
The Performance Evaluation of Continuous Speech Recognition Based on Korean Phonological Rules of Cloud-Based Speech Recognition Open API
- DOI
- 10.2991/ijndc.k.201218.005How to use a DOI?
- Keywords
- Speech recognition; pronunciation dictionary; Korean phonological rules; cloud computing; Open API
- Abstract
This study compared and analyzed the speech recognition performance of Korean phonological rules for cloud-based Open APIs, and analyzed the speech recognition characteristics of Korean phonological rules. As a result of the experiment, Kakao and MS showed good performance in speech recognition. By phonological rule, Kakao showed good performance in all areas except for nasalization and Flat stop sound formation in final syllable. The performance of speech recognition of Korean phonological rules was good for /l/nasalization and /h/deletion. The speech recognition performance of phonological rule words accounted for a very high percentage of the whole words speech recognition performance, and the speech recognition performance of phonological rule was more different among companies than between speakers. This study hopes to contribute to the improvement of speech recognition system performance of cloud companies for Korean phonological rules and is expected to help speech recognition developers select Open API for application speech recognition system development.
- Copyright
- © 2021 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Speech recognition systems have significantly improved performance with cloud computing technology [1] and application of artificial intelligence [2]. The cloud-based speech recognition engine addresses the difficulties of developing speech recognition systems. By collecting large amount of speech data for development of speech recognition system, high performance computer for learning large volume speech data is not needed. Cloud-based speech recognition Open API has saved a lot of time, effort, and money to develop an applied speech recognition system. The improved performance and ease of development of speech recognition systems are being applied in a variety of areas. Speech recognition systems are largely divided into pre-processing and recognition units [3]. The recognition unit makes a word for the extracted speech information of the speech. The process of creating words either uses pronouncing dictionaries according to the characteristics of the speech recognition system [4–6], using information through deep learning of vocal information without pronouncing dictionaries [7,8]. The speech recognition system should accurately recognize phonological changes regardless of whether a pronouncing dictionary exists. In the speech recognition process, meaningful sentences should be made in terms of syllables by finding the exact morphemes. Therefore, assessing the recognition rate of speech recognition systems for phonological rules will help to understand the characteristics of speech recognition systems. This study aims to explore the characteristics of cloud-based speech recognition system’s application of phonological rules and to present the criteria for selecting a high-performance cloud-based Open API for developing an applied speech recognition system. This study conducted a study on continuous speech recognition performance evaluation in accordance with the Korean phonological rules of the cloud-based speech recognition Open API. The composition of the paper described the related research on Korean phonological rules and cloud-based speech recognition Open API in Chapter 2, and Chapter 3 described experiment methods and test results as experiments. Chapter 4 summarizes the evaluation and meaning of experimental results and describes future research tasks.
2. BACKGROUND
2.1. Speech Recognition Overview
Speech recognition is a technique that converts a person’s pronunciation into meaningful characters. The Korean Telecommunications Technology Association (TTA)’s Information and Communication terms Dictionary describes speech recognition as “automatically identifying linguistic meaning contents from speech, and more specifically, it is a processing process that identifies words or series of words and extracts meanings by entering speech waveforms.” The processing of speech recognition systems is divided into pre-processing and recognition units, as in Figure 1 [3]. In preprocessing, the input speech information is extracted, and in the recognition section, the speech information extracted from preprocessing is converted into words and the sentence is made. The creation of sentences uses pronouncing dictionaries and vocabulary dictionaries made in large TEXT coppers.

Process of speech recognition system.
Factors affecting the performance of speech recognition system include noise elimination method, method of extracting speech characteristics, method of generating sound model, method of generating pronouncing dictionary, method of creating language model, and method of decoding network method. Pronouncing dictionary is a crucial factor in making speech information of speech recognition system a meaningful word. The pronouncing dictionary gives vocal information according to the heading. This vocalization information reflects phonetic rules to create a pronouncing dictionary. In particular, the difficulty of Korean speech recognition is to make a dictionary of pronunciation because there are so many rules that apply to the Korean pronunciation method in the generation of pronunciation.
2.2. Korean Phonological Rule
Phonological rules mean changing the predetermined pronunciation of the morpheme due to changes in phoneme and phenomena of change. The phonological process can be divided into official phonological processes and general phonological changes. The phonological process is divided into five parts [9] from the point of view of the syllabus: replacement, elimination, inclusion, condensation, and metathesis. Moreover, it is divided into essential phonological rules and veterinary rules, depending on the environment. Essential phonological rules are rules that must be applied in all conditioned environments, and optionally rules are rules that are both good and need not be applied in the same phoneme environment. Table 1 shows the classification and division of public phoneme rules by phoneme process. Table 2 describes essential phonological rules and examples of related words in the synchronic phonological process, and Table 3 describes optionally phonological rules and examples of related words in the synchronic phonological process [9].
| Synchronic phonological process | Formative phonological process | Formative phonological process of consonants | Replacement | Flat stop sound formation in final syllable, Nasalization, Liquidization, Place assimilation, Fortition |
| Deletion | Simplification of Consonant cluster, /h/deletion, Geminate consonants Reduction, /t/deletion, /l/deletion, Nasal deletion | |||
| Insertion | Gemination, /n/insertion, Homophony insertion | |||
| Contraction | Aspiration, Fortition | |||
| Formal phonological process for vowels and semi-vowels | Replacement | Vowel harmony, Umlaut, /j/semi-vowelization /w/semi-vowelization, Complete assimilation of vowel, front-vowelization, Vowel rounding | ||
| Deletion | /ɯ/deletion, Same vowel elision, /j/deletion, /w/deletion | |||
| Insertion | /j/insertion | |||
| Contraction | Vowel coalescence | |||
| Joint process | Formative phonological process of consonants | Replacement | Implosive formation, Voicing (voicing assimiliation), Lateralization, Palatalization | |
| Formal phonological process for vowels and semi-vowels | Replacement | w-fronting (w front-vowelization) | ||
| Deletion | /j/deletion |
Classification and types of synchronic phonological rules
| Phonological rules | Explanation | Example: Pronunciation variation (Before → After), Symbol (IPA) |
|---|---|---|
| Flat stop sound formation in final syllable | A phenomenon in which the obstruent changes from the final consonant to one of the final syllable neutralization /p, t, k/. | jʌpʰ → jʌp, sotʰ → sot |
| Nasalization | Final syllable neutralization /p, t, k/ assimilate into nasal /m, n, ŋ/ respectively in front of nasal sound. | pabman → pamman, padnɯn → pannɯn |
| Liquidization | /n/ encounters /l/ and turns into /l/. | mulnoli → mullori, ɕilnɛ → ɕillɛ |
| Fortition | A phonological phenomenon in which a plain consonant among obstruent is changed to a fortis in a certain environment. | tsabgo, → tsapkʼo, midgo → mitkʼo |
