
Multigranulation rough set: A multiset based strategy
- DOI
- 10.2991/ijcis.2017.10.1.19How to use a DOI?
- Keywords
- Approximate distribution reduct; Approximate quality; Multiset; Multiple multigranulation rough set
- Abstract
A simple multigranulation rough set approach is to approximate the target through a family of binary relations. Optimistic and pessimistic multigranulation rough sets are two typical examples of such approach. However, these two multigranulation rough sets do not take frequencies of occurrences of containments or intersections into account. To solve such problem, by the motivation of the multiset, the model of the multiple multigranulation rough set is proposed, in which both lower and upper approximations are multisets. Such two multisets are useful when counting frequencies of occurrences such that objects belong to lower or upper approximations with a family of binary relations. Furthermore, not only the concept of approximate distribution reduct is introduced into multiple multigranulation rough set, but also a heuristic algorithm is presented for computing reduct. Finally, multiple multigranulation rough set approach is tested on eight UCI (University of California–Irvine) data sets. Experimental results show: 1. the approximate quality based on multiple multigranulation rough set is between approximate qualities based on optimistic and pessimistic multigranulation rough sets; 2. by comparing with optimistic and pessimistic multigranulation rough sets, multiple multigranulation rough set needs more attributes to form a reduct.
- Copyright
- © 2017, the Authors. Published by Atlantis Press.
- Open Access
- This is an open access article under the CC BY-NC license (http://creativecommons.org/licences/by-nc/4.0/).
1. Introduction
Back in the early 1980s, Pawlak proposed the rough set 27 for characterizing the uncertainty. Through the three decades of the development, rough set has been demonstrated to be useful in knowledge acquisition 5,10, pattern recognition 3,7,23, machine learning 6,8,9,11,26, decision support 21,44,46,57 and so on.
In Pawlak’s rough set, indiscernibility relation is a basic concept, it is an intersection of some equivalence relations in knowledge base 27. An indiscernibility relation can induce a partition on the universe of discourse. Lower, upper approximations and boundary region in rough set model are then the unions of some blocks (equivalence classes) in partition with different conditions, respectively. Obviously, Pawlak’s rough set is constructed on the basis of one and only one set of the information granules (set of equivalence classes in a partition), we call such set a granular structure 29. From this point of view, Pawlak’s model is referred to as a single–granulation rough set approach in this paper. Nevertheless, single–granulation is not good enough for practical problem solving. For example:
- 1.
a map can be explained from different levels of viewpoints, the coarser perspective is based on the greater information granules while the finer perspective is based on the smaller information granules, i.e. we may explore a map through different levels of granulations;
- 2.
single feature information is not robust for authentication (e.g. fingerprint may be stolen and copied by criminals) and then multi–biometrics are needed;
- 3.
single–granulation approach is very time–consuming in rough set theory since it needs to do the intersection on more than one binary relations.
To fill those gaps of single–granulation approach and further improve the effectiveness of Pawlak’s rough set theory, Qian and Liang et al. 15,17,30,31,33,34,35,37,38 proposed the concept of the multigranulation rough set. Presently, with respect to different requirements, multigranulation rough set progressing rapidly 2,18,41,42,45,48,49,50,51,55. We may classify the existing multigranulation rough sets into two categories.
- 1.
Firstly, synchronous multigranulation approach: a lot of the granulations are presented simultaneously for problem solving. For instance, in Qian et al.’s classical multigranulation rough set approach, the target is approximated through a set of partitions; Yang et al. 52 and Xu et al. 43 presented the multigranulation fuzzy rough set through a family of fuzzy relations, respectively; Lin et al. 14 presented the neighborhood multigranulation rough set by using a family of neighborhoods, i.e. neighborhood system 53; Khan and Banerjee 12 introduced the concept of the multiple–source approximation systems, which are multigranulation fusions of Pawlak’s approximation spaces; Abu–Donia 1 studied the rough approximations based on multi–knowledge; Wu and Leung 40 investigated the multi–scale information system, which reflects the explanation of same problem at different scales (levels of granulations); Dou et al. 4 integrated variable precision rough set 56 with multigranulation rough sets; She et al. 39 studied the algebraic structure of multigranulation rough set.
- 2.
