
User Community Detection From Web Server Log Using Between User Similarity Metric
 , K. Muneeswaran
, K. Muneeswaran- DOI
- 10.2991/ijcis.d.201126.002How to use a DOI?
- Keywords
- Session identification; Sequential pattern mining; Clustering; Community detection
- Abstract
Identifying users with similar interest plays a vital role in building the recommendation model. Web server log acts as a repository from which the information needed for identifying the users and sessions (pagesets) are extracted. Sparse ID list and Vertical ID list are used for identifying the closed frequent pagesets which is beneficial in terms of memory and processing. The browsing behavior of a user is identified by computing similarity among the pageset that belongs to the user. A new metric for measuring within user similarity is proposed. The novelty in this approach is, only the users having consistent behavior over the time are taken into consideration for clustering. Consistent users are then clustered by different clustering techniques such as Agglomerative, Clustering Large Applications Using RANdomized Search (CLARANS) and proposed Density-Based Community Detection (DBCD). The quality of the clusters formed by DBCD is found to do better for clustering the users. The outcomes show significant improvements in terms of quality and speed of the clustering.
- Copyright
- © 2021 The Authors. Published by Atlantis Press B.V.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
In order to hold the present market needs, the way in which the business firm makes decision changes day by day. Making right decision at right time is important for the enhancement of the business. The recommendation model plays an important role for making such decisions. Nowadays people prefer to use website for any kind of transactions, therefore it is inevitable to provide service in a way that it would satisfy their interest and needs. The interest of an individual can be found out by discovering hidden navigational patterns. Context aware interactive web page navigation with prediction capabilities has necessitated the web page usage mining in extracting the patterns from web server logs [1].
Pattern mining is the process of discovering interesting, useful, hidden and unexpected patterns from the dataset. Various types of patterns that can be identified include frequent item sets, sequential rules and periodic patterns. In those types of patterns, sequential patterns plays a major role in numerous real life applications such as bioinformatics, e-learning, market basket analysis, texts and webpage click-stream analysis due to the fact that data is naturally encoded as sequences of symbols.
Frequent itemset mining and association rule mining deals with identifying the set of items which occurs together in a transaction and relationship between the items [2–5]. They do not take it into consideration the order of the items in the transaction. The drawback of this methodology is that it may not be appropriate for sequence prediction type of applications where the order of items is important. Ref. [6] made use of the sequential rule pattern to explore the user behavior and foresee whether they are intruder or not.
Sequential pattern mining is a data mining task specialized for analyzing the data, to discover sequential patterns [7]. More precisely it is the process of discovering interesting subsequence from a set of sequences, where the interestingness of the subsequence can be measured in terms of various criteria such as its occurrence frequency and length. On the other hand sequential pattern mining is concerned with finding statistically relevant patterns among the data examples where the values are delivered in a sequence.
Sequential pattern mining has numerous applications in the area of medicine, DNA sequencing, Web log analysis, computational biology. Large amount of sequence data have been and continue to be collected in genomic and medical studies, security applications, business applications, etc.
In Web log analysis, the behavior of a user can be extracted from member records or log files. In this case, the sequences could be sequence of Web Pages visited by users on a website. Then a sequential pattern mining algorithm can be used to discover sequences of web pages that are often visited by users [8].
Ref. [9] proposed a Generalized Sequential Pattern Mining (GSP) Algorithm which is faster compared to the Apriori approach. It performs a level wise search where n-length sequences are generated from
To overcome the limitations in previous approaches, pattern-growth algorithm was introduced where the patterns in original database is scanned repeatedly for generating larger patterns instead of forming larger patterns from smaller ones [12,13]. Projected database was used to reduce the database scan. The drawback of this approach is database must be scanned repeatedly to form projected database. In this approach the time taken for constructing the itemset depends on the size of the projected database and for lengthy sequence it takes longer time. In our approach we have used the vertical representation to overcome it.
Many researches were carried for grouping users and for finding communities where each user is considered as a point in the Euclidean space [14,15]. The similarity among the users is found by computing pairwise distance between the points in the space. The network-based approaches Refs. [16–18] takes as input the graph and identifies communities based on the edges/link that exists between the pair of users. Many hierarchical clustering-based approaches were proposed for identifying communities [19–21]. Ref. [19] made use of the PrefixSpan algorithm for generating the frequent patterns. To reduce the number of patterns generated, only patterns whose length is greater than three is taken into consideration. The travelers were grouped based on the patterns generated. The problem with this approach is that if the size of the dataset is large and number of patterns with length>3 is used then the process becomes costlier in terms of time and space. The problem with hierarchical clustering is they are good at discovering strong communities but they cannot be used for finding arbitrary shaped clusters. The goal of this paper is to cluster the data points associated with the users to form communities even they are distributed in an arbitrarily shaped cluster.
The contribution of this paper is (i) extended log format is used for session identification, (ii) a density-based clustering algorithm is used for finding community among the users of arbitrary shape, (iii) closed frequent pageset (CFP) is used instead of frequent pageset (FP) thus reducing the search space, (iv) vertical representation is used for identifying the FP and the CFP to avoid the usage of projected database and scanning the database multiple times, (v) the processing time and usage of memory is reduced by considering only consistent users who repeatedly visits the similar set of pages for clustering instead of including all users. During the mining process, a non-Euclidean distance metric is used for computing the similarity between the users based on the sequence of pages visited by them. The recommendation model could use the clusters formed to generate suggestions specific to a user.
