
A New F-Test Applicable to Large-Scale Data
- DOI
- 10.2991/jsta.d.191217.001How to use a DOI?
- Keywords
- Microarray data; Permutation test; Null statistic; F-test
- Abstract
In large-scale multiple testing, the permutation test based on making a null statistic has been widely employed in the literature. Because it enables us to use the null permuted samples and estimate the
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
In some experimental scientific fields such as microarray and deep sequencing (or next generation sequencing) methods in biology, the numbers of features (probe sets) is huge while the number of samples is limited to perhaps only two or three. Nearly all features are numeric, showing the values of gene expressions between control and other groups, and finding differentially expressed genes between those groups is of great interest. Such data refer to large-scale data.
Traditional approaches to multiple testing under a null hypothesis, the equality of means in different groups, can lead to inaccurate decisions, particularly in the context of many tests and small sample sizes. These poor decisions can arise for a number of reasons, including the detection of spurious significant differences, asymmetry in the distribution of alternatives [1], and failure of assumptions about the normality of the underlying random variables. In this situation, employing the permutation method to estimate the
However, as the sample size is small, the number of permutation samples is reduced and the estimation of an appropriate
To overcome this obstacle one can use the null statistic. The null statistic is a modified test statistic from the initial test statistic with the same distribution. Some methods based on deriving a null statistic have been constructed for the analysis of two groups, e.g., see [4,12]. However, in many cases, interest may center on three or more groups. For instance, in microarray analysis introduced by [13–15], three groups were used to describe the expression value of many genes.
Some researchers have proposed three-stage filtrations, which reduce the number of comparisons and then use one-way analysis of variance (ANOVA) to identify the differentially expressed genes on filtered genes or features, see [13], and also [16,17]. Applying one-way ANOVA and calculating the
We organize the paper as follows: In Section 2, we review the Fisher test, the usual permutation test for the one-way ANOVA, and the estimation of the
2. F
When we have three independent groups or more and we are going to test the null hypothesis, equality of means, versus the alternative hypothesis, different means, we usually use the well-known one-way ANOVA method, under the assumption of normally distributed, independent random samples in each group. When the normality assumption is not satisfied, we can use the permutation method instead. In this section, we review these methods briefly. In addition, we present a method for estimating the
2.1. Multiple Testing Problems
In this paper, we deal with multiple hypothesis testing with
A common test statistic, which is used for testing the hypotheses (1) is the Fisher test, [21], as follows:
In the usual permutation approach described by [22], one constructs (2) by randomly permuting
Denote the permuted elements of
2.2. Estimated p
Suppose that we decide to reject the null hypothesis
In large-scale data like microarray data, we can use the information of other genes to estimate the
(3) and (4) involve the use of information about a lot of genes, and it is unknown if the null hypothesis holds for them. [11] and [4] suggest the usage of the null statistic instead of the main test statistic. The null statistic,
Therefore, one can estimate the
3. PROPOSED METHOD
We propose a new permutation test statistic for hypothesis testing (1), such that it can be modified to a null statistic. The
Constructing the test statistic and its null statistic: Consider
We want to test the hypotheses (1).
Theorem 3.1.
Under the normality assumption for
Proof.
Let
Since
It can be shown that
Remark 3.1.
It follows, from Theorem 3.1, that for testing the null hypothesis in (1), the test statistic
The critical value, called
Theorem 3.2.
Proof.
Since the denominator of
4. RESULTS
This section is organized into two parts. In the first subsection, the robustness of the proposed test statistic,
4.1. Simulated Data
Robustness of the new test statistic: The condition (5) is convinced under the normality condition by Theorem 3.2. Considering some candidates for the underlying distribution of the random sample, we investigate if the proposed test statistic,
Without loss of generality, take
| Sample Sizes |
|||
|---|---|---|---|
| Candidate Distribution | Family Parameter | ||
| 4 | 0.723 | 0.952 | |
| 10 | 0.281 | 0.569 | |
| 15 | 0.992 | 0.872 | |
| 25 | 0.792 | 0.958 | |
| Logistic |
0.204 | 0.569 | |
| Laplace |
0.339 | 0.640 | |
AD, Anderson–Darling; The null hypothesis is that two samples come from the common distribution.