Secondly, asynchronous multigranulation approach: a granulation is constructed or obtained from the last granulation. For example, Qian et al. 33,34 proposed a positive approximation accelerator for attribute reduction, which can make universe smaller step by step; Liang et al. 19 proposed an efficient rough feature selection algorithm for large–scale data sets, which selects a valid feature subset though dividing big samples into small samples and fusing the feature selection results of small samples together, they 20 also studied the incremental feature selection mechanism by considering the monotonic increasing of samples; Wang et al. presented a dimension incremental strategy for attribute reduction, in which the current information entropy can be updated by the last computation result.
The purpose of this paper is to further explore synchronous multigranulation approach. Qian et al.’s optimistic and pessimistic multigranulation rough sets are two typical examples of such research. Through the investigation of optimistic and pessimistic multigranulation lower approximations, we know that optimism needs at least one of the granular structures (partitions) to be satisfied with the containment between equivalence class and target, pessimism needs all of the granular structures to be satisfied with the containments between equivalence class and target. Obviously, these two multigranulation rough sets do not take frequencies of occurrences of set containments into account. We have some practical examples to illustrate such limitation.
- 1.
Take for instance multi-subspace learning problem, each subspace is corresponding to a world which can be used to construct approximation. If Qian et al.’s optimistic approach is used, then it is confused for us to count how many subspaces have contributed to the set containments, e.g., lower approximations. Therefore, the subspaces with high contribution may be mixed with subspaces with low contribution.
- 2.
Qian et al.’s optimistic approach is too loose (Here is a China old saying: One tree does not make a forest.) while the pessimistic approach is too strict (Here is also a China old saying: It is hard to please all.). Voting is a possible strategy to solve these problems. Therefore, it is required that the frequencies of occurrences of set containments should be counted.
To sum up, we will propose the multiple multigranulation rough set by using the concept of the multiset 13,24 in this paper. In our multiple multigranulation rough set, both lower and upper approximations are multisets, which can reflect frequencies of occurrences of objects belonging to lower and upper approximations, respectively.
To facilitate our discussions, we present the basic knowledge about optimistic and pessimistic multigranulation rough sets in Section 2. In Section 3, we propose the model of multiple multigranulation rough set, not only the basic properties of such model are studied, but also the relationships among multiple and Qian et al.’s multigranulation rough sets are explored. Since attribute reduction is one of the key problems in rough set theory, we also introduce the concept of the approximate distribution reduct into multiple multigranulation rough set. Through experimental analyses, the comparisons of approximation qualities and reducts on three different multigranulation rough sets are shown in Section 4. The paper ends with conclusions in Section 5.
2. Preliminary knowledge
2.1. Multigranulation rough sets
Formally, an information system can be denoted as a pair I =< U,AT >, in which U is a non–empty finite set of objects called the universe; AT is a non–empty finite set of attributes. ∀a ∈ AT, Va is the domain of attribute a. ∀x ∈ U, let a(x) denote the value of x on attribute a (∀a ∈ AT). For an information system I, one can describe the relationship between two objects through their values on attributes. For example, suppose that A ⊆ AT, an indiscernibility relation IND(A) may be defined as
Since IND(A) is still an equivalence relation, U/IND(A) is then denoted as the partition determined by indiscernibility relation IND(A) on U. From the viewpoint of granular computing 47, each equivalence class in U/IND(A) is an information granule. In other words, by a given indiscernibility relation, objects are granulated into a set of information granules, called a granular structure 29. It should be noticed that partition is only a special granular structure, granular structure may also be a set of information granules induced by a general binary relation.
Definition 1.
Let I be an information system in which A ⊆ AT, ∀X ⊆ U, the lower and upper approximations of X are denoted by
Qian et al.’s classical multigranulation rough set is different from Pawlak’s rough set since the former is constructed on the basis of a family of the binary relations instead of a single one. In this paper, to simplify our discussions, it is assumed that each attribute in an information system I is corresponding to an equivalence relation. Therefore, each attribute in I can induce a partition based granular structure on the universe of discourse and then all the attributes in I will induce a partitions based multigranular structure. In Qian et al.’s multigranulation rough set theory, two different models were defined. The first one is optimistic multigranulation rough set 31,37, the second one is pessimistic multigranulation rough set 35.
Definition 2.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X ⊆ U, the optimistic multigranulation lower and upper approximations of X are denoted by
The pair
Theorem 1.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X ⊆ U, we have
Proof.
It can be derived directly from Def. 2.
