
Soft Sensor Modeling Method by Maximizing Output-Related Variable Characteristics Based on a Stacked Autoencoder and Maximal Information Coefficients
- DOI
- 10.2991/ijcis.d.190826.001How to use a DOI?
- Keywords
- Soft sensor; Deep learning; Stacked autoencoder (SAE); Maximal information coefficient (MIC); Modeling method
- Abstract
The key factors required to establish a precise soft sensor model for industrial processes include selection of variables affecting vital indicators from a large number of online measurement variables and elimination of the effects of unrelated disturbance variables. How to compress redundant information and retain the unique characteristic information contained by the selected variables is worthy of in-depth research. A novel soft sensor modeling method based on weighted maximal information coefficients (MICs) and a stacked autoencoder (SAE), hereinafter referred to as MICW-SAE, is proposed in this work. In our model, the MICs between each input and output variable are calculated and compared with the threshold before training each network in SAE. Then, input variables with low MICs are selected, and the average MIC index is calculated using other input variables. If the index is higher than the second threshold, the MIC of this specific variable is set to 0. Finally, the weights of all input variables are determined in accordance with the scale and placed into the loss function for training. The Boston house-price and naphtha dry point temperature datasets are used to prove the prediction ability of our model. Results demonstrate that MICW-SAE can enhance the output-related features of the input variables. Moreover, redundant information that can also be represented by other input variables are identified and excluded.
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Demands for industrial process control are increasing with the flourishing development of modern industry [1]. Since process variables are often highly related to the quality of the final product, controlling these variables in a timely and precise manner is important. In a typical process, some variables are key indicators of process performance. However, most variables are difficult to measure due to several issues, including economic problems, environmental harshness, technical constraints, and severe time-delay. Soft sensor technology is often used to solve such problems [2,3]. Soft sensor technology allows accurate and real-time online measurement of variables dominant to a process, thereby rendering stable process control and ensuring the quality and economic benefits of industrial products. Thus, soft sensors are an important research field in modern control.
Soft sensor modeling methods are of three types, namely, first-principles models (FPMs), data-driven models, and mixed models (combination of FPMs with data-driven models). FPMs require prior knowledge of the mechanism of process objects and usually need to idealize and simplify some of the processes. Thus, implementation of FPMs to complex industrial processes is difficult. By contrast, data-driven models do not need detailed mechanistic information of the process during modeling as they only utilize the sample data from an industrial process to describe its state. Therefore, data-driven models are widely used in industrial processes [4]. A number of data-driven modeling methods are available, and these methods are mainly divided into two categories. One is based on multivariate statistical algorithms, including principal component regression (PCR) [5] and partial least-squares regression (PLS) [6], and the other is based on statistical machine learning algorithms, such as support vector regression (SVR) [7], genetic algorithm (GA) [8], and artificial neural network (ANN) [9]. Although these algorithms can be applied to various fields, some problems, such as those related to robustness and accuracy, still exist in the soft sensor modeling process. ANN has become an important modeling tool for soft sensors, but it only allows shallow learning, which presents a single hidden layer, and easily falls into a local optimum or undergoes gradient diffusion. Establishing an accurate and effective estimation model is a key endeavor in soft sensor modeling processes. Bengio et al. [10] proved that deep learning, a branch of machine learning, can overcome these complex problems well.
Deep learning, which was first proposed by Hinton and Salakhutdinov [11], is a data analysis and processing method. In recent years, it has received increased attention and gradually become a key research area of artificial intelligence [12]. Convolutional neural network (CNN), recurrent neural network (RNN), deep autoencoder (DAE), long short-term memory network, and deep belief network (DBN) are considered deep learning algorithms. Initially, deep learning was applied to the fields of image identification [13–16] and natural language processing [17–19]. Today, it is also gradually applied on process monitoring and modeling prediction [20–23]. Zhu et al. [24] issued a novel prediction method based on DBN that used linear regression as the final layer of its general structure. This model could examine the nonlinear and unstable features of internal valve leakage signals. Yan et al. [25] proposed a novel soft sensor modeling method that combines denoising autoencoders with a neural network (DAE-NN). In contrast to shallow learning methods, DAE-NN could remarkably improve the robustness and performance of predictions of the oxygen content in flue gasses in 1000 MW ultrasuperficial units. Despite their many benefits, however, these existing methods place all input variables into the network for training and barely consider the correlation between variables. Thus, even unimportant variables, which contribute to prediction errors, are treated equally when training the model.
