
Compressed Sensing Image Reconstruction Based on Convolutional Neural Network
- DOI
- 10.2991/ijcis.d.190808.001How to use a DOI?
- Keywords
- Image reconstruction; Compressed sensing; CNN; Reconstruction accuracy; PSNR
- Abstract
Compressed sensing theory is widely used in image and video signal processing because of its low coding complexity, resource saving, and strong anti-interference ability. Although the compression sensing theory solves the problems brought by the traditional signal processing methods to a certain extent, it also encounters some new problems: the reconstruction time is long and the algorithm complexity is high. In order to solve these problems and further improve the quality of image processing, a new convolutional neural network structure CombNet is proposed, which uses the measured value of compression sensing as the input of the convolutional neural network, and connects a complete connection layer to get the final Output. Experiments show that CombNet has lower complexity and better recovery performance. At the same sampling rate, the peak signal-to-noise ratio (PSNR) is 12.79%–52.67% higher than Tval3 PSNR, 16.31%–158.37% higher than D-AMP, 1.00%–3.79% higher than DR2-Net, and 0.06%–2.60% higher than FCMN. It still has good visual appeal when the sampling rate is very low (0.01).
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
In recent years, due to the rapid development of the network, our lives are closely related to the processing of images and videos. However, the traditional processing method usually has high sampling cost, redundant data, not only wasting time but also wasting a lot of hardware resources. It's urgently to solve these problems. In 2006, Candes et al. [19] mathematically proved that the original signal is reconstructed by the partial Fourier transform coefficient cocoa, which laid a theoretical foundation for compressed sensing (CS). Based on these results, Donoho [17] formally proposed the concept of CS and related theoretical frameworks. The theory says that as long as the signal is sparse itself or in a certain transform domain, a high-dimensional signal can be projected onto a low-dimensional space using an observation matrix that is not related to the sparse basis. Reconstructing sufficient information of the signal, so that the original signal can be reconstructed with high probability by solving optimization problems. The sampling rate is no longer determined by the signal bandwidth, but by the structure and content of the information in the signal.
The CS theory has been widely studied in the field of signal processing and has been paid more extensive attention [1–4,16,18]. CS theory carries out compression and sampling at the same time. Under certain conditions, the original signal can be recovered with high precision by collecting much smaller amount of information. Therefore, CS theory has brought a subversive breakthrough in information acquisition and processing technology. The theory of CS is simple, which greatly reduces the coding complexity. In addition, the CS eliminates the redundant information in the signal processing, and compresses the data while sampling, thereby saves much resource consumption. Therefore, CS is widely used. However, the performance of the traditional compression sensing reconstruction algorithm is not perfect. Because the image has high dimension (up to millions of pixels), therefore, the reconstruction of the traditional algorithm complexity is high, the number of iterations, large amount of calculation, some algorithms of reconstruction precision is high, but takes time for a long time, some algorithm reconstruction time is short, but the reconstruction accuracy is not high, therefore, the reconstruction of the traditional algorithms can't good balance to refactor accuracy and time both.
In order to solve the bottleneck of traditional reconstruction algorithms, reduce the computational complexity and improve the quality of reconstruction, many scholars proposed to use convolutional neural network (CNN) to replace the optimization process [5–8], so as to accelerate the reconstruction stage. In reference [5], a superimposed noise reduction automatic encoder (SDA) is used to recover signals from under-sampled measurements. ReconNet [7] and Deepinverse [6] introduce CNN into the reconstruction problem, and use random Gaussian measurement matrix to generate measurement values.
Although ReconNet is a typical algorithm that applies CNN to CS, it also has shortcomings. Its reconstruction precision is not high, the image edge is fuzzy. On the basis of ReconNet, this paper deepens the layers of full convolution network, designs deeper network structure, expands the scale of full convolution network, and replaces the convolution core with smaller convolution core, because the superposition of multiple small convolution kernels is better than the single use of large convolution kernels, which can reduce the number of parameters and reduce the computational complexity.