Definition 3.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X ⊆ U, the pessimistic multigranulation lower and upper approximations of X are denoted by
The pair
Theorem 2.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X ⊆ U, we have
Proof.
It can be derived directly from Def. 3.
Please refer to Refs. 30,31,35,37 for more details about optimistic and pessimistic multigranulation rough sets.
2.2. Multiset
Assume that U is the universe of discourse, a crisp multiset M of U is characterized by the count function such that
In this paper, for technical reasons, we consider a special multiset, which is a mapping from universe to a finite set, i.e.,
Similar to classical set theory, it is not difficult to define some relations and operations on multisets. Suppose that M and N are two multisets over the same universe U, then
- 1.
Inclusion: M ⊑ N ⇔ CM(x) ≤ CN(x),∀x ∈ U;
- 2.
Equality: M = N ⇔ CM(x) = CN(x),∀x ∈ U;
- 3.
Union: M ⊔ N ⇔ CM⊔N(x) = max{CM(x),CN(x)}, ∀x ∈ U;
- 4.
Intersection: M ⊓ N ⇔ CM⊓N(x) = min{CM(x),CN(x)}, ∀x ∈ U;
- 5.
Complement: ¬M ⇔ C¬M(x) = m − CM(x), ∀x ∈ U;
- 6.
Empty multiset: ∅0 ⇔ C∅0 (x) = 0, ∀x ∈ U;
- 7.
Full multiset: Um ⇔ CUm (x) = m,∀x ∈ U.
3. Multiple multigranulation rough set
3.1. Definition and properties
By Defs. 2 and 3, we can see that an object belongs to optimistic multigranulation lower approximation if and only if at least one of its equivalence classes is contained in the target, an object belongs to pessimistic multigranulation lower approximation if and only if all of its equivalence classes are contained in the target. Similar conclusions of upper approximations can also be drawn by Theorems 1 and 2. In other words, for a given object, it may belong to lower approximation one or more times since it has one or more equivalence classes, which are contained in the target; it may also belong to upper approximation one or more times since it has one or more equivalence classes, which are intersected with the target. Nevertheless, optimistic and pessimistic multigranulation rough sets do not take frequencies of occurrences of such containment or intersection into consideration. Therefore, in this section, a new multigranulation rough set will be proposed to solve such problem. To achieve such goal, we need following definitions of characteristic functions.
Definition 4.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X ⊆ U and ∀x ∈ U, two characteristic functions are defined as
To distinguish with optimistic and pessimistic multigranulation rough sets, our approach is referred to as multiple multigranualtion rough set in this paper.
Definition 5.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X ⊆ U, the multiple multigranulation lower and upper approximations of X are denoted by
The pair
Different from optimistic and pessimistic multigranulation rough sets, in our multiple multigranulation rough set model, an object may belong to multiple multigranulation lower/upper approximation more than one times.
Theorem 3.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X ⊆ U and ∀x ∈ U, we have
Proof.
It can be derived directly from definitions of three multigranulation rough sets.
In Theorem 3, formulas (16) and (17) show the relationship between multiple multigranulation rough set and optimistic multigranulation rough set, formulas (18) and (19) show the relationship between multiple multigranulation rough set and pessimistic multigranulation rough set.
Since classical set may be considered as a special multiset (given a classical set X, if x ∈ X, then CX(x) = 1, otherwise, CX(x) = 0), we then obtain the following theorem immediately.
Theorem 4.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X ⊆ U, we have
Proof.
We only prove formula (20), and the others can be proved analogously. Suppose that
- 1.
If
- 2.
If
From discussions above, we obtain
Theorem 4 shows that both optimistic and pessimistic multigranulation lower approximations are smaller than multiple multigranulation lower approximation, both optimistic and pessimistic multigranulation upper approximations are also smaller than multiple multigranulation upper approximation.
For the readers’ convenience, the relationships among three different multigranulation rough sets are shown in Fig. 1. In Fig. 1, each node denotes a multigranulation approximation or a target, and each line connects two nodes, where the lower node is a multiset inclusion of the upper node.
Relationships among three different multigranulation rough sets.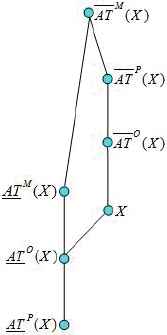
By Fig. 1, some interesting results can be obtained.
- 1.
- 2.
Theorem 5.
Let I be an information system in which AT = {a1,a2,⋯,am}, ∀X,Y ⊆ U, we have
Proof.
