
Interval-Valued Probabilistic Dual Hesitant Fuzzy Sets for Multi-Criteria Group Decision-Making
- DOI
- 10.2991/ijcis.d.191119.001How to use a DOI?
- Keywords
- Interval-valued probabilistic dual hesitant fuzzy sets; Multi-criteria group decision-making; Ordered weighted averaging operator; Ordered distance and similarity measures; Risk evaluation
- Abstract
As a powerful extension to hesitant fuzzy sets (HFSs), dual hesitant fuzzy sets (DHFSs) have been closely watched by many scholars. The DHFSs can reflect the disagreement and hesitancy of decision-makers (DMs) flexibly and conveniently. However, all the evaluation values under the same membership degree are endowed with similar importance. And DHFSs are not able to express DMs' preference degrees on different variables. To overcome this drawback, in this paper, we propose the concept of interval-valued probabilistic dual hesitant fuzzy sets (IVPDHFSs) by providing each element with an interval-valued probability value, which can describe DMs' preferences, hesitancy and disapproval simultaneously. Then we define the basic operation laws, score function and deviation function for interval-valued probabilistic dual hesitant fuzzy elements (IVPDHFEs). Besides, the ordered distance and similarity measures are proposed to calculate the deviation of any two IVPDHFSs and to derive the weight vector for DMs objectively, respectively. To aggregate decision-making information, we present interval-valued probabilistic dual hesitant fuzzy ordered weighted averaging (IVPDHFOWA) operator. Moreover, the water-filling theory is first introduced into IVPDHFSs environment and utilized to obtain unified criteria weights mathematically. Furthermore, a three-phased multi-criteria group decision-making (MCGDM) framework is constructed to address IVPDHFSs information. Finally, a case study concerning Arctic risk evaluation is provided to verify the effectiveness and superiority of the proposed three-phased framework.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
The process of multi-criteria decision-making (MCDM) [1–5] is usually uncertain and complex in human activities. But how to deal with these vague issues is a challenging question. It is intractable to employ traditional techniques to cope with imprecise information. As a result, Zadeh [6] proposes the fuzzy sets (FSs) theory, which is generally recognized as a convenient model to describe imperfect and uncertain information [7]. FSs have only single membership function to describe the degree to which the given alternative satisfies the DMs. However, to express DMs' hesitancy on the performance of the given alternative, the corresponding models of FSs are limited. To alleviate this issue, Torra [8] introduces the concept of hesitant fuzzy sets (HFSs). Because HFSs allow several values to reflect the membership degree to which an element belongs to the given set, it is very suitable to use HFSs to express the hesitancy of DMs in the decision-making process.
Since HFSs have unique advantages, many scholars pay attention to the study of HFSs theory and obtain many achievements. On the theories of HFSs, Xu and Xia [9] investigate the aforementioned information measures and further define the ordered weighted distance and similarity measures for HFSs; Zhu et al. [10] apply proposed hesitant fuzzy geometric Bonferroni mean (HFGBM), hesitant fuzzy Choquet geometric Bonferroni mean (HFCGBM), weighted hesitant fuzzy geometric Bonferroni mean (WHFGBM) and weighted hesitant fuzzy Choquet geometric Bonferroni mean (WHFCGBM) to make MCDM; Zhang [11] develop a wide range of hesitant fuzzy power aggregation operators to aggregate input arguments that take the form of HFSs; Rodríguez et al. [12] make a position and perspective analysis of HFSs and a discussion about current proposals; Wei [13] proposes some prioritized aggregation operators to address MCDM problems in which the criteria are in different priority level; Xu and Zhang [14] develop a new approach based on TOPSIS and maximizing deviation method to handle hesitant fuzzy information. Moreover, there are some successful extensions of HFSs, such as hesitant fuzzy linguistic term sets [15,16], interval-valued HFSs [17,18], interval-valued hesitant fuzzy linguistic sets [19], interval-valued intuitionistic HFSs [20,21], DHFSs [22], generalized HFSs [23], triangular HFSs [24], probabilistic HFSs (PHFSs) [25] and interval-valued PHFSs (IVPHFSs) [26,27].