The rest of the paper is structured as follows. In Section 2, the past works done with regards to the proposed work are examined. Section 3 details the proposed work which includes the expulsion of information which is not significant, identifying unique users, grouping of records of a specific user and grouping users of similar interest. Section 4 examines the trials that are carried out and the outcomes received. Section 5 gives review and the enhancement that can be carried out.
2. RELATED WORK
Due to advent of many applications added to the digital era, Web mining has gained momentum in recently. The web log files forms the major source for Web Usage Mining. The web log files can be collected from web server, proxy server and client (browser). Log files stored in the web server contains information about the users accessing the web site. It contains information such as date and time of access, IP address of the client, page requested, browser, Operating System (OS) and other information related to the user. Proxy server acts as an intermediator between client and the web server. Caching at proxy reduces the response time and network traffic [22]. The Log files stored in proxy server contains information about several users using the same proxy server. Log files stored in client side can be used to collect data about the client and avoids the problems associated with identifying the sessions. But for collecting the data at client side requires the cooperation of the client. Client side log file can be used for identifying user navigation behavior [23,24]. In order to collect data about different clients using different proxy servers, it is best to use the Web server log files. In our approach we have used Web Server Log file for collecting data.
In a web mining work, data cleaning forms the core part of session identification [25]. It deals with extracting relevant details from the web log file by converting the unstructured data into a structured format. Whenever a page is visited several image files are also downloaded and an entry will be created in web log file. These log entries must be deleted as part of data cleaning. The cleaned data can be stored in the log table for further processing [26]. IP address field from web server log can be used for user Identification [27]. The problem with this approach is if website is accessed through proxy server then multiple users will be having the same IP address. It can be used in applications like server side caching where importance is given to the pages which are frequently visited and not to find out who visited the pages. Cookie-based user identification is proposed by Ref. [28] which requires user cooperation.
Session Identification deals with identifying the sequence of web pages visited by the user over a period of time. Two different heuristics are adopted for identifying the web sessions. In time-oriented heuristics page stay time or fixed session duration is used for identifying the sessions. In referrer-based heuristics the link between the web pages are used for identifying the sessions.
In the work proposed by Ref. [23] a time threshold of 30 minutes was used for identifying a session that belongs to a user, where they have studied the relation between the average frequency with average path length per site per visit. This session duration of 30 minutes is still being used in many research works. Many researchers have adapted different strategies for identifying the sessions in terms of duration, referrer based and its combination of these [29–32]. Ref. [33] made use of the sitemap for identifying the link between web pages. The problem with existing approaches is they have used the common log format (CLF) for session identification. The requested url of previous entry and requested url of subsequent entry is used for finding the link between the WebPages. In our approach we have used the extended log format which includes the referrer url field for finding the link between WebPages.
Closed frequent itemset can be considered as the lossless representation of the frequent itemset. CloSpan [34] algorithm first generates candidate CFPs and then performs postpruning. If there are large numbers of CFP then more memory space is needed and time taken for checking the closure property is also high. In Ref. [35] Bi-Directional Extension (BIDE) algorithm was proposed for finding CFP without candidate generation. It makes use of the projected database for finding frequent sequences. It is suitable for dataset which sparse and low support threshold. Clasp [36] made use of the vertical database format for finding the CFP and computing the support without scanning the entire database. It may produce large number of patterns which are not in the input. Ref. [37] introduced a data structure named co-occurrence map (CM) which can be integrated with any of the vertical mining algorithms which greatly reduced the time taken for mining the closed frequent items. CloFAST algorithm was presented by Ref. [38] which uses sparse ID lists and vertical ID lists to compute the support of the sequential patterns quickly.
User community detection/Clustering is one of the major applications of the data mining tasks where the likeminded users could be brought under one group. Many researches were carried out for clustering based on the usage of the FP [39,40]. Ref. [41] used the ratings of the items in the itemset for clustering the users by giving weightage for the items. Ref. [42] made use of agglomerative hierarchical clustering for clustering the sessions and Similarity Between Session (SBS) measure for finding similarity between the patterns. An initial method for setting the initial partitions and number of clusters was proposed in Ref. [43]. Ref. [44] made use of the Density Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm for clustering the sessions and sequence similarity measure for finding the similarity between patterns. Problem with this approach is the weightage for given for the set similarity and sequence similarity must be chosen appropriately as it determines the quality of clustering. Ref. [45] made use of self-organizing map (SOM) for clustering the students. But SOM is ideal for generating only low-dimensional input-space representation. A divide and agglomerative algorithm was used to find the user communities in social networks [46]. Ref. [47] proposed a framework which makes use of density-based techniques for semi supervised clustering. A recommendation model by clustering the users using agglomerative clustering was proposed by Ref. [48] in which the similarity between items preferred by the users are taken into account and not the order of the items.
3. PROPOSED WORK
User Community detection involves various steps such as i) Data Preprocessing, ii) User/ PageSet Identification, iii) CFP Identification, iv) User Community Detection/ Clustering users based on similarity. The architecture of the entire process is given in Figure 1.
