
Evaluate the Effectiveness of Multiobjective Evolutionary Algorithms by Box Plots and Fuzzy TOPSIS
- DOI
- 10.2991/ijcis.d.190629.001How to use a DOI?
- Keywords
- Multiobjective problems; MOEAs; Box plots; Fuzzy TOPSIS
- Abstract
Now, there are a lot of multiobjective evolutionary algorithms (MOEAs) available and these MOEAs argue that they are competitive. In fact, these results are generally unfair and unfaithful. In order to make fair comparison, comprehensive performance index system is established. The weights among the performance index system are solved by an adaptive differential evolution (ADE) algorithm. An approach is proposed to estimate MOEAs based on box plots and fuzzy TOPSIS. Box plots are employed to depict features of performance indicators and fuzzy TOPSIS is used to make evaluation. Experiments have been tested on IEEE CEC2009. The experiment results have revealed that the evaluation approach is effective, fair, and faithful when evaluating MOEAs.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Evolutionary algorithm (EA) is a useful approach to solve multiobjective problems (MOPs). multiobjective evolutionary algorithms (MOEAs) try to find a good approximation [1,2]. Nowadays, there are a lot of MOEAs available. They are widely used to solve the real applications.
Many performance indicators are designed to evaluate MOEAs. NSGAII employed convergence and diversity indicators to compare with SPEA and PAES [3]. The set convergence and inverted generation distance (IGD) were used to evaluate the performance of MOEAD [4]. Convergence measurement, spread, hyper volume (HV), and computational time (CT) were selected as performance indicators in epsilon-MOEA [5]. To validate the proposed MOPSO, four quantitative performance indicators (success counting IGD, set coverage, two set difference HVs) and qualitative performance indicators (plotting the Pareto fronts) were adopted [6]. Three indicators: spread, additive unary epsilon, and HV were considered in SMPSO [7]. Spacing and binary C were used in GDE3 [8]. Three performance indicators: spread, generation distance (GD), and HV were used to estimate ABYSS [9]. GD, diversity, CT, and box plot were considered as measurements in MOSOS [10]. GD and diversity indicators were adopted in MOEDA [11].
In fact, every indicator can’t demonstrate the whole performance of MOEAs. It can just depict some specific qualifications of performance. It can’t estimate the whole performance of MOEAs. Therefore, it is unfaithfully to measure MOEAs performance by one or two indicators. Besides, it is known that we can’t get any useful conclusions based on a single run. Generally speaking, statistical measurement is often used, such as mean values. However, the mean values can’t give more information of indicators, such as the max value, min value, and distribution.
In order to deal with these problems, a comprehensive performance index and a novel evaluation method are proposed. Evaluations of MOEAs involve many indicators, it can be considered as a multiple criterion decision-making (MCDE) problem. MCDE techniques can be used to make evaluations. Comprehensive performance index system (HV, GD, IGD,
An approach is proposed by box plots and fuzzy TOPSIS to make fair comparisons. Box plot is commonly employed to make comparisons [3,10], which is a useful approach to depict groups of data. It is used to depict the results of performance indicators. As it is hard to compare box plots directly, fuzzy method is used to evaluate them. The efforts can give more fair and faithful comparisons than single indicator and mean values. To validate the effectiveness of the evaluation method, 14 functions from CEC 2009 are used to perform testing and make comparisons.
The main advantage of the proposed method can be listed as follows:
The performance index system is proposed, which includes HV, GD, IGD,
A novel method on how to solve the weights among the performance index system is proposed, which is different from the traditional method.
Box plots and fuzzy TOPSIS are combined to evaluate MOEAs. It is very convenient to depict features of performance indicators by Box plots. Fuzzy TOPSIS is used to make evaluation.
Section 2 presents the previous work and Section 3 introduces performance index system. The related methodologies are introduced in Section 4. In Section 5, proposed approach is presented. In Section 6, experiments are presented. In Section 7, conclusions are illustrated.
2. PREVIOUS WORK
Over the past decades, research on MOEAs has produced a large number of algorithms. These MOEAs are compared with very few, often a decade older MOEAs using some performance indicators. In fact, a common baseline for comparison should be established. Otherwise, the state of the art in MOEAs is a disputed topic [12]. Four different performance indicators: IGD, spacing, maximum spread (MS), and HV are adopted to make evaluations among different MOEAs [13]. Five indicators Pareto dominance indicator, IGD, spacing, MS, and HV are chosen to evaluate MOEAs [1]. Epitropakis et al. adopted average percentage of fault detection (APFD) indicator to evaluate seven MOEAs [14]. Error rate (ER), generational distance (GD), and Pareto subset (PS) are used to evaluate five MOEAs [15].
