
An Overview on Fuzzy Modelling of Complex Linguistic Preferences in Decision Making
- DOI
- 10.1080/18756891.2016.1180821How to use a DOI?
- Keywords
- Fuzzy Linguistic Approach; Fuzzy Logic; Computing with Words; Decision Making; Preference Modelling
- Abstract
Decision makers involved in complex decision making problems usually provide information about their preferences by eliciting their knowledge with different assessments. Usually, the complexity of these decision problems implies uncertainty that in many occasions has been successfully modelled by means of linguistic information, mainly based on fuzzy based linguistic approaches. However, classically these approaches just allow the elicitation of simple assessments composed by either one label or a modifier with a label. Nevertheless, the necessity of more complex linguistic expressions for eliciting decision makers’ knowledge has led to some extensions of classical approaches that allow the construction of expressions and elicitation of preferences in a closer way to human beings cognitive process. This paper provides an overview of the broadest fuzzy linguistic approaches for modelling complex linguistic preferences together some challenges that future proposals should achieve to improve complex linguistic modelling in decision making.
- Copyright
- © 2016. the authors. Co-published by Atlantis Press and Taylor & Francis
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
In spite of decision making processes have been an object of research during many years, new requirements and challenges within the topic arise often, because of new problems and new necessities of decision makers. Nowadays the complexity of decision making problems is not only due to the existence of multiple and conflicting goals and the necessity of dealing with huge amounts of information and alternatives, but also because of time pressure, lack of knowledge and so on. It implies that these problems are ill-structured whose definition framework often involves uncertainty, vagueness and incomplete information that cannot be properly modelled by probabilistic models. In such decision situations with non-probabilistic uncertainty the use of linguistic information has provided successful results in different fields 10,24,30,31. To model and cope with the inherent uncertainty and vagueness of linguistic descriptors, it has been extensively used the fuzzy linguistic approach 2,47 based on the fuzzy sets theory 17. Hence, decision making problems could use the fuzzy linguistic approach in its solving process whenever its fuzzy representation would be adequate for the decision situations.
The usefulness of using a fuzzy representation to model linguistically preferences in decision making comes from the interpretation of the semantics of a fuzzy set as a degree of preference 8, such that the fuzzy semantics represents the values of a decision variable more o less preferred. Therefore, by using the interpretation of degree of preference for semantics of fuzzy sets, the use of fuzzy linguistic labels to express the intensity of preference for a given alternative in a decision-making problem seems natural.
The use of linguistic information in decision making implies to carry out computing with words (CW) processes. CW is defined as a methodology for reasoning, computing and making decisions using information described in natural language 29. Therefore, it emulates human cognitive processes to improve solving processes of problems dealing with uncertainty. Thus, CW has been applied as computational basis to decision making problems that deal with linguistic information 22,26, because it provides tools close to human beings reasoning processes related to decision making, enhances the reliability and flexibility of classical decision models and improves the resolution of decision making under uncertainty with linguistic information. Consequently, different linguistic computational models have been developed to manage linguistic decision making 14, 20, 37, 41, 43 .
Across specialized literature different fuzzy linguistic based approaches for modelling preferences in decision making and computational models for CW processes can be found 18,22,26,28,32, however these approaches provide just either simple terms or labels that hardly can express in many complex decision situations the decision makers’ knowledge in a proper and adequate way according to decision makers’ aims. Hence, recently different researchers have proposed different attempts to facilitate the elicitation of linguistic preferences by expressions to some extent more elaborated than simple labels 20,33,38,42,49. Such extensions have used different fuzzy tools to model and compute with such linguistic expressions in a closer way to decision makers’ needs. This paper aims at providing an overview of the fuzzy approaches that model complex linguistic expressions together with their computational models. Eventually several challenges related to the modelling of com plex linguistic expressions within decision making are also pointed out.
This paper is structured as follows: Section 2 provides a brief review of the use of fuzzy linguistic information in decision making. Section 3 presents an overview of different fuzzy based approaches for modelling complex linguistic expressions paying attention to their computational models. Section 4 points out different challenges that must be achieved for improving this linguistic modelling in decision making problems, and finally Section 5 concludes this paper.
2. Decision Making and Linguistic Information
The introductory section pointed out that complex real world decision making problems are often ill-structured problems that cannot be solved straightforwardly because of the uncertainty, vagueness and incomplete information involved. In such a type of decision making problems, the use of linguistic descriptors by decision makers is a straightforward and natural tool to elicit their preferences on the alternatives. The fuzzy linguistic approach 2,47 which is based on the fuzzy sets theory 17, has been widely used to model and manage the vagueness and inherent uncertainty of the linguistic descriptors by linguistic variables.