| Simplification of consonant cluster | In the case of a group of consonants consisting of two consonants, one of the two consonants is dropped out of the final consonant. | nʌgtsto, → nʌktʼo, ʌntsnɯn) → ʌnnɯn |
| /h/deletion | The predicate final consonant /h/ is a dropout phenomenon in front of a vowel. | nahɯn → naɯn, anha → aˈna |
| /t/deletion | /t/ is dropped in front of /sʼ/. | tsʌdzso → tsʌsʼo, os sanda → osʼanda |
| /l/deletion | The predicate final consonant /l/ are dropped in front ofthe first consonant /n/, thefinal consonant /n, l, m, p/, the pre-final ending ‘-ɯsi-, -ɯo-', the sentence-closingending ‘ -ɯo, -ɯma'. | mandɯl-m nida → mandɯmnida |
| Aspiration | A phenomenon in which the final syllable neutralization and the flat spirant become aspiration sounds when they meet /h/. | nohda → notʰa, anhgo → (ankʰo |
| Complete assimilation of vowel | In Gyeongsang dialect, the mediated vowel /ʌ/ is completely assimilated to the frontvowel. | tah-ʌmo → taːmo |
| /ɯ/deletion | /ɯ/ is dropped out under various conditions. | sʼɯ-ʌ → sʼʌ, hʰɯ-ʌ → tʰʌ |
| Same vowel elision | When vowel endings are connected after /a, ʌ/ terms, endings /a, ʌ/ are dropped out. | ka-ʌ → kaː, sʌ-ʌ → səː |
| /j/deletion | [j] is eliminated after the palatal sound [ɲ, ʃ, ʃʼ, ʎ]. | tʌndzi-ʌ → tʌndzʌ, igi-e → iˈkeː |
| /w/deletion | In some dialects, when the conjugated form is connected with a bilabial sound, a tongue front sound and a double vowel /wa, w/ is eliminated. | po-a → pwa → paː |
| Lateralization | [r] is the lateralization of [l] at the final consonant or after [l]. | oɾɯnparro → oɾɯnballo, tarrara → tallaɾa |
| Palatalization | A phenomenon in which dental sound [n], alveolar sound [s, sʼ, l] change to palatal sound [ɲ, ʃ, ʃʼ, ʎ] in a front sound [i, j, ɥ], respectively. | kasʼni/kanni, jʌnlʎo/jʌlʎo |
Explanation and examples of essential phonological rules
| Phonological rules | Explanation | Example: Pronunciation variation (Before → After), Symbol (IPA) |
|---|---|---|
| Place assimilation | A Phenomenon that /t, n/ is changed to /p, m/ in front of bilabial, /k, ŋ/ in front of dorsal (back). And /p, m/ is changed to /k, ŋ/ in front of dorsal (back). | mitʰpʰan → mibpʰan, tsipʰko → tsikʼo |
| Geminate consonants Reduction | In front of fortis and aspirate of stop and fricative sound, a flat (lax) sound /p, t, k/ is optionally deleted at same place | pabpʰul → papʰul, tɯdtsa → tɯtsʼa |
| Gemination | In front of fortis and aspirate of stop and fricative sound, a flat (lax) sound /p, t, k/ is optionally inserted at same place | apʼa → appʼa, apʰasə → appʰasə |
| /n/insertion | A phenomenon that occurs optionally when the preceding word ends with a consonant and the word behind it starts with /i, j/ when a compound or derivative word is created | pamil → pamɲil, polil → polɲil |
| Umlaut | The back vowel /a, ʌ, o, u/ is changed to front vowel /ɛ, e, ø, y/ due to the influenceof the following front vowel 'i' or glide 'j' | pab-i → pɛˈbi, tʼəg-i → tʼegi |
| /j/semi-vowelization | When ending of vowel is connected behind predicate /i/, auslaut of predecate /i/ is optionally changed to semi-vowel /j/ | pʰ-ə → pʰjʌ |
| /w/semi-vowelization | When ending of vowel is connected behind predicate /o, u/, auslaut of predicate /o, u/ is optionally changed to semi-vowel /w/ | po-a → pwa |
| Front-vowelization | Onset of postposition or ending /ɯ/ is changed to /i/ behind sibilant /s, sʼ, ts, tsʼ, tsʰ/ | os-əno → osino |
| /j/insertion | /j/ is inserted optionally when ending onset /ʌ/ is connected to predicate /i, e, ɛ, wi, ø/. | pʰi-ə → pʰjʌ |
Explanation and examples of optionally phonological rules
2.3. Prior Study on the Korean Pronunciation
Factors affecting the degradation of speech recognition rate in speech recognition systems include noise, completed pauses, repeat/repeat speech, pronunciation variation, stammering, and vocabulary diagram. Among these factors that reduce speech recognition is due to non-grammatical vocalization, except for noise factors. Many studies have been conducted on how to match spelling and pronunciation to reduce the error rate of speech recognition by non-grammatical speech. These methods include creating and using Grapheme to Phoneme (G2P) and learning pronunciation. The process of making a pronouncing dictionary is complex and has many maintenance limitations, so studies are being conducted on end-to-end speech recognition that does not require a pronouncing dictionary [10]. The existing pronouncing dictionary is a standard pronouncing dictionary based on linguistic standards, and the phonetic column is hand-written. However, this required professional knowledge of Korean phonological changes and required a lot of time and effort in writing. To solve these problems, we created a phonetic dictionary based on the Korean phonological rules [11]. This method performed particularly well in multi-pronunciation dictionaries. However, there is a problem with multiple pronunciations, which increases the size of the dictionary, increases the ambiguity of the perceived object at the recognition stage, and increases the congestion [12]. Thus, phonetic was extracted from two corpus of syllable unit and morpheme unit in consideration of phonological variation [4], and a pronouncing dictionary was created by establishing a new unit corpus in which morphological phonological variation was considered [5]. The size of the pronouncing dictionary decreased a lot and the error rate of the word also decreased. There was also a study without a pronouncing dictionary. Although the G2P process that requires changes in phoneme and exception processing of Hangeul is necessary [13], there is a study that breaks down the method of recognizing through deep learning without the G2P process [7] and uses it as an output unit of sound model [8] by breaking it down into letters in initial, neutral, and ending. The method of using lettering showed better performance than pronouncing dictionaries. A new set of phonetic phonemes was created by clustering the ignited voices into a common spectral pattern to increase the discriminative power [6]. Pronouncing dictionaries using common spectral patterns had an effect of reducing the relative word error rate of 8.9% in the phonetic speech than phonetic pronouncing dictionaries, and free speech data by about 7.0%. This study will be meaningful in evaluating the pronunciation treatment of the cloud company speech recognition system through the performance evaluation of Korean phonological rules for the cloud company speech recognition system.
2.4. Cloud Speech Recognition Open Application Programming Interface
Cloud-based speech recognition Open Application Programming Interface (API) is an application service in cloud computing environment. Cloud computing is a service that remotely orders and pays for computer resources (such as software, hardware, storage, etc.) and uses them [1,14]. Cloud computing has characteristics such as multitenancy, on-demand usage, usage measurement, elasticity, resilience, and ubiquitous access. The advantages of cloud computing are, first, low investment and lower maintenance costs. Second, the scalability of computer resources is good. Third, the service configuration is short. Fourth, availability and reliability are high. Fifth, rapid decision-making by the organization of the system configuration is reflected. The downside is, first, that it is vulnerable to security. The stability of data should be delegated to external companies. Second, it is difficult to transfer data when changing service provider. Third, data may be required to be disclosed in accordance with local regulations and regulations of the service provider [1,14]. Cloud-based speech recognition Open API is an API that enables speech recognition developers to develop speech recognition systems using the characteristics of cloud computing. The difficulty of developing a speech recognition system should be based on high-performance computers that can collect large-capacity speech data and learn large-scale speech data. However, cloud-based speech recognition Open API addresses the difficulties of developing speech recognition systems. The cloud-based Open API allows application speech recognition developers to implement desired application speech recognition systems quickly and easily. Companies providing cloud-based speech recognition Open API are represented by domestic Kakao Speech-to-Text system [15], SKT NUGU [16], Naver Clova Speech Recognition [17], GiGA Genie Speech Recognition [18], ETRI STT [19], and others, while foreign companies are Microsoft Azure Cognitive Speech Service [20], Amazon Transcribe [21], IBM Watson Speech to Text [22], and Google Cloud Speech-to-Text [23].