Among all the extensions of HFSs, DHFSs have gained wide popularity since it can depict the membership hesitancy degree and non-membership hesitancy degree in the domain simultaneously. Ye [28] proposes a correlation coefficient of DHFSs and apply it to solve MCDM problems. Su et al. [29] introduce the distance and similarity measures for DHFSs. Based on Archimedean t-conorm and t-norm, Wang et al. [30] present some dual hesitant fuzzy power aggregation operators for multiple criteria group decision-making (MCGDM). Singh [31] presents a new similarity measure and further proposes two algorithms to find the optional solution under DHFSs environments. Wang et al. [32] introduce generalized dual hesitant fuzzy Choquet ordered aggregation (GDHFCOA) operator for MCDM. Ren et al. [33] propose a comparison method to distinguish DHFSs efficiently and extend the VIKOR method into DHFSs environment for MCGDM. Yu and Li [34] apply the generalized dual hesitant fuzzy weighted averaging (GDHFWA) operator, the generalized dual hesitant fuzzy ordered weighted averaging (GDHFOWA) operator and the generalized dual hesitant fuzzy hybrid averaging (GDHFHA) operator to aggregate dual hesitant fuzzy information. Yu et al. [35] propose dual hesitant fuzzy Heronian mean operator and dual hesitant fuzzy geometric Heronian mean operator and utilize them to make group decision-making (GDM) for supplier selection. Zhao et al. [36] introduce dual hesitant fuzzy preference relation (DHFPR), which provides a powerful solution to describe the hesitant cognitions of DMs over some feasible alternatives. Ren and Wei [37] employ the proposed correctional score function and the dice similarity measure for DHFSs to address MCDM problems in which the attributes are in different priority levels.
Though these operators and methods can handle dual hesitant fuzzy information effectively, still the issue of DMs' preference on evaluation values has not been addressed. In the membership degree part or the non-membership degree part of DHFSs, all elements have the same importance or weight. Apparently, it is not in conformity in real life. DMs may prefer one element to another one due to the epistemic uncertainty. Up to now, probabilistic approaches are prevalent to model the aleatory uncertainty in terms of the statistical uncertainty but are unable to solve complex and fuzzy MCGDM problems. Thus, it is a hot academic issue that how to combine the randomness in mathematics and vagueness in complex MCDM problems efficiently, which motivates many scholars to make a large number of investigations.
On the whole, the work to incorporate probability theory into fuzzy sets theory can be roughly summarized into the following process: (i) introducing the probability theory and make it available in fuzzy sets theory; (ii) integrating the probability theory into fuzzy operation, measure and aggregation process and (iii) combined methods producing the probabilistic fuzzy values. Followed by this idea, the immediate probability was introduced into the fuzzy decision-making process [38,39]. The immediate probability information can reflect the attitudinal characteristics of DMs precisely and be properly considered as the weight information of the corresponding element in the aggregation process. To transform this incorporated theory into practical applications where the evaluation information is denoted by DHFSs, Hao et al. [40] propose the concept of probabilistic dual hesitant fuzzy sets (PDHFSs) and define the operational laws and some aggregation operators for PDHFSs. In the probabilistic dual hesitant fuzzy element (PDHFE), each evaluation value is endowed with an occurring probability to express the confidence and preference of DMs. Meanwhile, Zeng et al. [41] present the concept of weighted dual hesitant fuzzy sets (WDHFSs) and weighted dual hesitant fuzzy element (WDHFE) and provide a GDM method under DHFSs environment. For instance, an expert is invited to assess the performance of a central processing unit (CPU) manufacturing company over the technical ability attribute, he/she provide a dual hesitant fuzzy element (DHFE)
However, we may ignore the fact that DMs are unable to give precise probability preference information for their comments. In some real scenarios, DMs may estimate the preference degree of a certain membership value using linguistic form or interval format. It is unreasonable and irrational to utilize PDHFSs and WDHFSs to express linguistic or interval preference information. As a result, we propose the concept of interval-valued probabilistic dual hesitant fuzzy sets (IVPDHFSs), in which the occurring probability of each element in satisfaction and dissatisfaction degrees is extended to a range covering lower and upper limit values. By contrast, IVPDHFSs are quite suitable to reflect the uncertain preference degree in the decision-making process. Some motivations for this research are summarized as follows:
PDHFSs cannot express DMs' hesitant probabilistic preference. Motivated by this weakness, we are devoted to presenting a new concept called IVPDHFSs, which allocates each element with an interval-valued probability value.
Motivated by the rationality and consistency of aggregation operator, efforts are made to utilize ordered weight averaging operator to fuse IVPDHFSs information.
Motivated by the effectiveness and practicability of score function and deviation function of HFSs, contributions are made to extend score and deviation functions in IVPDHFSs environment.
Motivated by the risk preference character of DMs, we propose ordered distance and similarity measures to calculate the difference of any two IVPDHFSs.
