
A Method for Secure Communication Using a Discrete Wavelet Transform for Audio Data and Improvement of Speaker Authentication
- DOI
- 10.2991/jrnal.2018.5.2.4How to use a DOI?
- Keywords
- Secure communication; Audio data processing; Wavelet transform; Encoding
- Abstract
We developed a secure communication method using a discrete wavelet transform. Two users must each have a copy of the same piece of music to be able to communicate with each other. The message receiver can produce audio data similar to the sending user's speech by using our previously proposed method and the given recording of music. To improve the accuracy of speaker authentication, the quantization level for the scaling coefficients is increased. Furthermore, the amount of data sent to the message receiver can be remarkably reduced by exploiting the characteristics of this data.
- Copyright
- Copyright © 2018, the Authors. Published by Atlantis Press.
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
The elderly are often targets of telephone fraud. The fraudster pretends to be a grandchild of the elderly person while talking on the phone, and appeals to the elderly person to send money, for example, through a bank transfer. In the present study, we propose a method for secure communication using a discrete wavelet transform (DWT) and thus improve speaker authentication; this is an enhancement of our previously proposed method.1 It can be used with Internet protocol (IP) telephones, and it has the potential to help prevent telephone fraud.
2. Proposed Method
2.1. Encoding
2.1.1. Phenomenon exploited for the coding algorithm for audio data
In the course of our research,1 we found that the histogram of the scaling coefficients for each domain of a multiresolution analysis (MRA) sequence is centered at approximately zero when a DWT is performed on audio data. Exploiting this phenomenon, we have developed a secure communication method using audio data.1
2.1.2. Use of five quantization levels for scaling coefficients
(1) Parameter setting
In our reported study,1 we set the following coding parameters.
The values of Th(minus) and Th(plus) in Fig. 1 are chosen such that the nonpositive scaling coefficients (Sm in total frequency) are equally divided into two groups by Th(minus), and the positive scaling coefficients (Sp in total frequency) are equally divided into two groups by Th(plus). Next, the values of T1, T2, T3, and T4, which are the parameters for controlling the authentication precision, are chosen to satisfy the following conditions:
- 1)
T1 < Th(minus) < T2 < 0 < T3 < Th(plus) < T4
- 2)
The value of ST1, which is the number of scaling coefficients in (T1, Th(minus)), is equal to ST2, which is the number of scaling coefficients in [Th(minus),T2), i.e., ST1 = ST2.
- 3)
The value of ST3, the number of scaling coefficients in (T3, Th(plus)], is equal to ST4, the number of scaling coefficients in (Th(plus),T4), i.e., ST3 = ST4.
- 4)
ST1/Sm = ST3/Sp.
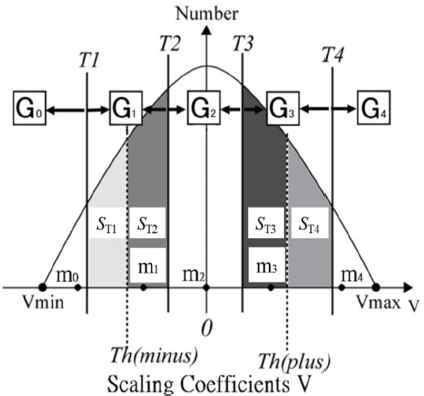
Schematic diagram for demonstrating the selection of the scaling coefficients for encoding the audio data.1
In the present study, the values of both ST1/Sm and ST3/Sp are set to 0.3, which was determined experimentally.
(2) Encoding
In the preprocessing of the audio data prior to encoding, the scaling coefficients V of the MRA sequence are separated into five sets (G0 to G4), as shown in Fig. 1, under the following criteria:
- •
G0 = {V | V ∈ VSC, V ≤ T1},
- •
G1 = {V | V ∈ VSC, T1 < V < T2},
- •
G2 = {V | V ∈ VSC, T2 ≤ V ≤ T3},
- •
G3 = {V | V ∈ VSC, T3 < V < T4},
- •
G4 = {V | V ∈ VSC, T4 ≤ V},
The scaling coefficients for the MRA sequence are encoded according to the following rules, where Vi denotes scaling coefficient i: Vi ∈ G0, ci = 0; when Vi ∈ G1, ci = 1; when Vi ∈ G2, ci = 2; when Vi ∈ G3, ci = 3; and when Vi ∈ G4, ci = 4. We represent the scaling coefficient for each set, Gj, by its average value, mj. For the formation of audio data, we use a code C, which is the sequence of ci and mj defined above.