Some works considering weighted features in deep neural networks have been reported. Yu and Yan [26] monitored and enhanced the layer-wise abnormal fluctuation information extracted by DBN to prevent this information from vanishing during the training process. The enhancement degree was determined by the fluctuation degree. The enhanced features showed the current working status by integrating support vector data, moving average filter, and kernel density estimation techniques, and the resulting method improved the detectability and performance of the Tennessee Eastman benchmark process. Yuan et al. [27] developed a soft sensor modeling with a variable-wise weighted stacked autoencoder (VW-SAE). This model considered the linear correlation between independent and dependent variables measured by the Pearson correlation coefficient before training. Application to estimations of butane content showed that this model achieves higher accuracy than three other methods. The method proposed by Yuan et al. [27] only calculated the linear correlation between independent and dependent variables. In fact, however, input and output variables are often highly nonlinearly correlated in the practical industrial process. The Pearson correlation coefficient cannot describe the nonlinear correlation between variables well. Although some variables are given relatively small weights, these variables and their effects on the output still exist during training. Furthermore, the number of variables collected at each sampling point may be massive during the industrial process, but not all input variables are useful or have a significant influence on the output variables due to differences in physical or chemical mechanisms. Thus, filtering redundant information while retaining unique feature information contained by other variables relevant to the output is particularly important.
Our work aims to uniformly select input variables and measure the relationships between them before training the network. We propose a novel SAE soft sensor modeling method based on maximal information coefficients (MICs) weighted between variable, hereinafter referred to as MICW-SAE. In this new model, the MIC between each input and output variables is initially calculated. If the MIC of one independent variable is lower than the threshold, the average MIC between this and the other variables is calculated. Whether this MIC must be changed to 0 is determined by comparing this average MIC and the second threshold. Thereafter, weights are proportionally assigned according to the adjusted MIC and added as a multiplier to the loss function of each autoencoder in SAE. The regression portion of this model is a simple ANN. Finally, the pre-training and fine-tuning processes are carried out as usual.
The rest of this study is organized as follows. First, a brief review of SAE and MIC is introduced in Section 2. Section 3 provides the detailed descriptions of our proposed method. Then, the Boston house-price dataset is used as a benchmark dataset to verify the effectiveness of our proposed method in Section 4. Following this step, our method is validated on the predicted output of naphtha dry points during the practical industrial process in Section 5. Finally, Section 6 draws our conclusions.
2. RELATED WORK
The concepts and basic algorithms of autoencoder (AE), SAE, and MIC are briefly reviewed in this section to introduce our proposed method in detail.
2.1. AE and SAE
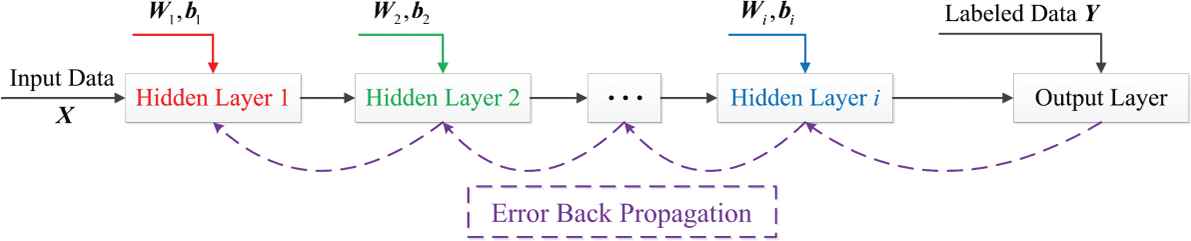
AE, which was first proposed by Rumelhart in 1986, is a typical unsupervised machine learning method [28]. Hinton and Salakhutdinov [11] improved the structure of the original AE and introduced the concept of DAE. In DAE, the unsupervised layer-by-layer greedy training algorithm is first applied to complete the pre-training of the hidden layer. Then, the back-propagation (BP) algorithm is used to optimize the system parameters of the whole network, which can greatly improve the learning ability of the network and effectively solve the problem of local optimum observed in neural networks. This training mechanism has been widely used in deep learning.