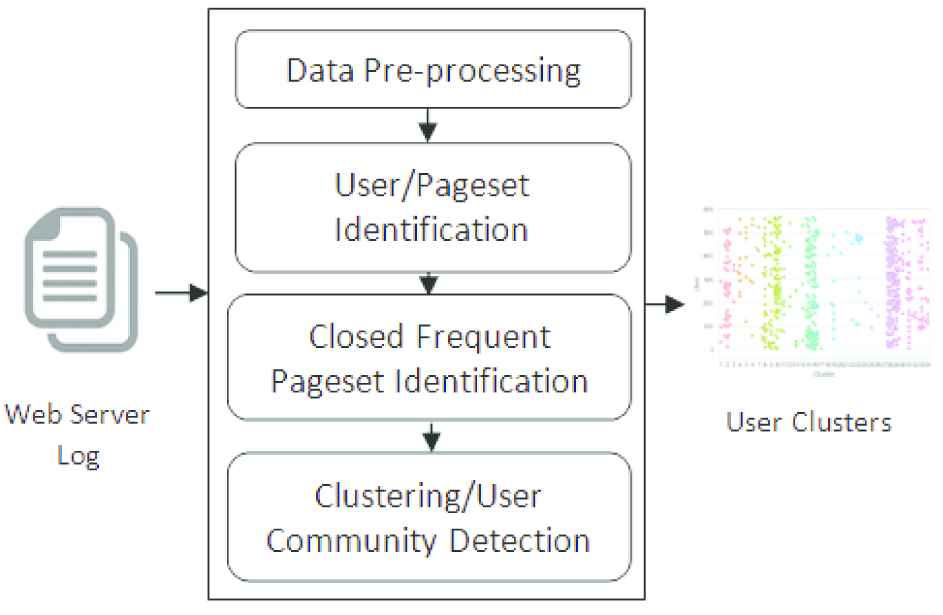
Block diagram of the user community detection.
In data preprocessing the unstructured data is converted into structured data to extract the needed information. Records which are not relevant to group the users such as image request, robot request and unsuccessful request are removed during preprocessing. After preprocessing the records that belong to individual users are identified based on the IP address, browser and OS. In order to identify the sequence of pages (pageset) visited by the user, requested url and referrer url of the log record is used and the sequence of pages visited by the user is grouped into multiple pagesets/sessions [49].
The identified users and the pagesets are given as input to the CFP identification process. It is used for reducing the voluminous number of redundant pagesets associated with each and every individual user. The CFPs associated with the users undergoes the clustering process. The within user similarity metric is used for checking whether a user has consistent navigation behavior or not. If the user is not consistent then the users along with their pagesets are removed from further processing. Various clustering techniques are applied on the identified consistent users and are clustered based on their CFPs. The resultant clusters are evaluated using the intrinsic quality measure. The proposed work is suitable for clustering when a user can be represented as a data point in the pattern space and the distance metric used is non-Euclidean. The advantages of using our proposed approach are i) the memory space and processing time is reduced by considering the CFPs instead of FPs for clustering, ii) importance is given to sequential order rather than frequency of the pages visited by the users while computing similarity, iii) taking into account only the users who repeatedly visits the same set of pages will improve the accuracy of recommendation.
3.1. Closed Frequent Pageset (CFP) Identification
Sessionization results in the generation of large of number of pagesets for one user. In order to reduce the number of pagesets only FPs are taken into consideration, for clustering. Pageset Support can be defined as the number of sequences which contains the pageset relative to the total number of sequences. Minimum support (msup) is defined as the minimum pageset support required for classifying a pageset as FP.
Example 3.1.
FP is defined as the set of page(s) visited by the user whose support is greater than a specific threshold. Let us consider a user who visits the pages of a website in the following sequence over period of time t1 = <1, 3, 4>, t2 = <1, 2, 4, 3>, t3 = <4, 5> and t4 = <3, 2, 4>. The pages frequently visited by the user are
Example 3.2.
Maximal Frequent PageSet (MFP) is defined as the set of page(s) visited by the user which does not have any superset in the FP generated. It does not take into consideration the support (sup). For the above example the maximal frequent pages are
Example 3.3.
CFP is defined as the set of page(s) visited by the user which does not have any superset with the same support in the FP generated. If FP =
If the FP generated by PrefixSpan algorithm is used for clustering the users then each individual user will be having a large number of FP and the time taken for processing the pageset will be high [19]. To improve the time complexity, Sparse ID list (Slist) and Vertical ID list (Vlist) used in CloFAST algorithm is employed to identify the CFP. The identified CFP is used for clustering the users which is our contributory work not cited in any existing literature [38]. The supports of individual pages in Session database S are identified using the sparse ID list. Individual Pages whose support is greater than msup threshold is identified using the algorithm findClosedSequence and is given as input for the sequence extension process. To check whether a sequence can be extended or not, vertical ID list (Vlist) is used. Vlist can be computed from Slist. A sequence can be extended by adding the last page of the sibling to the sequence being extended and by adding the last page of the sequence to itself. The closed sequence tree data structure is used for storing the closed sequential patterns generated as given in extendNodeSequence algorithm. The algorithm is applied to each and every user to identify the CFP of that user.