The specific contributions of this paper are as follows:
(i) This paper proposes a new image compression sensor reconstruction network CombNet, which consists of a full connection layer and a full convolution network. Its performance is better than the existing network. For this network, when the measurement rate is less than 0.1, the signal-to-noise ratio is higher, the signal-to-noise ratio decreases more slowly and the robustness is stronger.
(ii) Full connection layer generates fairly good preliminary reconstructed images with faster speed and lower computational cost. Full connection layer is very suitable for image reconstruction tasks with limited computing resources and network bandwidth. Full connection layer plays an initial role in image restoration.
(iii) Full convolution network further improves the reconstructed quality of network, restores the pixel information of image, and achieves better visual effect.
The organizational structure of this paper is as follows: Section 2 introduce CNN and the related work of using CNN to solve CS reconstruction problem. Section 3 introduces the proposed total convolution measurement network CombNet. Section 4 presents the experimental results of this method and the comparison of experimental data. The conclusions of this paper are presented in Section 5.
2. RELATED WORK
2.1. Convolutional Neural Network
2.1.1. CNN structure
In recent years, the powerful feature learning ability and classification ability of CNNs have attracted extensive attention. A typical CNN consists primarily of the input layer, the convolutional layer, the pooled layer, the fully connected layer, and the output layer, as Fig. 1 shown.
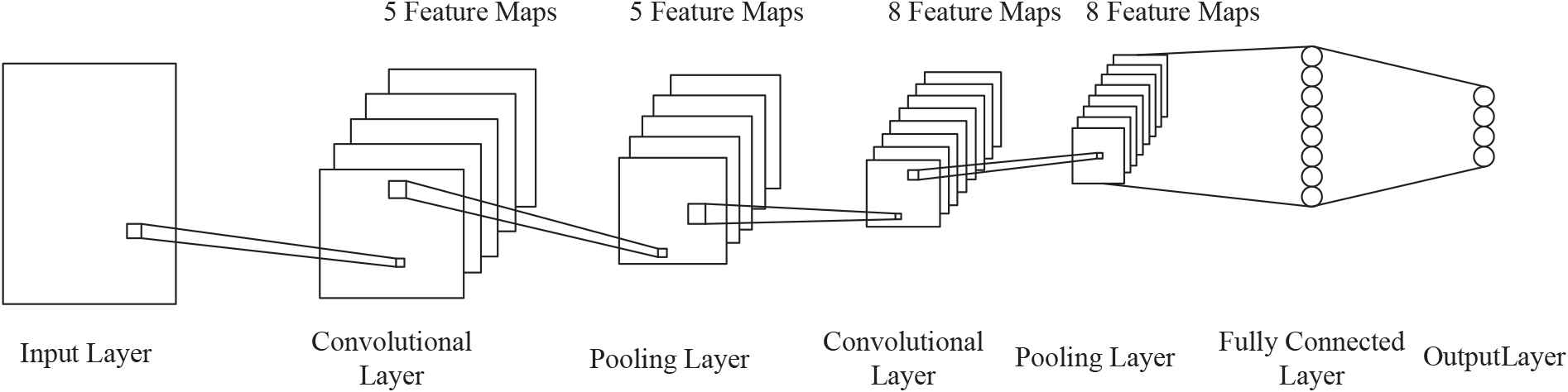
Typical structure of convolutional neural networks.
The input of CNN is usually the original image. The layer
Where
The pooling layer usually follows the convolutional layer and downsamples the feature map according to certain downsampling rules. There are two main functions of the pooling layer: (i) Dimension reduction of feature maps; (ii) Keeping the feature scale unchanged to a certain extent. After multiple convolutional and pooled layers are alternately transmitted, CNN relies on a fully connected network to classify the extracted features to obtain an input-based probability distribution
Based on the above definition, the working principle of CNN can be divided into three parts: network model definition, network training, and network prediction.