In general, a three-layer neural network constitutes a common AE. In contrast to ANN, AE aims to reproduce input signals. Figure 1 shows the schematic structure of AE. The unlabeled sample dataset is assumed to be

Schematic structure of autoencoder (AE).
The transformation process from the hidden layer to the output layer is called the decoding portion and used to reconstruct the input signal. The reconstructed signal can be expressed as
To make the input and output as equal as possible, AE uses the reconstructed error as a loss function, which can be described as:
SAE, which is an improved model of AE, was first developed by Bengio et al. [10] The training mechanism of SAE is divided into two steps: Layer-wise greedy unsupervised pre-training and supervised fine-tuning. First, SAE abandons the decoding portion of AE and only extracts the feature information obtained by AE. This feature information can represent the original information within the tolerance of the error, and, thus, the reconstructed process can be removed. Moreover, the extracted feature can be compressed once more by another AE. The AE in SAE is connected layer by layer. In other words, the feature achieved by the previous AE is the input signal of the next AE, which can be expressed as:

Structure of stacked autoencoder (SAE).
Training procedure of the fine-tuning.
2.2. Maximal Information Coefficient
MIC, which was proposed by Reshef et al. [29], measures the dependence between variables. The calculation process of MIC aims to find the maximal grid resolution of all grids by meshing the scatterplot of two sets of variables. A labeled dataset is denoted as
Suppose the number of grids is less than
MIC highlights an excellent characteristic, that is, as the number of samples increases, the MIC score approaches 1 with probability 1, regardless whether the relationship between variables is a never-constant noiseless functional relationship or a larger class of noiseless relationships. Moreover, the MIC approaches 0 for statistically independent variables. The use of MIC to mathematically measure the association between variables causes the MIC score to be concentrated at both ends of the [0, 1] range, which improves the ability of the model to distinguish the relationship of data because the association between variables is a binary relationship [30]. Consequently, compared with other traditional correlation coefficients, such as Pearson, Spearman, and MI, MIC can better identify different relationship types [29].
3. METHODOLOGY
The layer-wise greedy pre-training and fine-tuning process can effectively solve the problems of neural networks easily falling into local optimum and gradient diffusion. Despite the powerful ability of SAE to extract the features of the original input data, irrelevant information in the output is still added to the network during the pre-training process if the input data are not judged by importance. In addition, the model developed by Yuan et al. [27] only considered the linear relationship between variables. In practical industrial processes, the mathematical relationship between variables is highly nonlinear and cannot be identified using Pearson or other traditional statistical correlation coefficients. MIC presents the advantage of describing both linear and nonlinear relationships. Simultaneously, although most independent variables have a strong mathematical functional relationship to the dependent variables, still there are some relatively minor independent variables that have a slight impact on the output signals. Those variables should be filtered to eliminate their impact on reducing the prediction accuracy.
As a result, we combined MIC with SAE to build a novel soft sensor modeling method. Assume the existence of a labeled dataset
Finally, the weights are added to the loss function as a multiplier to train the network. Each AE in SAE will conduct this mechanism during pre-training and fine-tuning. The loss function is modified from Eq. (4) to:
Figure 4 presents the MICW-SAE structure. MICs naturally represent the correlation between the feature extracted from the previous AE and the labeled data since the second AE when pre-training, which means this mechanism of weighted MICs only targets the input signals of the current AE and the labeled data. By executing this step before pre-training, the primary variables directly affecting the output are gradually strengthened by the training progress due to the presence of large weights; secondary variables are gradually lost. Ultimately, the features abstracted by SAE for regression contain rich and valuable information representing the original input signal. Similarly, the variables must be weighted before fine-tuning.

Structure of maximal information coefficient-stacked autoencoder (MICW-SAE).
To conclude, the MICW-SAE algorithm is conducted in a stepwise manner:
The thresholds are denoted as
The MIC of the
If
If
The labeled dataset is normalized to
The aforementioned steps are carried out during layer-wise greedy pre-training and fine-tuning. Eq. (11) is used as the new loss function of all AEs in SAE and the whole fine-tuning network. Thereafter, the performance of soft sensor model is tested.
The flow chart in Figure 5 demonstrates our proposed modeling algorithm intuitively. The regression portion of MICW-SAE is a two-layer simple neural network. Two indicators, namely, the root mean squared error (RMSE) and the regression index

Flow chart of maximal information coefficient-stacked autoencoder (MICW-SAE).