Example 3.4.
Sparse ID list (Slist) for a page is used for storing the position of the page in respective sessions. Consider a Session Database S which consists of a set of sessions as shown below:
| SessionID | Pages Visited | |||
|---|---|---|---|---|
| S1 | 1 | 2 | 3 | 5 |
| S2 | 5 | 3 | 5 | |
| S3 | 2 | 4 | 3 | 2 |
| S4 | 1 | 3 | 5 | |
Each session consists of a set of pages P. For every individual page present in S, Slist is computed which enables fast computation of support of the page. Slist for a page p(Slist (p)) is used for storing the position of the page p in respective sessions. Support for a page is computed by counting the number of nonnull list in Slist.
In session S1, page 2 has occurred at position 2 and in session S3 it has occurred at position 1 and 4. In sessions S2 and S4 it has not occurred so it is represented as 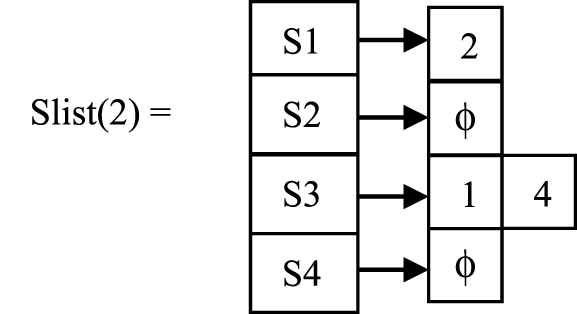
Example 3.5.
Vertical ID list (Vlist (p)) is used for storing the first occurrence position of the page in respective sessions. For the sequence database given in Example 3.4 the Vlist for the page 2 can be computed as follows:
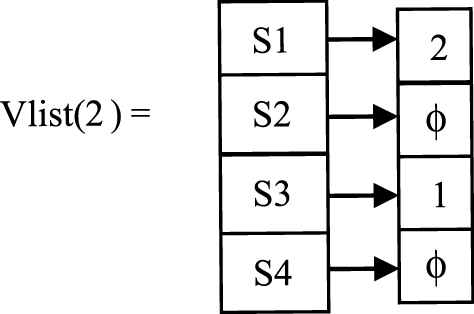
If a sequence consists of n pages Vlist can be computed by taking the first occurrence of the last page (nth page) after 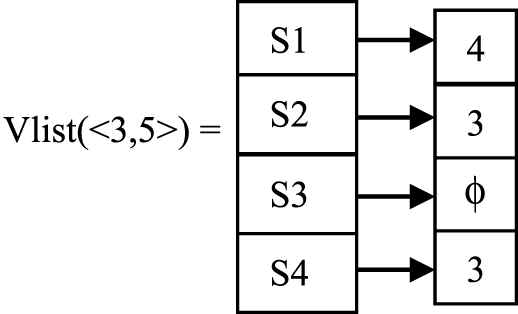
Slists(p) represents the position of page p in session s and Vlists(p) represents the first occurrence position of page p in session s. Slists1(3) = 3 specifies that the page 3 has occurred at position 3 in session S1 and Slists1(5) = 4 specifies that the page 5 has occurred at position 4 in session S1. As Slists1 (3) < Slists1(5), place the value of Slists1(5) in Vlists1(<3, 5>). Position of 5 in session S2 is Slists2(5) = [1, 3]. Slists2(3) = 2 and first value in Slists2(5) = 1. Here 2> 1 so try to find the next position of 5 such that its position comes after page 3 called as Virtual Shifting. From Slists2(5) it is found that the next occurrence position of 5 in S2 is 3 which comes after Slists2(3). So place 3 in Vlists2(<3, 5>). In S3, Slists3(3) = 2 but Slists3(5) =
Example 3.6.
Closed Sequence Enumeration Tree is used for representing the closed sequences and for enumerating new sequences from existing sequences using depth first search strategy. Vlist is used for checking whether a sequence can be extended are not. Root node is represented by 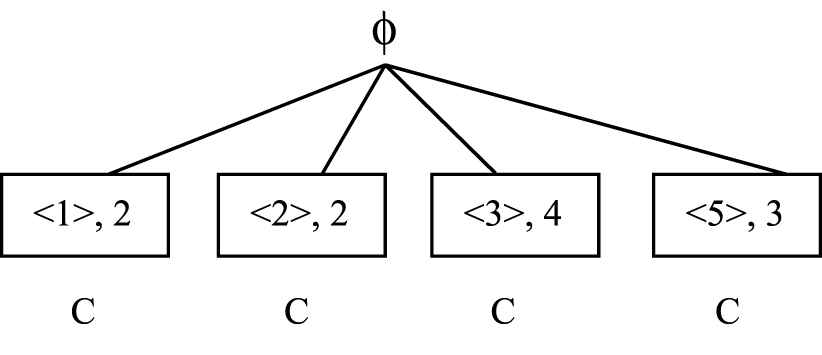
Initially all the nodes are assumed to be closed (C) and during extension they are either marked as nonclosed (NC) or unpromising (U). If a node is labeled as NC then one of its descendant is closed with same support, unpromising means the node has a supersequence with the same support in other branches of the tree. During extension if the support of the new sequence is less than msup it is not added to tree.