2.1.2. Network model definition
The network model definition needs to design the network depth, the function of each layer of the network, and the hyperparameters in the network according to the amount of data of the specific application and the characteristics of the data itself:
2.1.3. Network training
The CNN trains the parameters in the network through the back propagation of the residuals, but the over-fitting in the training process greatly affects the convergence performance of the training. In the current research, some effective improvement methods have been proposed: the random initialization network parameters based on the Gaussian distribution [20], initialize with trained network parameters, and the parameters of different layers of the CNN are initialized independently of each other [21].
2.1.4. Network prediction
The prediction process of CNN is to output the feature map at each level by forward-conducting the input data, and finally use the fully connected network to output the conditional probability distribution based on the input data. Studies have shown that the CNN high-level features of forward conduction have strong discriminating ability and generalization ability.
2.2. ReconNet
ReconNet is a representative work of low-resolution mixed images measured by neural network reconstruction of random Gaussian matrix. The frame is shown in Fig. 2.

ReconNet network architecture.
It can be seen from the previous traditional algorithms that in order to reconstruct high-quality images with CS technology, the image needs to be segmented, which can achieve special processing of complex information blocks, and at the same time reduce the complexity of reconstruction and improve the accuracy of reconstruction. ReconNet is also using this idea, which divides a scene into non-overlapping blocks and reconstructs each block by feeding corresponding CS measurements to its network. The reconstructed blocks are appropriately arranged to form an intermediate reconstruction of the image, which is then input into an off-the-shelf noise remover to remove the block effect and obtain the final output image.
There are many papers extended by ReconNet [8,13–15]. In reference [8], in the measurement section, the input is subjected to block measurement to obtain a measurement value. In the recovery section, all measurements of an image are reconstructed simultaneously, which allows the image to be recovered from the measurement at the same time, rather than recovering from the scattered measurements. Document 13 combines a linear mapping network with a residual network algorithm, reconstructs the residual network, and compares the different residual networks. In reference [14], the image is restored by a full convolution measurement network. The first layer of this full convolution measurement network is the convolutional layer, which is used to obtain measurements. The second layer is the deconvolution layer for recovering low-resolution images from the measured data. The high-resolution image is then reconstructed by a residual block. In reference [15], the fully connected layer is first used as a measurement, and the full connection layer and ReconNet are combined to form an adaptive measurement network. The measurement rate is determined by the size of the network input and the output of the full connection layer.
3. COMBNET
3.1. The CombNet Model
The algorithm in this paper compresses an image into an

Flow chart of the algorithm.
The total convolutional network structure of this paper is shown in Fig. 4. Except that the first layer of the network is a fully connected layer, the rest are convolutional layers. In the first layer and the second layer of the convolutional layer, a 1 × 1 convolutional kernel is used, where in the first layer generates 128 feature maps, and the second layer generates 64 feature maps. The third to seventh layers all use a 3 × 3 convolutional kernel, in which the third layer generates 32 feature maps, and the fourth layer to the sixth layer all generate 16 feature maps. The seventh layer generates 64 feature maps, and the second and ninth layers all use a 9 × 9 convolutional kernel to generate 32 feature maps. The tenth layer uses a 1 × 1 convolutional kernel to generate 16 maps. The feature map, the eleventh layer uses a 1 × 1 convolutional kernel, and generates a feature map. In the last layer, a 5 × 5 convolutional kernel is used to generate a feature map as the output of the network. The algorithm in this paper keeps the size of the feature map unchanged in all layers. Therefore, except for the first layer, the second layer, and the eleventh layer, the other layers need to be zero-padded. Common incentive layer functions are sigmoid, tanh, ReLU, Leaky ReLU, ELU, Maxout, this paper uses ReLU to reduce the computational complexity of the network and the training speed is also faster. The BM3D filter is used in this algorithm to remove the block effect caused by the quantization error after block quantization, because it balances the time complexity and reconstruction quality well.

Overview of the algorithm in this paper.