4. EXPERIMENT AND RESULTS OF THE BOSTON HOUSE-PRICE DATASET
In this example, we take the Boston house-price dataset, which is available online in the sklearn library, as a benchmark dataset to verify the effectiveness of MICW-SAE. Benchmark data sets are generally used to illustrate the performance of the algorithm. The Boston house-price dataset contains 13 variables affecting the output, namely, average house-prices in Boston [31]. A total of 506 samples are included in this dataset. After random disruption, the numbers of training, valid, and test datasets are 323, 81, and 102, respectively.
The program is written in Python and run on a computer with an Intel Core i5-4590 (3.3 GHz) processor and 4 GB storage. MICW-SAE consists of three AEs, the hidden nodes of which number 7, 5, 3. The thresholds

Results of estimation of the Boston house-price dataset by maximal information coefficient-stacked autoencoder (MICW-SAE).

Plot of the prediction absolute errors by maximal information coefficient-stacked autoencoder (MICW-SAE) (Boston Dataset).

Histogram of the prediction absolute errors by maximal information coefficient-stacked autoencoder (MICW-SAE).
For comparison, four modeling methods based on machine learning, including partial least square (PLS), SVR, multi-layer ANN (M-ANN), and eXtreme Gradient Boosting (XGBoost) proposed by Chen and Guestrin [32] are applied to the same dataset. Moreover, three deep learning methods based on SAE (without weighted MICs), VW-SAE [27] as mentioned above and SAE-MIPCA-NN proposed by Wang and Yan [33] are also imported as comparative experiments. XGBoost, which is an extension of the Gradient Boosting Decision Tree (GDBT), has shown its good regression ability in various data mining competitions. The parameters are set as follows in this experiment: the max depth is 5, the learning rate is 0.1 and the number of trees is 20. SAE-MIPCA-NN uses principle component analysis (PCA) to extract the raw data and features weighted with MI above the threshold from each AE, and then regressed by ANN. The parameter setting method of this parallel experiment is the same as that of Wang and Yan [33]. As a result, the number of extracted components is eight. Additionally, because SVR does not require a valid dataset, the valid and training datasets are merged to train the SVR model in the experiments. The kernel function of SVR is the Gaussian radial basis function
| Model | MICW-SAE | PLS | SVR | XGBoost | M-ANN | SAE | VW-SAE | SAE-MIPCA-NN |
|---|---|---|---|---|---|---|---|---|
| RMSE | 0.083223 | 0.129535 | 0.094930 | 0.095231 | 0.114164 | 0.098563 | 0.098805 | 0.095944 |
| 0.917145 | 0.768137 | 0.885209 | 0.889115 | 0.824841 | 0.871915 | 0.895120 | 0.890171 |
RMSE and
5. APPLICATION ON ATMOSPHERIC COLUMN
In this section, MICW-SAE is validated on a practical atmospheric column process. A description of this industrial process is first provided in Section 5.1. Next, an experiment to predict the naphtha dry point temperature is conducted, and seven regression modeling methods are used for comparison. Finally, an analysis and a discussion of the experiment results on the changing in the thresholds, the loss function value and reconstruction error are given.
5.1. Description of Atmospheric Column
Figure 9 shows a simple flow chart of an atmospheric column unit. The atmospheric column has 60 column plates. After heating by an atmospheric pressure kiln, the crude oil enters the fractionation distillation tower, and the top of the tower is driven into a cold reflux, which controls the temperature to approximately 120 °C. The temperature gradually increases from the top of the tower to the feeding section. Given different boiling point ranges, the gasoline vapor and steam are distilled from the top of the tower. Kerosene, light diesel oil, and heavy diesel oil are separately distilled from the No. 1, No. 2, and No. 3 side-streams, respectively [34]. The product at the top of the tower enters the reflux accumulator through the heat exchanger and condenser. Then, the product is pumped out by an atmospheric overhead pump. Part of the product is refluxed at the top of the tower, and another part is collected as the final product, naphtha. Naphtha is the distillate product obtained after the first step of crude oil distillation. The quality index of naphtha, as a raw material of the subsequent product, is an important consideration. However, the measurement accuracy of the naphtha dry point temperature is not ideal due to the large number of side-streams and complicated structure of the system, the diverse crude oil composition, and the high nonlinearity between variables. Thus, building a prediction model that can reliably estimate the naphtha dry point temperature and quality is essential. MICW-SAE is tested on this complex industrial process.