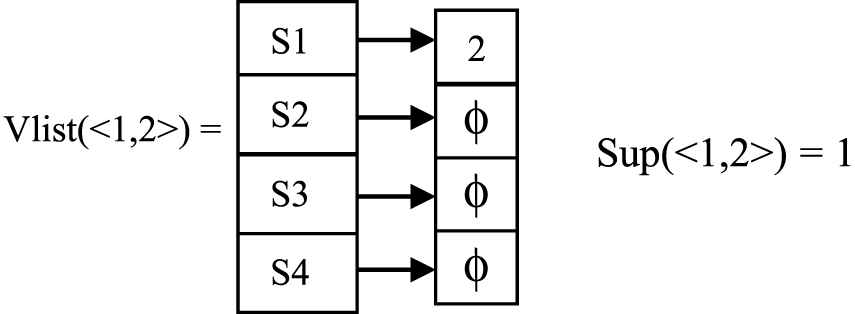
Node extension starts with 1. The node is extended by adding the last sequence in the siblings and by adding last sequence in itself. So possible extensions of sequence <1> are {<1, 2>, <1, 3>, <1, 5>, <1, 1>}. First <1, 2> is taken. Vlist<1, 2> is computed from Slist(1) and Slist(2) and support calculated from Vlist(1, 2).
Sup(<1, 2>) < msup, so sequence <1, 2> is not added to the tree. For next extension <1, 3> is taken. Compute Vlist(<1, 3>) using Slist(1) and Slist(3).
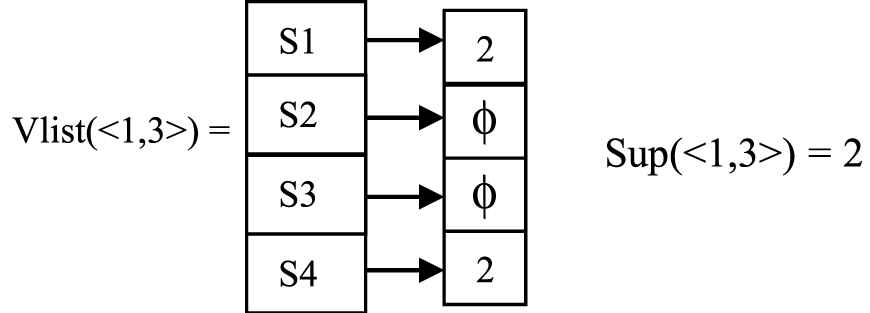
Sup(<1, 3>) is greater than msup. If a supersequence exists in other branches of the tree with same support it is not added. Otherwise it adds a node for the new sequence and checks the following conditions: If any ancestor until
Since there is no supersequence for <1, 3> in the tree with same support, it is added as child of the node with sequence <1> in the tree. Ancestor of <1, 3> is <1>. The support of the ancestor <1> is same as <1, 3>, so it is marked as NC. Sibling of the ancestor <1> whose sequence is subsequence of <1, 3> is <3>. Since Sup(<3>) is not same as Sup(<1, 3>), no changes is done to <3>.
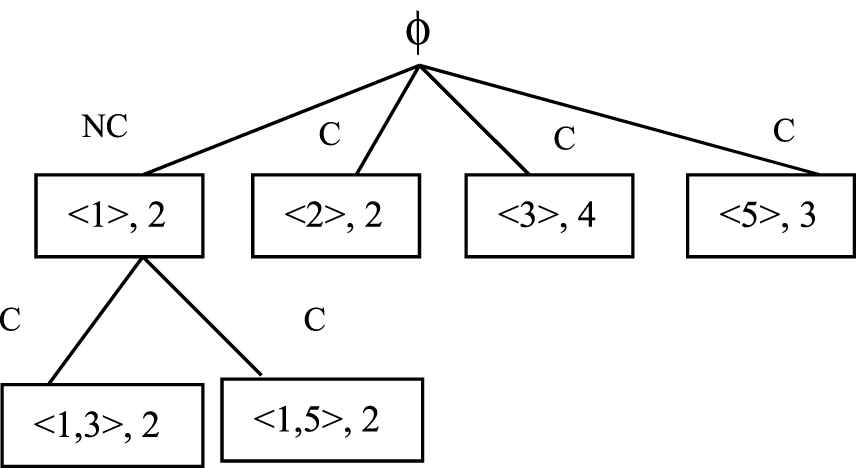
Similarly the Vlist(<1, 5>) and Vlist(<1, 1>) are computed. Sup(<1, 5>) = 2 and Sup(<1, 1>) = 0. Sequence <1, 5> is added to the tree and sequence <1, 1> is not added to the tree.