Therefore, before providing an overview about different fuzzy based approaches to model complex linguistic preferences, this section reviews in short necessary concepts to understand such approaches. First, a brief revision of fuzzy linguistic approach is provided. Afterwards, the decision making solving scheme used when linguistic information takes part in the decision process is reviewed and eventually classical fuzzy linguistic computational models are shown.
2.1. Fuzzy Linguistic Approach
The fuzzy linguistic approach 47 based on the fuzzy set theory is a common approach for modelling the linguistic information by using the concept of linguistic variable 47, “a variable whose values are not numbers, but words or sentences in a natural or artificial language”. A linguistic value is less precise than a number, but it is closer to human cognitive processes used to solve successfully problems dealing with uncertainty. Formally a linguistic variable is defined as follows:
Definition 1.
48: A linguistic variable is characterized by a quintuple (V,T(V),U,G,M) in which V is the name of the variable; T(V) (or simply T) denotes the term set of V, i.e., the set of names of linguistic values of V, with each value being a fuzzy variable denoted generically by X and ranging across a universe of discourse U which is associated with the base variable u; G is a syntactic rule (which usually takes the form of a grammar) for generating the names of values of H; and M is a semantic rule for associating its meaning with each V, M(X), which is a fuzzy subset of U.
The use of linguistic variables needs the selection of appropriate linguistic descriptors for the term set, including the analysis of their granularity of uncertainty, and their syntax and semantics. The former commonly noted as, g + 1, determines the level of discrimination among different counts of uncertainty modeled by the linguistic descriptors in the linguistic term set, S = {s0, …, sg}. A fine granule means a high level of discrimination, however a coarse granule means a low discrimination level. The selection of the syntax and suitable semantics are crucial to determine the validity of the fuzzy linguistic approach, and exist different approaches to choose the linguistic descriptors and different ways to define their linguistic semantics 21,44,47. The semantics of the terms is represented by fuzzy numbers, described by membership functions. The linguistic assessments given by users are just approximate ones. A way to characterize a fuzzy number is to use a representation based on parameters of its membership function 3. Figure 1 shows an example of a linguistic term set with the syntax and semantics defined.
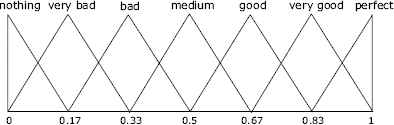
A linguistic term set of 7 labels
2.2. Linguistic decision making solving scheme
A classical decision making solving scheme consists of two main steps 35:
- 1.
An aggregation phase that aggregates the values provided by the decision makers to obtain a collective assessment for the alternatives.
- 2.
An exploitation phase of the collective assessments to rank, sort or choose the best one/s among the alternatives.
The use of linguistic information in decision making modifies the previous solving scheme adding two new steps: (i) selecting the linguistic term set and its semantics and (ii) selecting the aggregation operator for linguistic information. Therefore, the linguistic decision making solving scheme is composed by 4 steps (see Fig. 2).
- •
Selecting the linguistic term set and the semantics: In this step, the linguistic domain in which decision makers provide their assessments about the alternatives is defined according to each specific decision problem.
- •
Selecting the aggregation operator for linguistic information: A proper linguistic aggregation operator is selected to aggregate the linguistic assessments provided by decision makers in accordance to the goal of the problem.
- •
Aggregation: The linguistic assessments are aggregated by using the aggregation operator previously selected to obtain a collective value for each alternative of the decision problem.
- •
Exploitation: The collective values obtained in the previous aggregation step are ranked to select the best alternative(s).
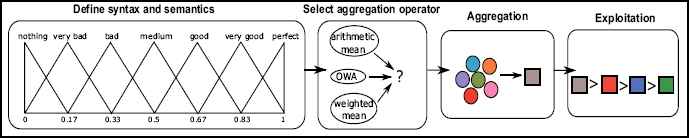
Linguistic decision making solving scheme
2.3. Linguistic computing models
The linguistic decision making solving scheme depicted in Figure 2 shows the necessity of developing linguistic computing models to operate with linguistic information. Different linguistic computing models have been developed to facilitate such processes. Here a brief revision of the most extended models to deal with linguistic variables are revised.
2.3.1. Classical linguistic computing models
Initially, two linguistic computing models based on the fuzzy linguistic approach 47 were defined to perform CW processes.
- 1.
