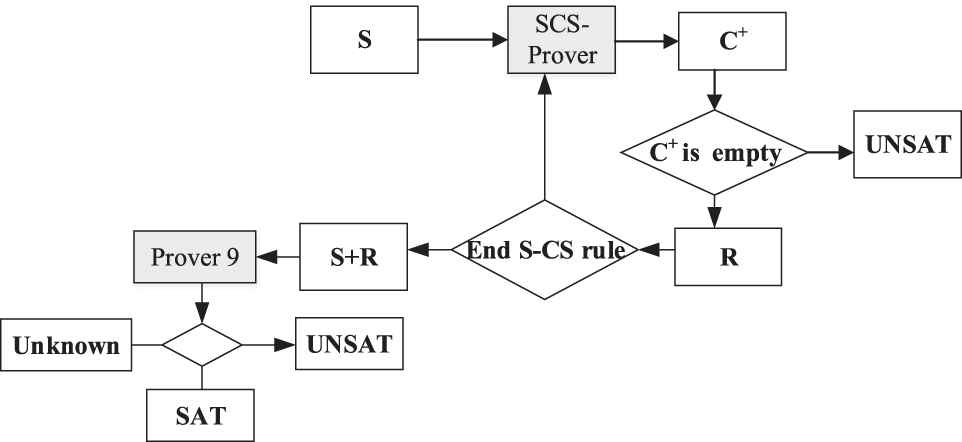
The framework of CoProver.
SCS-Prover is an ATP system based on S-CS rule, while Prover9 is a famous resolution-based prover, its overall architecture is very similar to that of Otter-3.3 [16,17]. In the works of other scholars, Prover9 is often used nowadays as a benchmark to measure the performances of the proposed provers.
The workflow of CoProver is as follows:
Step 1. SCS-Prover is first applied to the initial set of clauses S for deduction and generates an inference result, i.e., contradiction separation clause C+.
Step 2. If C+ is empty, the proof is found, output UNSAT. Otherwise, putting C+ into the clause set R.
Step 3. If the terminating condition of S-CS rule is reached, then we obtaining new clause set S' =
Step 4. Input S' into the Prover9 for proof-search and obtaining a result.
In the above process, there are some points.
The termination condition for SCS-Prover mainly includes time limit and restart times limit.
The clause set R can be regarded as a lemma set of S.
According to the features of S-CS rules, we can control the C+ in the deduction process; to generate as more unit clauses and ground clauses as possible. Experiments show that the addition of these lemmas can greatly improve the ability of Prover9.
5. EXPERIMENTS
C++ in the 64-bit Unbuntu operating system is used to implement the first-order logic prover CSC-Provers based on the S-CS rule, and the combined system CoProver.
5.1. The Result of Competition Problems
We testify CoProver by the first-order logic problems taken from the category FOFs of the last three years CASC [18] competition (2017–2019). We assign the value 2 to the Max literals number of C+ (|C+| = 2). For the problems in 2017 and 2018, the CoProver runs with a CPU time limit of 300 s per problem; specifically, the CPU time limit of CSC-prover is 180s, and the CPU time limit of Prove9 is 120s. In addition, for the competition problems in 2019, we set the total CPU time limit to 180s. first, the maximum CPU time of CSC-prover was 120s, and then 60s is left to Prover9
All the experiments are done in an Intel(R) CPU I7 @ 3.4 GHz and 8GB of main memory. The experimental results are presented in Table 1.
| 2017 (500) | 2018 (500) | 2019 (500) | |
|---|---|---|---|
| Prover9 | 140 | 122 | 100 |
| CoProver | 238 | 199 | 163 |
| Ratio (%) | 70 | 63 | 63 |
Comparison of the number of solved problems from Conference on Automated Deduction ATP System Competition (CASC).
Table 1 shows the comparison result of Prover9 and CoProver solving the competition problems in 2017–2019. The “Ratio” row is the radio of the number of solved problems of CoProver and Prover9. We can see that CoProver can solve 63% more problems than by Prover9.
