
Dynamic Knowledge Update Using Three-Way Decisions in Dominance-Based Rough Sets Approach While the Object Set Varies
- DOI
- 10.2991/ijcis.d.190807.001How to use a DOI?
- Keywords
- Dominance-based rough sets approach (DRSA); Three-way decisions (3wds); Approximations; Dynamic maintenance; Vector inner product
- Abstract
Dominance-based rough set approach is the extension of classical Pawlak rough set theories and methodologies, in which the information with preference-ordered relation on the domain of attribute value is fully considered. In the dominance-based information system, upper and lower approximations will be changed while the object set varies over time and the approximations need to be updated correspondingly for their variations result in changes of knowledge and rules. Considering that three-way decisions is a special class of general and effective human ways of problem solving and information processing, a new incremental maintenance mechanism using three-way decisions is proposed in this paper, namely, the universe is divided into three pair-wise disjoint subsets firstly, then appropriate strategies are developed and acted on each subsets. Furthermore, the corresponding methods for updating the approximations of upward unions and downward unions of decision classes are analyzed systematically under the variations of object set in the dominance-based information system from the perspective of three-way decisions. Moreover, considering vector representation and calculation is intuitive and concise, two incremental update algorithms of approximations are suggested and implemented in the MATLAB platform. Finally, some tests on data sets from UCI (UC Irvine Machine Learning Repository) are undertaken to verify the effectiveness of the proposed methods. Compared with the non-incremental updating methods, the proposed incremental updating method with three-way decisions generally exhibits a better performance.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Rough set theory (RST) provides a powerful mathematical tool for modeling and processing problems with incomplete, imprecise, uncertain and vague information [1] and it is one of the three primary models of Granular Computing [2] (GrC). The recent two decades have witnessed the booming interest and growing development in research of RST and its applications. As a kind of information processing tools, RST has been widely applied to the fields of artificial intelligence and cognitive sciences, such as pattern recognition [3], knowledge discovery [4,5], decision making [6,7], inductive reasoning [8] and machine learning [9]. In multiple-criteria decision making problems, attributes with preference-order domain (Criteria) constitute an important kind of attribute and should be brought to our great attention. However, only attribute values themselves, by which to tell one object from another, are considered and the preference-order relations among criteria values domain are not considered in RST. On this account, the information with preference-order attribute values domain cannot be processed by RST. Greco et al. [10–12] proposed the Dominance-based Rough Set Approach (DRSA) to address this issue, in which the innovation mainly lies in the substitution of the indiscernibility relation by dominance relation. Comparing with the decision rules derived from RST, those derived from DRSA are easy to understand as well as consistent with the practical situation due to the fact that the ordering properties of attributes are taken into account in DRSA. In real-life application, information system (IS) always varies with time for the generation and the collection of data are dynamic, called dynamic IS, it can cause the corresponding changes of the approximations of a concept from which the knowledge are acquired [13]. So updates of the approximations are of great importance for knowledge maintenance and other related tasks. Incremental update scheme is an effective and efficient technique for knowledge update, which enables to acquire new knowledge on the basis of prior knowledge without recalculation from scratch under variation of IS. A great deal of researches have been done in the area of incremental knowledge maintenance under rough sets methodologies. In general, the researches on incremental knowledge update can be fallen into four categories owing to the fact that ISs evolve over time with four levels of variational situations, i.e., (1) incremental knowledge update while the object set varies [14–17]; (2) incremental knowledge update while the attribute set varies [18–23]; (3) incremental knowledge update while the attribute values vary [24–27]; (4) incremental knowledge update under the simultaneous variations of object set and attribute set (or object set and attribute value, attribute set and attribute value) [28–32]. All these researches will help decision makers update knowledge from different perspectives in different kinds of ISs. Some achievements based on rough set methodologies under the changed IS are as follows:
Li et al. presented a new approach for incrementally updating approximations of a concept under the characteristic relation-based rough sets when the attribute set varies over time for dynamic attribute generalization, which can deal with the case of adding and removing some attributes simultaneously in the IS [14]. Huang et al. proposed mechanisms for updating approximations in probabilistic set-valued IS with the variation of attributes [31]. Zhang et al. developed the change of approximations in neighborhood decision systems when the object set evolves over time, and proposed two fast incremental algorithms for updating approximations when multiple objects enter into or get out of the neighborhood decision table [15]. Considering dynamic updating of attribute reduction for data vary with time, Jing et al. examined an incremental attribute reduction algorithm with a multi-granulation view to maintenance reduct of large-scale data sets dynamically [33,34]. Liu et al. proposed some relevant strategies and algorithms for incremental learning knowledge in probabilistic rough sets when attributes evolve with time [22]. Zhang et al. suggested an incremental methods for updating rough approximations in interval-valued ISs while attributes set evolves [18]. Luo et al. developed an incremental learning technique for hierarchical multi-criteria classification while attribute values vary across different levels of granulations [25]. He further analyzed the updating mechanisms of approximations under the variation of the object set and criteria values respectively in set-valued-ordered IS and set-valued decision system [35]. Zhang et al. examined the updating approach of approximations of the concept in set-valued IS by using matrix under the variation of attribute set [36]. Wang et al. proposed an incremental matrix method for updating approximations under the variable precision rough set model at insertion or deletion of a single object [37]. Huang et al. introduced an incremental mechanisms for updating rough fuzzy approximations with simultaneous variation of objects and attributes set by using matrix operator [31].