Linguistic computing model based on membership functions: It makes the computations with linguistic terms by operating directly on their membership functions using the Extension Principle 16. The use of fuzzy arithmetic based on the Extension Principle increases the vagueness of the results. Therefore, the results obtained are fuzzy numbers that usually do not match with any linguistic term in the initial linguistic term set. Taking into account these results, there are two possible ways:
- •
If in the decision problem, it is more relevant to obtain precise results than interpretable ones, the results are expressed by fuzzy numbers 1.
- •
If an interpretable and linguistic result is required, then it is necessary an approximation function, app1(·), to associate the fuzzy result with a linguistic term in S 23:
where Sn symbolizes the n Cartesian product of S,The approximation process implies a loss of information and lack of accuracy of the results.
A later computational approach based on membership functions for linguistic information is the one based on type-2 fuzzy sets. This computational model makes use of type-2 fuzzy sets to model the linguistic assessments 27,39. The use of type-2 fuzzy sets has been justified in order to improve the modelling and management of the uncertainty in linguistic information 28,39. The majority of the contributions dealing with this fuzzy representation use interval type-2 fuzzy sets which maintain the uncertainty modelling properties of general type-2 fuzzy sets, but reducing the computational efforts that are needed to operate with them. Different aggregation operators for type-2 representation were introduced in 7,50. As the type-1 linguistic based representation, the type-2 fuzzy sets computational based model needs to approximate the resulting type-2 fuzzy set from a linguistic operation by mapping the result into a linguistic assessment producing a loss of information.
- •
- 2.
Symbolic linguistic computing model: Symbolic models have been widely used in CW, because they are simple and provide interpretable results. Such models use the ordered structure of the linguistic term set, S = {s0, s1, …, sg} where si < sj if i < j, to carry out the computations. The intermediate results are numerical values γ ∈ [0, g], that must be approximated by an approximation function app2(·) to obtain a numerical value.
Yager in 45 introduced the symbolic model based on ordinal scales and max–min operators, it obtains linguistic results easy to understand, but their accuracy is low because they are computed by using the maximum or minimum values ignoring the inter-mediated ones. Later on, the linguistic symbolic computational model based on convex combinations was introduced by Delgado et al. 5, which directly acts over the label indexes, {0, …, g}, of the linguistic term set, S = {s0, …, sg}, in a recursive way producing a real value on the granularity interval, [0,g], of the linguistic term set S. It is worthy to note that this model usually assumes that the cardinality of the linguistic term set is odd and that linguistic labels are symmetrically placed around a middle term. The result of a symbolic convex combination aggregation usually does not match with a term of the label set S, therefore it is also necessary to introduce an approximation function app2(·) for obtaining a solution in the linguistic term set S.Hence, similarly to the linguistic computing based on membership functions, the approximation process in the symbolic based models produces loss of information.
Therefore, both types of linguistic classical computing models produce loss of information due to the approximation processes and hence a lack of accuracy in the results. This loss of information is produced because the information representation model of the fuzzy linguistic approach is discrete in a continuous domain. In order to overcome these limitations different linguistic computing models have been proposed in the literature 26, the most widely used in decision making with linguistic information is the 2-tuple linguistic model 14,? that is briefly revised below, because some of the proposals to deal with complex linguistic expressions either extend it or are based on it.
2.3.2. 2-tuple linguistic model
As it was aforementioned, the 2-tuple linguistic model 14 was developed to avoid the loss of information and the lack of accuracy that present the classical computing models in the CW processes. Many approaches that deal with complex linguistic expressions either make or can make use of it, thus a short revision about the model it is introduced.
The 2-tuple linguistic model represents the linguistic information by means of a pair of values (s,α), where s is a linguistic term and α is a numerical value that represents the symbolic translation.
Definition 2.
14,22 The symbolic translation is a numerical value assessed in [−0.5, 0.5) that supports the “difference of information” between a counting of information β assessed in the interval of granularity [0, g] of the linguistic term set S = {s0, …, sg} and the closest value in {0, …, g} which indicates the index of the closest linguistic term in S.
This model defines a set of functions to facilitate the computations with 2-tuple linguistic values.
Definition 3.
14 Let S = {s0, …, sg} be a set of linguistic terms. The 2-tuple linguistic set associated with S is defined as
Remark 1.
Δ is a bijective function and
The 2-tuple linguistic model has defined a symbolic computational model based on the functions Δ and Δ −1 and defines a negation operator, several aggregation operators and the comparison between two 2-tuple linguistic values 14.
Example 1.
