
A Decision Making Approach with Linguistic Weight and Unavoidable Incomparable Ranking
- DOI
- 10.2991/ijcis.d.190923.003How to use a DOI?
- Keywords
- Linguistic lattice implication algebra; Linguistic-real valuation function; Incomparable ranking; Linguistic decision making
- Abstract
In order to deal with the decision making problem including some linguistic values uncertainty information, we propose an approach for decision making with linguistic weighted and unavoidable incomparable ranking based on Linguistic-valued lattice implication algebra (LV-LIA). The properties of binary operations
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
In terms of common sense, people use linguistic terms in nature language for evaluating, reasoning and making decision, rather than crisp numbers. Hence, collection with qualitative information is always got, for example, object-attribute assessment for a car may be “very cheap” in price, “slightly comfortable” in comfort, “somewhat dangerous” in safety. To handle the qualitative information, many linguistic terms models have been proposed based on computing with words (CWW) [1,2], such as fuzzy set theory [3–5], symbolic approaches [6,7] and linguistic truth-valued mode in lattice order [8,9].
Fuzzy set theory was proposed by Zadeh in 1965 using a membership function to model the uncertain information [5]. But it is difficult to find appropriate membership function when we confronted with the circumstances where various concepts are given in various contexts. Type-2 fuzzy set is the extension of ordinary fuzzy set based on the theory of computing with words (CWW) [2]. Unlike a type-1 fuzzy set where the membership grade is a crisp number in [0, 1], the membership grade of Type-2 fuzzy set was extended to an ordinary fuzzy set [2–4]. Type-2 fuzzy set plays a role in wider applications and processes the uncertain information more flexibility [10–12].
Symbolic approaches use linguistic symbols to represent linguistic information directly without the numerical approximation required by fuzzy set based methods, and aggregate or compute on the indexes of these symbols to obtain the final result [13,14]. Symbolic approach has performed well in decision making problems especially semantic interpretation of linguistic terms in nature language [15,16]. But there exists some loss of information when the results come out from the initial expression domain. Francisco Herrera and Luis Martínez proposed a 2-tuple model which are composed by a linguistic term and a numeric value assessed in [−0.5, 0.5) [17,18]. The 2-tuple model is widely used in many real problems for that it can avoid information losing in linguistic information processing and many aggregation operators of 2-tuple model were provided [19–22].
The conventional symbolic approach for linguistic value uses a linear order structure. However, in the natural language, some linguistic values are incomparable, for example, “Exactly True” and “Somewhat False.” Obviously, it is difficult to describe the incomparable values utilizing a linear order structure. Lattice implication algebra (LIA) structure can imitate the uncertain and both comparable and incomparable characteristic [7]. Many researchers have studied in varied direction of LIA [23,24]. Jun Liu et al. have proposed an axiomatizable lattice ordered qualitative linguistic truth-valued logic system, which is a foundation for establishing formal linguistic truth-valued logic [25]. Xingxing He et al. have unified method for finding the structure of k-IESF in linguistic truth-valued lattice-valued propositional logic which provided a theoretical foundations and algorithms for α-resolution automated reasoning [26]. Yang Xu et al. have extended the binary α-resolution to multiary α-resolution in lattice-valued propositional logic LP(X) and lattice-valued first-order logic LF(X), obtained a result that multiary α-resolution principle in LF(X) can be equivalently transformed into that in LP(X) [27]. Yi Liu and Vassilis G. Kaburlasos et al. have introduced a LIA with implication values in a complete lattice of intervals on the real number axis which followed a capacity to optimize [28]. Li Zou proposed a linguistic-valued knowledge representation mode and approximated reasoning approach with linguistic-valued credibility factors [29].
All the above researches provided the feasibility of decision making with linguistic values based on linguistic-valued lattice implication algebra (LV-LIA). Besides object-attribute assessment, the importance of the attributes is often expressed using linguistic terms. However, the linguistic weights are always transformed to numbers or values on a linear order structure in a decision making problem [30]. This paper is aiming at decision making problems not only with the linguistic evaluation set but also the linguistic important degree, i.e., linguistic weight. We will propose a decision making model based on LV-LIA which has a flexible linguistic weighted method.
LV-LIA can express both comparable and incomparable linguistic information, which is consistent with nature language characteristic. In decision making there often exist some incomparable linguistic-valued decision making results. The positive valuation function (PVF) which implies a metric distance as well as an inclusion measure function can mapping a lattice to a real set [31]. We define a linguistic-real valuation function and get a rank with incomparable linguistic values through the linguistic-real metric distance (LRMD) elastic according to the individual preference degree.
