
Bayesian Analysis of Inverse Gaussian Stochastic Conditional Duration Model
- DOI
- 10.2991/jsta.d.191031.001How to use a DOI?
- Keywords
- Stochastic conditional duration; Bayesian analysis; Markov Chain Monte Carlo; Inverse Gaussian distribution; Slice sampler
- Abstract
This paper discusses Bayesian analysis of stochastic conditional duration model when the innovations follow inverse Gaussian distribution. Estimation is carried out by the methods of Markov Chain Monte Carlo. Applications of the model and methods are illustrated through simulation and data analysis.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
The empirical analysis of durations between the occurrences of certain financial events is important in understanding the market behavior. To describe the evolution of such durations, Bauwens and Veredas [1] proposed a class of models called the stochastic conditional duration (SCD) models. One can refer Engle and Russell [2], Pacurar [3] for details on such duration models. The SCD model assumes that the conditional mean of durations between events is generated by a latent stochastic process. The likelihood based inference for such models requires evaluation of multiple integral with respect to latent variables. In view of these difficulties Bauwens and Veredas [1] estimated the parameters by quasi-maximum likelihood (ML) by expressing the model into a linear state space form and then applying Kalman filter method. Feng, Jiang and Song [4] proposed an extension to Bauwens and Veredas's [1] SCD model in order to capture the asymmetric behavior or leverage effect in the duration process. They adopted the Markov Chain Maximum Likelihood (MCML) approach proposed by Durbin and Koopman [5]. Strickland, Forbes and Martin [6] proposed a Bayesian Markov Chain Monte Carlo (MCMC) method in which the sampling scheme employed is a hybrid of the Gibbs and Metropolis-Hastings (MH) algorithm, with the latent vector sampled in blocks. Knight and Ning [7] discussed the empirical characteristic function (ECF) and the generalized method of moments estimation. Bauwens and Galli [8] developed a ML estimation based on the efficient importance sampling (EIS) method to estimate the parameters. Xu, Knight and Wirjanto [9] extended the SCD model of Bauwens and Veredas [1] by imposing mixtures of bivariate normal distributions on the innovations of the observation and latent equations of the duration process. Men, Kolkiewicz and Wirjanto [10] introduced a correlation between the error process and the innovations of the duration process and adopted Monte Carlo methods for estimation. Ramanathan, Mishra and Abraham [11] introduced a new procedure for estimation, filtering and smoothing in SCD models, based on estimating functions. Majority of the literature on SCD models assume that the errors follow either a Weibull, Gamma or exponential distribution. Balakrishna and Rahul [12] proposed a SCD model having inverse Gaussian (IG) distribution for innovations. In the present paper, we consider the Bayesian analysis of SCD model with IG error random variables. We propose Bayesian MCMC methods to estimate the parameters of the model. Here we follow the algorithm mentioned in Men, Kolkiewicz and Wirjanto [13], Edwards and Sokal [14] and Neal [15]. Since it is difficult to obtain the analytical conditional densities of observed data, the auxiliary particle filter (APF) in Pitt and Shephard [16] is employed to evaluate the likelihood function.
A brief review of IG SCD model is given in Section 2. The Bayesian estimation methodology and MCMC algorithm are discussed in Section 3. Simulation studies are carried out in Section 4. Section 5 presents the application of proposed method to real life data sets.
2. THE SCD MODEL
Let
The SCD model is defined by
A random variable
If we restrict
In order to develop an estimation procedure for the model let
3. BAYESIAN ESTIMATION
We consider the problem of estimation for the SCD model when the innovations of the durations follow an IG distribution in a Bayesian framework. By Bayes theorem, the joint conditional distribution of
To construct an appropriate Markov Chain sampler, the joint posterior should be expressed as proportional to various conditional distributions. So in Eq. (5), the joint posterior,
While developing MCMC algorithm, the latent variables are augmented with the vector of parameters and then the estimation is carried out. We start drawing samples from the conditional posterior distribution of the latent variable
The parameters
Step 1. Sample
For
Substituting for the corresponding normal densities and on simplifying the square terms we get
Hence the conditional posterior distribution of
The posterior distribution in (8) is proportional to a product of three positive functions and data cannot be simulated directly from them. So we propose a method of slice sampler whose algorithm is given below.
Slice sampler algorithm for
To start the slice sampling procedure, the sampled value of
Initialize
Draw a random observation
Similarly draw a random observation
Draw
Stop, if a stopping criterion is met; otherwise, set
Step 2. Sample
Step 3. Sample
Step 4. Sample
The following is a summary of the procedure used to sample
Sample
Sample
Sample
Sample
In the next section we demonstrate the applications of the above methods through a simulation study.