Next, the performance of the hybrid ATP system is analyzed further. Table 2 shows the results of different phases of CoProver. The “CSC-Prover” denotes the results that only the CSC-Prover based on S-CS rule is used in the first phase, the “Prover9+” row denotes the results of the second phase. In this stage, the input clause set S' for Prover9 is
| 2017 | 2018 | 2019 | |
|---|---|---|---|
| CoProver | 238 | 199 | 163 |
| CSC-Prover | 183 | 129 | 136 |
| Prover9+ | 55 | 70 | 36 |
| New solved | 18 | 21 | 17 |
| Ratio (%) | 32.73 | 30.00 | 47.22 |
Analysis at the different phase of CoProver.
Table 2 also shows that the lemmas provided by S-CS rule-based ATP have a significant effect on improving Prover9's performance. Especially for the problems in 2019, even if they are harder. Actually, the performance of Prover9 has been improved to 47.22%.
Figure 4 shows the relationship between the solution number and CPU time. It can be seen that with some lemmas (i.e., contradiction separation clause) are provided by CSC-Prover, most problems can be solved in a short time, where many problems cannot be solved by Prover9.
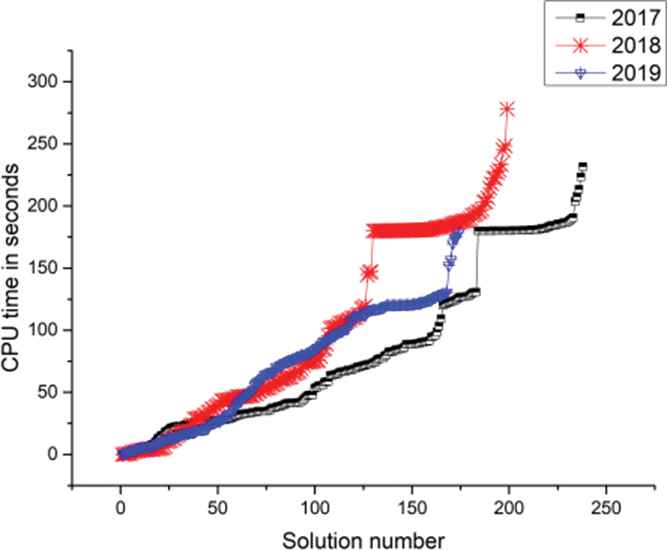
First-order theorem (FOF) results-proof-time by CoProver.
5.2. The Result of Benchmark Problems in TPTP
We testify CoProver on the first-logic problems with rating = 1 from the TPTP-v6.1.0 [19] problems library. The rating is an indicator of how hard the problem is, so the problem with rating = 1 meant that it could not be solved by any ATPs system. However, we proposed a hybrid ATP system based on the S-CS rule. Namely, the CoProver can solve 103 problems with rating = 1, within the CPU time limit 300 s. See the detailed proof in Appendix.
6. CONCLUSIONS AND FUTURE WORKS
In this paper, we firstly proposed a simplified and effective implementation scheme for the S-CS rule. We also presented a dynamic heuristic strategy based on the S-CS rule scheme. Then, we introduced the CoProver as a novel combined ATP based on S-CS rule for more effectively and efficiently solving the problems with rating = 1.
Experimental results showed that compared with the provers based on binary resolution, the performance of the prover based on S-CS rule is significantly improved. As a result, in the TPTP problem library, our proposed combinational ATP system CoProver successfully solved 103 problems, which could not be solved by any other existing prover.
In the future, we will further optimize the dynamic coordination strategy based on the separation rules of contradictions. Notably, the first-order logic formula decision strategy of equivalent words will be optimized and improved.
CONFLICT OF INTEREST
The authors declare they have no conflicts of interest.
AUTHORS' CONTRIBUTIONS
Jian Zhong has proposed the main idea of the paper, including the algorithm implementation, application. Yang Xu, Feng Cao have contributed a lot of good suggestions for the algorithm implementation. In addition, Yang Xu has contributed with some writing, review, and helpful comments to further enhance the quality of the paper and Feng Cao has contributed with experimental evaluation.
ACKNOWLEDGMENTS
This paper is supported by the National Natural Science Foundation of China (Grant No. 61673320) and the Fundamental Research Funds for the Central Universities (Grant No. 2682018CX59, 2682020CX59).