In the real application, AMALGAM outperformed NSGA-II, NSHS, and NSDE for the evaluation of rehabilitation of urban storm water drainage systems in terms of convergence and diversity indicators [16]. The comparative performance of MOEAs has been investigated according to their overall end-of-run results within pre-specified computational budgets when solving water resource optimization problems [17].
However, these comparisons are generally unfair and unfaithful. On the one hand, they are based on few performance indicators. Systematic, comprehensive evaluations are not implemented. On the other hand, some new proposed MOEAs are compared with very older MOEAs. In fact, evaluations of MOEAs can be considered as MCDE problems. Therefore, comprehensive performance index system should are established.
3. PERFORMANCE INDICATORS
For different performance indicators, different MOEAs tend to perform different [18]. However, it is very important to accelerate convergence of MOEAs, while keep diversity of population [19]. Thus, convergence and diversity should be given more attentions. The following outlines six of the commonly used performance indicators which can be used to evaluate MOEAs [20].
3.1. Hyper Volume
HV is demonstrated in Figure 1. The indicator computes the volume of the space which is dominated by these nondominated solutions. It is bounded by a reference point, which is plus some fixed increment. This fixed increment is necessary to allow the external points to contribute to the HV. HV can reflect the degree of outperformance between two approximation sets [21].
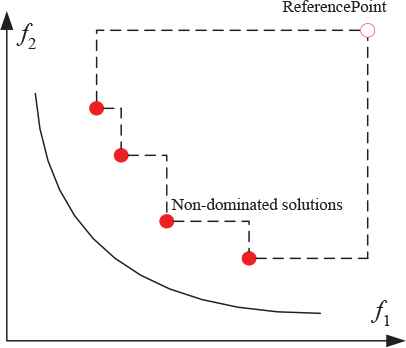
Hyper volume measurement.
3.2. Generational Distance
GD is the average distance. It is from every solution in the nondominated solutions to the nearest solutions in the reference set in Figure 2.

Generational distance.
The performance indicator measures convergence to the reference set. GD by itself can be misleading, as an approximation set containing a single solution in close convergence to the reference set produces low GD measurements, and is often combined with diversity measures in practice [22].
3.3. Inverted Generational Distance
IGD is the inverse of GD. It is also the average distance. But, it is from every solution to the nearest solution in the nondominated solutions in Figure 3.

Inverted generational distance measurement.
The distance is Euclidean distance. IGD measures diversity and convergence since an approximation set is required to have solutions near each reference set point in order to achieve low IGD measurements [20].
3.4. ε+ – Indicator
Good convergence and good diversity both result in low
3.5. Spacing
Spacing, shown in Figure 4, measures the uniformity of the spacing between solutions in an approximation set [20]. An approximation set that is well spaced will not contain dense clusters of solutions separated by large empty expanses. Note that, since spacing does not involve a reference set in its calculation, an approximation can register good spacing while having poor convergence to the reference set. It is therefore recommended to use spacing in conjunction with a performance indicator for convergence.

Spacing measurement.
3.6. Computational Time
The CT can reflect the space and time complexity of an algorithm. The less the CT is, the better the MOEA is. However, with the development of computer technology, the speed of computer becomes faster and faster.
4. RELATED METHODOLOGIES
In this section, some related methodologies are briefly introduced. They are used to formulate the proposed approach in the next section.
4.1. Box Plot
It is well known that we can’t get any conclusion according to a single run. Generally speaking, statistical measurement is often employed, such as box plot. The approach is a kind of box-and-whisker diagram. It is very convenient. It is a useful method to depict groups of data by five parameters, which include the smallest observation, largest observation, lower quartile (Q1), median (Q2), and upper quartile (Q3) [24]. They are presented in Figure 5.

Box plots diagram.
The approach is useful to demonstrate differences between populations. The approach can be drawn either vertically or horizontally.
The approach is widely used to evaluate MOEAs [3,10]. However, it is a graphical method. It is still difficult to compare the difference of box plots directly because it uses five numbers from the results of MOEAs. In order to solve the issue, the fuzzy theory is applied.