A large number of models for deriving the criteria weights rarely take the criteria dimensions into account. Motivated by the power of water-filling theory, the achievement is made to remove the influence of criteria dimensions and magnitude the criteria into a consistent scale.
Motivated by the efficiency and flexibility of interval-valued probabilistic preference, we regard IVPDHFSs as a novel basic theory and further put forward a three-phased MCGDM framework under IVPDHFSs environment.
Some main contributions of this paper are presented below:
We define a new concept of IVPDHFSs so as to describe the hesitant probabilistic preference of DMs.
We propose the operational laws for IVPDHFEs and further present the IVPDHFOWA operator to make information fusion.
The score function and deviation function is defined to make a simple comparison of any two IVPDHFEs.
We present the ordered distance measure to compute the difference of any IVPDHFEs and introduce the ordered similarity measure to derive the weight vector of DMs.
The water-filling theory is first introduced into IVPDHFSs environment, and based on this theory, we construct a mathematical model to derive the criteria weights, which eliminates the impact of criteria dimensions.
A three-phased MCGDM framework is conceived to handle IVPDHFSs information.
The organization of this paper is constructed as follows. In Section 2, we review some definitions of HFSs, DHFSs and PDHFSs. In Section 3, we give a series of concepts of IVPDHFSs and propose the operational laws and comparison method for IVPDHFEs. Besides, the ordered distance and similarity measures and IVPDHFOWA operator are also presented. In Section 4, we propose a three-phased MCGDM framework within IVPDHFSs. In Section 5, we make a case study to verify the validity of the proposed three-phased framework. Finally, a conclusion is provided in Section 6.
2. PRELIMINARIES
In this section, we review some conceptions related to HFSs, DHFSs and PDHFSs.
2.1. Hesitant Fuzzy Sets
Definition 1.
[8] An HFS
Xia and Xu [42] provide the mathematical symbol of HFS as follows:
2.2. Dual Hesitant Fuzzy Sets
Definition 2.
[22] A DHFS
Zhu et al. [22] also give basic operations for DHFSs.
Definition 3.
[22] Let
2.3. Probabilistic Dual Hesitant Fuzzy Sets
Definition 4.
[40] A PDHFS
Hao et al. [40] also give the basic operational laws for PDHFSs as follows:
Definition 5.
[40] Let
3. INTERVAL-VALUED PROBABILISTIC DUAL HESITANT FUZZY SETS
In this section, to describe the probabilistic hesitant information flexibly and reasonably, we propose the concept of IVPDHFSs and investigate basic operational laws and its comparison method. Besides, we define the ordered distance and similarity measures of generalized IVPDHFSs. To fuse information, the interval-valued probabilistic dual hesitant fuzzy ordered weighted averaging (IVPDHFOWA) operator is presented.
3.1. The Concept of IVPDHFSs
As has been discussed above, it is difficult for the DMs to give precise probabilistic preference degrees on their evaluation values. Sometimes, they prefer to use interval-valued probability to express their opinions instead of single-valued probability. Thus, we present the concept of IVPDHFSs as follows:
Definition 6.
Let
The components
For the sake of simplicity, the pair
In real problems, some evaluation values may be lost due to complex decision-making environment and unexpected ignorance behaviors. Thus, we provide the definition of generalized IVPDHFSs and discuss some special forms of IVPDHFSs.
Definition 7.
Let
Remark 1.
Let
Very often in the decision-making process, the elements in given IVPDHFEs are disordered, which may lead to difficulties in operation. Thus, we propose the concept of ordered IVPDHFE as follows:
Definition 8.
Let
Remark 2.
Specially, if the values of
Example 1.
Given an IVPDHFE
For an IVPDHFE
Definition 9.
Let
3.2. The Basic Operations for IVPDHFSs
Definition 10.
Let
Remark 3.
In IVPDHFSs, the probability distribution of all elements is denoted by interval values with lower limits and upper limits. For each evaluation value, if the lower limit is equal to the upper limit, namely, interval-valued probability reduces to single probability, then Eqs. (18–21) reduce to Eqs. (8–11); if all the elements in membership set and non-membership set have equal importance and weight, namely,
Property 1.
The complement set of generalized IVPDHFS is involutive.
Proof.
According to the Eq. (22), we can conclude that
Property 2.
Commutative
Property 3.
Associative
Proof.
The proofs for Properties 2 and 3 are straightforward and simple. Here, we concrete on these Properties alone.
Property 4.
Distributive
Proof.
For the left part of Eq. (27), we have
For the right part of Eq. (27), we have
Thus, Eq. (27) is kept.
Similarly, Eq. (28) can be proved.