4. SIMULATION STUDY
A simulation study is carried out to assess the performance of the Bayes estimators, described in the previous section. We generate 5000 observations from the model (1). Then the MCMC algorithm discussed in Section 3 is run and first 25000 iterations were discarded as burn-in from 100000 iterations. The parameters are estimated and the simulation results are tabulated in Table 1. The plots of histograms of posterior samples of
| True. | 0.75 | 1.5 | 1 |
| Est. | 0.763302 | 1.529561 | 0.999191 |
| mse. | 0.000039 | 0.000094 | 0.0000039 |
| HPD CI(95%) | (0.74633, 0.78840) | (1.47808, 1.57561) | (0.9557, 1.1477) |
| True. | 0.85 | 1.5 | 1 |
| Est. | 0.84699 | 1.55057 | 0.999242 |
| mse. | 0.0000322 | 0.000095 | 0.0000041 |
| HPD CI(95%) | (0.82633, 0.86840) | (1.49808, 1.58561) | (0.9657, 1.1413) |
| Highest probability density | Confidence interval (HPD CI) | ||
True and estimated parameters of the IG-SCD model.
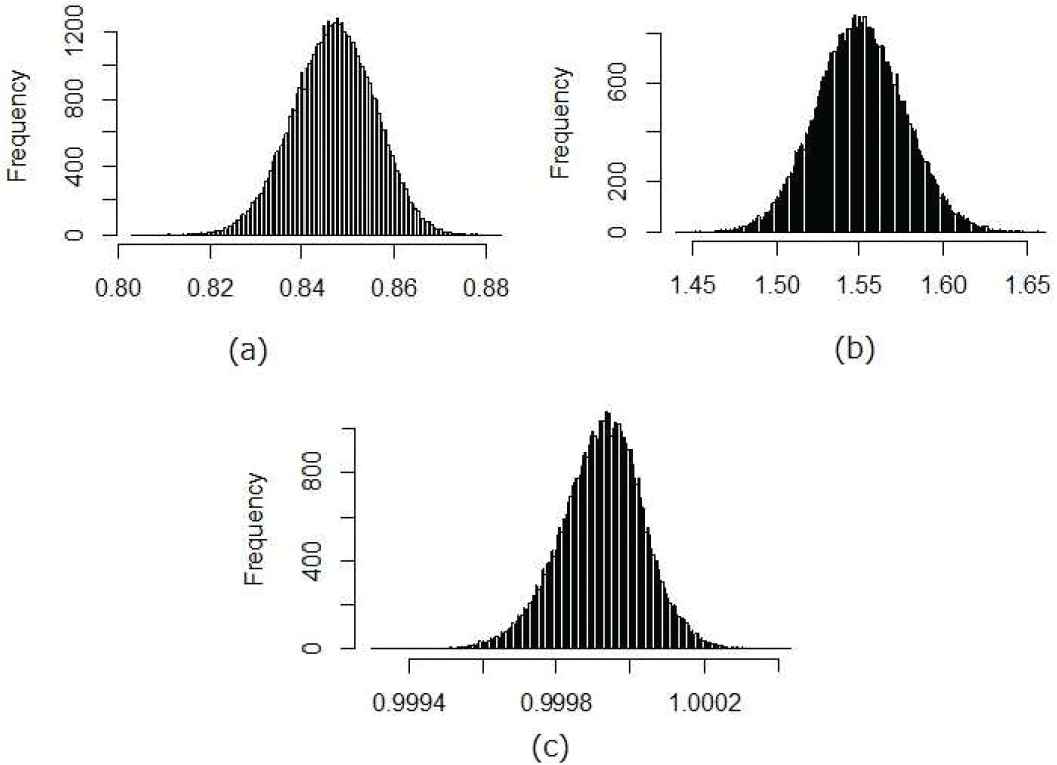
Histogram of the posterior samples using simulated data.
Trace plots of the posterior samples using simulated data.
To illustrate the application of Bayesian estimation method we analyze two sets of data. We perform model diagnosis based on the residuals to explain model adequacy. The residuals of SCD model with IG innovations are defined as
4.1. Particle Filter
Particle filters are a class of simulation-based filters that recursively approximate the filtering distribution using a collection of particles with some probability masses. The particles are samples of unknown states from the state space, and the particle weights are probability mass computed by Bayes theory. The basic idea is the recursive computation of relevant probability distribution and approximation of probability distribution.