Based on the aforementioned academic ideas, we will introduce a decision making approach based on 18-element LV-LIA.
The rest of paper is organized as follows: In section 2, we briefly review the concepts of LIA and LV-LIA. In section 3, we discuss the properties of the operations
2. LINGUISTIC-VALUED LATTICE IMPLICATION ALGEBRA
We briefly review some concepts of linguistic truth-valued LIA. We refer to the related Ref. [7].
Definition 1.
[7] Let (L,
Then (L,
Definition 2.
[7] Let
Definition 3.
[7] Let
Then
Then The Hasse diagram of 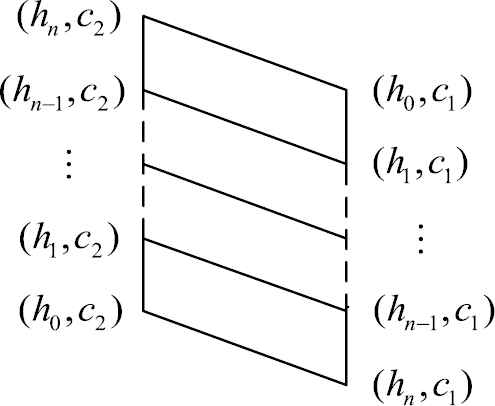
The operation “
Note that
3. THE DECISION MAKING APPROACH WITH LINGUISTIC WEIGHTED BASED ON LV-LIA
In a multi-attributes decision making problem, sometimes attribute importance is expressed with linguistic terms. We explore a linguistic weighted method expressing these linguistic weights with a linguistic lattice structure based on LV-LIA and apply it into decision making with linguistic weight in this section.
3.1. The Operations in LV-LIA
In a LIA L, there exist two binary operations
For any
Similarly, we extend two binary operations
Definition 4.
For any
According to Eqs. (4) and (7), an equal definition is obtained.
For operation
And for operation
As
Some other special properties of the operations
Theorem 1.
For any
Proof.
We prove it from four situations.
Without loss of generality, we only prove situation at that
From Eq. (8), we know that
Hence,
From Eq. (9), we know that
Hence,
It also can be proved in the other situations that
From the properties of the operations
Theorem 2.
For any
It can be proved from the Eqs. (8) and (9) respectively.
According to the properties of the operations
Suppose that
According to the Theorem 2, if
That shows that when the assessments of alternatives are the same, more important the attribute is, higher evaluation the alternative achieves. Accordingly, when the weights of attributes are the same, larger the assessment of alternative is, higher evaluation the alternative achieves.
3.2. The Decision Making Approach Based on 18LV-LIA
In generally, linguistic terms with linguistic hedges can be seen as linguistic modifiers and prime terms. In the following, we divide the linguistic terms into nine linguistic hedges (modifiers) applying to two prime terms. The linguistic modifiers of LV-LIA are {Slightly (Sl for short), Somewhat (So), Rather (Ra), Almost (Al), Exactly (Ex), Quite (Qu), Very (Ve), Highly (Hi), Absolutely (Ab)} with the semantic ordering relationship Sl < So < Ra < Al< Ex < Qu < Ve < Hi < Ab, i.e., the hedge set is

The Hasse diagram of
A decision making model is constructed based on 18LV-LIA. Weights of the attributes are expressed with linguistic terms on LV-LIA. The operation
There are some aggregation function about the logical relation “or” and “and”.
For relation “
- where
For relation “
- where
They all satisfy the associative law and commutative law.
A linguistic multi-attribute decision making problem consists of a finite and non-empty alternative set
The decision making approach based on 18LV-LIA consists mainly of the flowing steps.
Step 1. Linguistic assessment matrix and linguistic weight transforming. The linguistic assessment matrix is
In the linguistic assessment matrix,
The attribute weights given by the experts are the linguistic terms in
In this step, the attribute assessment collection of alternatives is transformed to linguistic terms on
Step 2. Weighted evaluation matrix Construction. Weighted evaluation matrix is constructed from Eq. (8).
Step 3. Aggregation function setting and comprehensive evaluations aggregation.
The comprehensive evaluation
Step 4. Decision making process. The comprehensive evaluations
Here are a few notes. The aggregation function is set as
It is also noted that incomparable linguistic results are allowed.
3.3. Examples Illustration
Example 1.