The theory of three-way decisions was introduced by Yao in order to model a particular class of human heuristic ways of problem solving and information processing [38,39] and its essential ideas are widely applied in many fields and disciplines. As for the application of three-way decisions in dynamic knowledge update field. Yu et al. proposed a new tree-based incremental overlapping clustering method using the three-way decision theory in order to efficiently update the clustering when the data changes [40]. Yang et al. proposed a unified model of sequential three-way decisions and multi-level incremental processing for complex problem solving [28,41], then they suggested an unified dynamic framework of decision-theoretic rough sets for incrementally updating three-way probabilistic regions [42].
In this paper, inspired by the trisecting-and-acting model of three-way decisions proposed by Yao, the essential ideas of the trisecting-and-acting model, namely, tri-partition and action are applied to analyze the incremental update mechanisms of approximations with the variation of objects set in dynamic dominance-based IS. Subsequently, the updates of the approximations is realized by using column vector as representation tool as well as computational tool, considering that the column vector is concise and intuitional in representation and operation. Our research motivation is to investigate incremental update of approximations from a new view and to exploit its feasibility and efficiency.
The remainder of the paper is organized as follows: In Section 2, some basic concepts of DRST as well as relevant operations of Boolean column vector are introduced. Under the variation of the object set, the re-judgement of existing relationship between subsets is examined in Section 3, the analyses on incremental update of approximations with three-way decisions and its corresponding illustrated example are presented in Sections 4 and 5, respectively. In Section 6, we propose two incremental algorithms using vector operations for computing approximations based on the preceding analyses. Performance evaluations are illustrated in Section 7. The paper ends with conclusions and further research topics in Section 8.
There are two contributions from our research. One is to provide a three-way decisions perspective on incremental update of approximations in DRSA. The other is an application of Boolean column vector inner product in judging the relationship (inclusion or intersection) between two sets, by which some objects need to be merged to the prior approximations and some other objects need to be removed from the prior approximations during the incremental update process of approximations.
2. PRELIMINARIES
2.1. Symbol Notation
For the sake of convenience, the symbols used in this paper and their corresponding meanings are listed in Table 1.
| Symbol | Meaning |
|---|---|
| X | The column vector of subset X |
| Dominance relation matrix and its transposed matrix | |
| The column vector of |
|
| The column vector of |
|
| The column vector of |
|
| The column vector of |
|
| ones(n, 1), ones(1, n) | The n-dimensional row and column vector with all the components are equal to 1 |
| The cardinality of set | |
| [ A;B] | A column vector which is constructed though concatenation of column vector A and B |
| A[m:n] | Column sub-vector which consist of rows m-n of column vector A |
Description of symbols.
2.2. The Basic Concepts of Dominance-Based Rough Set Approach
Some basic concepts of RST and DRSA are briefly reviewed in this subsection [1,10–12].
An IS is a quadruple
In an IS,
In Ref. [10], the granules of knowledge of element x used in DRSA for approximation of the unions
The equivalence classes partition of universe U by the decision attribute d is denoted as
Definition 1.
Assume that IS is an information system,
2.3. Brief Introduction to Three-Way Decisions
In this subsection, we briefly introduce the essential ideas of three-way decisions and trisecting-and-acting model used in this research.