Let us suppose an example where decision makers provide their assessments by using the linguistic term set shown in Figure 1. The assessments provided are {low, very high, medium}. These linguistic terms are aggregated by using the 2-tuple arithmetic mean (see 25 for further detail). The result is
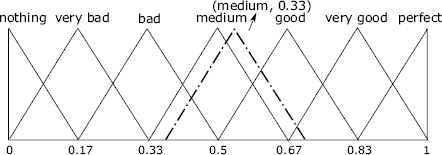
A 2-tuple linguistic value
3. Modelling Complex Linguistic Preferences
So far, it has been shown that the use of fuzzy linguistic information and its computational models (see Section 2) have been not only broadly used to model and manage the uncertainty in real world decision problems but also to solve such problems in different fields 9,12. Notwithstanding, some researchers have indicated the necessity of introducing some improvements to model the elicitation of linguistic information in decision making. Because decision makers involved in the problems are limited to express their knowledge by using only a simple linguistic term and often this type of modelling is not enough to reflect the knowledge and preference that they really want to elicit. Additionally, another limitation of current linguistic preference modelling approaches based on the fuzzy linguistic approach consists of the linguistic terms that can be used by decision makers in the decision problem are defined a priory, thus decision makers cannot express their preferences in a more flexible and richer way if it is necessary to elicit the preferences in a more elaborated way.
In order to face these restrictions, different proposals that facilitate the elicitation of elaborated linguistic preferences with complex linguistic expressions have been introduced in the literature 20,33,38,42,49. Such proposals focus their performance on very different points of view that can be used by decision makers according to their needs in each specific problem. Hence this section provides an overview of the most important proposals to model complex linguistic preferences pointing out the way to construct such expressions and the computing models used by them in order to accomplish the processes of CW in decision making. Additionally, some comments for analysing the main features of each proposal are introduced.
3.1. Proportional 2-tuple linguistic model
The first model that attracts our attention for modelling expressions more elaborated than a single term is the proportional 2-tuple linguistic model introduced by Wang and Hao in 41. Such a model is a generalization and extension of the 2-tuple linguistic model in which the linguistic modelling is based on the use of proportions of two adjacent linguistic terms represented by two pairs of values.
3.1.1. Representation model
In this model the information is represented by a proportional 2-tuple value which has a linguistic term in each pair that represents the linguistic information and a numerical value that indicates its proportion in the expression.
Definition 4.
41 Let S = {s0, …, sg} be an ordinal term set, I = [0,1] and
Remark 2.
The ordinal term si, i = {2, …, g − 1}, can be represented both (0si−1, 1si) and (1si, 0si+1).
This model also defines some functions to make easier the operations with this type of information.
Definition 5.
42 Let S = {s0, …, sg} be an ordinal term set and
The position index function π is bijective and its inverse
Example 2.
By using the linguistic term set depicted in Figure 1, some assessments represented by proportional 2-tuple values might be,
(0.66 medium, 0.33 good)
(0.25 good, 0.75 very good)
3.1.2. Computational model
A computational model based on the functions π and π−1 was also defined with the following operations 42.
- 1.
Comparison of proportional 2-tuple values
The comparison of linguistic information represented by proportional 2-tuple value is carried out as follows:
Let S = {s0, …, sg} be an ordinal term set and
Therefore, for any two proportional 2-tuple values (αsi, (1 − α)si+1) and (βsj, (1 − β)sj+1):
- •
if i < j, then
- (a)
(αsi, (1−α)si+1), (βsj, (1−β)sj+1) represents the same information when i = j − 1 and α = 0, β = 1
- (b)
(αsi, (1−α)si+1) < (βsj, (1−β)sj+1) otherwise
- (a)
- •
if i = j, then
- (a)
if α = β then (αsi, (1 − α)si+1), (βsj,(1 − β)sj+1) represents the same information
- (b)
if α < β then (αsi, (1 − α)si+1) < (βsj, (1 − β)sj+1)
- (c)
if α > β then (αsi, (1 − α)si+1) > (βsj, (1 − β)sj+1)
- (a)
- •
- 2.
Negation operator of a proportional 2-tuple value
The negation of a proportional 2-tuple value is defined as:
where g+1 is the cardinality of S, S = {s0, …, sg}. - 3.
Proportional 2-tuple aggregation operators
Several aggregation operators were defined by Wang and Hao to accomplish CW processes. The definitions of these aggregation operators are based on canonical characteristic values of linguistic terms. To do so, similar corresponding aggregation operators developed in 14 were defined to aggregate ordinal 2-tuple values by means of their position indexes 42.
In 42 was also introduced a relationship between the proportional 2-tuple linguistic model and the 2-tuple linguistic model 14.
Definition 6.