By successive conditional decomposition, the likelihood of the IG-SCD model is
The difficulty in obtaining an analytical form of the above integral leads to the utilization of APF. Suppose that we have a particle sample {
The one step ahead prediction distribution of
Given the particle sample from a filtered distribution
4.1.1. Algorithm for APF
(a) Given a sample {
and sample N times with replacement the integers 1,2,…,N with probabilityFor each value of
whereCalculate the weights of the values
and using these weights resample the values
5. DATA ANALYSIS
We demonstrate the applications of the model, by analysing two sets of data. Data sets are on intraday trades of IBM OHLC bar data downloaded from Algoseek Website and intraday trades of US Brent Crude Oil downloaded from the Website of a Swiss Forex bank. Only trades between 9:30:00 am and 4:00:00 pm are recorded as this is the normal trading hour.
5.1. IBM Trades Data
The model is applied to intraday IBM trades data as on
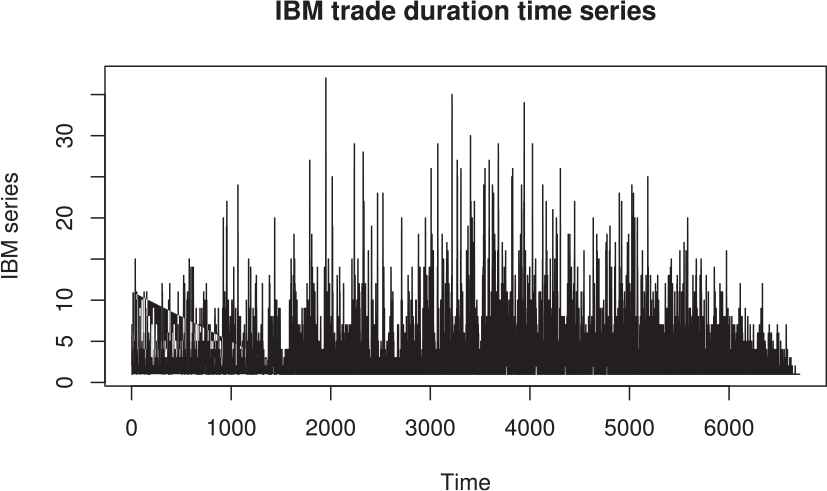
IBM trade duration time series.
| Statistic | IBM Trades Data |
|---|---|
| Sample size | 6708 |
| Minimum | 1 |
| Maximum | 37 |
| Mean | 3.48 |
| Median | 2 |
Descriptive statistics for IBM trades data.
The estimation of the parameters is carried out by the MCMC algorithm described in Section 3 and the estimates are provided in Table 3. For model diagnosis we compute residuals,
| Est. | 0.69803 | 1.2366 | 1.1566 |
| Std error | 0.00143 | 0.00906 | 0.00658 |
Estimated parameters of the IG-SCD model based on IBM Trades duration data.
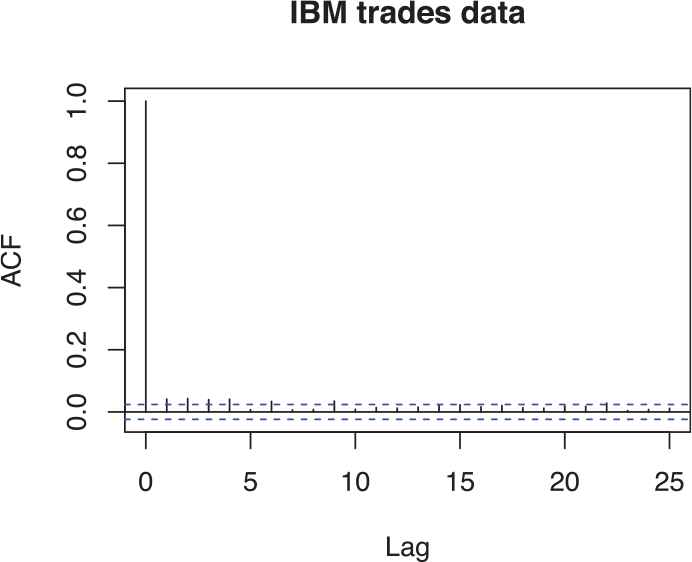
ACF plot of residuals.