Three-way decisions, proposed by Yao, is a general and effective human heuristic way to problem solving and information processing, their aim is to make fast, low cost and/or high benefit decisions in solving problems with uncertainty and imprecision [38,39,43,44]. The essential ideas of three-way decisions are described in term of a ternary classification according to evaluations of a set of criteria [38]. The two basic tasks of three-way decisions, which gives rise to a trisecting-and-acting model of three-way decisions, are trisecting and acting. Trisecting, namely, tri-partition is to divide a whole into three pair-wise disjoint parts or regions and acting is to develop an appropriate strategy on each part or region [39]. In many real applications, trisecting-and-acting model can turn complexity into simplicity [39] due to its firm cognitive basis and appropriate strategies and it would be a simple, general and flexible model.
2.4. The Boolean Column Vector
The basic concepts of Boolean column vector as well as the operations on Boolean Column vector (including the operations we proposed) are introduced in this subsection [45–47]. Definition 2 is quoted from Ref. [45], Definition 3 is quoted from Ref. [46] and Definition 7 is quoted from Ref. [47]. The vector inner product will be used in analyses on incremental updates of approximations of unions of decision classes, the other operations of vector will be used in the incremental update matrix algorithms of the unions’ approximations at insertion or deletion of an object in Section 6.
Definition 2.
Assume that
In Formula (8), the location of object
Example 1.
Assume that
Example 2.
Suppose
2.4.1. Operations on Boolean column vector
Assume set X, Y and Z are subsets of university U and their corresponding n-dimension Boolean column vectors are X, Y, Z respectively and
Definition 3.
Let
The following formulas are easy to gained from Definition 3.
Vector Inner product can be used to judge the intersection or inclusion between two sets.
Example 3.
(Continuation of Example 1)
Taking into account the characteristics of Boolean column vector, we defined their operations corresponding to the intersection, union and difference of two sets respectively as follows:
Definition 4.
Let
Example 4.
(Continuation of Example 1)
Let
Definition 5.
Let
Z is called summation of X and Y. It can be used to calculate the union of two sets.
Example 5.
(Continuation of Example 1)
Let
Definition 6.
Let
Z is called difference of X and Y. It can be applied to calculate the difference of two sets.
Example 6.
(Continuation of Example 1)
Let
Definition 7.
Assume that
It is obviously that
Inclusion degree can be used to judge the relationship of two sets. The following formulas are easy to gained from Definitions 7 and 3.
3. THE RE-JUDGEMENT OF EXISTING RELATIONSHIP BETWEEN SUBSETS UNDER VARIATIONS OF OBJECTS
According to the definitions of approximations, the judgement of inclusion relationship or intersection relationship between two subsets of universe is a prerequisite for calculating approximations in RST. However, the pre-existing relationship between two subsets will change after new objects are inserted into the universe or the original objects are removed from the universe, so the relationship between two subsets remains to be re-judged. In this paper, Boolean column vector is employed to denote the subsets of the universe, and the problem that judge one object belongs to approximations of upward (downward) unions or not can be transformed into the operations of Boolean column vectors and the subsequent simple numeric comparison. In short, the vector approach of dynamic maintenance and update of approximations at variation of objects is that of incremental maintenance and update of approximations via operations on column vectors. Therefore, the research of this section is the foundation of follow-up analyses on incremental update of approximations from perspective of trisecting and acting.
Suppose that set A and set B are two non-empty subsets of the universe U.
The Lemma 1 and Lemma 2 can be applied to re-judge the relationship between set A and set B after object
Lemma 1.
Assume that
The equivalent expressions of column vector are as follows:
Lemma 2.
Assume that
Its equivalent expression of column vector’s inner product is as follows:
Proof.
The above conclusions can be driven easily from connotation of the inclusion relation between two sets.
Lemma 2 can be demonstrated by the Venn diagram in the Fig. 1.

The change of inclusion relation between two subsets after insertion of object
Similarly, the Lemma 3 and Lemma 4 can be applied to re-judge the relationship between set A and set B after object
Lemma 3.
Assume that
The equivalent expressions of column vector are as follows:
Lemma 4.
Assume that
Its equivalent expression of column vector’s inner product is as follows:
Proof.