- 1.
- 2.
∀x ∈ U, since ∀ai ∈ AT, we have x ∈ [x]ai and then [x]ai ⊈ ∅, it follows that
- 3.
∀x ∈ U, since ∀ai ∈ AT, we have [x]ai ⊆ U and then
- 4.
∀x ∈ U and ∀ai ∈ AT, if
- 5.
The proof of
- 6.
∀x ∈ U, since X ⊆ Y, then ∀ai ∈ AT, we have [x]ai ⊆ X ⇒ [x]ai ⊆ Y,
- 7.
The proof of
- 8.
Suppose that
From discussions above, we can conclude that
- 9.
Theorem 5 shows some basic properties of multiple multigranulation rough set.
Theorem 6.
Let I be an information system in which AT = {a1,a2,⋯,am}, suppose that B = {b1,b2,⋯,bn} ⊆ AT, ∀X ⊆ U, we have
Proof.
It can be derived directly from Def. 5.
Theorem 6 shows the monotonic variation of multiple multigranulation lower and upper approximations with the monotonic increasing or decreasing of number of equivalence relations, the details are: if the number of used equivalence relations is increasing, then both multiple multigranulation lower and upper approximations are increasing. It should be noticed that such result is different from those of optimistic and pessimistic multigranulation rough sets. In optimistic multigranulation rough set, with the monotonic increasing of number of equivalence relations, the lower approximation is increasing while the upper approximation is decreasing; in pessimistic multigranulation rough set, with the monotonic increasing of number of equivalence relations, the lower approximation is decreasing while the upper approximation is increasing.
3.2. Approximate quality
Following Pawlak’s rough set theory, Qian et al. have presented the definitions of approximate qualities based on optimistic and pessimistic multigranulation rough sets. Since in this paper, the multiple multigranulation lower approximation is a multiset rather than a classical set, we need to further present new definition of approximate quality.
Definition 6.
Let I =< U,AT ∪ {d} > be a decision system in which AT = {a1,a2,⋯,am}, partition U/IND({d}) = {X1,⋯,Xk} is the set of decision classes determined by decision attribute d, approximate qualities of d based on optimistic, pessimistic and multiple multigranulation rough sets are defined as γO(AT,d), γP(AT,d) and γM(AT,d), respectively, such that
Theorem 7.
Let I =< U,AT ∪ {d} > be a decision system in which AT = {a1,a2,⋯,am}, we have
Proof.
Firstly, let us prove
- 1.
If
- 2.
If
From discussions above, we obtain
Similarity, it is not difficult to prove that γM(AT,d) ≤ γO(AT,d).
Theorem 7 tells us that the approximation quality based on multiple multigranulation rough set is between those based on optimistic and pessimistic multigranulation rough sets.
3.3. Approximate distribution reducts
Attribute reduction 16,25,28,36 plays a crucial role in the development of rough set theory. In Pawlak’s rough set theory, reduct is a minimal subset of attributes, which is independent and has the same discernibility power as all of the attributes. In recent years, with respect to different requirements, different types of reducts have been proposed. In this paper, we will introduce the concept of approximate distribution reduct 22,54 into our multiple multigranulation rough set. Such goal is to preserve frequencies of occurrences that objects belong to multiple multigranualtion lower or upper approximations.
Definition 7.
Let I =< U,AT ∪ {d} > be a decision system in which AT = {a1,a2,⋯,am}, partition U/IND({d}) = {X1,⋯,Xk} is the set of decision classes determined by decision attribute d,
- 1.
B = {b1,b2,⋯,bn} ⊆ AT is referred to as a multiple multigranulation lower approximate distribution reduct in I if and only if MLB = MLAT and ∀B′ ⊂ B, MLB′ ≠ MLAT;
- 2.
B = {b1,b2,⋯,bn} ⊆ AT is referred to as a multiple multigranulation upper approximate distribution reduct in I if and only if MUB = MUAT and ∀B′ ⊂ B, MUB′ ≠ MUAT.
Specially, in Definition 7, if only MLB = MLAT or MUB = MUAT hold, then B is referred to as the multiple multigranulation lower or upper approximate distribution consistent attributes sets in I. Obviously, multiple multigranulation lower or upper approximate distribution reducts in I are the minimal subsets of attributes, which preserve multiple multigranulation lower or upper approximations of all the decision class, i.e. multiple multigranulation lower or upper approximate distribution reducts can be used to preserve the distributions of multiple multigranulation lower or upper approximations.