Flow chart of the atmospheric column.
5.2. Experiment on the Naphtha Dry Point Dataset
A total of 150 samples in the naphtha dry point dataset are collected from practical industrial processes. Table 2 provides a detailed description of each variable in this dataset. All samples are randomly disrupted, similar to the previous experiment. After normalization, the test dataset is composed of 30 samples; 120 samples are used as the training dataset, from which 24 samples are extracted as the valid dataset to monitor the training process. The batch size is set as 24 samples through the trial-and-error method. The thresholds

Maximal information coefficients (MICs) between input variables and output.
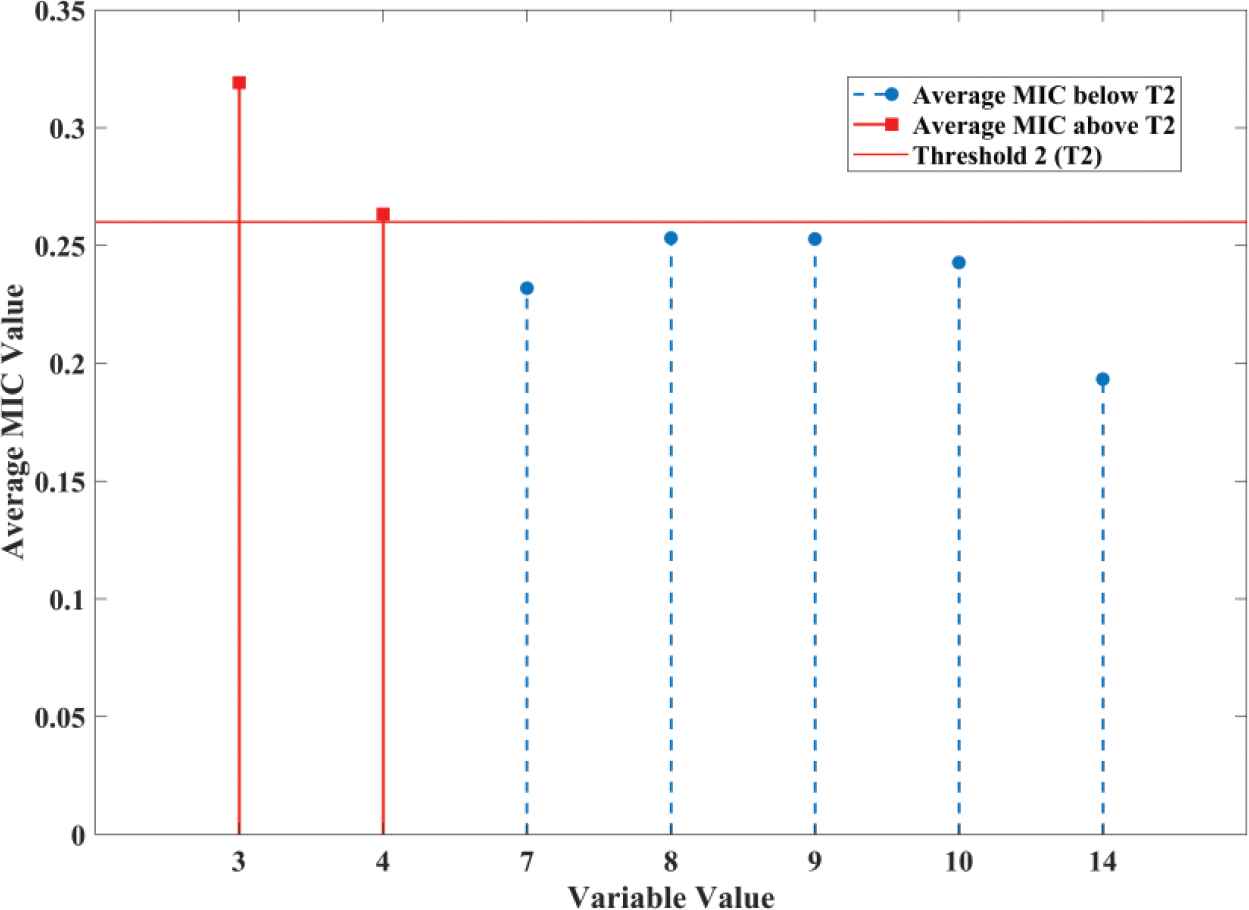
Average maximal information coefficients (MICs) of x(i) below T1.