The above conclusions can be driven easily from connotation of the inclusion relation. As shown in the Venn diagram in Fig. 2, three cases are considered, i.e.,
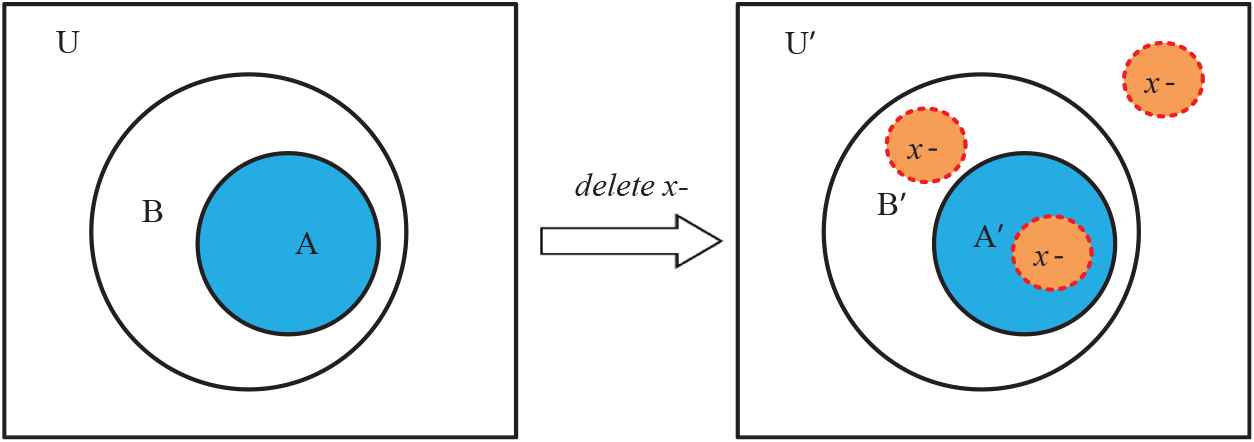
The inclusion relation between two subsets remains unchanged after deletion of object
Lemma 4 demonstrates that the removal of single object from the universe will not alter the existing inclusion relationship between two subsets.
4. THE ANALYSES ON INCREMENTAL UPDATE OF APPROXIMATIONS WITH THREE-WAY DECISIONS
In this section, a trisecting-and-acting model is presented to update approximations in DRSA incrementally and then the methods of tri-partition of universe at insertion or removal of one object are discussed.
4.1. A Trisecting-and-Acting Model for Incremental Update of Approximations in DRSA
The incremental update method of approximations is just the method in which updated approximations can be acquired on the basis of the approximations prior to update by some certain operations and it is not necessary to recompute from scratch. As for the incremental update using three-way decisions, the certain operations refer to trisecting and acting.
We take the update of
Above all, the objects in the universe

The unified framework of update of approximations.
The first part consists of all the objects which do not belong to the original approximation and belong to the updated approximation simultaneously, denoted as
The second part consists of all the objects which belong to the approximation before update and no longer belong to the approximation after update, denoted as
The rest objects of the universe constitute the third part, i.e., the third part is composed of all the objects except for the first part and the second part, denoted as
It’s worth noting that the inserted object
Secondly, the different strategy will be developed and adopted in the different part after trisection. It is obviously that the strategies should be developed and adopted only in the set
So the incremental update of
Computes the set
Subtracts the set
Computes the union set of
Thus, the incremental update of
The incremental update of
As for the case of object’s deletion, the process of incremental update of approximations is similar with that of object’s insertion, so it is not discussed again.
In the following subsections, under the unified frame of trisecting-and-acting model, only methods of tri-partition are discussed for update on dynamic environment of insertion and removal of one object, respectively. What’s more, it can be simplified as a series of calculational formulas of the set
4.2. The Update of Approximations Using Trisecting-and-Acting Model at Insertion of Object
Supposing
4.2.1. The update of unions of decision classes
Supposing that
The update of upward unions of decision classes
The updated upper unions of decision classes is as following formula:
The corresponding column vector of the updated upward unions of decision classes can be denoted as
The update of downward unions of decision classes
The updated downward unions of decision classes is as following formula:
The corresponding column vector of the updated upward union set can be denoted as
It is obviously that the dimension of updated column vector will increase to n + 1 after removal of
4.2.2. Trisection of universe at insertion of object
The calculations of the set N and M are discussed in Theorems 1–4 respectively. The computational results lead to tri-partition of universe naturally.
The computational formula of the set M and N for incremental update of
Theorem 1.
Proof.
Case 1: If
Case 2: Assume that
To sum up,
Case 3: Assume that
So,
Case 1: For
Case 2: Assume that
So,
Case 3: Assume that
So,
The computational formula of the set M and N for incremental update of
Theorem 2.