Proof.
The proof is easy and straightforward.
Theorem 2.
Let
Proof.
For the left part of Eq. (29), we have
For the right part of Eq. (29), we have
Thus, Eq. (29) is kept.
Similarly, Eq. (30) can be proved.
Theorem 3.
Let
Proof.
For the left part of Eq. (31), we have
Thus, Eq. (31) is hold.
3.3. The Comparison Method for IVPDHFEs
For an IVPDHFS, the elements in satisfaction function and dissatisfaction function are almost in the partial order. However, it is useful and necessary to rank a set of IVPFDHFEs in decision-making problems. Hence, we propose the score function and deviation function for IVPDHFEs, providing reliable access to the comparison of IVPDHFEs.
Definition 11.
Let
For any two generalized IVPDHFEs
Definition 12.
Let
As expressed in Eq. (36), the deviation function
Considering the score function and deviation function for IVPDHFEs, we further present the comparison method for IVPDHFEs.
Definition 13.
Let
If
If
If
if
if
if
3.4. The Ordered Distance and Similarity Measures for Generalized IVPDHFSs
The distance and similarity measures are classical tools to address decision-making problems in which the evaluation on alternative projects is denoted by FSs, HFSs, DHFSs and PHFSs. These measures can also reflect the closeness degree of any two items easily in practical applications. Hence, it is essential to study the distance and similarity measures under IVPDHFSs environment. To this end, we introduce the axioms for distance and similarity measures for IVPDHFSs.
Definition 14.
Let
Definition 15.
Let
Since there are complement relationships between the distance measure and the similarity measure, we mainly concrete on the distance measure of IVPDHFSs, and the similarity measure for IVPDHFSs can be obtained easily.
In most circumstance, for any
Based on Eq. (37), we can obtain the distance measure for IVPDHFEs easily:
Remark 4.
Before measuring the distance between any two IVPDHFEs by utilizing Eq. (38), we need to make the following two-step preparation.
Firstly, we need to line up all the elements in IVPDHFEs in descending order by referring to the Definition 8.
Secondly, for the membership set, two IVPDHFEs may have unequal length. Hence, we need to extend the shorter membership set until both of them have equal length. There are many methods to extend the shorter one, such as adding some elements in it. In most cases, we almost add some same values at the end or beginning of the shorter one, which depends on the DMs' attitude towards possible risks. Optimistic DMs are willing to add the element
According to the ordered distance measure for IVPDHFSs, the ordered similarity measure is denoted by the following expression:
3.5. Interval-Valued Probabilistic Dual Hesitant Fuzzy Ordered Weighted Averaging Operator
In fuzzy MCGDM problems, it is essential to fuse DMs' assessments into comprehensive information. Based on Definitions 8 and 10, we propose a basic aggregation operator under IVPDHFSs environment.
Definition 16.
Let
Theorem 4.
(Idempotency). If all
Theorem 5.
(Boundedness). Let
Theorem 6.
(Monotonicity). Let
Theorem 7.
(Commutativity). Let
Proof.
The proofs for Theorems 4–7 are simple and straightforward, and hence, we leave them to the readers for exploration.
4. A THREE-PHASED MCGDM FRAMEWORK WITH IVPDHFSs
In this section, an MCGDM problem under IVPDHFSs environment is described. Then, a similarity-based measure is developed to derive the weight information of DMs. In addition, inspired by the water-filling theory, we construct a mathematical modeling to obtain the weight vector of criteria under IVPDHFSs circumstance. Further, an extended fuzzy TODIM MCGDM method is constructed to generate the ranking order of alternatives. Finally, a three-phase MCGDM framework is summarized to cope with IVPDHFSs information.
4.1. Description for Interval-Valued Probabilistic Dual Hesitant Fuzzy MCGDM
For an interval-valued probabilistic dual hesitant fuzzy (IVPDHF) MCGDM problem, let
In this IVPDHF MCGDM problem, there are two types of criteria, namely, benefit and cost criteria. Besides, the probabilistic information provided by DMs may be incomplete and lost due to the decision-making background and DMs' expertise. Thus, it is essential to normalize the decision-making matrix (DMM). Combing the ideas in Eqs. (13) and (22), we normalize individual DMM
4.2. A Similarity-Based Method to Derive the Weight Vector of DMs
In MCGDM problems, it is impossible to have a batch of DMs whose attitude, experience and knowledge level are the same. Thus, it is essential to derive the weights of DMs to describe their contribution to the issue. The DM who has richer experience, more positive attitude and higher knowledge level should be endowed with higher weight. Currently, the similarity-based measure is one of the most preferential approaches to derive the weight vector for DMs. The core idea of similarity-based weight method is to make a pairwise comparison of decision-making matrices. Based on the Eq. (39), the pairwise comparison matrix can be established as
Then the weight information
From Eq. (47), it is clear that a higher weight should be assigned to the DM who has slighter divergence with other DMs.