2.5. Prior Study on Cloud Speech Recognition Open API
Cloud-based speech recognition Open API supports development of application speech recognition system quickly and easily. Due to the convenience of development using cloud-based speech recognition Open API, applied speech recognition system is being established in various fields. Application speech recognition developers should choose the speech recognition Open API appropriate for their application speech recognition system, depending on the function and performance they want in developing the application speech recognition system. There are many cases of cloud speech recognition Open API performance evaluation studies to provide criteria for this choice. Cloud-based speech recognition Open API shows performance differences depending on the timing of research and the nature of learning data. The March 2017 study found that Google API was the best [24]. In August 2017, a study conducted experiments on numbers, Hangul, and sentences. The numbers were Kakao, and Naver performed well in Hangeul and sentences [25]. The October 2017 study conducted an experiment on sentences, and the main factors in sentences in which recognition errors occurred were words in Portuguese and English, acronyms, names and certain corporate terms. The Google Cloud Speech API had the highest accuracy. However, the speed was found to be the slowest [26]. In the December 2017 study, the Korean people’s standard language and dialect were studied according to gender, age, and region. The accuracy of the sentences was measured based on spacing, props, surveys, and words according to the resulting sentences. Overall accuracy was good for Google, dialect was good for the Chungcheong and Jeolla dialects, and in the Gyeongsang dialects, sentences with large differences in intonation and pitch and unfamiliar Gyeongsang dialect words were not well recognized [27]. In the December 2018 study, Google showed moderate performance, unlike previous studies [28]. In the 2019 study, Korean and English sentences were recorded at a distance of 1, 3 and 5 m [29]. ETRI Open API in Korean, ETRI Open API in 1 m, Naver in 3 m, Naver Clova in 5 m, Microsoft Azure Speech Service in English, Microsoft Azure Speech Service in 1 m, Amazon Transcribe in 3 m, and ETRI Open API in 5 m showed high recognition rates [29]. According to prior research from 2017 to 2019, Google showed good performance in the beginning, but Microsoft Azure Speech Service and ETRI Open API showed good performance in the second half. In the preceding study, there is no case of speech recognition research on changes in Korean phonemes and changes. It would be a meaningful study to evaluate phonetic recognition of phonetic fever in identifying the characteristics of cloud-based speech recognition Open API.
3. EXPERIMENT
3.1. Experimental Method
The experiment tested the speech recognition performance of the cloud-based speech recognition Open API for Korean phonological rules. The Korean phonological rules selected 10 essential phonological rules (nasalization, /t/deletion, palatalization, /h/deletion, simplification of Consonant cluster, fortition, /l/nasalization, flat stop sound formation in final syllable, aspiration, liquidation) that occur during the public phonological process [9]. The cloud-based speech recognition Open API targeted seven domestic and foreign cloud companies (Kakao, ETRI, Naver, Microsoft, Google, IBM, Amazon, IBM). Speech data recorded a total of 100 sentences and 2560 phrases, 10 sentences each for 10 syllables by phonological rule, such as Table 4 [9,30,31]. Five speakers, male and female, participated in the recording, and the recording environment was recorded in a general office without soundproofing facilities. The format of the speech data was 16-bit PCM with a sampling of 16 kHz. Cloud-based speech recognition Open API did not consider any speech recognition options provided by cloud companies. The service method was chosen as a non-streaming method. The experimental equipment used a web program developed using PHP for general desktop computers. The evaluation method was measured in words. The recognition performance was verified by calculating the Word Error Rate (WER) in sentence, as shown in Equation (1). In Equation (1) S means Substitution, I mean Insertion, D means Delete, and N means the whole input phrase.
In the evaluation, the error rate of the whole words (sentence containing the phonological rule word) and the error rate of the phonological rule word were measured, respectively. Whole words consisted of sentences containing phonological rules (Ex: KOREAN-> "종이를 접는 방법들 배우고 싶다" / IPA->" tsoˈŋiɾɯl tsʌmnɯn paŋbʌpɯl pɛˈugo ɕiptʼa" / ENGLISH->"I would like to learn how to fold paper", the phonological rule word is KOREAN->"접는" / IPA->"tsʌmnɯn"/ ENGLISH->"folding") [32].
| Phonological rules | Examples: Pronunciation variation (Before → After), Symbol (IPA) |
|---|---|
| Nasalization | tsʌpnɯn → tsʌmnɯn, pʌpman → pʌmman, patnɯn → pannɯn, natsʰman → nanman, magnɯn → maŋnɯn,tʼʌgman → tʼʌŋman, takʼnɯn → taŋnɯn, ipʰman → imman, u:snɯn → uːnnɯn, mitnɯnta → minnɯnta. |
| /t/deletion | tsʌdzsoka → tsʌsʼoka, mitsaoni → misʼaˈoˈni, kasʼsɯbnida → kasʼɯmnida, patsɯbnida → pasʼɯmnida, kɯɾɯsɕʼisgo → kɯˈɾɯt ɕʼikʼo, mutsɯbnida → musʼɯmnida, tɯtsɯbnida → tɯsʼɯmnida, tatsɯbnida → tasʼɯmnida,kətsɯbnida → kəsʼɯmnida, kotsɯbnida → kosʼɯmnida. |
| Palatalization | mitʰi → mitsʰi, patʰita → patsʰita, kuˈti → kuˈdzi, katʰi → katsʰi, hɛˈdotiɾɯl → hɛˈdodziɾɯl, maˈti iˈni → maˈdzi iˈni,kʌtʰi → kʌtsʰi, putʰida → putsʰida, satʰsatʰi → saˈsʼatsʰi, kuthjʌsʼta → kutsʰʌta. |
| /h/deletion | naˈha → naˈa, ɕiˈɾhʌhanda → ɕiˈɾʌɦanda, maːnhɯn → maːnɯn, sʼaˈhida → sʼaˈida, noˈhinda → noˈinda, kʼɯlhidaka → kʼɯlidaka, anhɯn → annɯn, aˈnha → aˈna, aˈɾha → aˈɾa, aɾhɯn → aɾɯn |
| Simplification of consonant cluster | nʌksto → nʌktʼo, ʌndznɯn → ʌnnɯn, kuːlmko → kuːmkʼo, saːlmmani → saːmmani, haltʰtsi → haltsʼi, kʼɯlhnɯnda → kʼɯllɯnda, palktsi → paktsʼi, nʌlbta → nʌltʼa, ɯlpʰko → ɯpkʼo, alhnɯn → allɯn. |
| Fortition | kukputʰʌ → kukpʼutʰʌ, tsapko → tsapkʼo, papto → paptʼo, mittsi → mitsʼi, uːsko → uːtkʼo, aːnko → aːnkʼo,oːmtsi → oːmtsʼi, kaltɯŋɯn → kaltʼɯŋɯn, multsilɯn → multsʼilɯn, solpaŋulɯl → solpʼaŋulɯl. |
| /l/nasalization | nɯŋljʌkdo → nɯŋɲʌkdo, hamljaŋ → hamɲaŋ, ɯˈmunlon → ɯˈmunnon, hjʌpljʌkhajʌ → hjʌmɲʌkhaˈjʌ,homlʌnɯl → hom nʌnɯl, ʌplodɯ → ʌpnodɯ, ɕimlilɯl → ɕimɲilɯl, pjəːŋljʌlɯn → pjəːŋɲʌlɯn, tsikljʌllo → tsiŋɲʌllo, taːmljʌk → taːmɲʌk. |
| Flat stop sound formation in final syllable | jʌpʰ → jʌp, təːpʰko → təːpkʼo, ipʰto → iptʼo, nastwa → natʼo, isʼta → itʼa, pitsʼto → pitʼo, nohnɯn → nonnɯn, takʼnɯn → taknɯn, osman → onman, apʰman → amman. |
| Aspiration | mathjʌŋɯn → matʰjʌŋɯn, nohko → nokʰo, nohtaga → notʰaga, nəhtʌɾa → nətʰʌɾa, maːnhkʌdɯn → maːnkʰʌdɯn,kʼɯl htsido → kʼɯltsʰido, tsohtsinɯn → tsoˈtsʰinɯn, pʌphakkwanɯn → pʌpʰakʼanɯn, palkhjʌtsugi → palkʰjʌtsuˈgi,iphaki → ipʰaki. |
| Liquidization | mulnori → mullori, sʼalnunɰi → sʼallunɰi, pulnɯŋ → pullɯŋ, ɕilnɛhwaɾɯl → ɕillɛɦwaɾɯl, hultʰnɯn → hullɯn, tal nimɯl → talʎiml, alhnɯn → allɯn, sonnanloka → sonnaːlloka, ɕinlaeˈke → ɕillaeˈke, onlain → ollain. |
Examples of words by experimental phonological rules
3.2. Experiment Result
As a result of the experiment, as shown in Table 5, the error rate for all words on a per cloud company basis was 8.09% for Microsoft and 8.28% for Kakao, showing good performance. IBM 43.38% and Naver 19.02% showed poor performance. As shown in Table 6, the error rates for phonological rules were 18.00% for Kakao and 25.60% for Microsoft, which showed good performance. IBM 71.20% and Amazon 36.00% did not performance well. As shown in Table 5, the error rates of sentences containing phonological rules word on the basis of phonological rules were for /l/nasalization 12.32% and /h/deletion 13.20%, showing good performance. Palatalization 23.48% and aspiration 22.04% showed poor performance. In Table 6, the error rates for phonological rules word were /h/deletion 16.29% and /l/nasalization 20.57%, which showed good performance, while simplification of consonant cluster 61.43% and aspiration 49.14% showed poor performance. Table 7 show the ratio of the number of incorrect words in phonological rules words to the number of incorrect words in whole words. The ratio was as low as 31.34% for IBM and 35.11% for Naver, and as high as 61.84% for Microsoft and 50.57% for Google. As shown in Table 8, the speech recognition error rate for whole words by speaker was 14.79% to 20.34%, and the speech recognition error rate for phonological rule words by speaker was 30.43% to 40.00% as shown in Table 9.