3.2. Training Network
This paper first constructs a measurement matrix
As shown in Fig. 5, the 481 × 321 images are reconstructed by the sampling rate of 0.25, 0.10, and 0.04, and give the reconstructed images obtained by each. It can be found that the algorithm of this paper effectively processes the image texture details and significantly improves the image processing quality.

Effect diagram of reconstruction at different measurement rates (the pictures are taken from Berkeley image). It is well known that the lower the sampling rate, the less key information contained in the image and the greater distortion of the image. In this figure, at 10% measuring speed, you can clearly see the tiny fluff on the stem of the fifth pictures. At 4% of the measurement rate, the starfish Mantis, flower, and leaf can be clearly seen, and we can see their details intuitively. It satisfies the visual experience people need.
The training of the reconstructed network is based on 91 image sets [22]. The blocks of size 32 × 32 are uniformly extracted from these image sets, the stride is 14, and 21760 patches are obtained. These form the labels of the training set. The input to the training set is the corresponding CS measurement of the patch. Experiments show that this training set is sufficient to train deep networks.
All training is based on the Caffe platform [9,10]. The computer used in this article is Nvidia GEFORCE GTX 1060 3GB and the training lasted for three days. The loss function is the average reconstruction error for all training image blocks. Here we choose MSE as the loss function because we want to minimize the loss function and favors a high peak signal-to-noise ratio (PSNR). MSE is the square of the difference between the true value and the predicted value and then the summed average. It is easy to derive by the form of square, so it is often used as a loss function for linear regression. Given a set of high-resolution images
4. EXPERIMENT
To illustrate the superiority of the improved algorithm, we apply the algorithm of this paper to the two images of the two iterative CS image reconstruction algorithms TVAL3 [11], D-AMP [12], ReconNet [7], DR2-Net [13], and FCMN [14]. According to the experimental results, the performance of each algorithm is analyzed and compared.
This paper is at four different sampling rates: 0.25, 0.1, 0.04, and 0.01. In both noisy and noiseless, the reconstruction experiments of each image in Fig. 6 are performed by four different algorithms. The PSNR is also compared, and the algorithm with higher reconstruction quality is obtained. In order to simulate the noiseless block CS, firstly, the image is divided into 32 × 32 non-overlapping blocks, and then the CS measurement values of each block are calculated using the same random Gaussian measurement matrix as the training data for different sampling rates. This article uses the code provided by the respective author on the website. The parameters of these algorithms, including the number of iterations, are set to default values. Table 1 lists the PSNR values in dB for the intermediate reconstruction (expressed as not using BM3D) and the final denoised version (represented by using BM3D).