Proof.
Assume that
So,
Case 1: For
Case 2: Assume that
So,
Case 1: If
Case 2: Assume that
To sum up,
The computational formula of the set M and N for incremental update of
Theorem 3.
The computational formula of the set M and N for incremental update of
Theorem 4.
4.3. The Update of Approximations Using Trisecting-and-Acting Model at Deletion of Object
Supposing
4.3.1. The update of unions of decision classes
Supposing that
The update of upward unions of decision classes
The updated upward unions of decision classes is as following formula:
The corresponding column vector of the updated upward union set can be denoted as
The update of downward unions of decision classes
The updated downward unions of decision classes is as following formula:
The corresponding column vector of the updated upward unions can be denoted as
It is obviously that the dimension of updated column vector will decrease to n−1 after removal of
4.3.2. Trisection of universe at deletion of object
The calculations of the set N and M are discussed in Theorem 5–8, respectively. The computational results lead to tri-partition of universe naturally.
The computational formula of the set M and N for incrementally update of
Theorem 5.
Proof.
When
When
So
The computational formula of the set M and N for incrementally update of
Theorem 6.
Proof.
When
To sum up,
When
For
The computational formula of the set M and N for incrementally update of
Theorem 7.
The computational formula of the set M and N for incremental update of
Theorem 8.
5. ILLUSTRATIVE EXAMPLE
Consider the following example (See Table 2). A set of 16 objects is described by the set of 3 attributes (criteria)
| Object | ||||
|---|---|---|---|---|
| 0.8 | 0.5 | 1.5 | ||
| 1 | 1.5 | 8 | ||
| 1 | 3 | 5 | ||
| 2.5 | 4 | 11 | ||
| 1.2 | 1 | 7 | ||
| 1.9 | 4.5 | 14 | ||
| 2.8 | 5.5 | 15 | ||
| 2.4 | 4 | 13 | ||
| 0.6 | 3 | 6 | ||
| 2 | 2.5 | 6 | ||
| 2.4 | 3.5 | 9 | ||
| 1.6 | 3 | 12 | ||
| 1.8 | 5 | 9.5 | ||
| 0.6 | 2 | 2.5 | ||
| 1 | 2 | 4.5 | ||
| 3 | 4.5 | 9 |
Illustrative data table.
Let
Now we consider the following two cases at time t + 1:
A new object
Object 0.8 0.5 1.5 1 1.5 8 1 3 5 2.5 4 11 1.2 1 7 1.9 4.5 14 2.8 5.5 15 2.4 4 13 0.6 3 6 2 2.5 6 2.4 3.5 9 1.6 3 12 1.8 5 9.5 0.6 2 2.5 1 2 4.5 3 4.5 9 1.8 2.8 3.5 Table 3Insertion of one object.
The
According to Theorems 1–4, we have
The object
Object 0.8 0.5 1.5 1 1.5 8 1 3 5 2.5 4 11 1.2 1 7 1.9 4.5 14 2.8 5.5 15 2.4 4 13 0.6 3 6 2.4 3.5 9 1.6 3 12 1.8 5 9.5 0.6 2 2.5 1 2 4.5 3 4.5 9 Table 4Deletion of one object.
According to Theorem 5–8, we have
6. INCREMENTAL UPDATE MATRIX ALGORITHM OF THE UNION SET’S APPROXIMATIONS AT INSERTION OR DELETION OF ONE OBJECT
According to the preceding methods using trisecting and acting in update of approximations at object’s insertion or removal, their corresponding incremental update algorithms are proposed. All the algorithms are described by matrix considering that representation and calculation of matrix are intuitive and concise.
The Algorithm 1 is finished.
Assume that number of objects, number of attributes and number of dominance classes are n1, n2 and m, respectively. The time complexity of Algorithm 1 is equal to
Algorithm 1: A matrix-based incremental algorithm for updating approximations of unions of decision classes when a new object adds to an information system.
Input:
(1)
(2)
(3) An inserted object
Output:
Begin
Compute
Update
Update
For n = 1, …, m do
If(n < g) Then// g is the index of the class which the object
// assigned
If
End.
If
End.
If
If
End.
End.
If(n == g) Then
If
End.
If
End.
If
End.
End.
If(n > g) Then
If
If
If
End.
End.
End.
Return
End.
The Algorithm 2 is finished.