4.2. Fuzzy TOPSIS
Fuzzy method is widely used in uncertain environments [25,26]. Fuzzy TOPSIS is based on fuzzy theory. Triangular fuzzy number is widely used. A triangular fuzzy number
The distance between triangular fuzzy number
Besides, the multiplication operation between the real number k and triangular fuzzy number
In the real application, fuzzy linguistic is often adopted to deal with the ambiguities of human assessments. Therefore, it is necessary to establish the relationship between fuzzy linguistic and triangular fuzzy number. The fuzzy linguistic and their corresponding fuzzy number are listed in Table 1 and Figure 6 [27].
| Linguistic Value | Triangular Fuzzy Number |
|---|---|
| VP | (0, 0, 0.25) |
| P | (0, 0.25, 0.5) |
| FP | (0.25, 0.5, 0.75) |
| FG | (0.5, 0.75, 1) |
| G | (0.75, 1, 1) |
FG, fairly good; FP, fairly poor; G, good; P, poor; VP, very poor.
The correspondence of linguistic terms and linguistic values.

The correspondence of linguistic terms and linguistic value.
TOPSIS is one of widely used MCDM techniques as it is useful, convenient, and practical to estimate alternatives and rate them [28–30]. TOPSIS is according to the fact that the best alternative should be the farthest from the negative-ideal point and the shortest from the positive-ideal point. The distance is often Euclidean distances. However, it is difficult to give a precise performance rating for a decision maker. Fuzzy TOPSIS is used to solve the problem by introducing fuzzy number. Fuzzy TOPSIS has the following steps [29]:
Step 1: The suitable linguistic variables should be selected for the alternatives. They can be used to evaluate alternatives, so that the fuzzy performance matrix xijcan be established.
Step 2: Establish the decision matrix, which is the weighted normalized matrix. The value vij of the matrix can be computed by Equation (6).
Step 3: Finding out the negative-ideal point (A-) and positive-ideal point (A*).
The fuzzy negative-ideal point (FNIS, A-) and fuzzy positive-ideal point (FPIS, A*) are presented as follows:
Step 4: Compute the distance of each alternative from FNIS and FPIS, respectively.
The distance can be computed by Equation (4).
Step 5: Calculate the closeness coefficients by Equation (11).
Step 6: Rank order.
Rank alternatives based on
Now, how to solve relative weights w among criteria is the next issue that should be solved. Analytic Hierarchy Process (AHP) is a good approach and it is widely used in the decision problems.
4.3. AHP
AHP is a useful approach to solve MCDM in the different kinds of real applications. In the theory, multiple pair wise comparisons have to be established from
According to the above analysis, there are six performance indicators: HV, GD, IGD,

Six criteria.
Let
When the following conditions are met, the matrix E can achieve complete consistent:
According to the Equation (13), the following equations can be obtained:
Thus, when the judgment matrix E meets the Equation (15), it is a complete consistent matrix. In fact, it is very hard to meet the demand. The matrix E has to satisfy the satisfactory consistency in the real applications. The Equation (15) can be transformed into Equatiion (16):
Now, solving weights among performance indicators is converted to COP: the objective function is to minimize f and
The constraints
Where
Where k is from 1 to the number of criteria. The constraint violation (CV) can be presented as follows:
From above discussion, it can be observed that solving weight is a typical COP. How to solve the typical COP is very important. An adaptive DE (ADE) algorithm is presented to solve the COP.
4.4. Solving COP by the Proposed ADE Algorithm
DE is one of EAs [31]. Mutation strategy is very important during evolution. The main strategies of DE are given [32]:
DE/best/1:
DE/rand/1:
Three parameters
There are many mutation strategies. They have different performances. Among these strategies, DE/rand/1 was the first proposed [33]. It has been reported that the strategy is widely used and has achieved successful [34]. The strategy can keep diversity of population by random search. However, it may result in poor convergence [22]. The mutation strategy DE/best can accelerate convergence of algorithm with the help of the best information found so far during evolution process [18,19]. But, it may also have some problems. For example, diversity of population may become poor as the algorithm searches around the best information [20]. Algorithm may get into local optimum. It is very critical to deal with convergence and diversity during evolution. In order to realize the aim, DE/rand and DE/best are combined together to generate offspring shown in Table 2.
The generation method of offspring.