2.1.3. Use of eight quantization levels for scaling coefficients
Here, we define eight sets of G8,0, to G8,7, as follows:
- •
G8,0 = {V | V ∈ VSC, V ≤ T1},
- •
G8,1 = {V | V ∈ VSC, T1 < V < Th(minus)},
- •
G8,2 = {V | V ∈ VSC, Th(minus) ≤ V ≤ T2},
- •
G8,3 = {V | V ∈ VSC, T2 < V < 0},
- •
G8,4 = {V | V ∈ VSC, 0 ≤ V ≤ T3},
- •
G8,5 = {V | V ∈ VSC, T3 < V < Th(plus)},
- •
G8,6 = {V | V ∈ VSC, Th(plus) ≤ V ≤ T4},
- •
G8,7 = {V | V ∈ VSC, T4 < V}.
Again, we let the representative value for each set, G8,i, be its average, m8,i. For the formation of audio data, we use the code C8, which is the sequence of c8,i defined for eight quantization levels for scaling coefficients in the similar manner as ci described in Section 2.1.2, and m8,j as defined above.
2.1.4. Use of 16 quantization levels for scaling coefficients
(1) Parameter setting
The values of T1m, T1p, T2m, T2p, T3m, T3p, T4m, and T4p, which are the parameters for controlling the authentication precision, are chosen to satisfy the following conditions:
- 1)
T1m < T1 < T1p < Th(minus) < T2m < T2 < T2p < 0 < T3m < T3 < T3p < Th(plus) < T4m < T4 < T4p
- 2)
The value of T1m is defined so that it equally divides the number of scaling coefficients in [V min, T1]. T1p, T2m,..., T4p are defined similarly to T1m.
(2) Encoding
Sixteen sets of G16,0 to G16,15 are defined as follows:
- •
G16,0 = {V | V ∈ VSC, V ≤ T1m},
- •
G16,1 = {V | V ∈ VSC, T1m < V < T1},
- •
G16,2 = {V | V ∈ VSC, T1 ≤ V ≤ T1p},
- •
G16,3 = {V | V ∈ VSC, T1p < V < Th(minus)},
- •
G16,4 = {V | V ∈ VSC, Th(minus) ≤ V ≤ T2m},
- •
G16,5 = {V | V ∈ VSC, T2m < V < T2},
- •
G16,6 = {V | V ∈ VSC, T2 ≤ V ≤ T2p},
- •
G16,7 = {V | V ∈ VSC, T2p < V < 0},
- •
G16,8 = {V | V ∈ VSC, 0 ≤ V ≤ T3m},
- •
G16,9 = {V | V ∈ VSC, T3m < V < T3},
- •
G16,10 = {V | V ∈ VSC, T3 ≤ V ≤ T3p},
- •
G16,11 = {V | V ∈ VSC, T3p < V < Th(plus)},
- •
G16,12 = {V | V ∈ VSC, Th(plus) ≤ V ≤ T4m},
- •
G16,13 = {V | V ∈ VSC, T4m < V < T4},
- •
G16,14 = {V | V ∈ VSC, T4 ≤ V ≤ T4p},
- •
G16,15 = {V | V ∈ VSC, T4p < V}.
As before, the value for each set, G16,i, is represented by its average value, m16,i. For the formation of audio data, we use the code C16, which is the sequence of c16, i defined for 16 quantization levels for scaling coefficients in the similar manner as ci described in Section 2.1.2, and m16,j defined above.
2.2. Audio data formation using code replacement
In this subsection, the formation of sound data is explained; for this example, we use five quantization levels for the scaling coefficient.1 The scaling coefficient sequence for audio data A is expressed as S(A)k = {x1, x2, x3,...,xk}, where k is the total number of scaling coefficients of A at this level. Then, the sequence C(A)k = {X1, X2, X3,..., Xk} is determined, where Xi ∈ {0,1,2,3,4} is the element index, which indicates to which of the five sets of scaling coefficients xi of A belongs. Next, the audio data A′ is defined as having the scaling coefficient sequence S(A′)k and a value of zero for all wavelet coefficient values at every level. S(A′)k is defined as S(A′)k = {a1, a2, a3,..., ak}, where
2.3 Data for communication
A sequence D1(B′A)n is defined as D1(B′A)n = {z1, z2,..., zn}, where n is the total number of cases where Yi ≠ Xi, zp = [|yi|]mod 256, and the integer p is increased from 1 to n, in steps of size 1, when Yi ≠ Xi.1 Here, [x] signifies the maximum integer that is not greater than x. Then, a sequence D2(B′A)n is defined as D2(B′A)n = {Z1, Z2,..., Zn}, where n is the total number of cases for which Yi ≠ Xi and Zp = Xi.1
In communications between two users, the message sender and the receiver each have the secret key B, and the sender sends D1(B′A)n and D2(B′A)n to the receiver.1 Then, the receiver composes B″A, which is defined in Section 2.4 and is expected to be similar to A.