| Amazon | ETRI | IBM | Kakao | MS | Naver | Sum of wrong words | Total number of words | WER% | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Nasalization | 12% | 13% | 9% | 44% | 10% | 8% | 20% | 309 | 1855 | 16.66 |
| /t/deletion | 12% | 13% | 13% | 42% | 8% | 10% | 18% | 270 | 1610 | 16.77 |
| Palatalization | 22% | 18% | 17% | 56% | 13% | 13% | 25% | 452 | 1925 | 23.48 |
| /h/deletion | 13% | 4% | 8% | 45% | 4% | 4% | 15% | 231 | 1750 | 13.20 |
| Simplification of consonant cluster | 21% | 22% | 16% | 43% | 14% | 11% | 22% | 415 | 1960 | 21.17 |
| Fortition | 16% | 12% | 8% | 40% | 9% | 7% | 13% | 254 | 1715 | 14.81 |
| /l/nasalization | 11% | 5% | 6% | 42% | 5% | 3% | 15% | 220 | 1785 | 12.32 |
| Flat stop sound formation in final syllable | 9% | 11% | 4% | 44% | 5% | 5% | 20% | 270 | 1960 | 13.78 |
| Aspiration | 27% | 23% | 13% | 41% | 9% | 16% | 26% | 378 | 1715 | 22.04 |
| Liquidization | 16% | 11% | 7% | 46% | 6% | 4% | 16% | 251 | 1645 | 15.26 |
| Sum of wrong words | 404 | 343 | 261 | 1136 | 212 | 207 | 487 | 3050 | 17920 | 17.02 |
| Total number of words | 2560 | 2560 | 2560 | 2560 | 2560 | 2560 | 2560 | 17920 | – | – |
| WER% | 15.78 | 13.40 | 10.20 | 44.38 | 8.28 | 8.09 | 19.02 | 17.02 | – | – |
Speech recognition error rate for whole words by company (WER%)
| Amazon | ETRI | IBM | Kakao | MS | Naver | Sum of wrong words | Total number of words | WER% | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Nasalization | 36.00% | 32.00% | 26.00% | 76.00% | 24.00% | 20.00% | 24.00% | 119 | 350 | 34.00 |
| /t/deletion | 46.00% | 44.00% | 50.00% | 92.00% | 24.00% | 44.00% | 40.00% | 170 | 350 | 48.57 |
| Palatalization | 42.00% | 34.00% | 36.00% | 60.00% | 8.00% | 26.00% | 34.00% | 120 | 350 | 34.29 |
| /h/deletion | 14.00% | 2.00% | 8.00% | 60.00% | 0.00% | 12.00% | 18.00% | 57 | 350 | 16.29 |
| Simplification of consonant cluster | 72.00% | 56.00% | 54.00% | 88.00% | 44.00% | 52.00% | 64.00% | 215 | 350 | 61.43 |
| Fortition | 20.00% | 26.00% | 20.00% | 60.00% | 16.00% | 16.00% | 22.00% | 90 | 350 | 25.71 |
| /l/nasalization | 24.00% | 12.00% | 12.00% | 58.00% | 6.00% | 10.00% | 22.00% | 72 | 350 | 20.57 |
| Flat stop sound formation in final syllable | 14.00% | 26.00% | 6.00% | 78.00% | 18.00% | 20.00% | 40.00% | 101 | 350 | 28.86 |
| Aspiration | 52.00% | 72.00% | 36.00% | 60.00% | 26.00% | 42.00% | 56.00% | 172 | 350 | 49.14 |
| Liquidization | 40.00% | 18.00% | 16.00% | 80.00% | 14.00% | 14.00% | 22.00% | 102 | 350 | 29.14 |
| Sum of wrong words | 180 | 161 | 132 | 356 | 90 | 128 | 171 | 1218 | 3500 | 34.80 |
| Total number of words | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 3500 | – | – |
| WER% | 36.00 | 32.20 | 26.40 | 71.20 | 18.00 | 25.60 | 34.20 | 34.80 | – | – |
Speech recognition error rate for phonological rules by company (WER%)
| 1st | 2nd | Average (%) | |||
|---|---|---|---|---|---|
| Company | WER% | Company | WER% | ||
| Nasalization | MS | 20.00 | Kakao, Naver | 24.00 | 34.00 |
| /t/deletion | Kakao | 24.00 | Naver | 40.00 | 48.57 |
| Palatalization | Kakao | 8.00 | MS | 26.00 | 34.29 |
| /h/deletion | Kakao | 0.00 | ETRI | 2.00 | 16.29 |
| Simplification of consonant cluster | Kakao | 44.00 | MS | 52.00 | 61.43 |
| Fortition | Kakao, MS | 16.00 | Amazon, Google | 20.00 | 25.71 |
| /l/nasalization | Kakao | 6.00 | MS | 10.00 | 20.57 |
| Flat stop sound formation in final syllable | 6.00 | Amazon | 14.00 | 28.86 | |
| Aspiration | Kakao | 26.00 | 36.00 | 49.14 | |
| Liquidization | Kakao, MS | 14.00 | 16.00 | 29.14 | |
| Total | Kakao | 18.00 | MS | 25.60 | 34.80 |
Ranking of WER% in terms of phonological rules by company
| A | B | C | D | E | Sum of wrong words | Total number of words | WER% | |
|---|---|---|---|---|---|---|---|---|
| Nasalization | 13.21% | 24.26% | 14.82% | 14.29% | 16.71% | 309 | 1855 | 16.66 |
| /t/deletion | 15.53% | 19.25% | 17.39% | 13.35% | 18.32% | 270 | 1610 | 16.77 |
| Palatalization | 20.78% | 26.49% | 19.74% | 23.64% | 26.75% | 452 | 1925 | 23.48 |
| /h/deletion | 12.29% | 16.29% | 13.43% | 10.00% | 14.00% | 231 | 1750 | 13.20 |
| Simplification of consonant cluster | 19.13% | 24.49% | 20.15% | 21.68% | 20.41% | 415 | 1960 | 21.17 |
| Fortition | 12.83% | 18.95% | 11.37% | 10.50% | 20.41% | 254 | 1715 | 14.81 |
| /l/nasalization | 12.04% | 14.29% | 13.73% | 9.80% | 11.76% | 220 | 1785 | 12.32 |
| Flat stop sound formation in final syllable | 10.97% | 15.82% | 9.44% | 12.76% | 19.90% | 270 | 1960 | 13.78 |
| Aspiration | 20.41% | 24.78% | 20.99% | 19.53% | 24.49% | 378 | 1715 | 22.04 |
| Liquidization | 12.77% | 17.93% | 12.77% | 10.64% | 22.19% | 251 | 1645 | 15.26 |
| Sum of wrong words | 539 | 729 | 552 | 530 | 700 | 3050 | 17920 | 17.02 |
| Total number of words | 3584 | 3584 | 3584 | 3584 | 3584 | 17920 | – | – |
| WER% | 15.04 | 20.34 | 15.40 | 14.79 | 19.53 | 17.02 | – | – |