Six pictures to be compared: (a) barbara, (b) foreman, (c) lenna, (d) baboon, (e) 56028, (f) 67079, (g) 92059, (h) 113016, (i) 126007, (j) 189003. Among them, pictures starting from (e) are selected from Berkeley images.
| MR = 0.25 |
MR = 0.10 |
MR = 0.04 |
MR = 0.01 |
||||||
|---|---|---|---|---|---|---|---|---|---|
| Image Name | Algorithm | Not using BM3D | Using BM3D | Not using BM3D | Using BM3D | Not using BM3D | Using BM3D | Not using BM3D | Using BM3D |
| Barbara | TVAL3 | 20.05 | 20.13 | 18.94 | 19.03 | 18.32 | 18.89 | 13.38 | 13.51 |
| D-AMP | 29.87 | 29.93 | 21.79 | 21.84 | 9.64 | 9.72 | 5.97 | 6.06 | |
| ReconNet | 20.36 | 20.43 | 19.43 | 19.55 | 18.41 | 18.55 | 16.84 | 16.98 | |
| DR2-Net | 20.85 | 21.05 | 19.72 | 19.84 | 18.13 | 18.28 | 16.97 | 17.08 | |
| FCMN | 20.86 | 20.93 | 19.65 | 19.77 | 18.64 | 18.78 | 17.03 | 17.19 | |
| CombNet | 21.02 | 21.33 | 20.86 | 20.93 | 18.76 | 18.90 | 17.09 | 17.22 | |
| Foreman | TVAL3 | 24.76 | 24.85 | 21.24 | 21.34 | 19.15 | 19.31 | 11.16 | 11.21 |
| D-AMP | 26.91 | 26.99 | 18.29 | 18.36 | 11.33 | 11.39 | 6.57 | 6.60 | |
| ReconNet | 25.38 | 25.49 | 23.76 | 23.97 | 21.04 | 21.25 | 17.75 | 17.89 | |
| DR2-Net | 26.74 | 26.77 | 24.03 | 24.16 | 21.28 | 21.47 | 17.80 | 17.95 | |
| FCMN | 28.03 | 28.07 | 23.88 | 24.06 | 21.21 | 21.38 | 18.06 | 18.19 | |
| CombNet | 27.01 | 27.18 | 24.07 | 24.21 | 21.33 | 21.52 | 17.96 | 18.09 | |
| Lenna | TVAL3 | 18.30 | 18.32 | 17.15 | 17.17 | 16.68 | 17.09 | 11.42 | 11.89 |
| D-AMP | 25.70 | 25.75 | 17.98 | 18.06 | 9.08 | 9.18 | 5.51 | 5.54 | |
| ReconNet | 26.78 | 26.90 | 25.39 | 25.57 | 22.71 | 22.94 | 19.17 | 19.37 | |
| DR2-Net | 27.74 | 27.77 | 25.45 | 25.60 | 22.69 | 22.91 | 19.02 | 19.15 | |
| FCMN | 28.97 | 29.03 | 25.57 | 25.77 | 23.17 | 23.39 | 19.14 | 19.33 | |
| CombNet | 28.41 | 28.73 | 25.47 | 25.62 | 23.23 | 23.44 | 19.19 | 19.38 | |
| Baboon | TVAL3 | 16.24 | 16.22 | 14.89 | 14.85 | 12.17 | 12.12 | 7.89 | 7.80 |
| D-AMP | 21.74 | 21.83 | 17.94 | 18.09 | 9.79 | 9.97 | 5.41 | 5.57 | |
| ReconNet | 16.83 | 16.89 | 15.91 | 16.02 | 15.59 | 15.70 | 14.82 | 14.92 | |
| DR2-Net | 17.07 | 17.18 | 16.11 | 16.20 | 15.23 | 15.34 | 15.02 | 15.18 | |
| FCMN | 16.89 | 16.96 | 16.17 | 16.25 | 15.71 | 15.87 | 14.98 | 15.15 | |
| CombNet | 17.76 | 17.85 | 16.41 | 16.48 | 15.80 | 15.90 | 15.10 | 15.19 | |
| 56028 | TVAL3 | 17.02 | 17.09 | 16.72 | 16.74 | 15.14 | 15.23 | 10.80 | 10.91 |
| D-AMP | 19.56 | 19.61 | 16.01 | 16.08 | 9.24 | 9.30 | 6.38 | 6.46 | |
| ReconNet | 19.06 | 19.16 | 17.25 | 17.41 | 16.21 | 16.36 | 14.22 | 14.35 | |