After obtaining the weight vector for DMs, we can aggregate normalized individual decision-making matrices
4.3. Water-Filling Theory-Based Modeling for Determining the Criteria Weights
Water-filling theory was initially applied to address power optimization selection problem in wireless communication field [44]. It is argued that the sub-channel with a lower signal to noise ratio (SNR) should be allocated with smaller transmit power. The aim of this theory is to maximize the channel capacity.
And this theory can be expressed by the following symbol:
The main advantage of applying the water-filling theory into MCGDM is that it can unify the criteria dimensions into a compatible scale. If we compare decision criteria to channel, then the weight for each criterion can be regarded as the assigned power of each sub-channel [45].
Inspired by the total capacity of attributes proposed by Liu et al. [46], we propose a mathematic modeling to derive the criteria weights under IVPDHFSs environment as follows:
To solve this model, we introduce the following Lagrange function:
Computing the partial derivative and set
Solving Eq. (50), we can get
4.4. Acquisition of the Ranking Order by Fuzzy TODIM Method
Based on the weight vector of criteria obtained in Section 4.3, we can calculate the relative weight vector for criteria
Then the dominance of alternative
Further, the overall dominance degree of alternative
Finally, the comprehensive value of alternative
Therefore, the ranking order of alternatives can be acquired by descending the values of
4.5. A Three-Phased MCGDM Framework with IVPDHFSs
According to the above analysis, a three-phased MCGDM framework with IVPDHFSs is constructed, of which the procedure is summarized as follows:
Phase I: Determination of the weight vector for DMs.
Step 1: Collect the evaluation information from each DMs, and construct individual DMM
Step 2: Normalize the individual DMM
Step 3: Calculate the relative similarity degrees of any two decision-making matrices by using Eq. (39).
Step 4: Construct the pairwise similarity comparison matrix based on Eq. (46).
Step 5: Derive the weight vector
Phase II: Determination of criteria weight.
Step 6: Based on the weight information for DMs in Step 5 and IVPDHFOWA operator in Eq. (40), the normalized individual DMM
Step 7: Calculate the score function
Step 8: Obtain the weight vector
Phase III: Acquisition of the ranking order.
Step 9: Calculate the relative criteria weight vector
Step 10: Calculate the dominance degree of alternative
Step 11: Compute the overall dominance degree of alternative
Step 12: Obtain the comprehensive value
Step 13: Rank the alternatives by descending the values of
5. A CASE STUDY CONCERNING ARCTIC GEOPOLITICS RISK EVALUATION
In this section, an example of Arctic geopolitics risk evaluation is cited to demonstrate the applicability and effectiveness of our proposed three-phased MCGDM framework. In addition, comparative analysis and sensitivity analysis are provided to verify the superiority and efficiency of our proposed framework.
5.1. Description of Arctic Geopolitics Risk Evaluation Problems
With the warming of the climate, the Arctic has developed into a hot spot in world politics. Especially since the beginning of the 21st century, the international competition in the Arctic has become more and more fierce. Relevant countries have been competing for the initiative of Arctic affairs from different fields to seize the commanding heights of geopolitics. At the same time, international coordination and cooperation in the Arctic region are also under way, making international relations in the Arctic region complex and confused. Thus, how to grasp the investment opportunity and manage the risk in the Arctic is the prominent decision-making problem.
To solve the above issues, Hao et al. [40] conduct a geopolitical risk evaluation for the Arctic region by considering peripheral countries' exploitation actions. Five countries adjacent to the Arctic area are taken into consideration first, such as Russia, Canada, the USA, Denmark and Norway. Besides, China that intends to gain a seat in the Arctic investment and exploitation is also taken into account. Next, a committee of domain experts is organized to make positive risk evaluation on these countries' Arctic resource exploitation actions. After discussion at the meeting, it is agreed that four evaluation criteria are selected, such as
| The USA | ||||
| Canada | ||||
| Russia | ||||
| Denmark | ||||
| China | ||||
| Norway |
MC = military conflict; DD = diplomatic dispute; EI = energy import; MR = marine route.
The decision-making matrix provided by the domain expert
| The USA | ||||
| Canada | ||||
| Russia | ||||
| Denmark | ||||
| China | ||||
| Norway |
MC = military conflict; DD = diplomatic dispute; EI = energy import; MR = marine route.