Speech recognition error rate for whole words by speaker (WER%)
| A | B | C | D | E | Sum of wrong words | Total number of words | WER% | |
|---|---|---|---|---|---|---|---|---|
| Nasalization | 30.00% | 45.71% | 31.43% | 27.14% | 35.71% | 119 | 350 | 34.00 |
| /t/deletion | 45.71% | 47.14% | 57.14% | 44.29% | 48.57% | 170 | 350 | 48.57 |
| Palatalization | 31.43% | 41.43% | 34.29% | 34.29% | 30.00% | 120 | 350 | 34.29 |
| /h/deletion | 12.86% | 24.29% | 15.71% | 10.00% | 18.57% | 57 | 350 | 16.29 |
| Simplification of consonant cluster | 60.00% | 70.00% | 55.71% | 62.86% | 58.57% | 215 | 350 | 61.43 |
| Fortition | 27.14% | 35.71% | 20.00% | 15.71% | 30.00% | 90 | 350 | 25.71 |
| /l/nasalization | 28.57% | 18.57% | 22.86% | 11.43% | 21.43% | 72 | 350 | 20.57 |
| Flat stop sound formation in final syllable | 24.29% | 34.29% | 27.14% | 27.14% | 31.43% | 101 | 350 | 28.86 |
| Aspiration | 50.00% | 48.57% | 50.00% | 48.57% | 48.57% | 172 | 350 | 49.14 |
| Liquidization | 24.29% | 34.29% | 27.14% | 22.86% | 37.14% | 102 | 350 | 29.14 |
| Sum of wrong words | 234 | 280 | 239 | 213 | 252 | 1218 | 3500 | 34.80 |
| Total number of words | 700 | 700 | 700 | 700 | 700 | 3500 | – | – |
| WER% | 33.43 | 40.00 | 34.14 | 30.43 | 36.00 | 34.80 | – | – |
Speech recognition error rate for words of phonological rules by speaker (WER%)
4. CONCLUSION
In this paper, a study was conducted on continuous speech recognition performance in accordance with the Korean phonological rules of the cloud-based speech recognition Open API. First, the results of the experiment were compared and analyzed the speech recognition performance of the cloud-based speech recognition Open API. In Figure 2, the whole words error rate and phonological rule words error rate by cloud company both showed good performance for Kakao and MS, while IBM and Naver showed low performance. Looking at Table 7’s ranking of error rates for corporate phonological rule phrases, Kakao showed good performance in all areas except nasalization and flat stop sound formation in final syllable, while Microsoft showed good performance in nasalization and Google showed good performance in flat stop sound formation in final syllable. Table 7’s second-place group showed Google performing well in two areas of aspiration and liquidization, Amazon in two areas of fortition and final syllable neutralization, and Naver in /t/deletion and ETRI in /h/deletion. Cloud company’s speech recognition Open API showed good performance for certain phonological rules. Second, the speech recognition characteristics of the Korean phonological rules were analyzed. In Figure 3, the whole words error rate and the phonological rule words error rate were both good for /h/deletion and /l/nasalization, and palatalization, simplification of consonant cluster, and aspiration were poor. Table 10 represents the ratio of the number of wrong words of phonological rules words to the number of wrong words of whole words by company. The ratio is very high, from at least 35.11% to up to 61.84%. Figures 4 and 5 show similar alignments in both speech recognition error rates for whole words and speech recognition error rates for phonological rule words. In other words, the speech recognition performance of the phonological rule words is affecting the speech recognition performance in the whole words. Figures 6 and 7 represent speech recognition error rates for phonological rule words by company and speaker, and the linear shape in Figure 6 shows a more distracting linear form than in Figure 7. In other words, speech recognition performance for phonological rules can be attributed more to the speech recognition engine of cloud companies than to the speaker. Through this study, we confirmed that the speech recognition performance of the cloud-based speech recognition Open API for Korean phonological rule differs between companies, and that the speech recognition system of the same cloud company also has characteristics that show different performance by Korean phonological rule. According to the characteristics of speech recognition by Korean phonological rule, first, there was a difference in speech recognition performance by phonological rule. Second, speech recognition performance of phonological rule words had a significant impact on the overall speech performance. Third, speech recognition performance for phonological rule words was more different between companies than speakers. Therefore, this research will contribute to improving the Korean phonological rule speech recognition performance of the speech recognition engine of the cloud computing company and help speech recognition developers select the Open API to develop an applied speech recognition system.
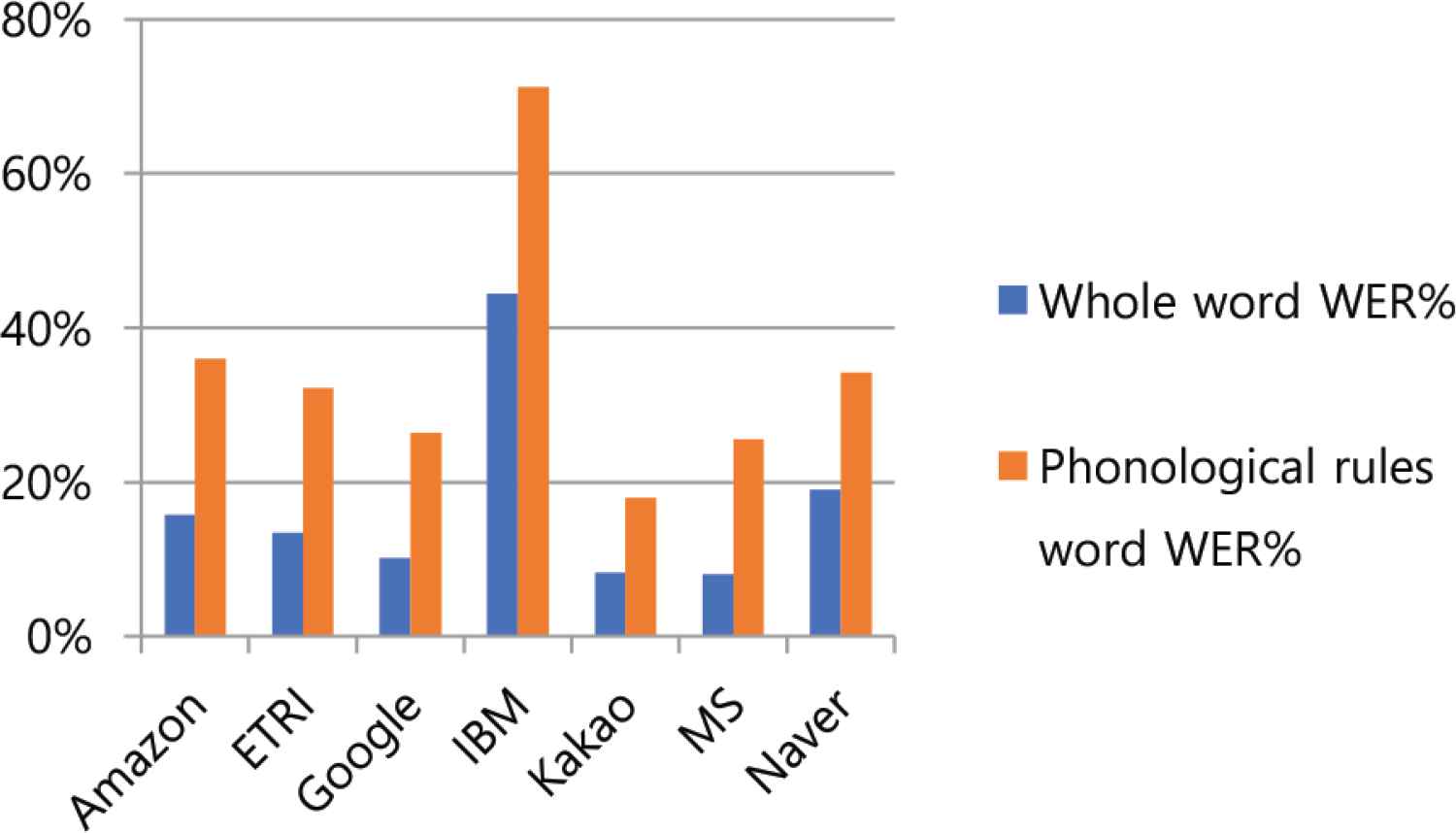
Comparison of WER% by company.