Theorem 8.
Let I =< U,AT ∪ {d} > be a decision system in which AT = {a1,a2,⋯,am}, if B = {b1,b2,⋯,bn} ⊆ AT, then
- 1.
- 2.
Proof.
“⇒”: If MLB = MLAT, by Definition 7, we know that
“⇐”: If
Similarity, it is not difficult to prove that
Theorem 8 tells us that multiple multigranulation lower or upper approximate distribution consistent attributes sets can be used to preserve frequencies of occurrences that objects belong to multiple multigranulation lower or upper approximations, repsectively.
Based on the result shown in Theorem 6, we know that multiple multigranulation rough lower and upper approximations are monotonic variations with the monotonic increasing or decreasing attributes. Therefore, let I =< U,AT ∪ {d} > be a decision system in which AT = {a1,a2,⋯,am}, suppose that B = {b1,b2,⋯,bn} ⊆ AT, ∀b ∈ B, we define the following two coefficients for two approximate distribution reducts, respectively:
By above measures, a forward greedy attribute reduction algorithm for computing reduct can be designed as following.
| Input: Decision system I; |
| Output: A multiple multigranulation lower approximate distribution reduct B. |
Step 1: B ← ∅, compute MLAT; |
Step 2: Compute the significance of each ai ∈ AT with
|
Step 3: B ← aj where
|
Step 4: Do |
∀ai ∈ AT − B, compute
|
If
|
B = B ∪ {aj}; |
End |
Until MLB = MLAT ; |
Step 5: ∀ai ∈ B |
If MLB−{ai} = MLB |
B = B − {ai}; |
End |
Step 6: Return B. |
Attribute reduction based on multiple multigranulation rough set in I.
If
The above forward greedy attribute reduction algorithm is starting with the attribute with maximal change of significance when eliminating a single attribute, we then take the attribute with the maximal significance into the attribute subset in each loop until the entire approximate distribution of this attribute subset satisfies the target requirement, and then we can get a attribute subset. Step 5 is to delete the redundant attribute in the obtained attribute subset.
In the above algorithm, in the worst case, all attributes should be checked for comparing the approximation equalities. Moreover, an attribute is never checked twice. Therefore the number of checking steps is bounded by |AT|. Moreover, the time consuming of computing approximation quality is O(|U|2), therefore, the time complexity of this algorithm is O(|U|2 * |AT|). Such complexity if same to Qian et al.’s pessimistic multigranulation rough set based attribute reduction 32 and lower than Qian et al.’s optimistic multigranulation rough set based attribute reduction (O(|U|2 * |AT| * 2|AT|))37.
4. Experimental results
In the following, through experimental analysis, we illustrate the differences among three multigranulation rough sets mentioned in this paper. All the experiments have been carried out on a personal computer with Windows 7, Intel Core 2 Duo T5800 CPU (2.00 GHz) and 2.00 GB memory. The programming language is Matlab 2010.
We have downloaded eight public data sets from UCI Repository of Machine Learning databases, which are described in Tab. 1. In our experiment, we assume that each attribute in a data set can induce an equivalence relation and then all attributes in a data set will induce a family of equivalence relations on the universe of discourse.
| Data ID | Data sets | Objects | Attributes | Decision classes |
|---|---|---|---|---|
| 1 | Zoo | 101 | 16 | 7 |
| 2 | German Credit | 1000 | 20 | 2 |
| 3 | Car | 1728 | 6 | 4 |
| 4 | Contraceptive Method Choice | 1473 | 9 | 3 |
| 5 | Breast Cancer Wisconsin | 569 | 30 | 2 |
| 6 | Libras Movement | 360 | 90 | 15 |
| 7 | Glass Identification | 214 | 9 | 6 |
| 8 | Ionosphere | 351 | 34 | 2 |
Data sets description.
4.1. Comparison among approximate qualities
Fig. 2 shows the experimental results of approximate qualities on eight data sets, each sub–figure in Fig. 2 is corresponding to the computing result on one data set. For each sub-figure, the x–coordinate pertains to the number of attributes while the y–coordinate concerns obtained approximate quality. The tagging “OMGRS” is the computing result based on optimistic multigranulation rough set, the tagging “MMGRS” is the computing result based on multiple multigranulation rough set and the tagging “PMGRS” is the computing result based on pessimistic multigranulation rough set.