42 Let
3.1.3. Analysis of proportional 2-tuple expressions
The expressions represented by this model are still simple and far from common linguistic expressions used by human beings, because from the linguistic point of view decision makers do not provide naturally such expressions but rather they can be computed either from other linguistic representations or after a specific training expert might provide them directly. However, it was an interesting and initial step to provide a way to improve the elicitation of linguistic information.
3.2. Linguistic model based on fuzzy relation
A second step for dealing with the modelling of elaborated linguistic expressions was introduced by Tang and Zheng 38.
3.2.1. Representation model
Tang and Zheng proposed a linguistic model that generates linguistic expressions from a set of linguistic terms S = {s0, …, sg}, using logical connectives, such as (∨, ∧, ¬, →), whose semantics are represented by fuzzy relations R, that describe the degree of similarity between two linguistic terms si and sj. The set of all linguistic expressions is denoted as LE.
Definition 7.
38 Let LE be the set of linguistic expressions which is defined recursively as follows:
- 1.
si ∈ LE for i = {0, …, g},
- 2.
if θ, ϕ ∈ LE then ¬θ, θ ∨ ϕ, θ ∧ ϕ, θ → ϕ ∈ LE.
A formal definition of this set is the following one.
Definition 8.
38 Any linguistic expression θ ∈ LE is associated with a set of subsets of S, denoted λ(θ) and defined recursively as follows,
- 1.
λ(si) = {Z ⊆ S|si ∈ Z}∀i = {0, …, g},
- 2.
λ(θ ∧ ϕ) = λ(θ) ∩ λ(ϕ),
- 3.
λ(θ ∨ ϕ) = λ(θ) ∪ λ(ϕ),
- 4.
- 5.
Example 3.
Some examples of linguistic expressions in LE generated from the linguistic term set S shown in Figure 1 could be the following ones:
¬good ∨ very good
medium ∧ good
3.2.2. Computational model
A fuzzy relation R = (rij)n×n is defined on S where the elements rij ∈ [0, 1] of R represent the degree of similarity between the linguistic terms si and sj. Therefore, rij is denoted as r(si, sj). A membership function ℱsi(·) = r(si,·) on S can be obtained for each si.
There is also a correspondence between fuzzy sets and consonant mass assignment functions 11.
Definition 9.
38 Let ℱsi be a membership function that achieves its value in {λ1, …, λz} such as 1 = λ1 > λ2 > … > λz ⩾ 0. A consonant mass assignment function msi for the membership function ℱsi can be obtained as follows,
And from the consonant mass assignment function msi, a membership function ℱsi could be obtained as follows,
This equation can be rewritten as the following one,
The fuzzy relation R on S can be generalized to the fuzzy relation R on LE.
Definition 10.
38 Let θ, ϕ ∈ LE be any two linguistic expressions, the degree similarity between θ and ϕ is defined recursively as follows,
- 1.
- 2.
Some properties of this computational linguistic model are defined in 38 to simplify the inference process for the fuzzy relation R on linguistic expressions.
3.2.3. Analysis of fuzzy relation based expressions
The linguistic expressions provided by this approach are more elaborated and flexible than previous one (Section 3.1), but their formalization is still far from common language used by decision makers in decision making, unless for mathematician experts that are familiar with logic expressions. Therefore, it can be very useful in some decision problems in which logic expressions are close to the decision makers and the solving process.
3.3. A fuzzy-set approach to treat determinacy and consistency of linguistic terms
As it has been previously mentioned Ma et al. 20 also pointed out that the use of predefined linguistic terms facilitates the elicitation of linguistic information, but it limits to decision makers to express their preferences freely, because they have to select one linguistic term from the predefined linguistic term set, that might not matching with his/her opinion, and he/she might think in several linguistic terms at the same time. Consequently, a new approach that increases the flexibility of the linguistic expressions allowing to use more than one linguistic term was proposed.
3.3.1. Representation model
This idea consists of decision makers provide their preferences on all the alternatives by using 0 or 1 for each linguistic term. Table 1 shows a general representation of such a model, where X = {x1, …, xn} is the set of alternatives, si ∈ S = {s0, …, sg} is the linguistic term set and ek ∈ E = {e1, …, em} is the set of decision makers. Therefore, vk,i(xr) = 1 means that the decision maker ek assigns the corresponding linguistic term si ∈ S to the alternative xr ∈ X, and 0 in otherwise. The selected linguistic terms are then used to generate synthesized comments.
| s0 | s1 | ··· | sg | synthesized comment | |
|---|---|---|---|---|---|
| x1 | vk,1(x1) | vk,2(x1) | ··· | vk,g(x1) | ck,1 |
| x2 | vk,1(x2) | vk,2(x2) | ··· | vk,g(x2) | ck,2 |
| ⋮ | ⋮ | ⋮ | … | ⋮ | ⋮ |
| xn | vk,1(xn) | vk,2(xn) | ··· | vk,g(xn) | ck,n |
Synthesized comments.