Where rand is uniformly generated between 0 and 1. Parameter ϕ is the feasible solution proportion. For COPs, there are little feasible solutions at the early stage. Therefore, ϕ is small at this stage. The condition rand < ϕ cannot be met frequently. Thus, the mutation strategy DE/rand/1 is used more frequently. At the later stage, feasible solutions are increased and kept. So, parameter ϕ will get bigger. The condition rand < ϕ will be met more frequently. DE/best will be used more frequently during evolution.
The crossover operation of the proposed algorithm is similar to the conventional DE.
The crossover operation is employed to
The crossover constant is
The comparison among two vectors
Now, the main steps of the ADE is revealed as follows:
Step 1 Parameters settings. Number of Population (NP); tolerance level ε; F; crossover rate (CR).
Step 2 Generate NP solutions
Step 3 Compute fitness value and CV of each solution, and feasible proportion ϕ of the current population.
Step 4 While stopping condition is not met
Step 4.1 if (ε <= 0.000001) ε = 0; end
Step 4.2 Generate vector
Step 4.3 Generate vector
Step 4.4 If vectors
Step 4.5 Compute the fitness value, total CVs of
Step 4.6 Selection
Compare Vector
Step 4.7 Update ε linearly
Step 5 End while
When the proposed algorithm is employed to acquire the weights of performance indicators, the fitness value is the result of Equation (16) and the CV is the result of Equation (20).
5. PROPOSED EVALUATION APPROACH
The approach for evaluating MOEAs, composed of ADE, box plot, and fuzzy TOPSIS approaches, has following four steps. It is depicted in Figure 8.

The proposed method.
Select alternative MOEAs and identify performance indicators
In this step, MOEAs and performance indicators are determined. The decision hierarchy is established. Indicators are in the first level and MOEAs are located in the second level. The performance indicators are HV, GD, IGD,
Determine weights
In this step, the weights of six performance indicators are determined. As weights among the six performance indicators are not equal, how to solve weights is very critical. AHP and proposed ADE algorithm are combined to solve weights.
Select benchmark functions and draw box plots
In this step, benchmark functions are needed. As we can get any useful conclusions based on a single run, 30 runs are generally required. The results of performance indicators are gotten. Box plots can be drawn based on the results of 30 runs.
Evaluate MOEAs and determinate the final rank
Ranking MOEAs is determined by fuzzy TOPSIS in the fourth step. Linguistic values are employed to evaluate box plots. Ranking MOEAs is achieved based on the value of
6. EXPERIMENTS
6.1. Solving Weights of Performance Indicators
In the above evaluation index system, HV, IGD and
The min f(w) is as follows:
The proposed algorithm ADE can be used to optimize the CIF. To validate the results, weights from ADE and AHP are listed in Table 3. It can be noticed that the results are very consistent with each other. The observations have demonstrated that ADE has the capability to solve weights.
| Method | w1 | w2 | w3 | w4 | w5 | w6 |
|---|---|---|---|---|---|---|
| ADE | 0.1874 | 0.1875 | 0.1875 | 0.1874 | 0.1875 | 0.0627 |
| AHP theory | 0.1875 | 0.1875 | 0.1875 | 0.1875 | 0.1875 | 0.0625 |
ADE, adaptive differential evolution.
The weights comparison.
In order to validate the consistency of the judgment matrix, the consistency is tested. By following the steps of AHP, CR is 0.0451, which is less than 0.1 [38]. Therefore, it can be concluded that evaluation matrix is consistent.
6.2. Evaluate MOEAs
The experiments are implemented to evaluate six MOEAs including NSGAII [3], GDE3 [8], MOEAD [4], SMSEMOA [36], eNSGAII [37], and eMOEA [5]. In order to make faithful comparisons, 14 test functions from CEC 2009 are used in MOPs and employed in the experiments. They can be divided into two groups: constrained (CF1~CF7) and unconstrained (UF1~UF7). The detail information of these test functions can be obtained from the reference [39].
The parameter settings of these algorithms are same to the original paper. It is recommended that each algorithm should be run independently 30 times for each test problem in CEC 2009 [39]. The values of performance indicators are obtained. The box plots of these values are presented.
In order to elaborate the whole calculation process, the CF1 results of six performance indicators are acquired and box plots are presented in Figure 9. Linguistic values are adopted to rank six MOEAs.

The box plots of six performance indicators, respectively.