| DR2-Net | 20.09 | 20.13 | 17.56 | 17.75 | 16.35 | 16.51 | 14.36 | 14.47 | |
| FCMN | 20.19 | 20.30 | 17.94 | 18.07 | 16.78 | 16.92 | 14.69 | 14.59 | |
| CombNet | 20.21 | 20.34 | 18.27 | 18.41 | 16.86 | 17.03 | 14.78 | 14.68 | |
| 67079 | TVAL3 | 20.22 | 20.25 | 19.37 | 19.41 | 18.54 | 18.62 | 11.33 | 11.46 |
| D-AMP | 23.37 | 23.43 | 15.93 | 16.02 | 8.70 | 8.77 | 5.58 | 5.06 | |
| ReconNet | 21.10 | 21.17 | 19.84 | 19.98 | 18.42 | 18.58 | 16.43 | 16.59 | |
| DR2-Net | 22.40 | 22.46 | 20.11 | 20.25 | 18.23 | 18.38 | 16.88 | 17.01 | |
| FCMN | 22.07 | 22.13 | 20.26 | 20.39 | 18.89 | 19.03 | 16.91 | 17.04 | |
| CombNet | 22.61 | 22.80 | 20.32 | 20.45 | 18.99 | 19.12 | 16.93 | 17.06 | |
| 92059 | TVAL3 | 22.61 | 22.69 | 21.18 | 21.27 | 20.80 | 20.96 | 13.97 | 14.14 |
| D-AMP | 24.86 | 24.95 | 21.05 | 21.11 | 12.28 | 12.35 | 10.39 | 10.43 | |
| ReconNet | 23.47 | 23.55 | 22.34 | 22.48 | 21.00 | 21.16 | 18.99 | 19.12 | |
| DR2-Net | 24.64 | 24.72 | 22.39 | 22.54 | 20.65 | 20.80 | 19.15 | 19.27 | |
| FCMN | 24.23 | 24.31 | 22.35 | 22.49 | 21.16 | 21.31 | 19.12 | 19.23 | |
| CombNet | 24.89 | 24.98 | 22.52 | 22.63 | 21.41 | 21.55 | 19.19 | 19.31 | |
| 113016 | TVAL3 | 19.38 | 19.42 | 18.28 | 18.31 | 16.97 | 17.06 | 9.05 | 9.11 |
| D-AMP | 23.57 | 23.62 | 18.49 | 18.57 | 8.27 | 8.35 | 5.36 | 5.41 | |
| ReconNet | 19.88 | 19.94 | 18.66 | 18.87 | 17.61 | 17.75 | 16.44 | 16.57 | |
| DR2-Net | 20.57 | 20.62 | 18.95 | 19.07 | 17.67 | 17.82 | 16.52 | 16.63 | |
| FCMN | 20.23 | 20.38 | 18.96 | 19.08 | 17.92 | 18.04 | 16.58 | 16.71 | |
| CombNet | 21.86 | 21.99 | 19.06 | 19.17 | 18.05 | 18.18 | 16.65 | 16.76 | |
| 126007 | TVAL3 | 24.42 | 24.49 | 22.38 | 23.41 | 20.55 | 20.59 | 13.68 | 13.63 |
| D-AMP | 27.14 | 27.18 | 21.76 | 21.83 | 18.41 | 18.55 | 9.38 | 9.46 | |
| ReconNet | 23.99 | 24.07 | 22.47 | 22.61 | 20.75 | 20.92 | 18.90 | 19.07 | |
| DR2-Net | 25.08 | 22.20 | 22.83 | 22.90 | 20.92 | 21.08 | 18.86 | 19.00 | |
| FCMN | 25.17 | 25.31 | 22.86 | 22.99 | 21.07 | 21.31 | 19.02 | 19.16 | |
| CombNet | 25.19 | 25.34 | 22.89 | 23.01 | 21.20 | 21.36 | 19.13 | 19.27 | |
| 189003 | TVAL3 | 15.99 | 16.03 | 13.92 | 13.89 | 12.14 | 12.16 | 8.67 | 8.59 |
| D-AMP | 16.93 | 17.01 | 11.00 | 11.12 | 6.79 | 6.87 | 5.65 | 5.74 | |
| ReconNet | 19.37 | 19.46 | 17.65 | 17.81 | 16.08 | 16.25 | 9.61 | 9.74 | |
| DR2-Net | 21.05 | 21.14 | 17.78 | 17.92 | 16.18 | 16.36 | 13.69 | 13.81 | |
| FCMN | 20.76 | 20.83 | 18.42 | 18.55 | 16.86 | 17.02 | 14.52 | 14.65 | |
| CombNet | 21.77 | 21.92 | 18.50 | 18.63 | 16.81 | 16.97 | 14.19 | 14.34 | |
Note: The experimental data of the same picture are different from those in Ref. 7 because different computers are used. MR = Measurement rate. The bold value represents the highest value of PSNR obtained by the six algorithms at different measurement rates, using BM3D and not using BM3D.