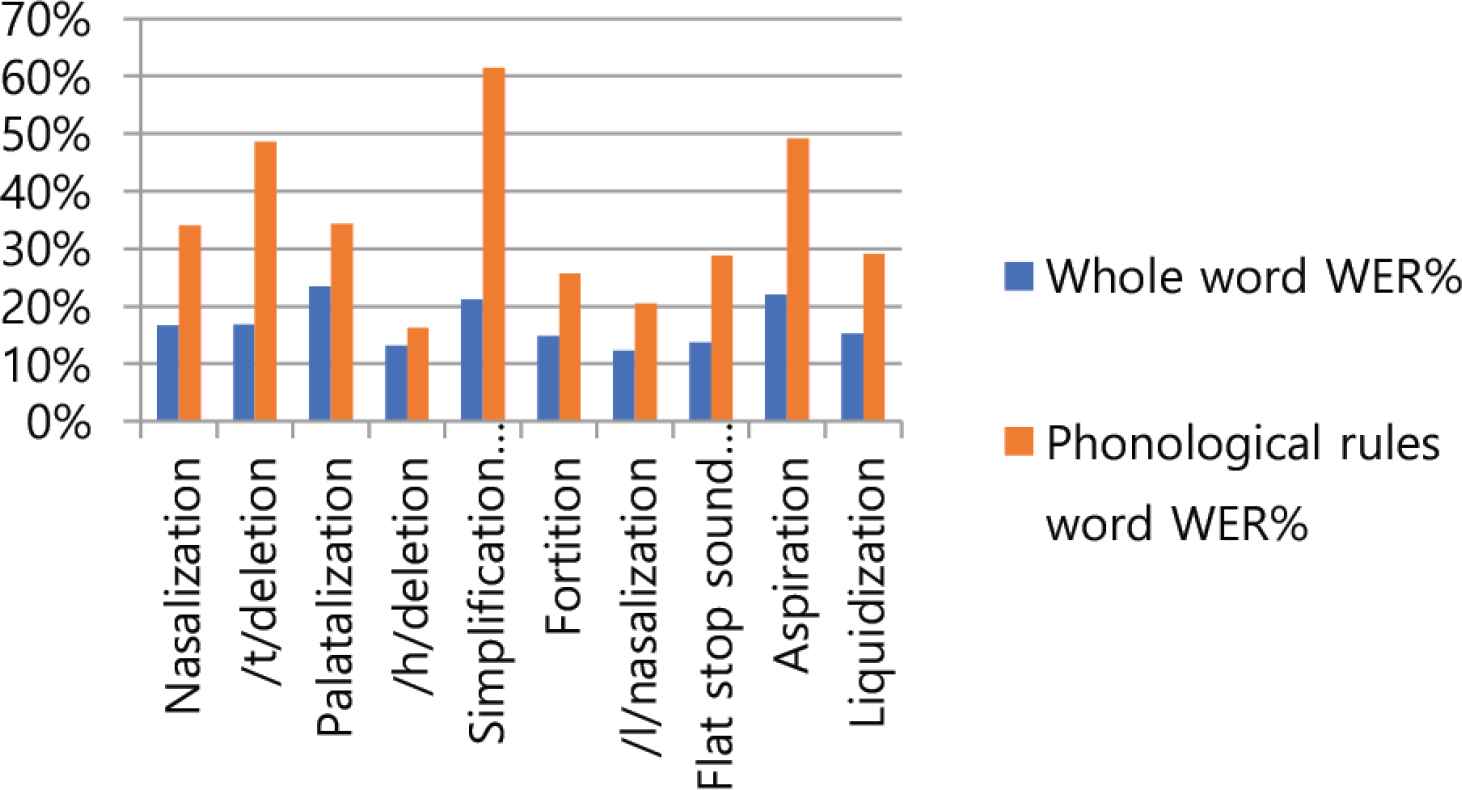
Comparison of WER% by phonological rules.