Example 4.
By using the linguistic term set depicted in Figure 1, a decision maker might provide the synthesized comments shown in Table 2.
| nothing | very bad | bad | medium | good | very good | perfect | Comment |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | Commonly |
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | Excellent |
Synthesized comments.
3.3.2. Computational model
The computational model of this linguistic approach is based on a fuzzy model and two novel concepts namely determinacy and consistency.
The concept of determinacy indicates the understandable degree that the decision maker has on the linguistic terms. For instance, if a decision maker provides his/her preference using only one linguistic term, it means that he/she is sure about the usage of the linguistic terms. However, if the decision maker uses more than one linguistic term, it is because of he/she cannot select one from the set. Formally, it is defined as follows.
Definition 11.
20 The determinacy of a linguistic term si ∈ S presented by a decision maker k ∈ E is,
The consistency is related to the rationality of the preferences provided by the decision makers. The linguistic terms obtained by the decision maker should be consistent, otherwise the final result might lead to wrong conclusions in the decision making problem.
Definition 12.
20 Let S be a set of linguistic terms and ℱsi, i = {0, …, g} be the corresponding fuzzy sets of si, the consistency of S is,
In order to represent the synthesized comments Ma et al. proposed a strategy similar to the voting strategy in data fusion 46 which uses the definitions of consistency and determinacy.
Definition 13.
Let xr an alternative, ek a decision maker, and S the linguistic term set that the decision maker uses to provide his/her opinions, the synthesized comment is,
The set of synthesized comments {Comk(xr) : k = 1, …, m} of all decision makers can be aggregated by using any aggregation operator defined in 14,13,46.
3.3.3. Analysis of expressions based on synthesized comments
This model is initially quite flexible and suitable to achieve the aim of modelling rich and flexible expressions for eliciting complex linguistic preferences because it allows to build expressions close to natural language used by experts in decision making. However, there is not any formal process or rule defined to fix the syntax of the synthesized comments obtained from multiple linguistic terms that makes this model hard to use in different decision situations with different decision makers chasing comparable results.
3.4. Linguistic distribution
Keeping in mind the proportional 2-tuple linguistic model presented by Wang and Hao 42, Dong et al. developed a generalization of such a model introducing the concept of distribution assessment 6.
3.4.1. Representation model
The representation of this model consists of assigning symbolic proportions to all the terms of the linguistic term set. To do so, the definition of distribution assessment is proposed.
Definition 14.
49 Let S = {s0, …, sg} be a linguistic term set, a distribution assessment, m, of S is defined as follows, m = {(si, βi)|i = {0, …, g}} where si ∈ S, βi ⩾ 0,
An example of the representation of this model is the following one.
Example 5.
Let’s suppose that 10 students has to evaluate to their teacher by using the linguistic term set S, depicted in Figure 1, two of them provide very good, five provide good and the remaining ones say bad. The evaluation could be defined using the following distribution assessment, {(nothing, 0),(very bad, 0),(bad, 0.3),(medium, 0), (good, 0.5),(very good, 0.2),(perfect, 0)}
3.4.2. Computational model
A computational model was also proposed to carry out operations with distribution assessments.
- 1.
A comparison law
To compare two distribution assessments, it was necessary to introduce the definition of Expectation.
Definition 15.
49 Let m = {(si, βi}, i = {0, …, g} where si ∈ S, βi ⩾ 0,
- •
If E(m1) < E(m2), then m1 is smaller than m2
- •
If E(m1) = E(m2), then m1 and m2 have the same expectation.
- 2.
A negation operator
- 3.
Aggregation operators of distribution assessments
Several aggregation operators to aggregate this type of information were defined in 49.
- 2.
Dong et al. also studied some consistency measures, such as additive and multiplicative consistency for a distribution linguistic preference relation 49, and they proposed a consensus model which identifies those distribution linguistic preference relations that less contribute to achieve the consensus level and modifies them until the consensus level is reached.
3.4.3. Analysis of expressions based on linguistic distributions
The linguistic distributions allow to keep linguistic information in a broad sense taking into account more than a single term in a similar but more complete way than the proportional 2-tuple (see Section 3.1). Hence its interpretability of the linguistic information is still far from common language used by decision makers in decision making problems despite it can be useful in managing computational processes for keeping as much information as possible.