Now the first child of <1> will be extended in a depth first manner. Possible extension of the sequence <1, 3> are {<1, 3, 5>, <1, 3, 3>}. First <1, 3, 5> is taken. Vlist<1, 3, 5> is
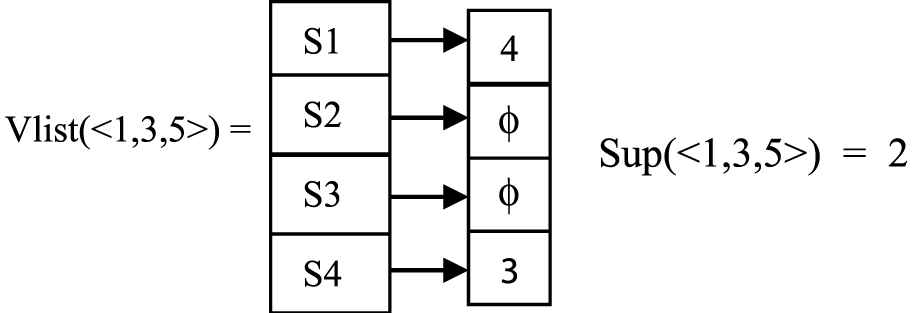
Sup(<1, 3, 5>) is greater than msup. Ancestors(<1, 3, 5>) with same support = {<1, 3>, <1>}. They are marked as NC. Subsequences(<1, 3, 5>) in the tree = {<1, 5>, <5>}. <1, 5> is having same support as <1, 3, 5>, so it is marked as unpromising and it will not be extended further. <5> is having different support, so no changes will be done.
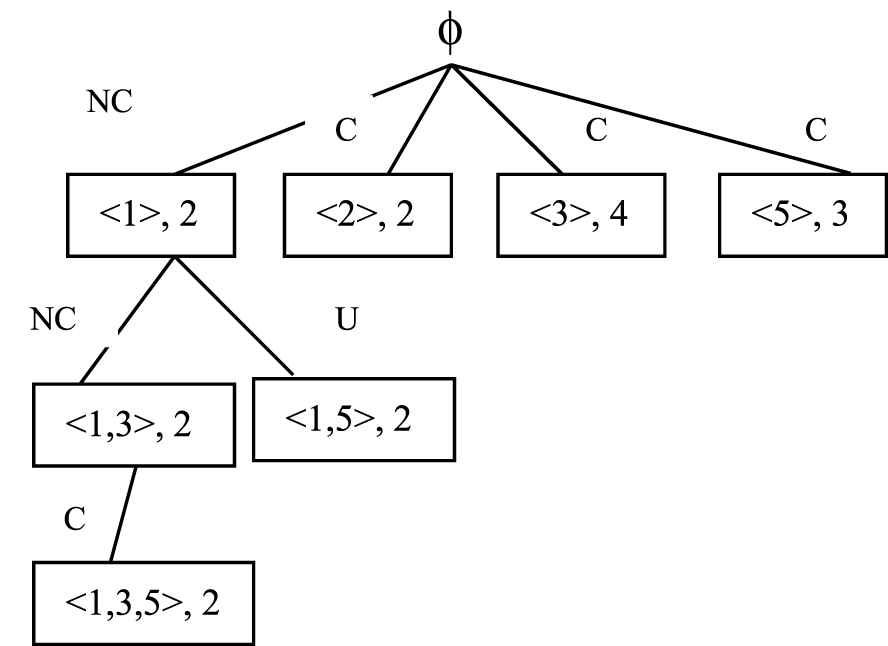
Sup(<1, 3, 3>) is 0 so it is not added to the tree. Since <1, 3, 5> is not having any sibling it will not be further extended. It moves up one level. <1, 5> is unpromising so it is not extended. In previous level it moves to the node with sequence <2> for further extension. The process is repeated until all the children of root are extended.
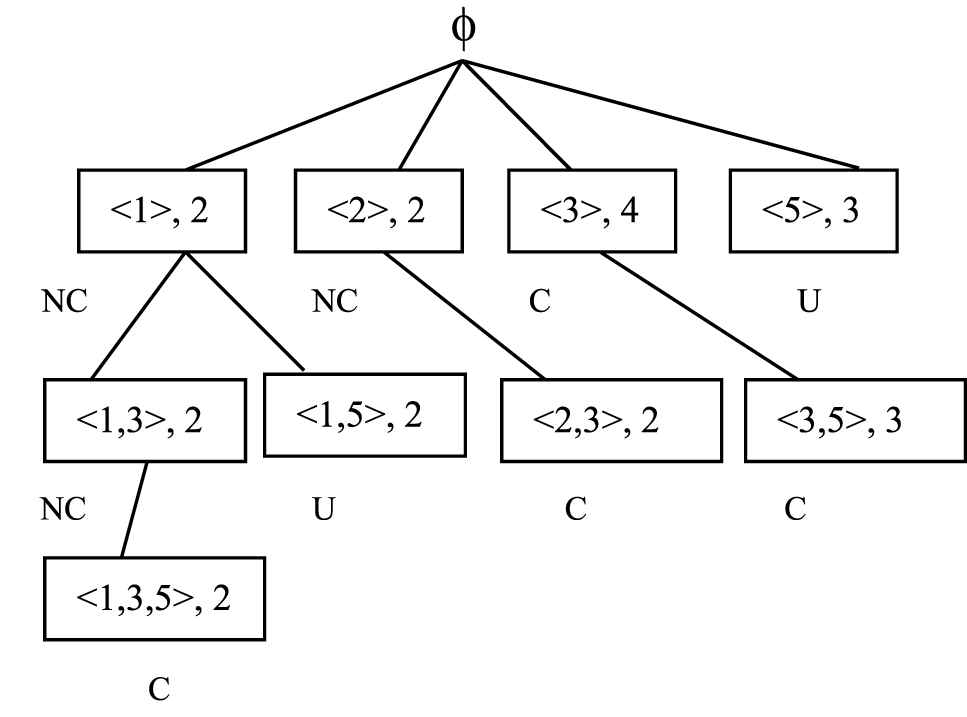
The sequences in the node marked as C represents the closed sequential pattern generated. The Closed Sequential Patterns = {<1, 3, 5> Sup:2, <2, 3> Sup:2, <3, 5> Sup:3, <3> Sup:4}. The sessions belonging to individual users can be considered as a session database. For each user the closed sequential pattern mining algorithm is applied and the CFPs are generated.