Comparison of PSNR (dB) of four algorithms for ten different images at the same sampling rate.
According to the image processing method of the improved CS algorithm proposed in this paper, take the ten pictures in Fig. 6 as test images, and the simulation results are compared with the processing methods of TVAL3, D-AMP, ReconNet, DR2-Net, FCMN, and get the conclusion. The simulation data is shown in Tables 1 and 2 The subjective reconstruction quality of the images processed by the four algorithms is shown in Table 1. The average PSNR when using BM3D is shown in Table 2. Compared to the PSNR of images reconstructed by the other three algorithms, it can be seen that the PSNR of CombNet is significantly improved. An improvement in PSNR means that the smoothness will be better and the distortion will be reduced. By comparing the simulation data with the reconstruction quality, CombNet effectively improves the image processing quality, significantly reduces the loss of image detail, makes the reconstructed image clearer, and the reconstruction effect is better. In addition, CombNet's PSNR is higher when the sampling rate is low. Experiments have shown that CombNet can adapt to low sampling rate environments.
| Alogrithm | MR = 0.25 | MR = 0.1 | MR = 0.04 | MR = 0.01 |
|---|---|---|---|---|
| TVAL3 | 19.95 | 18.54 | 17.20 | 11.22 |
| D-AMP | 24.03 | 18.02 | 10.44 | 6.63 |
| ReconNet | 21.71 | 20.43 | 18.95 | 16.46 |
| DR2-Net | 22.40 | 20.62 | 18.90 | 16.96 |
| FCMN | 22.66 | 20.74 | 19.31 | 17.12 |
| CombNet | 23.25 | 20.96 | 19.40 | 17.13 |
PSNR = peak signal-to-noise ratio, MR = Measurement rate.
The bold value represents the highest value of PSNR obtained by the six algorithms at different measurement rates, using BM3D and not using BM3D.
The average PSNR of the four algorithms at different sampling rates when using BM3D.
To verify the effect of different algorithms on reconstructed images at different sampling rates, we selected two images, as shown in Fig. 7. Among them, the first image has more detailed information, and more information needs to be reconstructed to reconstruct a high-quality images. The second picture is smoother, which does not require much reconstruction information to satisfy the visual experience. Therefore, this paper takes these two pictures as the representation of the reality image. Figure 7 shows the visual effect comparison of the original image, TVAL3, D-AMP, ReconNet, DR2-Net, FCMN, and the improved algorithm in this paper. The sampling rate of reconstruction is 0.1. It can be found that the reconstructed image of this algorithm is the closest to the original image, and the reconstructed image has the best effect.

Compare the reconstructed images of four different algorithms at a sampling rate of 0.1.
5. CONCLUSION
With the continuous development of image and video information processing, CS technology has been widely used in image processing. Since the CS technology only needs to collect a small amount of information, the original signal can be recovered and the coding complexity and resource consumption are reduced. Therefore, the CS technology is called a hotspot of image processing.
In the traditional theory of CS algorithms, the iterative algorithm has no advantage because of its algorithm and time complexity, as well as the effect of reconstruction. In order to adapt to the needs of image and video signal processing in today's social life, improve the speed and quality of image processing, and effectively solve the block effect in the process of block processing. This paper proposes a new network structure CombNet for CS image reconstruction. Simulation and verification prove that it provides excellent reconstruction quality when the sampling rate is high, retains rich image information, and can retain key image information when the sampling rate is low, which effectively improves the image processing quality.
REFERENCES
Cite this article
TY - JOUR AU - Yuhong Liu AU - Shuying Liu AU - Cuiran Li AU - Danfeng Yang PY - 2019 DA - 2019/08/19 TI - Compressed Sensing Image Reconstruction Based on Convolutional Neural Network JO - International Journal of Computational Intelligence Systems SP - 873 EP - 880 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.190808.001 DO - 10.2991/ijcis.d.190808.001 ID - Liu2019 ER -