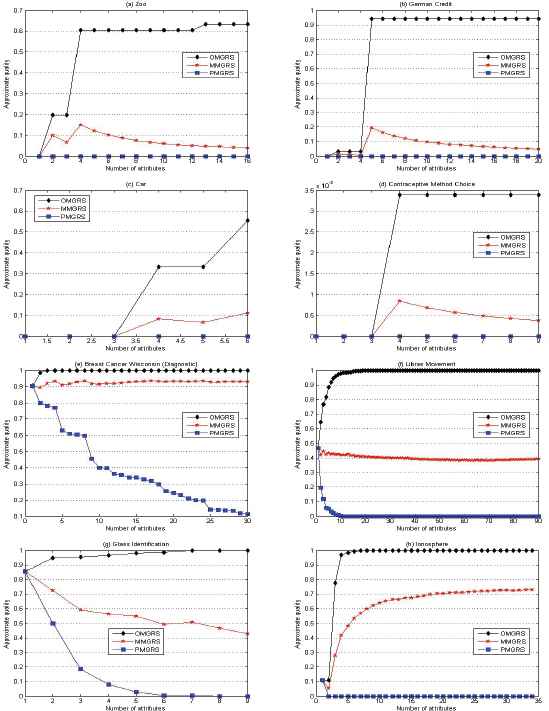
Approximate qualities based on three multigranulation rough sets.
It is not difficult to note from Fig. 2 that no matter how many attributes are used, approximate qualities based on multiple multigranulation rough set are between those based on optimistic and pessimistic multigranulation rough sets. Such experimental results demonstrate the theoretical result shown in Theorem 7. Moreover, it should be noticed that different from optimistic and pessimistic multigranulation rough sets, approximate quality based on multiple multigranulation rough set is not necessarily monotonic increasing or decreasing with the increasing of attributes. Though for each decision class Xj in a data set, its multiple multigranulation lower approximation is consistently increasing (see Theorem 6), the denominator of approximate quality is also increasing since #(Um) = m · |U| (m is the number of used attributes) and then such approximate quality is not necessarily monotonic.
4.2. Comparison among approximate distribution reducts
Tabs. 2–4 show the results of approximate distribution reducts and reduction ratios based on optimistic, pessimistic and multiple multigranulation rough sets, respectively.
| Data ID | Attributes in lower approximate distribution reduct | Reduction ratio | Attributes in upper approximation distribution reduct | Reduction ratio |
|---|---|---|---|---|
| 1 | 2,4,14 | 81.25% | 4,5,6,9,12,13,14 | 56.25% |
| 2 | 5,13 | 90.00% | 5,13 | 90.00% |
| 3 | 4,6 | 66.67% | 1,2,4,5,6 | 16.67% |
| 4 | 4 | 88.89% | 1,4 | 77.78% |
| 5 | 1,16 | 93.33% | 1,16 | 93.33% |
| 6 | 1,3,12,28,65,85,89 | 92.22% | 1,18,71 | 96.67% |
| 7 | 1,2,4,5,7 | 44.44% | 1,2,7 | 66.67% |
| 8 | 1,4,6,7,18,25 | 82.36% | 1,4,6,7,18,25 | 82.36% |
Reducts of optimistic multigranulation rough set.
| Data ID | Attributes in lower approximate distribution reduct | Reduction ratio | Attributes in upper approximation distribution reduct | Reduction ratio |
|---|---|---|---|---|
| 1 | 1 | 93.75% | 7 | 93.75% |
| 2 | 1 | 95.00% | 1 | 95.00% |
| 3 | 1 | 83.33% | 3 | 83.33% |
| 4 | 1 | 88.89% | 2 | 88.89% |
| 5 | 1,⋯,10,12,13,14,16,⋯,30 | 6.67% | 1,⋯,10,12,13,14,16,⋯,30 | 93.33% |
| 6 | 1,3,10,42,52 | 94.44% | 1,2,4,⋯,7,9,10,12,13,15,⋯,18,20,⋯42, 44,⋯,68,70,71,72,74,75,76,78,⋯,89 |
11.11% |
| 7 | 1,5,8,9 | 55.56% | 2,⋯,9 | 11.11% |
| 8 | 2 | 97.06% | 2 | 97.06% |
Reducts of pessimistic multigranulation rough set.