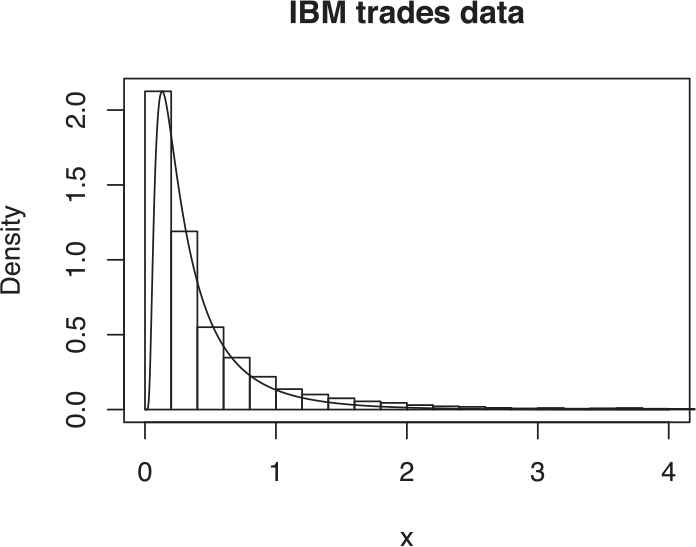
Histogram of residuals superimposed by inverse Gaussian density for IG-SCD model.
5.2. US Brent Crude Oil
The second set of data is the intraday trades data of US Brent Crude Oil downloaded from the Website of a Swiss Forex bank and Marketplace. The intraday trade of the Brent Crude Oil on 20 February 2017 is considered. Taking the normal trading hours and ignoring the zero durations the sample size obtained is 1625 trade durations. The time plot of the nonzero intraday durations and the time plot of the adjusted duration series is shown in Figures 6 and 7. The summary of data is given in Table 4.
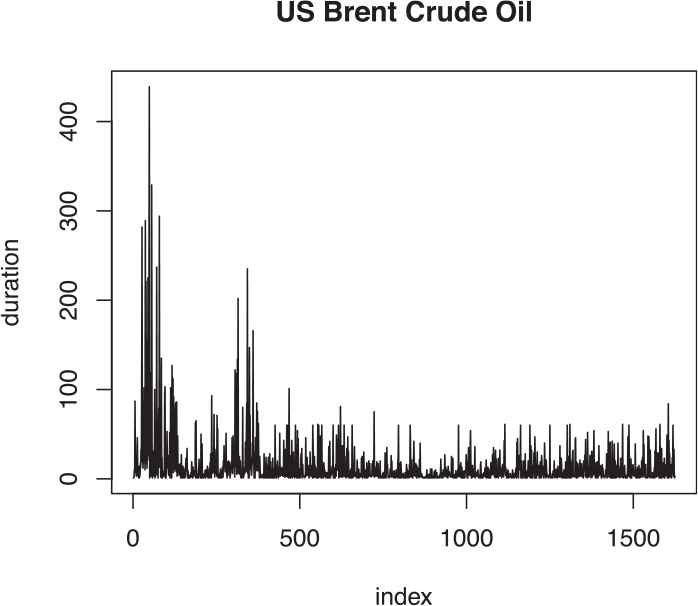
Duration plot of US brent crude oil.
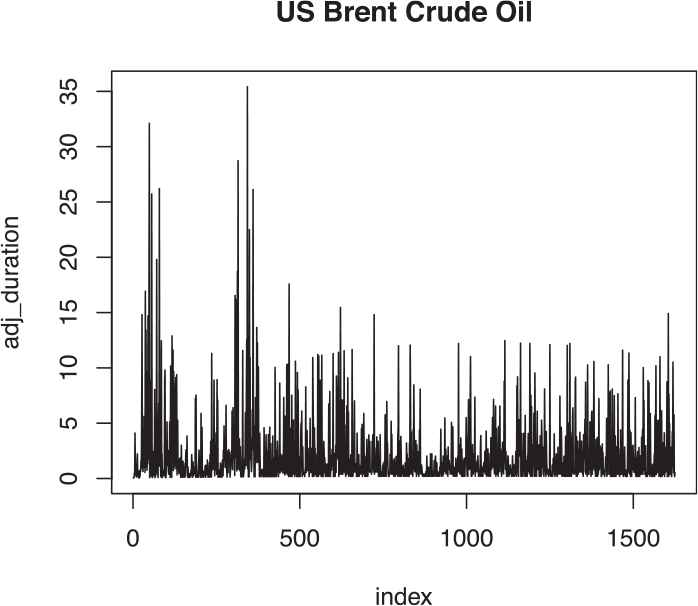
Adjusted duration plot of US brent crude oil.
| Statistic | IBM Trades Data |
|---|---|
| Sample size | 1625 |
| Minimum | 1 |
| Maximum | 439 |
| Mean | 14.4 |
| Median | 6 |
Descriptive statistics for US Brent Crude Oil Trades data.