The estimated
Let
Remark 4.1.
When we consider no effect in the groups, the labels assigned subject to the groups are interchangeable. Therefore, for each permuted sample, the homogeneity of variance must be tested.
Considering the above remark, when we permute a sample, randomly, and divide it into two partitions, some of the obtained permutation samples will display substantive heterogeneity of variances. These so-called extraneous permutation samples (EPSs) should be removed before computing
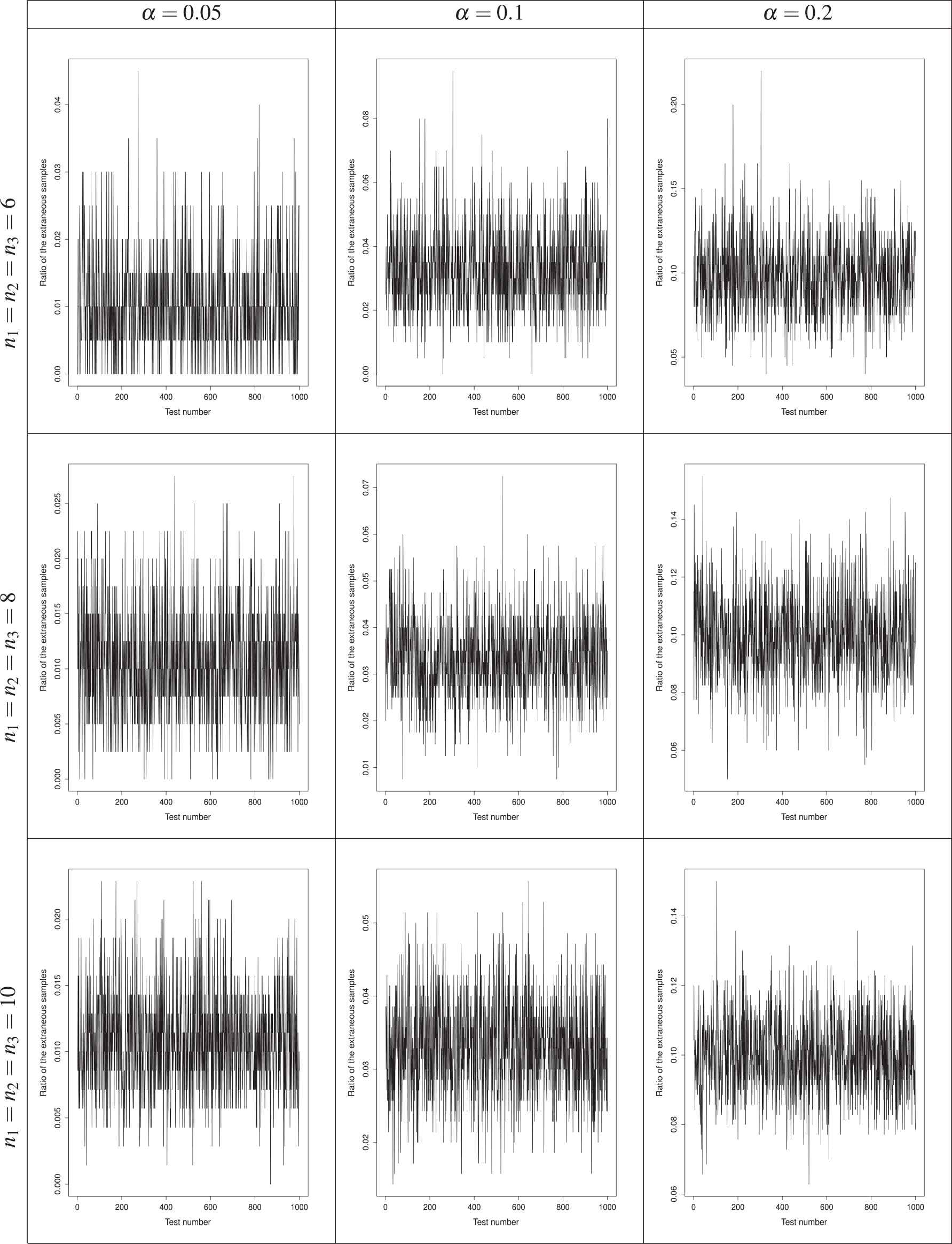
The ratio of extraneous permutation sample (EPS) from the total number of permuted samples in 1000 multiple testing. Each subfigure shows this ratio for the different values of and the sample sizes.