A teaching evaluation system with linguistic information.
To show how the proposed approach works, we give a teaching evaluation system which help decision makers evaluate the teacher's teaching quality. Suppose that the teaching quality depends on four attributes, responsibility, lesson preparation, professional proficiency and teaching efficiency. The attribute set is denoted as
Step 1. The assessment collection with respect to the attributes of four teachers about teaching quality is shown in Table 1. The linguistic terms are the linguistic values in
The assessment collection about quality of teaching.
W1, W2 and W3 are three weight vectors.
Step 2. The weighted matrix are got utilizing the operation
Step 3. Suppose there is facts that a teacher who is responsible or prepare lesson fully, and professional proficiency or teaching efficiency should be with high teaching quality. It is a rule, as a teacher,
IF (responsible or prepare lesson fully) and (professional proficiency or teaching efficiency) THEN (with high teaching quality).
The aggregation function for relation “or” is set as the logical operation Eq. (13). The aggregation function for relation “and” is set as the arithmetic operations Eq. (10). The weighted evaluations under
| A1 | A2 | A3 | A4 | |
|---|---|---|---|---|
The weighted evaluations values under W2.
And by the aggregation rule, we get the assessments of four teachers with different attribute weights (Table 3).
| A1 | A2 | A3 | A4 | |
|---|---|---|---|---|
| W1 | ||||
| W2 | ||||
| W3 | ||||
| Without weights |
Comprehensive evaluations.
Step 4: The results in Table 3 are ranked (Table 4).
| W1 | W2 | W3 |
|---|---|---|
The final results with different weights.
From Table 2, we can see that the four teachers get the same assessments in attribute
From Table 3, we can see that when all attributes are absolutely important, the results equal to the results without any weight. Therefore, the present method not considering weights is a special case of the proposed approach.
When the weights of attribute are different, the results will be changed. For example, Teacher
From the results, we can see that when we consider all attribute absolutely unimportant, i.e., the weight vector is W3, the four teachers get the same and lowest evaluation. It means that we collected unavailable data.
From Table 4, there are incomparable values in the results. For example, there exists the relation for W2 as follows (Figure 3),
Relations of teachers on 
It is reasonable for that the incomparable cases exist in reality because of the characteristic of the linguistic value in nature language.
Remark:
In step 3, taking the teacher
Example 2.
To illustrate the effectiveness of the method, an example of car evaluation in Ref. [30] is considered.
Suppose that there are three kinds of cars: BMW
| f1 | f2 | f3 | f4 | |
|---|---|---|---|---|
Linguistic assessment about cars on
The comprehensive evaluations is as Table 6.
| Weight | ||||||
|---|---|---|---|---|---|---|
| Method | ||||||
| Our Method | ||||||
| Chen's method | – | – | – | |||
The comprehensive evaluations from two methods.
From Table 6, we can see that when the weights are positive prime terms, the two methods get the same results. But when the weights consist of negative prime terms, the method in Ref. [30] is hard to handle it.
In Ref. [30], Shuwei Chen et al. used the linguistic multi-criteria decision making approach based on logical reasoning. Our method is more widely in weight setting and more flexible in comprehensive way.
In Ref. [30], weights are from the positive prime terms only. But in this paper, weights can be positive prime terms or negative prime terms. And the aggregation function can be logical operators or arithmetic operators or hybrid operators in this paper. Our method can handle more widely cases. It is more flexible facing the complex problems in reality.
From the results in Table 4, incomparable linguistic values are existed rationally because of the inherent characteristic of linguistic value. However, a certain decision is demanded sometimes. Then some further works should be done in this case.
4. RANKING METHOD FOR INCOMPARABLE LINGUISTIC VALUES
From the Figure 2, we know that that
4.1. PVF for Linguistic-Value Lattice
A valuation on a crisp lattice L is a real-valued function
A PVF
Utilizing a PVF, a value on a lattice can be mapped to a real number which keeping the order of these comparable elements on a lattice. Aiming to handle the incomparable problem of the linguistic values on LV-LIA, a PVF is defined called linguistic-real positive-valuation function (LR-PVF) on LV-LIA.
Definition 5.
Let
The preference parameters
Definition 6.
LRMD which implied by PVF
Theorem 4.
Suppose
If
Proof.
If
If
Definition 7.
Let
If
It is obvious that if
4.2. The Ranking Method Base on Linguistic-Real Valuation Function
Individual preference to the positive side and the negative side is different. We adjust the preference parameters in linguistic-real valuation function according to individual's preference for incomparable ranking.