| No. | Variable Description |
|---|---|
| 1 | Total exit temperature |
| 2 | Total flow |
| 3 | Temperature at tower top |
| 4 | Pressure at tower top |
| 5 | Pumparound Energy at tower top |
| 6 | Product flow at tower top |
| 7 | Flow of light diesel oil |
| 8 | No.1 side-stream |
| 9 | No.2 side-stream |
| 10 | No.3 side-stream |
| 11 | Energy brought by circulation at top tower |
| 12 | Energy of No.1 mid-pumparound |
| 13 | Energy of No.2 mid-pumparound |
| 14 | Vaporization temperature |
| 15 | Stripping steam flow |
| 16 | Previous value of naphtha dry point |
Description of each variable in the naphtha dry point dataset.
| Variable No. | Weight |
|---|---|
| 0.071943 | |
| 0.069409 | |
| 0 | |
| 0 | |
| 0.075694 | |
| 0.103963 | |
| 0.050637 | |
| 0.034854 | |
| 0.053006 | |
| 0.054964 | |
| 0.084609 | |
| 0.085078 | |
| 0.072433 | |
| 0.054684 | |
| 0.064075 | |
| 0.124650 |
Weights of each variable in the naphtha dry point dataset.

Plot of the prediction absolute errors by maximal information coefficient-stacked autoencoder (MICW-SAE) (Naphtha Dry Point Dataset).
The same training, valid, and test datasets are used with the seven other models, and the rules for setting the training dataset and parameters in these models are identical to those in the previous experiment. The radial basis function is still applied to SVR
| Model | RMSE | MARE | Performance Increase (MARE) | |
|---|---|---|---|---|
| MICW-SAE | 0.161319 | 0.560128 | 0.043065 | / |
| PLS | 0.167904 | 0.490067 | 0.047862 | 10.02% |
| SVR | 0.174369 | 0.466648 | 0.047105 | 8.58% |
| XGBoost | 0.171400 | 0.491696 | 0.053284 | 19.18% |
| M-ANN | 0.173193 | 0.217630 | 0.052893 | 18.58% |
| SAE | 0.177296 | 0.451228 | 0.052668 | 18.23% |
| VW-SAE | 0.165601 | 0.514201 | 0.045435 | 5.22% |
| SAE-MIPCA-NN | 0.164790 | 0.523348 | 0.046048 | 6.48% |
RMSE,
5.3. Analysis
To compare the performance of models comprehensively, the maximal absolute relative error (MARE) indicator is imported to assess the predicted point with the maximum error of model. MARE is defined as follows:
According to Table 4, the prediction accuracies of the tested model can be ranked in the order of MICW-SAE > SAE-MIPCA-NN > VW-SAE > XGBoost > PLS > SVR > SAE > M-ANN. In addition, MICW-SAE can increase
The original 16-dimensional data are all directed toward the other seven soft sensor models for training, which results in training of negligible information. By contrast, after weight assignment and extraction by MIC, the weights of only two input variables are set to 0 and 14 variables are retained. Useless information is filtered out by the proposed mechanism. During the training process, valuable information is further magnified layer by layer because of the existence of weights. In contrast, these two useless features are trained by VW-SAE, which leads to those invalid information being considered during the training process. Thus, the error of the test dataset by MICW-SAE is relatively lower.
Although SAE-MIPCA-NN performs better than VW-SAE in the second datasets, the former method has a larger prediction error for some sample points than the latter, which reflects on the lower MARE of VW-SAE. The mechanism of SAE-MIPCA-NN is to preserve the original data and the features extracted by each AE. Then, PCA is imported to select the components from all the weighted features calculated by MI above the threshold. If the number of original input variables or AEs in SAE becomes larger, the workload will be greatly increased. The calculation time and calculation cost will be increased as well. To conclude, VW-SAE only enhances the useful information related to the labeled data, but does not consider the interference of the useless one. MICW-SAE and SAE-MIPCA-NN both aim for the extraction of useful information but MICW-SAE proposed in this paper is not only simpler but also have a higher precision.