The decision-making matrix provided by the domain expert
| The USA | ||||
| Canada | ||||
| Russia | ||||
| Denmark | ||||
| China | ||||
| Norway |
MC = military conflict; DD = diplomatic dispute; EI = energy import; MR = marine route.
The decision-making matrix provided by the domain expert
Remark 5.
For an IVPDHFE
5.2. The Implementation Procedure of Proposed Three-Phased Framework
The procedure of the proposed three-phased framework is summarized as follows:
Step 1: Normalize individual DMM.
The probabilistic information in Tables 1–3 is already normalized.
Step 2: Compute the relative similarity degrees of any two decision-making matrices.
Based on Eq. (39), we can calculate the relative similarity degrees of pairwise matrices as follows:
Step 3: Construct the relative similarity degree matrix.
According to the results in Table 4 and the structure of Eq. (46), the relative similarity degree matrix is constructed as
| Tables 1 and 2 | Tables 1 and 3 | Tables 2 and 3 | |
|---|---|---|---|
| Relative similarity degree | 0.6133 | 0.6660 | 0.5815 |
The relative similarity degrees of any two matrices.
Step 4: Determine the weight vector for DMs.
Referring to Eq. (47), we can derive the weight vector for DMs, as is shown in Table 5.
| DM | |||
|---|---|---|---|
| Weight | 0.3373 | 0.3286 | 0.3340 |
DM = decision-maker.
The weight information of DMs.
Step 5: Aggregate all individual decision-making matrices into a comprehensive group DMM.
Based on proposed IVFDHFOWA operator and derived weight vector for DMs, we can aggregate all the individual decision-making matrices into a comprehensive group DMM, as is displayed in Table 6.
| The USA | |
| Canada | |
| Russia | |
| Denmark | |
| China | |
| Norway | |
| The USA | |
| Canada | |
| Russia | |
| Denmark | |
| China | |
| Norway | |
| The USA | |
| Canada | |
| Russia | |
| Denmark | |
| China | |
| Norway | |
| The USA | |
| Canada | |
| Russia | |
| Denmark | |
| China | |
| Norway | |
MC = military conflict; DD = diplomatic dispute; EI = energy import; MR = marine route.
The comprehensive group decision-making matrix.
Step 6: Compute the score function and deviation function of each alternative.
To make comparison effective and obtain criteria weights efficiently, we calculate the score function and deviation function of the performance of each alternative over criteria by utilizing Eqs. (35) and (36), as is outlined in Table 7.
| Score Function | Deviation Function | Score Function | Deviation Function | |
|---|---|---|---|---|
| The USA | 0.2521 | 0.3805 | 0.9843 | 1.1458 |
| Canada | 0.3415 | 0.2138 | −0.7584 | 2.4813 |
| Russia | 0.5569 | 0.4284 | 0.4777 | 0.3751 |
| Denmark | −0.9284 | 2.6285 | 0.0239 | 0.6423 |
| China | −0.7907 | 2.4706 | 0.3821 | 0.2167 |
| Norway | −0.7099 | 2.2828 | −0.9597 | 2.9433 |
| Score Function | Deviation Function | Score Function | Deviation Function | |
| The USA | 0.1013 | 0.4817 | 0.6925 | 0.5877 |
| Canada | 0.4211 | 0.2299 | −0.3687 | 1.5142 |
| Russia | −1.1342 | 3.1557 | −0.2000 | 1.2216 |
| Denmark | 0.4986 | 0.2924 | −0.5073 | 1.6657 |
| China | 1.1825 | 1.5904 | −0.4344 | 1.5306 |
| Norway | −0.6839 | 2.2845 | −0.2261 | 1.2982 |
MC = military conflict; DD = diplomatic dispute; EI = energy import; MR = marine route.
The score function and deviation function of alternatives.
Step 7: Determine the criteria weights.
By putting the score function and deviation function obtained in Step 6 into the Eq. (51), we can derive the weight vector for criteria, which is shown in Table 8.
| Criteria | ||||
|---|---|---|---|---|
| Weight | 0.2895 | 0.1711 | 0.0658 | 0.4737 |
MC = military conflict; DD = diplomatic dispute; EI = energy import; MR = marine route.
Criteria weights.
Step 8: Compute the relative criteria weights.
From the results in Table 8, it is clear that criterion
| Criteria | ||||
|---|---|---|---|---|
| Relative weight | 0.6111 | 0.3611 | 0.1389 | 1 |
MC = military conflict; DD = diplomatic dispute; EI = energy import; MR = marine route.