Boxplots of the estimated p-values by UPM and PPM in three cases (n1; n2; n3): (6,6,6), (8,8,8), (10,10,10). The random samples are generated from a normal distribution. UPM and PPM in each sub gure correspond to the usual permutation method and
We can see that the median of the estimated
| Sample Sizes |
|||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | |||||||||
| UPM | |||||||||
| PPM with EPS | |||||||||
| PPM without EPS | |||||||||
IQR, interquartile range; UPM, Usual Permutation Method; PPM, Proposed Permutation Method; EPS, extraneous permutation sample.
Comparing the computed IQR in UPM and PPM (with and without EPS).

Boxplots of the estimated p-values by PPM and UPM in three cases (n1;n2;n3): (6,6,6), (8,8,8), (10,10,10). The random samples are generated from the skew-normal distribution. PPM and UPM in each subfigure correspond to the usual permutation method and
Heterogeneity of the variance effect on the condition (5): Here, we address an important goal, namely the investigation of the effect of heterogeneity of variance on condition (5). We assume normal distributions for the underlying variables with zero means and the different values in the variances,
| Sample Sizes |
||
|---|---|---|
AD, Anderson–Darling; The null hypothesis is that two samples come from the common distribution.
The estimated
4.2. Real Data Sets
We have applied our method to two types of microarray data. The first study [13] is aimed to investigate the effectiveness of the processes of brain aging in increasing of Alzheimer's disease. Gene expression values were measured for
| Method | The Number of Detected Genes |
|---|---|
| One |
1081 |
| UPM | 1098 |
| PPM | 948 |
ANOVA, analysis of variance; UPM, Usual Permutation Method; PPM, Proposed Permutation Method.
The number of detected genes as differential gene expression through three methods: one-way ANOVA, UPM, and PPM for the male Fischer rats.
The second example, aimed to identify the reasons for preconceptional endometrial deregulations within in vitro fertilization (IVF) and intracytoplasmic sperm injection (ICSI) [23]. The study investigated whether there is any relation between preconceptional endometrial deregulations and the two events, implantation failures (IFs) and recurrent miscarriages (MSs), when IVF/ICSI is utilized. Three groups are thus considered: a fertile control group comprising women who have had at least one birth, and two test groups comprising women with IF and IM, respectively. Each group contained five subjects. In total, the gene expression values of
| Method | The Number of Detected Genes |
|---|---|
| One |
4894 |
| UPM | 1183 |
| PPM | 321 |
ANOVA, analysis of variance; UPM, Usual Permutation Method; PPM, Proposed Permutation Method.
The number of detected genes as differential gene expression through three methods: one-way ANOVA, UPM, and PPM for the preconceptional endometrial deregulations.
5. CONCLUSIONS
In this paper, we first introduced a new permutation
CONFLICT OF INTEREST
The authors declare they have no conflicts of interest.
ACKNOWLEDGMENTS
The comments of an associate editor and reviewers improved the manuscript significantly. We wish to express our appreciation to them. Thanks are due to our colleague Professor M. Ebrahimi, who assisted in extracting the real data sets. We are also thankful to Dr. S. K. Ghoreishi for his comments.
REFERENCES
Cite this article
TY - JOUR AU - Mohsen Salehi AU - Adel Mohammadpour AU - Kerrie Mengersen PY - 2019 DA - 2019/12/27 TI - A New F-Test Applicable to Large-Scale Data JO - Journal of Statistical Theory and Applications SP - 439 EP - 449 VL - 18 IS - 4 SN - 2214-1766 UR - https://doi.org/10.2991/jsta.d.191217.001 DO - 10.2991/jsta.d.191217.001 ID - Salehi2019 ER -