Suppose
The flowchart of the developing ranking process by considering the incomparable values ranking is shown in Figure 4.
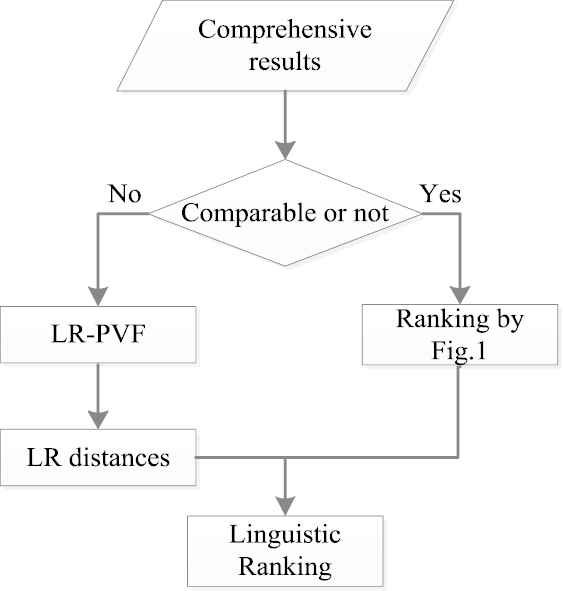
The flowchart of ranking with incomparable results.
Step 1. If two values in comprehensive results are comparable, then go to step 2; else go to step 3.
Step 2. The comparable values can be ranked by the lattice structure according to the Figure 1.
Step 3. For the incomparable values are mapped to real number by LR-PVF. For example, suppose
Step 4. Linguistic-real distance computing. According to Eqs. (17) and (18), denote the linguistic-real distance between
Step 5. Incomparable ranking process. If
Example 3.
In the teaching evaluation system, when the weight vector is W2, teacher
The preference parametersare set as
Step 1. The comparable values has been ranked in the Section 3.
Step 2. Linguistic valuation function computing:
According to Eq. (21),
Step 3. Linguistic-real distance: The linguistic-real distance
Step 4. Ranking process:
Since
We also can do that in another way. In step 3, linguistic-real distance between
It is obvious that
From above, the best one in teaching quality is teacher
When the preference changes, the ranking results would change. Figure 5 shows 
From Figure 5,
5. CONCLUSIONS
LV-LIA can deal with linguistic information by manipulating directly linguistic terms without numerical approximation. We proposed a linguistic approach of decision making with linguistic weight based on LV-LIA to deal with the attribute in different importance degree. The contrast example illustrated the proposed approach is more widely in setting weight and more flexible in linguistic aggregation. The attribute weight can be positive prime terms or negative prime terms which are on a lattice structure rather than a linear construction. The linguistic aggregation function for weighted evaluations comprehensive can be logical operations or arithmetic operations or hybrid ones. It makes the proposed approach more widely applied.
Incomparable linguistic results sometimes exist and are rational. In this paper we defined a PVF named LR-PVF by which the LV-LIA can be mapped to a real set. The distance implied by LV-LIA was used to do further works when these incomparable linguistic results need to be ranked. It is elastic by adjusting the performance parameters setting by individual performance to the positive side and negative side.
The proposed approach can be extended into more fields such as pattern recognition, risk analysis, quality evaluation and so on. The data and the parameters in the example are by experience in this paper. It will lead more convincing conclusion with practical data.
Funding Statement
This work was supported by the National Natural Science Foundation of P. R. China (Nos. 61772250, 61672127).
APPENDIX A Proof of Theorem 3
The proof of Theorem 3 is as below.
Proof.
There are two conditions should be proved to convince that
If and only if
The first condition is proved as the following.
To prove
Then we'll prove it in three cases according to the operations “
When
And
Then
Therefore, we get
when
And
Then
Therefore,
When
And
Then
If
If
Therefore, we get
The second condition is proved as the following.
According to
when
If
When
If v(
When
If
REFERENCES
Cite this article
TY - JOUR AU - Yunxia Zhang AU - Degen Huang AU - Wei Gao AU - Vassilis G. Kaburlasos PY - 2019 DA - 2019/10/04 TI - A Decision Making Approach with Linguistic Weight and Unavoidable Incomparable Ranking JO - International Journal of Computational Intelligence Systems SP - 1102 EP - 1112 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.190923.003 DO - 10.2991/ijcis.d.190923.003 ID - Zhang2019 ER -