| Amazon | ETRI | IBM | Kakao | MS | Naver | Sum of wrong words | ||
|---|---|---|---|---|---|---|---|---|
| Total number of wrong words (A) | 404 | 343 | 261 | 1136 | 212 | 207 | 487 | 3050 |
| The number of words with wrong phonological rules (B) | 180 | 161 | 132 | 356 | 90 | 128 | 171 | 1218 |
| B/A ratio (%) | 44.55 | 46.94 | 50.57 | 31.34 | 42.45 | 61.84 | 35.11 | 39.93 |
Ratio of phonological rules to whole words by company
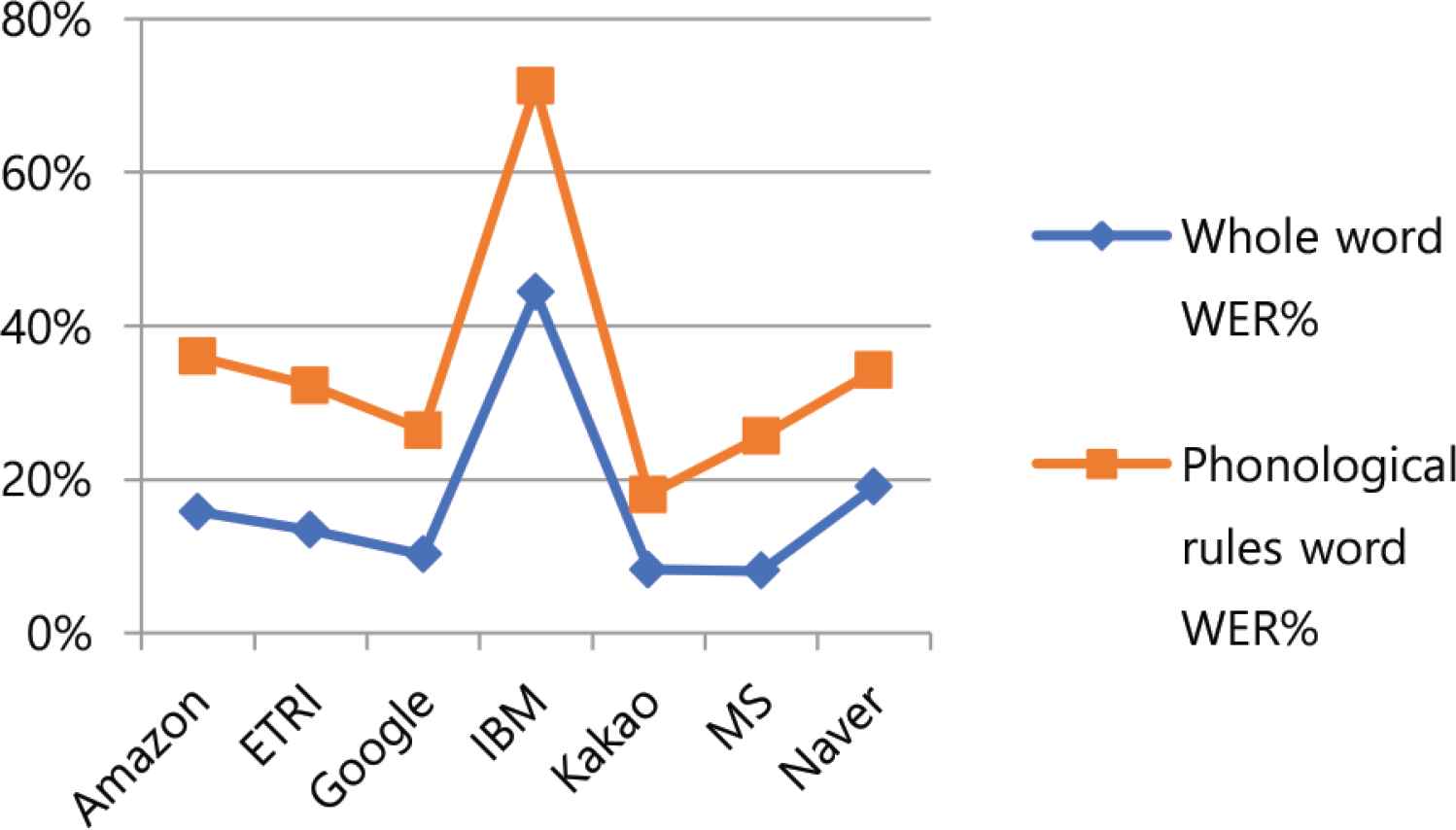
Linear comparison of WER% by company.
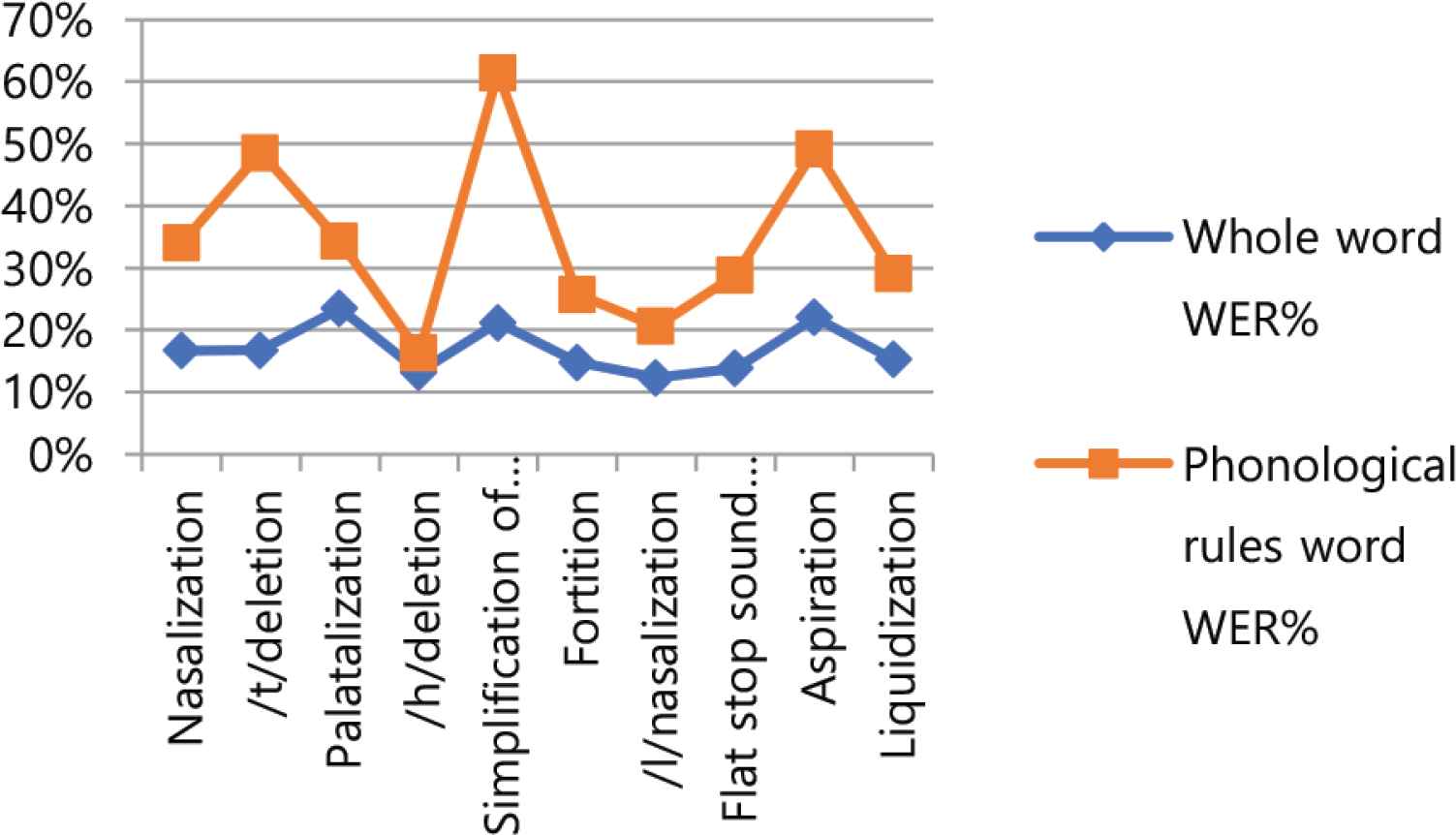
Linear comparison of WER% by phonological rules.