Similar to Algorithm 1, the time complexity of Algorithm 2 is approximately equal to
The non-incremental algorithm for computing the approximations is given below in order to compare its performance with that of the incremental algorithm in the next subsection.
Algorithm 2: A matrix-based incremental algorithm for updating approximation of unions of decision classes when an object gets out of an information system.
Input:
(1)
(2)
(3) An deleted object
Begin
Update
Update
For n = 1, …, m do
If (n < g) Then// g is the index of the class which the object
//is assigned.
If
End.
For each
If
End
For each
If
End.
End
If
End.
If(n == g) Then
If
End.
For each
If
End.
If
End.
For each
If
End.
End.
If (n > g) Then
For each
If
End.
End.
If
If
End.
For each
If
End
End.
End.
The Algorithm 3 is finished.
The time complexity of Algorithm 3 is equal to
Algorithms 1–3 have the same space complexity due to the same memory space.
Algorithm 3: A matrix-based algorithm for computing approximations of unions of decision classes.
Input:
Output:
Begin
Computing
Computing matrix multiplications
Computing Column Vector by sum of row sum
End.
7. THE TEST AND EVALUATION IN UCI DATA SET
Three data sets are selected (i.e., ‘Wine’ data set, ‘Car evaluation’ data set and ‘Abalone’ data set) from the machine learning data repository UCI (http://archive.ics.uci.edu/ml/) to test the performance of Algorithms 1 and 2 proposed in this paper and the existing Algorithm 3 (non-incremental updating algorithm) in order to verify the effectiveness of the proposed algorithms. Descriptions of the selected data sets are shown in Table 5.
| Name | Number of Attributes | Number of Objects | Number of Classes |
|---|---|---|---|
| Wine | 13 | 178 | 3 |
| Car evaluation | 6 | 1728 | 4 |
| Abalone | 8 | 4177 | 29 |
A descriptions on the selected three data sets.
Experimental Platform: CPU Intel Core i7-4510U (2.00 GHz), 8.0G Memory, Windows 8 operation system, Matlab7.0 development tool. Experimental method is as follows:
To show the time efficiency of dynamic algorithm (Algorithms 1 and 2) and compare with the existing static algorithm (Algorithm 3), each of selected data sets is divided into 10 sub-data sets. The generation of sub-data set follows four principles, take the ‘wine’ data set as an example to explain how to generate sub-data set from whole data set. Firstly, the ‘wine’ data set is divided into 10 subsets, each sub-data set is named as wine 1, wine 2, wine 3, wine 4, … and wine 10, respectively. Secondly, the size of wine 1, wine 2, wine 3, … and wine 9 is one-tenth, two-tenths, three-tenths, … and nine-tenths of that of ‘wine’ data set, respectively, wine 10 is the copy of wine data set. Thirdly, there exists the following inclusion relation among these ten sub-data sets, the wine 10 contains wine 9, wine 9 contains wine 8, …, wine 3 contains wine 2 and wine 2 contains wine1. Fourthly, the number of objects in a certain class of each sub-data set should be proportional to the size of the sub-data set in order to keep the original proportion of distribution of each class in whole data set. The distributions of each class in sub-data set of ‘wine’ are shown in Table 6.
| Sub-Data Set | Total Objects | Objects in Class 1 | Objects in Class 2 | Objects in Class 3 |
|---|---|---|---|---|
| Wine 1 | 18 | 6 | 7 | 5 |
| Wine 2 | 36 | 12 | 14 | 10 |
| Wine 3 | 54 | 18 | 21 | 15 |
| Wine 4 | 72 | 24 | 28 | 20 |
| Wine 5 | 90 | 31 | 35 | 24 |
| Wine 6 | 107 | 36 | 42 | 29 |
| Wine 7 | 125 | 42 | 49 | 34 |
| Wine 8 | 142 | 48 | 56 | 38 |
| Wine 9 | 160 | 54 | 63 | 43 |
| Wine 10 | 178 | 59 | 71 | 48 |
The distribution of classes in each subset of Wine.
The running time of the proposed Algorithms 1 and 2 and the existing Algorithm 3 can be gained by executing the corresponding programs on each of these 10 sub-data sets. Concerned programs which update four approximations of DRSA while object set varies are all developed on Matlab7.0 platform.