| Data ID | Attributes in lower approximate distribution reduct | Reduction ratio | Attributes in upper approximation distribution reduct | Reduction ratio |
|---|---|---|---|---|
| 1 | 2,4,13 | 81.25% | 1,⋯,16 | 0.00% |
| 2 | 2,5,13 | 85.00% | 1,⋯,20 | 0.00% |
| 3 | 4,6 | 66.67% | 1,⋯,6 | 0.00% |
| 4 | 4 | 88.89% | 1,⋯,9 | 0.00% |
| 5 | 1,⋯,30 | 0.00% | 1,⋯,30 | 0.00% |
| 6 | 1,⋯,90 | 0.00% | 1,⋯,90 | 0.00% |
| 7 | 1,⋯,9 | 0.00% | 1,⋯,9 | 0.00% |
| 8 | 1,3,⋯,34 | 2.94% | 1,⋯,34 | 0.00% |
Reducts of multiple multigranulation rough set.
By comparing with Tabs. 2 and 3, we can observe following.
- 1.
For lower approximate distribution reduct, reduction ratios of optimistic multigranulation rough set are equal or lower than those of pessimistic multigranulation rough set except the 5th data set.
- 2.
For upper approximate distribution reduct, reduction ratios of optimistic multigranulation rough set are equal or lower than those of pessimistic multigranulation rough set except the 5th and 6th data sets.
Through experimental analysis, though reduction ratios of pessimistic multigranulation rough set may be higher than those of optimistic multigranulation rough set, the limitation of pessimistic multigranulation rough set is stricter than that of optimistic multigranulation rough set (such case can be observed by comparing Definitions 2 and 3), it follows that we obtain empty set for pessimistic multigranulation lower approximation (see Fig. 2, the approximate quality is zero on eight data sets) and full universe for pessimistic multigranulation upper approximation frequently in our experiment. From this point of view, pessimism is meaningless since we obtain nothing of certainty or uncertainty.
Furthermore, by comparing with Tabs. 2 and 4, we can observe following.
- 1.
For both lower and upper approximate distribution reducts, reduction ratios of multiple multigranulation rough set are lower than those of optimistic multigranulation rough set. Such difference is coming from the difference between optimistic and multiple multigranulation rough sets. Multiple multigranulation rough set is stricter than optimistic multigranulation rough set since the former needs to compute frequencies of occurrences such that objects belong to lower or upper approximations. To preserve such frequencies of occurrences for each object in the universe, more attributes are required.
- 2.
The reducts of optimistic multigranulation rough set are included into those of multiple multigranulation rough set. This is mainly because if frequencies of occurrences for each object in lower/upper approximations are preserved, then belonging or not belonging to optimistic multigranulation lower/upper approximations are also preserved.
From discussions above, we may obtain the following theorem.
Theorem 9.
Let I be a decision system in which AT = {a1,a2,⋯,am}, partition U/IND({d}) = {X1,⋯,Xk} is the set of decision classes determined by decision attribute d, suppose that B = {b1,b2,⋯,bn} ⊆ AT, then
- 1.
MLB = MLAT ⇒ OLB = OLAT;
- 2.
MUB = MUAT ⇒ OUB = OUAT;
Proof.
If MLB = MLAT, then by Theorem 8, we have
- 1.
∀x ∈ U, ∀Xj ∈ U/IND({d}), if
- 2.
∀x ∈ U, ∀Xj ∈ U/IND({d}), if
To sum up, we know that
Similarity, it is not difficult to prove that MUB = MUAT ⇒ OUB = OUAT.
Theorem 9 tells us that multiple multigranulation lower or upper approximate distribution consistent attributes sets are also optimistic multigranulation lower or upper approximate distribution consistent attributes sets, respectively.
Finally, by comparing with Tabs. 3 and 4, we can observe following.
- 1.
For both lower and upper approximate distribution reducts, reduction ratios of multiple multigranulation rough set are lower than those of pessimistic multigranulation rough set. Similar to optimistic case, such difference is also coming from the difference between pessimistic and multiple multigranulation rough sets. For example, suppose that B ⊆ AT is a pessimistic multigranulation lower approximate distribution reduct, if an object belongs to the lower approximation of a target, then all of the attributes in B support the containment between equivalence classes and target. However, B cannot be always satisfied with the preserving of frequencies of occurrences for such object in multiple multigranulation lower approximations. In other words, pessimistic multigranulation lower approximate distribution reduct can only guarantee all the equivalence classes (w.r.t. all attributes in reduct) of an object are contained in the target, it cannot always preserve the invariance of frequencies of occurrences for objects in multiple multigranulation lower approximations.