3.2. User Community Detection
User community detection is the process by which users with similar interest are grouped together based on their navigation patterns. For grouping users with similar interest the similarity measures must be properly defined. As large number of users are identified, to reduce the processing time and to improve the quality of clustering we take into consideration the consistent behavior of the users. A user is said to have consistent behavior if he repeatedly visits the same set of pages. In order to identify the consistent user, within user similarity measure is used.
Algorithm 1: findClosedSequence
Input: S - Session Database, msup – minimum
support
Output: CS - closed sequence tree which contains
closed frequent pagesets
CS.root =
for each unique sequence
s.constructSlist()
s.Sup = computeSupport(s.Slist)
if(s.Sup > msup)
// create a new node with sequence s
newNode = CS.createNode(s);
newNode.label = "closed"
newNode.Vlist = constructVlist(newNode.Slist)
//add newNode as child of root in the CS tree
CS.addChild(root, newNode);
end if
end for
for each n
extendNodeSequence(CS, n, msup)
end for
return CS
PageSet Similarity (ρ):
For any given two pageset (p1, p2) the PageSet Similarity (ρ) can be calculated using Eq. (1) which is simplified version of the equation given in Ref. [19].
|p1| - Number of pages in p1 pageset
|p2| - Number of pages in p2 pageset
The value of ρ lies between 0 and 1. A value closer to 1 indicates pageset are closer to each other otherwise not.
Example 3.7.
Let p1= <2, 3, 4, 6, 7>, p2= <3, 4, 7, 8> be the pagesets.
Within User Similarity (γk):
The similarity between pageset that belongs to a user can be computed using γk. As proposed by Ref. [19] the within user similarity can be computed using Eq. (2).
n- represents the number of pageset/session of user k
pik, pjk represents ith and jth pageset/session of user k
ρ- similarity between two pagesets
Algorithm 2: extendNodeSequence
Input: CS - closed sequence tree, n - node, msup -
minimum support
if(n.label= "Unpromisin g")
return
end if
// sequence extension is trying to merge with the
last sequence of siblings of a node
for each s
// create a new vlist u sin g vlist of node
// and its sibling
ns = extendSequence(n, s)
ns.Vlist = computeVlist(n.Vlist, s.Vlist)
// compute support(Sup) of the new sequence
ns.Sup = computeSupport(ns.Vlist)
if(ns.Sup >= msup)
newNode = CS.createNode(ns)
newNode.label = "closed"
// To check whether the new sequence
// can be added to the tree and for updating the
// labels of other nodes in the tree
for each node x
if(x.isAncestor(newNode) and
x.isSubSequence(newNode) and
x.Sup = newNode.Sup)
x.label = "NonClosed"
else if(x.isSubSequence(newNode) and
x.Sup = newNode.Sup)
x.label = "Unpromisin g"
else if(x.isSuperSequence(newNode) and
x.Sup = newNode.Sup)
newNode.label = "Unpromi sin g"
// exit for loop
Break
end if
end for
if(newNode.label = "closed")
CS.addChild(n, newNode)
end if
end if
end for
// now all childs of n will be created.
// for each child of n try to find the
// extension.It is a DFS approach
for each child
extendNodeSequence(CS, child, msup)
end for
Every pageset visited by the user is compared with his own pagesets. Problem with this approach is if
(p1p1, p1p2, p1p3, p2p1, p2p2, p2p3, p3p1, p3p2, p3p3) Here
The value of γk lies between 0 and 1. If user k repeatedly visits the same sequence of pages then the value of γk is closer to 1. A user is said to have a consistent behavior, if the γk value is above a specific threshold δ, which is set as 0.5.
Example 3.8.
Let us consider a user u1 with pagesets PS = (p1, p2). If p1= <1, 2, 3>, p2= <4, 5> then using the Ref. [19] approach
Though there is no relation between the pagesets p1 and p2 the similarity value is 0.5 which is not desirable.
Using our proposed approach,
The within user similarity value is 0 which specifies there is no relation between the pagesets p1 and p2.