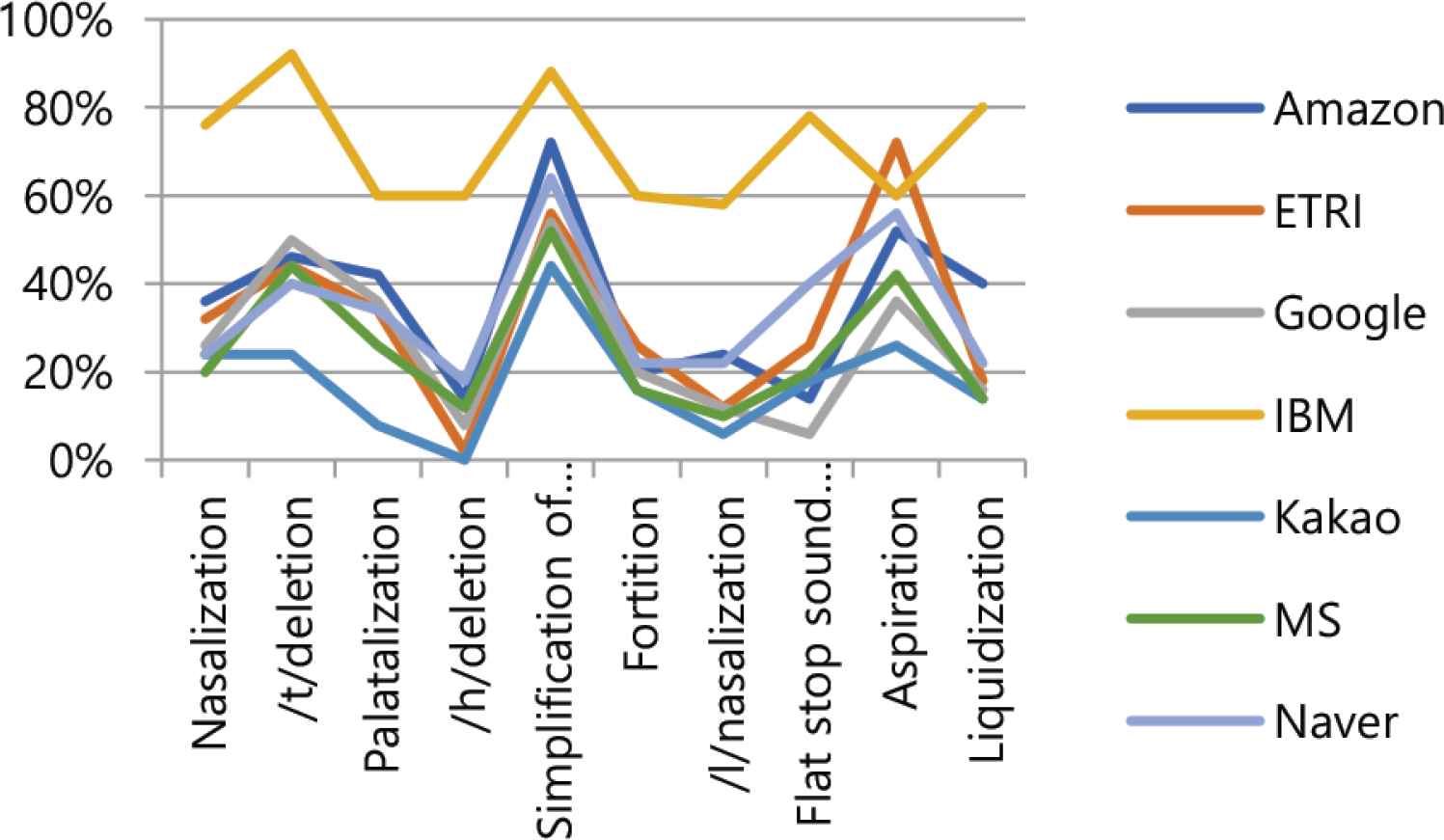
Comparison of WER% of phonological rules by company.
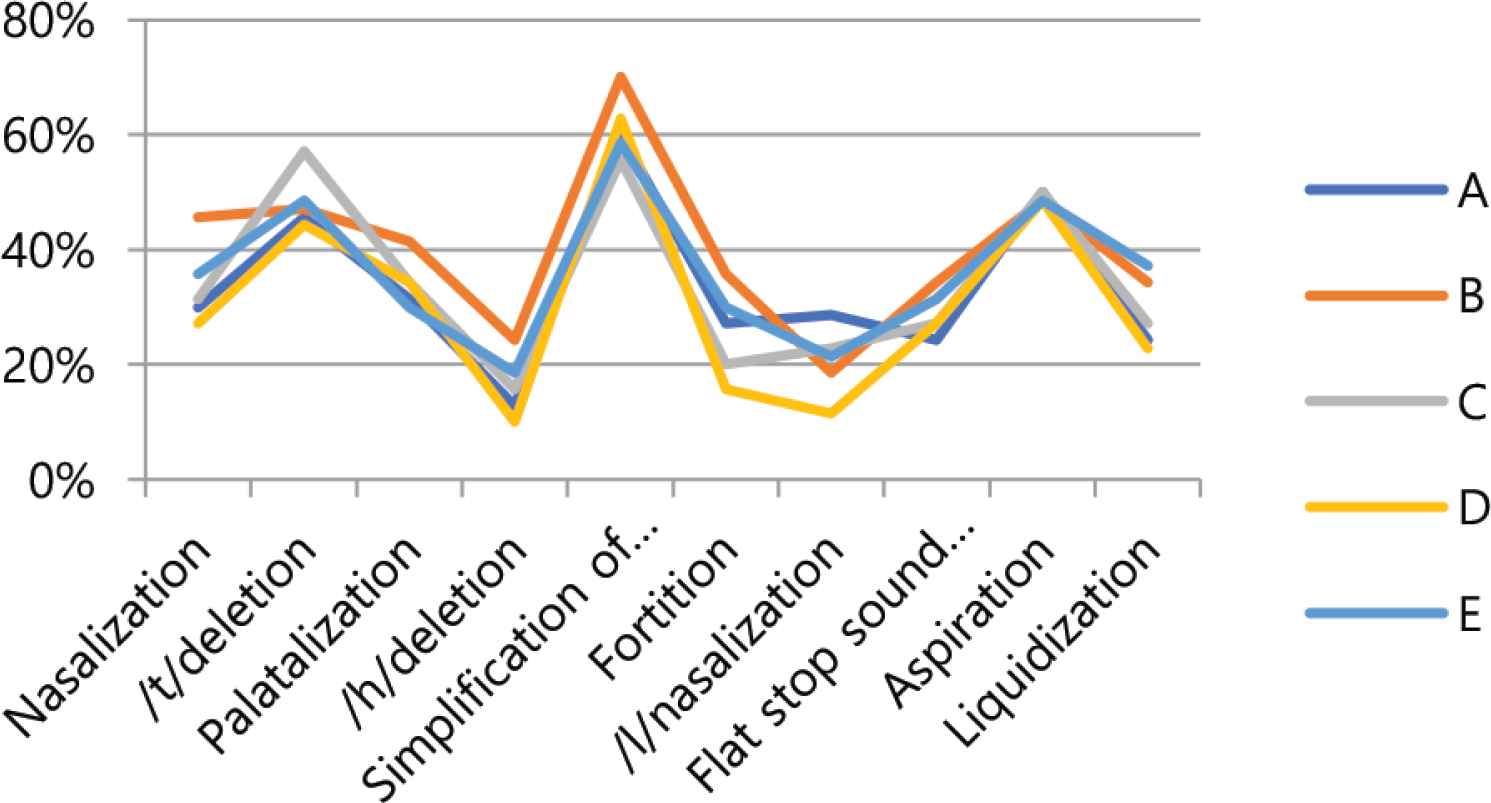
Comparison of WER% for phonological rules by speaker.
A future task is to evaluate the performance of speech recognition on the optionally phonological rules of the synchronic phonological process. The result is expected to be different from the speech recognition rate of the essential phonological rule because the rules may or may not be applied in the same phoneme environment. Following the essential phonological rules of the synchronic phonological process, the study of the evaluation of speech recognition performance for the optionally phonological rules will be meaningful to improve the performance of speech recognition in Korean.
CONFLICTS OF INTEREST
The authors declare they have no conflicts of interest.
REFERENCES
Cite this article
TY - JOUR AU - Hyun Jae Yoo AU - Sungwoong Seo AU - Sun Woo Im AU - Gwang Yong Gim PY - 2021 DA - 2021/01/08 TI - The Performance Evaluation of Continuous Speech Recognition Based on Korean Phonological Rules of Cloud-Based Speech Recognition Open API JO - International Journal of Networked and Distributed Computing SP - 10 EP - 18 VL - 9 IS - 1 SN - 2211-7946 UR - https://doi.org/10.2991/ijndc.k.201218.005 DO - 10.2991/ijndc.k.201218.005 ID - Yoo2021 ER -