The parameters are estimated by the algorithm mentioned in Section 3 and are tabulated in Table 5. From the residual plot given in Figure 8 and the p-value (= 0.8) obtained from rank portmanteau statistic we conclude that the residuals are independent. The superimposition of the histogram of the residuals and the IG density curve in Figure 9, shows a good fit of error distribution.
| Est. | 0.77263 | 1.34885 | 0.945069 |
| std error. | 0.00567 | 0.00975 | 0.01018 |
Estimated parameters of the IG-SCD model based on US Brent Crude Oil trades duration data.
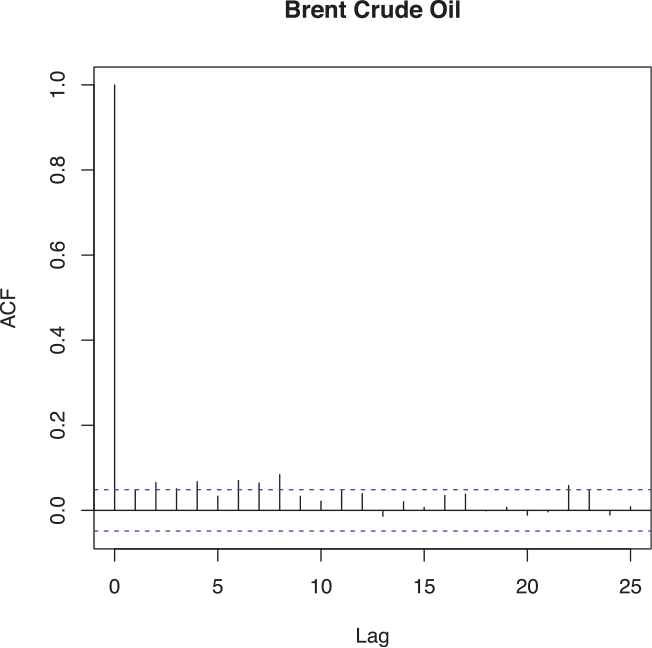
Residual plot of US brent crude oil.
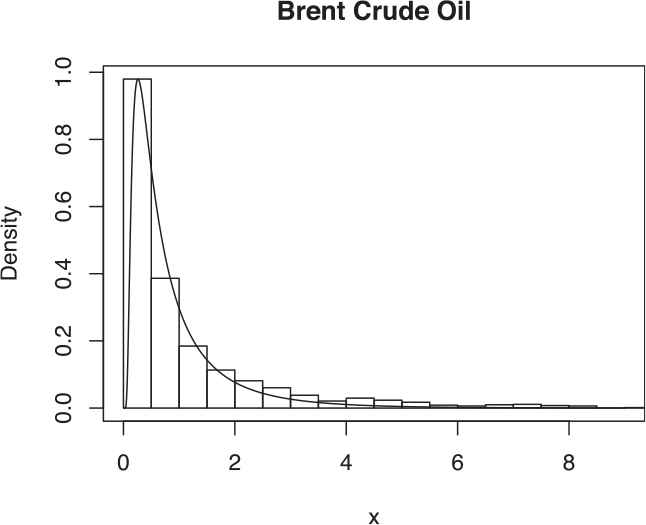
Histogram of residuals superimposed by inverse Gaussian density for inverse Gaussian-stochastic conditional duration (IG-SCD) model.
6. CONCLUSION
In this article we considered the Bayesian estimation of SCD model with IG error random variables. The slice sampling within an MCMC estimation methodology and the APF method are utilized to estimate the parameters and the latent states of the model. Simulation study shows that the proposed estimation method is reliable. Two sets of financial data are considered to demonstrate the utility of the model. The non-parametric tests applied to residuals support the assumptions on the errors. However, more rigorous statistical tests are to be developed to perform model diagnosis in the presence of latent variables.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
ACKNOWLEDGMENTS
The authors thank the editor and the reviewers for their careful reading of the article. Sri Ranganath acknowledge Kerala State Council for Science Technology & Environment, for the financial assistance for carrying out this research work. The research of N. Balakrishna is partially supported by the DST SERB under the project No. SR/S4/MS:837/13.
APPENDIX A
The conditional distribution of parameter
The conditional distribution of parameter
The conditional distribution of parameter
REFERENCES
Cite this article
TY - JOUR AU - C.G. Sri Ranganath AU - N. Balakrishna PY - 2019 DA - 2019/11/20 TI - Bayesian Analysis of Inverse Gaussian Stochastic Conditional Duration Model JO - Journal of Statistical Theory and Applications SP - 375 EP - 386 VL - 18 IS - 4 SN - 2214-1766 UR - https://doi.org/10.2991/jsta.d.191031.001 DO - 10.2991/jsta.d.191031.001 ID - SriRanganath2019 ER -