2.4. Audio data composition
In this subsection, the processing of sound data formation is also explained using the case of five quantization levels, as an example, for the scaling coefficient.1 The scaling coefficient sequence for audio data B is expressed as S(B)k = {y1, y2, y3,..., yk}, where k is the total number of scaling coefficients of B at this level. Then, a sequence C(B)k = {Y1,Y2,Y3,...,Yk} is determined, where Yi ∈ {0,1,2,3,4} is the element index, which indicates to which of the five sets of scaling coefficients yi of B belongs. S(B′)k is defined as S(B′)k = {b1,b2,b3,...,bk}, where
A sequence D3(B)k is defined as D3(B)k = {zB,1,zB,2,...,zB,k}, where k is the total number of scaling coefficients of B at this level, and zB,q = [|yq|]mod 256. B″A is determined as follows: S(B″A)k is calculated from S(B′)k by replacing bq with
2.5. Data reduction
2.5.1. Processing for D1
Because zp = [|yi|]mod 256, zp is in the range from 0 to 255, and thus it can be expressed using 8 bits. In our computer, an integer is represented by 32 bits. Therefore, four values for zp, each expressed using 8 bits, can be integrated into a single value expressed by 32 bits. For D1(B′A)n = {z1, z2,..., zn}, z′j is defined as
2.5.2. Processing for D2
(1) Case of five quantization levels
D2′(B′A)n = {Z1,Z2,...,Zn} and D2′(B′A)l = {Z′1,Z′2,...,Z′l}, where Z′j = Z13i–12 + Z13i–11 × 5 + Z13i–10 × 52 + ∙ ∙ ∙ + Z13i×512, are defined as described in Section 2.5.1.
(2) Case of eight quantization levels
D2′(B′A)n = {Z1,Z2,...,Zn} and D2″(B′A)r = {Z″1,Z″2,...,Z″r}, where Z″j = Z10i–9 + Z10i–8 × 8 + Z10i–7 × 82 + ∙ ∙ ∙ + Z10i × 89, are defined as described in Section 2.5.1.
(3) Case of 16 quantization levels
D2′(B′A)n = {Z1,Z2,...,Zn} and D2″(B′A)s = {Z′″1,Z′″2,...,Z′″s}, where Z′″j = Z8i–7 + Z8i–6 × 16 + Z8i–5 × 162 + ∙ ∙ ∙ + Z8i × 167, are defined as described in Section 2.5.1.
3. Numerical Experiment
We applied the proposed method, using several voice recordings for A, and for B, we used two recordings of music, one classical and the other hip-hop. The music was taken from a copyright-free database.2 In all cases, all of the produced B″A were audible and sounded similar to A; each B″A was made with five, eight, or 16 quantization levels. An increase in the quantization level improved the sound quality because a waveform made from B″A with a higher quantization level was more similar to the original waveform than was one made with a lower quantization level, as shown in Fig. 2. For (1), (2), and (3) in Section 2.5.2, the data reduction for one minute of audio data at 44.1 kHz, 16 bits, a single channel, and volume of 87 KB was as follows:
- (1)
D1(75 KB) → D1′(48 KB), D2(49 KB) → D2′(9 KB)
- (2)
D1(86 KB) → D1′(55 KB), D2(57 KB) → D2″(21 KB)
- (3)
D1(92 KB) → D1′(59 KB), D2(65 KB) → D2″′(29 KB)
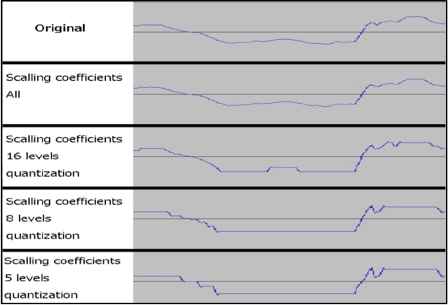
Examples of waveform
4. Conclusion
We developed a secure communication method using a discrete wavelet transform for audio data; we used an increased number of quantization levels for the scaling coefficients along with a data reduction technique. The waveform produced by the proposed method was more similar to the original one than that produced by our previously proposed method.1
References
Cite this article
TY - JOUR AU - Kouhei Nishimura AU - Yasunari Yoshitomi AU - Taro Asada AU - Masayoshi Tabuse PY - 2018 DA - 2018/09/30 TI - A Method for Secure Communication Using a Discrete Wavelet Transform for Audio Data and Improvement of Speaker Authentication JO - Journal of Robotics, Networking and Artificial Life SP - 93 EP - 96 VL - 5 IS - 2 SN - 2352-6386 UR - https://doi.org/10.2991/jrnal.2018.5.2.4 DO - 10.2991/jrnal.2018.5.2.4 ID - Nishimura2018 ER -