3.5. Complex Linguistic Expressions based on Hesitant Fuzzy Linguistic Term Sets
The linguistic computing models revised previously try to use linguistic expressions richer than single linguistic terms, but some of them provide linguistic expressions far from the common language used by human beings in decision making problems or they do not explain how the linguistic expressions are built formally. Another linguistic model was proposed in 33 to construct complex linguistic expressions, based on the use of Hesitant Fuzzy Linguistic Term Sets (HFLTS) 33 that models decision maker’s hesitancy when elicits linguistic preferences. Such complex linguistic expressions not only achieve the improvements pointed out by Ma et al. 20, but also provide decision makers greater flexibility to express their preferences by means of context-free grammars that fix the rules to generate comparative linguistic expressions similar to the natural language used by decision makers in decision making problems.
3.5.1. Representation model
The following context-free grammar GH, generates comparative linguistic expressions suitable to provide preferences in decision making problems.
Definition 16.
34 Let GH be a context-free grammar and S = {s0, …, sg} a linguistic term set. The elements of GH = (VN, VT, I, P) are defined as follows:
VN = {⟨primary term⟩, ⟨composite term⟩, ⟨unary relation⟩, ⟨binary relation⟩, ⟨conjunction⟩}
VT = {lower than, greater than, at least, at most, between, and, s0, s1, …, sg}
I ∈ VN
P = {I ::= ⟨primary term⟩ | ⟨composite term⟩
⟨composite term⟩ ::= ⟨unary relation⟩ ⟨primary term⟩ | ⟨binary relation⟩ ⟨primary term⟩ ⟨conjunction⟩ ⟨primary term⟩
⟨primary term⟩ ::= s0|s1|…|sg
⟨unary relation⟩ ::= lower than|greater than|at least| at most
⟨binary relation⟩ ::= between
⟨conjunction⟩ ::= and}
The comparative linguistic expressions generated by GH cannot be straightforwardly used to make computations, therefore, they are transformed into HFLTS by means of a transformation function, EGH.
Definition 17.
33 Let S = {s0, …, sg} be a linguistic term set, a HFLTS, HS, is defined as an ordered finite subset of consecutive linguistic terms of S, HS = {si, si+1, …, sj} such that, sk ∈ S, k ∈ {i, …, j}
The transformation function EGH, was defined as follows.
Definition 18.
33 Let EGH be a function that transforms comparative linguistic expressions, ll, obtained by GH, into HFLTS, HS, where S is the linguistic term set used by GH and Sll is the set of linguistic expressions generated by GH,
The comparative linguistic expressions generated through the context-free grammar GH, are transformed into HFLTS by using the following transformations:
- •
EGH (si) = {si|si ∈ S}
- •
EGH (at most si) = {sj|sj ∈ S and sj ⩽ si}
- •
EGH (lower than si) = {sj|sj ∈ S and sj < si}
- •
EGH (at least si) = {sj|sj ∈ S and sj ⩾ si}
- •
EGH (greater than si) = {sj|sj ∈ S and sj > si}
- •
EGH (between si and sj) = {sk|sk ∈ S and si ⩽sk ⩽ sj}
Example 6.
By using the context-free grammar GH, and the linguistic term set shown in Figure 1, some comparative linguistic expressions might be,
ll1 = between medium and very good
ll2 = at least bad
The transformation of these comparative linguistic expressions into HFLTS are,
EGH (between medium and very good) = {medium, good, very good}
EGH (at least bad) = {nothing, very bad, bad}
3.5.2. Computational model
Different computation models can be used to operate with HFLTS depending on its representation, such as an envelope that is an interval value 33 or the fuzzy envelope 19. Due to the interest in fuzzy based representations of this paper the fuzzy envelope is revised:
Definition 19.
19 Let HS = {si, si+1, …, sj} be a HFLTS, so that sk ∈S = {s0, …, sg}, k ∈ {i, …, j}.
The concept of fuzzy envelope envF(HS) of an HFLTS facilitates the CW processes with HFLTS 19 because it represents the comparative linguistic expressions by means of a fuzzy membership function obtained of aggregating the linguistic terms that compound the HFLTS and hence the computations can be carried out by the Extension Principle 25 (see Section 2.3.1).
3.5.3. Extension of Hesitant Fuzzy Linguistic Term Sets
Recently, the concept of HFLTS has been extended to use non-consecutive linguistic terms 40. This generalization is called Extended Hesitant Fuzzy Linguistic Term Set (EHFLTS) and it is defined as follows.
Definition 20.