Algorithms with larger HV, smaller GD, IGD,
| Algorithm | Hyper Volume | GD | IGD | Spacing | |
|---|---|---|---|---|---|
| NSGAII | VG | G | FG | FG | G |
| GDE3 | VP | FG | FP | VP | FG |
| MOEAD | FG | G | G | G | P |
| SMSEMOA | G | P | P | FP | P |
| eNSGAII | G | P | VP | P | P |
| eMOEA | G | VP | P | FP | FP |
FG, fairly good; FP, fairly poor; G, good; GD, generational distance; IGD, inverted generation distance; P, poor; VP, very poor.
The five performance indicators according to the box plots.
The linguistic evaluations are converted to triangular fuzzy number according to Table 1 and Figure 6. Every element belong to [0, 1] in Table 5. Therefore, there is no need to normalize them. Fuzzy positive-ideal point (FPIS, A*) and negative-ideal point (FNIS, A-) can be defined as following:
| Algorithm | Hyper Volume | GD | IGD | Spacing | |
|---|---|---|---|---|---|
| NSGAII | (0.8, 1, 1) | (0.6, 0.8, 1) | (0.4, 0.6, 0.8) | (0.4, 0.6, 0.8) | (0.6, 0.8, 1) |
| GD3 | (0, 0, 0.2) | (0.4, 0.6, 0.8) | (0.2, 0.4, 0.6) | (0, 0, 0.2) | (0.4, 0.6, 0.8) |
| MOEAD | (0.4, 0.6, 0.8) | (0.6, 0.8, 1) | (0.6, 0.8, 1) | (0.6, 0.8, 1) | (0, 0.2, 0.4) |
| SMSEMOA | (0.6, 0.8, 1) | (0, 0.2, 0.4) | (0, 0.2, 0.4) | (0.2, 0.4, 0.6) | (0, 0.2, 0.4) |
| eNSGAII | (0.6, 0.8, 1) | (0, 0.2, 0.4) | (0, 0, 0.2) | (0, 0.2, 0.4) | (0, 0.2, 0.4) |
| eMOEA | (0.6, 0.8, 1) | (0, 0, 0.2) | (0, 0.2, 0.4) | (0.2, 0.4, 0.6) | (0.2, 0.4, 0.6) |
GD, generational distance; IGD, inverted generation distance; MOEAs, multiobjective evolutionary algorithms.
The triangular fuzzy number of the six indicators for the six MOEAs.
The distance can be computed by Equations (9) and (10). For example,
| Algorithm | D* | D- | CC |
|---|---|---|---|
| NSGAII | 0.159 | 0.475 | 0.749 |
| GDE3 | 0.447 | 0.234 | 0.344 |
| MOEAD | 0.188 | 0.437 | 0.699 |
| SMSEMOA | 0.386 | 0.278 | 0.419 |
| eNSGAII | 0.442 | 0.270 | 0.379 |
| eMOEA | 0.432 | 0.270 | 0.384 |
MOEAs, multiobjective evolutionary algorithms; CC, closeness coefficients.
The D*, D-, and CC of the six MOEAs.
Similar procedures can be fulfilled for the other algorithms. The global performance of each algorithm is determined by CC. So, the ranking of six algorithms is: NSGAII > MOEAD > SMSEMOA > eMOEA > eNSGAII > GDE3. NSGAII is the best algorithm and GDE3 is the worst one for CF1.
Table 7 gives the complete rankings for all benchmark functions. For the 14 test functions, NSGAII wins in three problems: CF1, CF3, and UF6. NSGAII performs better for CF4, CF5, and UF3. GDE3 wins in five problems: CF4, CF5, CF7, UF1, and UF7. GDE3 provides better performance for CF2, CF6, UF2, and UF4. However, it achieves worse results for CF1 and UF5. MOEAD obtains better performance for CF1 and CF7. SMSEMOA gets the best performance for UF3 and better results for UF5. eNSGAII achieves the superior results for CF2, UF2, UF4, and UF5. It obtains better performance in four problems: CF3, UF1, UF6, and UF7. eMOEA ranks the first for CF6.