5.4. Discussion
During the experiment process, the thresholds
On the other hand, when
| RMSE | Number of Train/Total Variables | ||
|---|---|---|---|
| 0.115486 | 0.822850 | 6 / 13 | |
| 0.095972 | 0.881375 | 13 / 13 | |
| 0.083223 | 0.917145 | 12 / 13 | |
| 0.096463 | 0.879099 | 13 / 13 | |
| 0.088135 | 0.901740 | 11 / 13 |
RMSE and
| RMSE | Number of Train/Total Variables | ||
|---|---|---|---|
| 0.188237 | 0.442012 | 9 / 16 | |
| 0.165230 | 0.517732 | 16 / 16 | |
| 0.161319 | 0.560128 | 14 / 16 | |
| 0.165026 | 0.528801 | 15 / 16 | |
| 0.174754 | 0.455374 | 12 / 16 |
RMSE and
Furthermore, we investigated the reconstruction error of the different neural network models in the same batch size case. Figure 13 demonstrates the learning error of MICW-SAE, VW-SAE and SAE during fine-tuning within 200 epochs. SAE produces the highest learning errors among three methods surveyed at first because its loss function is without weights. Leading-in of the weighted process allows the variables in the VW-SAE and MICW-SAE models to be multiplied by

Loss function values of the three models.
| SAE | VW-SAE | MICW-SAE | |
|---|---|---|---|
| Loss function value | 0.004084 | 0.000171 | 0.000194 |
| Reconstruction error | 0.004084 | 0.004865 | 0.010889 |
Reconstruction errors of the first AE in MICW-SAE and SAE.
6. CONCLUSION
A novel soft sensor modeling method called MICW-SAE is developed in this article. Before pre-training and fine-tuning, the relationship between input and output variables is first measured by MIC and compared with the threshold
CONFLICT OF INTEREST
We wish to confirm that there are no known conflicts of interest associated with this publication and there has been no significant financial support for this work that could have influenced its outcome.
We confirm that the manuscript has been read and approved by all named authors and that there are no other persons who satisfied the criteria for authorship but are not listed. We further confirm that the order of authors listed in the manuscript has been approved by all of us.
We confirm that we have given due consideration to the protection of intellectual property associated with this work and that there are no impediments to publication, including the timing of publication, with respect to intellectual property. In so doing we confirm that we have followed the regulations of our institutions concerning intellectual property.
We understand that the Corresponding Author is the sole contact for the Editorial process (including Editorial Manager and direct communications with the office). He/she is responsible for communicating with the other authors about progress, submissions of revisions and final approval of proofs. We confirm that we have provided a current, correct email address which is accessible by the Corresponding Author and which has been configured to accept email from xfyan@ecust.edu.cn.
AUTHORS' CONTRIBUTIONS
We promise that all listed authors, named Yanzhen Wang and Xuefeng Yan, made substantial contributions to the conception or design of the work; or the acquisition, analysis, or interpretation of data for the work. And both listed authors drafted the work or revised it critically for important intellectual content and gave final approval of the version to be published. Wang and Yan agreed to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
The specific contribution that each Author made to the article is listed as follows:
Yanzhen Wang: literature search, study design, manuscript writing, data analysis.
Xuefeng Yan: guidance on experimental design, guidance on experimental ideas, data provider, manuscript revision, paper submission.
Funding Statement
The authors are grateful for the support of National Natural Science Foundation of China (21878081), Fundamental Research Funds for the Central Universities under Grant of China (222201717006), and the Program of Introducing Talents of Discipline to Universities (the 111 Project) under Grant B17017.
We also declare that the funding source(s) had no involvement in the work beyond providing a financial contribution.
ACKNOWLEDGMENTS
The authors are grateful for the support of National Natural Science Foundation of China (21878081), Fundamental Research Funds for the Central Universities under Grant of China (222201917006), and the Program of Introducing Talents of Discipline to Universities (the 111 Project) under Grant B17017.
REFERENCES
Cite this article
TY - JOUR AU - Yanzhen Wang AU - Xuefeng Yan PY - 2019 DA - 2019/09/06 TI - Soft Sensor Modeling Method by Maximizing Output-Related Variable Characteristics Based on a Stacked Autoencoder and Maximal Information Coefficients JO - International Journal of Computational Intelligence Systems SP - 1062 EP - 1074 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.190826.001 DO - 10.2991/ijcis.d.190826.001 ID - Wang2019 ER -