40 Let S be a linguistic term set, a EHFLTS is an ordered subset of linguistic terms of S, such that,
This extension was proposed to fuse the preferences provided by different decision makers by using the union operation. The idea consists of combining the HFLTS provided for each decision maker to obtain a EHFLTS that represent the collective preference of the group. Several aggregation operators for EHFLTS have been defined in 40.
Note that this model deals with multiple linguistic terms, but does not provide linguistic expressions similar to the common language.
3.5.4. Analysis of complex linguistic expressions based on HFLTS
It is clear that the comparative linguistic expressions generated by GH and represented by HFLTS provide an important flexibility to decision makers when eliciting preferences, together a clear formalization of the way of generating expressions that could be close to the expressions used by human beings in decision making depending on the grammar used for such a generation.
4. Challenges and Future in Modelling Complex Linguistic Preferences
The management of uncertain and vague information is always hard and complex, therefore the modelling of information in such an environment presents important difficulties that the fuzzy linguistic modelling has tackled successfully in many decision situations. However, it is clear that the use of simple fuzzy linguistic preferences composed by a single term is not always suitable to represent the real preferences of the decision makers.
Across this paper it has been shown different proposals to model linguistic preferences by means of more elaborated expressions than a single linguistic term. It is easy to observe that each different proposal treats the preference modelling from very different perspectives, all of them quite interesting in specific decision situations. However, despite the different linguistic modelling proposals for complex linguistic preferences introduced in the specialized literature, it seems necessary a further research looking for some aspects that have not been considered yet:
- •
Some proposals are very flexible to construct linguistic expressions such as in Sections 3.3 and 3.4, but there is not formal processes to build expressions either are far from common language. However, other proposals as comparative linguistic expressions (Section 3.5) are well formalized by means of context-free grammars, but are not so rich as previous ones. Hence, it is important to keep working on proposals able to keep features of the latter and increase its flexibility as the former. Maybe a way to do that, it will be the use of richer grammars than context-free grammars 4,15.
- •
So far, most of problems dealing with uncertain information have applied a determined technique to model and manage such a uncertainty. However, it is clear that in real world problems the use of only one technique is not realistic, because of multiple perspectives in which a problem can be solved, hence further research on the use of multiple linguistic modelling proposals to model complex linguistic preferences could suit better different real-world decision problems. Therefore, another important challenge to deal with complex linguistic information in uncertain decision making problems, is the development of hybrid modelling and computing proposals to improve the results, such hybridization could include the interoperability among different types of expressions and their computational models.
- •
Across this overview the proposals revised aim at providing richer and more flexible syntax to decision makers, for eliciting their knowledge, based on a fuzzy semantics. All of them provide a unique meaning for the complex expressions elaborated with each approach, however in CW literature it has been thoroughly discussed that words means different things for different people 25,29,36 because of different reasons. Therefore, the current approaches for eliciting linguistic complex expressions should consider this fact and provide mechanisms for representing and managing those different meanings for the linguistic expressions in the problems. Maybe this challenge can be initially tackled by integrating the view of multi-granular linguistic scales and later on by researching on the use of type-2 fuzzy sets. Other approaches and ideas can enrich previous ideas for this challenge.
Even though, there would be other challenges to point out, the previous ones could be the most interesting ones from a decision making and decision analysis point of view.
5. Conclusions
The need to model linguistically preferences in complex decision problems has led to many ways of linguistic modelling and computational approaches in which fuzzy based approaches play a key role. However, most of these approaches provide a priori fixed vocabularies that decision makers are forced to use for eliciting their preferences and usually in a very simple way. To overcome this drawback the ability to generate flexible and complex linguistic expressions to elicit preferences has been recently researched. An overview of the most important fuzzy proposals to deal with this type of preferences has been provided in this paper and pointed out the different points of view used in each proposal to model these complex preferences. Eventually some challenges have been introduced for further research.
Acknowledgments
This work is partially supported by the Spanish National research project TIN2015-66524-P, Spanish Ministry of Economy and Finance Postdoctoral Training (FPDI-2013-18193) and ERDF.
References
Cite this article
TY - JOUR AU - Rosa M. Rodríguez AU - Álvaro Labella AU - Luis Martínez PY - 2016 DA - 2016/04/01 TI - An Overview on Fuzzy Modelling of Complex Linguistic Preferences in Decision Making JO - International Journal of Computational Intelligence Systems SP - 81 EP - 94 VL - 9 IS - Supplement 1 SN - 1875-6883 UR - https://doi.org/10.1080/18756891.2016.1180821 DO - 10.1080/18756891.2016.1180821 ID - Rodríguez2016 ER -