| NSGAII | GDE3 | MOEAD | SMSEMOA | eNSGAII | eMOEA | |
|---|---|---|---|---|---|---|
| CF1 | 1 | 6 | 2 | 4 | 5 | 3 |
| CF2 | 4 | 2 | 3 | 6 | 1 | 5 |
| CF3 | 1 | 4 | 3 | 6 | 2 | 5 |
| CF4 | 2 | 1 | 3 | 4 | 6 | 5 |
| CF5 | 2 | 1 | 3 | 4 | 6 | 5 |
| CF6 | 3 | 2 | 6 | 4 | 5 | 1 |
| CF7 | 5 | 1 | 2 | 3 | 6 | 4 |
| UF1 | 4 | 1 | 5 | 6 | 2 | 3 |
| UF2 | 5 | 2 | 6 | 4 | 1 | 3 |
| UF3 | 2 | 4 | 5 | 1 | 3 | 6 |
| UF4 | 5 | 2 | 6 | 4 | 1 | 3 |
| UF5 | 3 | 6 | 4 | 2 | 1 | 5 |
| UF6 | 1 | 3 | 6 | 5 | 2 | 4 |
| UF7 | 3 | 1 | 6 | 4 | 2 | 5 |
MOEAs, multiobjective evolutionary algorithms.
The bold values are ranked the first, which indicates that the corresponding algorithm has the best performance.
The final ranking for the six MOEAs.
6.3. The Effectiveness of the Proposed Method
In order to make more comparisons among six MOEAs, the Pareto front and nondominated set of six MOEAs are presented in Figure 10. NSGAII can achieve many nondominated solutions. These solutions are evenly distributed along the Pareto front, while eNSGAII and GDE3 obtain nondominated solutions, in which both convergence and diversity are poor.

The Pareto front and the nondominated solutions of six multiobjective evolutionary algorithms (MOEAs).
In order to prove the advantage of the evaluation method, the set coverage is used. The set coverage can be utilized to compare the difference between two algorithms [4]. There are two nondominated solutions A and B. C(A, B) is denoted as following:
Where
| NSGAII | GDE3 | MOEAD | SMSEMOA | eNSGAII | eMOEA | |
|---|---|---|---|---|---|---|
| NSGAII | 96.3% | 56.5% | 79.4% | 60% | 73.5% | |
| GDE3 | 21.4% | 5.6% | 4.8% | 22.2% | 36.7% | |
| MOEAD | 55.7% | 92.6% | 81% | 68.9% | 71.4% | |
| SMSEMOA | 60% | 96.3% | 27.8% | 68.9% | 69.8% | |
| eNSGAII | 52.9% | 96.3% | 38.9% | 50.8% | 55.1% | |
| eMOEA | 52.9% | 85.2% | 36.1% | 67.3% | 60% |
The set coverage of pair wise comparisons among the six algorithms.
However, the set coverage has to make pair wise comparisons. If the number of algorithms is
7. CONCLUSIONS
Many MOEAs are available and the experiment results often get the conclusion that these MOEAs are the best based on few performance indicators. These comparisons are unfair. In order to solve the problem, an approach is proposed to evaluate MOEAs. The approach uses box plots and fuzzy TOPSIS. Six performance indicators HV, GD, IGD,
The experiments have been conducted based on CEC 2009. The results from CEC 2009 have implied that the proposed evaluation method is fair and accurate. The observation of experimental results demonstrates that the capability of MOEAs to solve MOPs counts on both MOEAs and the features of MOPs.
In the following research, we will adopt Pythagorean fuzzy sets (PFSs) to evaluate MOEAs, which was proposed by Yager [40]. The approach can deal with uncertain situation.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
AUTHORS' CONTRIBUTIONS
Xiaobing Yu conceived the research, edited, and revised the manuscript. Chenliang Li and Hong Chen drafted the manuscript and designed the experiments; Xianrui Yu performed the experiments and analyzed the data.
Funding Statement
This study was funded by Major Project of Philosophy and Social Science Research in Colleges and Universities in Jiangsu Province (2019SJZDA039), China Natural Science Foundation (71503134), Qinglan project in Jiangsu province, Key Project of National Social and Scientific Fund Program (16ZDA047).
ACKNOWLEDGMENT
This study was funded by China Natural Science Foundation (grant number. 71503134, 71871121), Qinglan project in Jiangsu province, Key Project of National Social and Scientific Fund Program (16ZDA047), Top-notch Academic Programs Project of Jiangsu Higher Education Institutions (TAPP).
REFERENCES
Cite this article
TY - JOUR AU - Xiaobing Yu AU - Chenliang Li AU - Hong Chen AU - Xianrui Yu PY - 2019 DA - 2019/07/26 TI - Evaluate the Effectiveness of Multiobjective Evolutionary Algorithms by Box Plots and Fuzzy TOPSIS JO - International Journal of Computational Intelligence Systems SP - 733 EP - 743 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.190629.001 DO - 10.2991/ijcis.d.190629.001 ID - Yu2019 ER -