The experimental results are depicted in Fig. 4, where the x-coordinate pertains to the test sub-data sets, while y-coordinate concerns the computing time of updating approximations. The following conclusions can be drawn from the experimental results on three UCI data sets:
The incremental updating matrix algorithms (Algorithms 1 and 2) have more effectiveness compared to the non-incremental updating matrix algorithm (Algorithm 3), showing that the time consume in incremental updating algorithm is obviously less that of the non-incremental ones.
For the same data set, the computational times of the incremental updating matrix algorithms and the non-incremental updating matrix algorithm all grow up with the increasing size of sub-data set. Furthermore, Algorithms 1 and 2 are much more faster than Algorithm 3, and the difference between incremental algorithms and the non-incremental algorithm are getting larger and larger while the size of sub-data set increases.
The running times of Algorithm 3 increases sharply with the increasing size of data while the running times of Algorithms 1 and 2 increase very slowly, demonstrating that the larger the size of data, the greater the advantage of Algorithms 1 and 2.
For the incremental update algorithm, the running time of object’s insertion is more less than that of object’s deletion in the same sub-data set. The reason is that there are more loop structure in Algorithm 2, which lead to more time consume.

The curve of time-consuming for updating of approximations at insertion or deletion of a one objects.
It can be seen from the above four conclusions that the incremental update approaches of approximations with trisecting-and-acting model of three-way decisions are feasible and outperform the existing non-incremental approach.
8. CONCLUSIONS
Incrementally updating approximations in rough sets is a critical issue for knowledge update, maintenance and data mining related task in dynamic IS. In this paper, considering the dynamic scenario of one object’s insertion or deletion, an incremental updated mechanism of approximations in DRSA is introduced from the perspective of three-way decisions and three update steps are derived from the updated mechanism. Then we suggested a concrete incremental updating approach of approximations in DRSA while the object set varies, in which Boolean column vectors are used as an expression tool of subsets as well as a calculation tool of approximations. The proposed methods can effectively update the four approximations of DRSA on the basis of the prior approximations. With a numerical example and some test results on UCI data set, we can conclude that the proposed incremental vector method for updating the approximations of DRSA is feasible and can effectively reduce the computational time in comparison to the existing non-incremental vector method when the set of objects changes. One of the further work is to investigate the approaches for updating approximations of DRSA under variations of attribute and attribute value and study the corresponding vector-based incremental algorithms.
CONFLICT OF INTEREST
The authors declare no conflicts of interest.
AUTHORS' CONTRIBUTIONS
All authors have contributed to this paper. The individual responsibilities and contribution of all authors can be described as follows: The idea of this paper was put forward by Lei Wang, he also wrote the paper. Min Li summarized the existing work of the research problem and presented the illustrative example in Section 5. The works in Section 3 were done by Jun Ye. The submission and revision of this paper was completed by Lei Wang and Xiang Yu. The tests on UCI data sets were performed by Ziqi Wang and Shaobo Deng. The other works of this paper were done by Lei Wang.
Funding Statement
This work was supported by the fund of Development Plan of Jiangxi Province of China for the Young and Middle-Aged Teachers in Universities to Pursue Study Abroad as a Visiting Scholar (Jiangxi Education Administration Letter [2016] No. 169), the National Natural Science Foundation of China (Nos. 61562061, 6136304 and 61703199), and the fund of Science and Technology Project of Ministry of Education of Jiangxi province of China (No. GJJ170995).
ACKNOWLEDGMENTS
The author would like to thank reviewers of the paper for their constructive comments which greatly improve the quality of this paper. This work was supported by the fund of Development Plan of Jiangxi Province of China for the Young and Middle-Aged Teachers in Universities to Pursue Study Abroad as a Visiting Scholar (Jiangxi Education Administration Letter [2016] No. 169), the National Natural Science Foundation of China (No. 61562061, No. 61363047, No. 61703199), and the fund of Science and Technology Project of Ministry of Education of Jiangxi province of China (No. GJJ170995).
REFERENCES
Cite this article
TY - JOUR AU - Lei Wang AU - Min Li AU - Jun Ye AU - Xiang Yu AU - Ziqi Wang AU - Shaobo Deng PY - 2019 DA - 2019/08/22 TI - Dynamic Knowledge Update Using Three-Way Decisions in Dominance-Based Rough Sets Approach While the Object Set Varies JO - International Journal of Computational Intelligence Systems SP - 914 EP - 928 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.190807.001 DO - 10.2991/ijcis.d.190807.001 ID - Wang2019 ER -