- 2.
The pessimistic multigranulation upper approximate distribution reducts are included into those of multiple multigranulation upper approximate distribution reducts. This is mainly because if in multiple multigranulation rough set, frequencies of occurrences for each object in upper approximations are preserved, then belonging or not belonging to upper approximations are also preserved. For example, if the frequency of occurrences for an object in lower approximations is m (m is the number of original attributes), then to preserve such frequency of occurrences, no attribute can be deleted, which also preserve the belonging of such object to pessimistic multigranulation upper approximation.
From discussions above, similar to Theorem 9, we may also obtain the following theorem.
Theorem 10.
Let I be a decision system in which AT = {a1,a2,⋯,am}, partition U/IND({d}) = {X1,⋯,Xk} is the set of decision classes determined by decision attribute d, suppose that B = {b1,b2,⋯,bn} ⊆ AT, then
- 1.
MLB = MLAT ⇒ PLB = PLAT;
- 2.
MUB = MUAT ⇒ PUB = PUAT;
Proof.
The proof of Theorem 10 is similar to that of Theorem 9.
Theorem 10 tells us that multiple multigranulation lower or upper approximate distribution consistent attributes sets are also pessimistic multigranulation lower or upper approximate distribution consistent attributes sets, respectively.
4.3. Related discussions
In this subsection, we summarize the differences between multiple and classical multigranulation rough set approaches.
- 1.
Approximate quality of multiple multigranulation rough set is equal or smaller than that of optimistic multigranulation rough set; it is also equal or higher than that of pessimistic multigranulation rough set. In Section 4.1, we have also noticed that different from optimistic and pessimistic multigranulation rough set approaches, approximate quality of multiple multigranulation rough set is not necessarily monotonic with the increasing or decreasing of used attributes.
- 2.
By comparing with Qian et al.’s two multigranulation rough sets, our multiple multigranulation rough set requires more attributes to construct a reduct. In Section 4.2, we have explained that such difference is coming from the stricter limitation of multiple multigranulation rough set. Such rough set needs to count frequencies of occurrences that objects belong to lower/upper approximations. Therefore, fewer attributes can be deleted.
- 3.
In our experimented data sets, multiple multigranulation lower or upper approximate distribution reducts include optimistic multigranulation lower or upper approximate distribution reducts, respectively; multiple multigranulation upper approximate distribution reduct includes pessimistic multigranulation upper approximate distribution reduct. In Section 4.2, we have derived two theorems (Theorems 9 and 10) based on such experimental results.
5. Conclusions
To count frequencies of occurrences that objects belong to lower or upper approximations under multigranulation environment, we have presented a general framework for the study of multiple multigranulation rough set in this paper. Based on this framework, a general heuristic algorithm is presented to compute multiple multigranulation lower/upper approximate distribution reducts. Experimental studies pertaining to eight UCI data sets show the differences of approximate qualities and reducts between our and Qian et al.’s multigranulation rough sets.
The following research topics deserve further investigation:
- 1.
The construction of multiple multigranulation rough set in fuzzy environment.
- 2.
Dynamic updating of multiple multigranulation rough set and dynamic computing of reducts when multigranulation environment is dynamic variation.
- 3.
Using multiple multigranulation rough set approach to design classifier.
Acknowledgment
This work is supported by the Natural Science Foundation of China (Nos. 61572242, 61503160, 61305058, 61373062, 61502211, 61471182), Key Program of Natural Science Foundation of China (No. 61233011), Qing Lan Project of Jiangsu Province of China, Postdoctoral Science Foundation of China (No. 2014M550293), Philosophy and Social Science Foundation of Jiangsu Higher Education Institutions (No. 2015SJD769).
References
Cite this article
TY - JOUR AU - Xibei Yang AU - Suping Xu AU - Huili Dou AU - Xiaoning Song AU - Hualong Yu AU - Jingyu Yang PY - 2017 DA - 2017/01/01 TI - Multigranulation rough set: A multiset based strategy JO - International Journal of Computational Intelligence Systems SP - 277 EP - 292 VL - 10 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.2017.10.1.19 DO - 10.2991/ijcis.2017.10.1.19 ID - Yang2017 ER -