Relative criteria weights.
Step 9: Compute the dominance degree of each alternative under each criterion.
We use the score function and deviation function obtained in Step 6 to make a simple comparison, then based on the relative criteria weights and Eqs. (38) and (53), we can obtain the dominance degree of alternative
Step 10: Compute the overall dominance degrees of pairwise alternatives.
We can calculate the overall dominance degree of alternative
| Dominance Degree | Dominance Degree | Dominance Degree | |||
|---|---|---|---|---|---|
| −0.0306 | −11.5888 | −3.5836 | |||
| 1.5773 | −5.2394 | −2.5831 | |||
| −1.1509 | −4.3763 | −6.1922 | |||
| −1.9894 | −5.3326 | 1.7288 | |||
| 3.6525 | −0.9679 | −1.5383 | |||
| −7.5690 | −7.8652 | −23.3851 | |||
| −3.6376 | −4.1633 | −16.9297 | |||
| −5.0951 | −5.9432 | −13.5330 | |||
| −4.7533 | −8.8851 | −13.4002 | |||
| −0.4164 | −2.1818 | −18.0163 |
The overall dominance degrees of pairwise alternatives.
Step 11: Compute the comprehensive value of alternatives.
Based on the data in Table 10, we can calculate the overall dominance degree of alternative
| The USA | Canada | Russia | Denmark | China | Norway | |
|---|---|---|---|---|---|---|
| Dominance degree | 2.0588 | −21.4714 | −27.5050 | −29.0386 | −12.1683 | −85.2643 |
| Comprehensive value | 1 | 0.7305 | 0.6614 | 0.6439 | 0.8371 | 0 |
| Ranking | 1 | 3 | 4 | 5 | 2 | 6 |
The overall dominance degrees and comprehensive values of alternatives.
Step 12: Rank the alternatives.
By descending the comprehensive values of six countries in Table 11, we can obtain the ranking order which is the USA
5.3. Comparative Analysis
In this subsection, a comparative analysis is conducted to verify the validity and rationality of our three-phased MCGDM framework.
5.3.1. Comparison with Hao et al.'s visualization method based on the entropy of PDHFSs [40]
We cite the example from Hao et al. [40], so we can make comparison and discussion directly. The result acquired from Hao et al.'s visualization method based on the entropy of PDHFSs [40] is the USA
First, Hao et al. [40] present the concept of PDHFSs, which is a special case of IVPDHFSs. Thus, IVPDHFSs has more advantages than PDHFSs, especially in the representation of probabilistic hesitant preference.
Second, in Hao et al.'s visualization method based on the entropy of PDHFSs [40], the weight information of DMs and criteria is subjectively assumed, which may not reflect the relative professional level of DMs and the objective importance degree of criteria. In this paper, we employ the relative similarity degree of decision-making matrices to derive the weight vector of DMs objectively. Besides, the water-filling theory is first introduced to IVPDHFSs environment to obtain criteria weights mathematically.
Third, Hao et al. [40] propose the entropy of PDHFSs, which is denoted by the following symbol:
5.3.2. Comparison with Wang et al.'s dual hesitant fuzzy weighted average operator [47]
It is acknowledged that IVPDHFSs and PDHFSs are the extensions of DHFSs. Hence, we can transform the PDHFE into the DHFE by multiplying the element value and its corresponding probability value. Let
In theory, DHFSs does not have the ability to reflect DMs' probabilistic preference, even interval probabilistic preference. Thus, while applying Wang et al.'s dual hesitant fuzzy weighted average operator [47] to tackle the problem described in Section 5.1, the probabilistic preference information is lost and ignored, which is unreliable and unrealistic.
In terms of method, Wang et al. [47] utilize the weighted average operator to aggregate information, while we apply the proposed ordered weighted averaging operator to make information fusion. In this paper, all the elements with corresponding probabilistic information are reordered by descending before information fusion, which can consider the risk preference characteristics of DMs and enable the final result more acceptable and reasonable. In addition, Wang et al. [47] use the score function to measure the overall performance of each alternative, which is regarded as a simple and single operation. In contrary, we employ the fuzzy TODIM method which takes DMs' attitude toward loss into account and acquire the final result by pairwise comparison instead of simple calculation.
As discussed above, we can conclude that our three-phased MCGDM framework within IVPDHFSs is more effective and efficient.