APPENDIX
| Problem | Time (s) | Problem | Time (s) | Problem | Time (s) |
|---|---|---|---|---|---|
| LCL148-1 | 124.04 | RNG010-1 | 224.05 | LCL530+1 | 242.63 |
| REL040-4 | 156.56 | RNG027-1 | 105.46 | LAT216-1 | 216.61 |
| ROB006-3 | 168.78 | LAT064-1 | 160.68 | LCL554-1 | 217.03 |
| GEO046-2 | 121.13 | LAT225-1 | 79.84 | CT065-1 | 106.55 |
| RNG028-9 | 86.91 | REL038-1 | 135.08 | WV850-1 | 227.17 |
| RNG028-7 | 192.77 | REL040-1 | 293.45 | ET021-3 | 162.16 |
| LCL147-1 | 273.25 | REL037-1 | 41.84 | REL039+1 | 99.76 |
| LAT191-1 | 224.73 | LAT231-1 | 43.96 | LCL477+1 | 229.48 |
| LAT190-1 | 218.57 | LAT206-1 | 84.41 | NUM005+1 | 233.36 |
| REL032-1 | 123.05 | ALG238-1 | 58.17 | ALG001-1 | 219.57 |
| GRP740-1 | 0.94 | LAT221-1 | 149.93 | REL040+4 | 85.43 |
| REL032-2 | 284.34 | KLE149+1 | 175.64 | LAT226-1 | 270.66 |
| GRP196-1 | 187 | KLE149+2 | 2.56 | LAT188-1 | 249.16 |
| REL017-1 | 1.25 | LAT161-1 | 139.06 | KLE047+1 | 97.77 |
| LAT193-1 | 279.66 | REL016+1 | 19.33 | LAT187-1 | 143.5 |
| REL016-1 | 7.1 | REL017+1 | 4.40 | WW456-1 | 44.52 |
| LAT074-1 | 140 | REL020+1 | 92.31 | RNG028-1 | 295.03 |
| ALG243-1 | 31.14 | REL032+1 | 91.99 | LAT139-1 | 168.89 |
| LAT077-1 | 124.6 | REL032+2 | 216.19 | LCL417-2 | 287.98 |
| LAT229-1 | 280.74 | REL040+1 | 169.07 | KLE162+1 | 133.51 |
| RNG029-2 | 244.72 | REL041+1 | 40.09 | LAT140-1 | 64.18 |
| GEO031-3 | 59.89 | KLE033+1 | 58.16 | ANA004-3 | 2.96 |
| REL040-2 | 169.73 | KLE155+2 | 205.42 | GEO113+1 | 86.60 |
| RNG027-2 | 249.82 | LDA009-2 | 64.46 | REL016+2 | 99.37 |
| GRP732-1 | 211.75 | ET970+1 | 11.26 | REL039-1 | 89.98 |
| LAT181-1 | 252 | KLE164+1 | 75.77 | LDA005-2 | 91.12 |
| LAT078-1 | 12.26 | KLE168+1 | 37.92 | NUM923+1 | 106.25 |
| LAT224-1 | 294.31 | LAT075-1 | 276.75 | KLE163+1 | 196.50 |
| ALG241-1 | 42.4 | RNG029-1 | 294.78 | LAT215-1 | 193.22 |
| LAT202-1 | 102.77 | REL040+2 | 240.94 | LAT189-1 | 178.95 |
| LAT185-1 | 78.48 | KLE077+1 | 41.7 | WV953-1 | 77.68 |
| LAT184-1 | 154.19 | REL040+3 | 153.87 | REL017+2 | 182.15 |
| LAT186-1 | 258.24 | WV719-1 | 84.05 | REL017-2 | 133.86 |
| LAT180-1 | 177.93 | LCL511+1 | 110.45 | ALG344-1 | 110.87 |
| ALG010-1 | 284.51 |
List of problem with rating = 1 by CoProver.
REFERENCES
Cite this article
TY - JOUR AU - Jian Zhong AU - Yang Xu AU - Feng Cao PY - 2020 DA - 2020/06/12 TI - A Novel Combinational ATP Based on Contradiction Separation for First-Order Logic JO - International Journal of Computational Intelligence Systems SP - 672 EP - 680 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200521.001 DO - 10.2991/ijcis.d.200521.001 ID - Zhong2020 ER -