5.4. Sensitive Analysis of Parameter t
In the fuzzy TODIM method, the parameter
When there is a loss, the partial dominance degree changes according to the value of
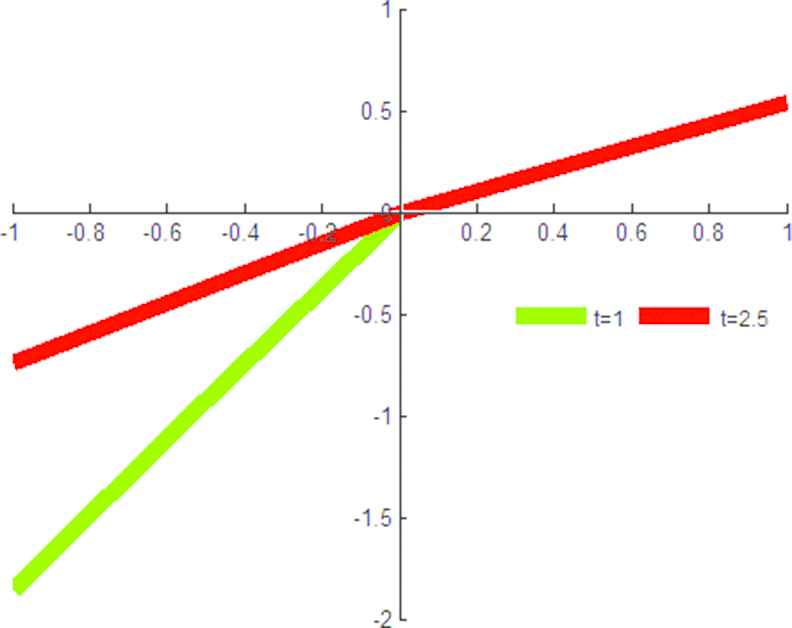
The prospect function with
Furthermore, the ranking result is also varied with different values of
| Ranking Order | |
|---|---|
| The USA |
|
| The USA |
|
| The USA |
|
| The USA |
|
| The USA |
|
| The USA |
|
| The USA |
|
| The USA |
|
| The USA |
|
| The USA |
The ranking order with different values of
From the results in Table 12, we can observe that the ranking order has slight changes as the value of
In theory, when
According to previous research results, the results are more reliable and convincing when the value of
6. CONCLUSIONS
To overcome the drawbacks of PDHFSs, we extend single-valued occurring probability into interval-valued probability and propose the concept of IVPDHFSs. First, a series of IVPDHFSs are defined, such as generalized IVPDHFSs, ordered IVPDHFSs and normalized IVPDHFSs. We also give some operations and comparison method for IVPDHFEs. In addition, the ordered distance measure is defined to calculate the deviation of any two IVPDHFSs, the ordered similarity measure is also defined to derive the weight information of DMs. Moreover, to fuse the information provided by multiple DMs, the IVPDHFOWA operator is proposed. Based on the criteria weights derived from the water-filling theory- based model, a three-phased MCGDM framework is designed under IVPDHFSs circumstance. Finally, an example regarding Arctic risk evaluation is introduced to demonstrate the feasibility and acceptance of our three-phased MCGDM framework. The results of comparative analysis and sensitive analysis also show that the proposed three-phased MCGDM framework is reasonable and efficient.
In future research, we intend to investigate IVPDHFSs theory and apply more MCDM techniques to cope with practical problems within IVPDHFSs environment.
CONFLICT OF INTEREST
The authors declare no conflicts of interest.
AUTHORS' CONTRIBUTIONS
Peide Liu: Conceptualization, methodology, formal analysis, writing–writing–review and editing, supervision, funding acquisition.
Shufeng Cheng: Conceptualization, methodology, validation, investigation, writing–original draft preparation, visualization.
ACKNOWLEDGMENTS
This paper is supported by the National Natural Science Foundation of China (Nos. 71771140 and 71471172), 文化名家暨“四个一批”人才项目 (Project of cultural masters and “the four kinds of a batch” talents), the Special Funds of Taishan Scholars Project of Shandong Province (No. ts201511045), and Shandong Provincial Social Science Planning Project (Nos. 17BGLJ04, 16CGLJ31 and 16CKJJ27).
REFERENCES
Cite this article
TY - JOUR AU - Peide Liu AU - Shufeng Cheng PY - 2019 DA - 2019/12/06 TI - Interval-Valued Probabilistic Dual Hesitant Fuzzy Sets for Multi-Criteria Group Decision-Making JO - International Journal of Computational Intelligence Systems SP - 1393 EP - 1411 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.191119.001 DO - 10.2991/ijcis.d.191119.001 ID - Liu2019 ER -