Between User Similarity (β):
Once the users is having consistent behavior, they can be clustered together based on between user similarity measures. The similarity between two users can be computed using β as given in Eq. (4). The similarity measure is symmetric as
Ui- ith User
Uj- jth User
β(Ui, Uj)i- similarity between Ui and Uj w.r.t Ui
β(Ui, Uj)j- similarity between Ui and Uj w.r.t Uj
x- number of pagesets belonging to Ui
y- number of pagesets belonging to Uj
s(pin)- support of nth pageset of Ui
avg- average of the support of the given pagesets
Best match pageset represents the pageset which has highest similarity to the pageset of a user. Let us assume that there two users U1 =
The value of β(Ui, Uj) lies between 0 and 1. If the value is closer to 1 then more similar the users are. The dissimilarity matrix (DM) can be computed using 1-β. The computed DM is given as input for clustering process.
Clustering:
The popular clustering techniques are i) Hierarchical, ii) Partitioning and iii) Density-based clustering [51]. Agglomerative Hierarchical Clustering is a bottom-up approach in which it starts with individual user as a cluster and continues to merge the users until a stopping condition is reached. The stopping condition used in our approach is the optimum number of clusters. To identify the optimum number of clusters various linkage metrics such as complete, single, average, weighted are applied. Based on the dendrogram results the cut-off distance is identified. The number of clusters formed by average linkage at the specified cut-off distance is chosen as optimal number of clusters. The drawback of using hierarchical clustering is ambiguity in the stopping condition and once merging is done it cannot be undone.
To overcome it, the Clustering Large Applications Using RANdomized Search (CLARANS) partitioning clustering applied to identify the user community. The limitation in partitioning clustering is choosing the value of “k” [52]. The optimal number of clusters found by hierarchical clustering is set as the value of “k.” The advantage of partitioning clustering over hierarchical clustering is it is an iterative approach and the quality of clusters formed is improved in subsequent iterations. CLARANS are lesser sensitive to outlier and it does not depend on order of comparison performed. The problem with this approach is that it identifies only spherical shaped clusters and it is difficult to find arbitrary shaped clusters. The runtime for CLARANS is very high for large datasets.
To identify user community of arbitrary shape a modified form of DBSCAN, a density-based clustering algorithm, userCommunityDetection algorithm (Density-Based Community Detection [DBCD]) is applied. It is used for identifying the community among users and findNeighbors algorithm is used for finding neighbors for a specific user. The density-based clustering algorithm does not require specifying the total number of clusters. It can be used to identify the relation among the data that are difficult to infer manually.
The time complexity is O(m|η|) where m is the number of users and |η| represents the number of neighbors of m. The space complexity is O(m2) as the DM must be stored in memory. The parameters required for the algorithm are minN and epsilon (ε). The term minN specifies the minimum number of neighbors required for forming a dense region. The users having minN neighbors are called core users. Core users are the core samples with high density from which the cluster can be expanded. If a user is having minN neighbors it is assumed that they have high density. The symbol ε specifies the minimum of distance between two users to consider them as neighbors. If the core users are within ε distance they are grouped into single cluster. All users directly reachable from the core user or through other core user will be added to the cluster to which the core user belongs to. The set of users accessing the website can be represented as Internal representation of users and sessions.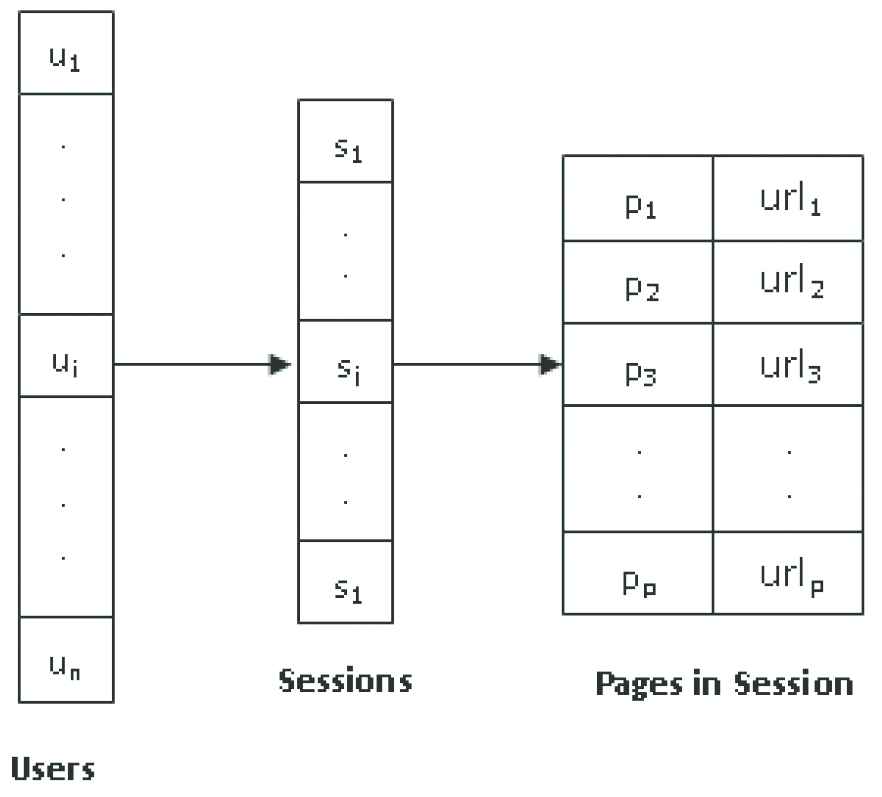
Figure 3 shows a graph
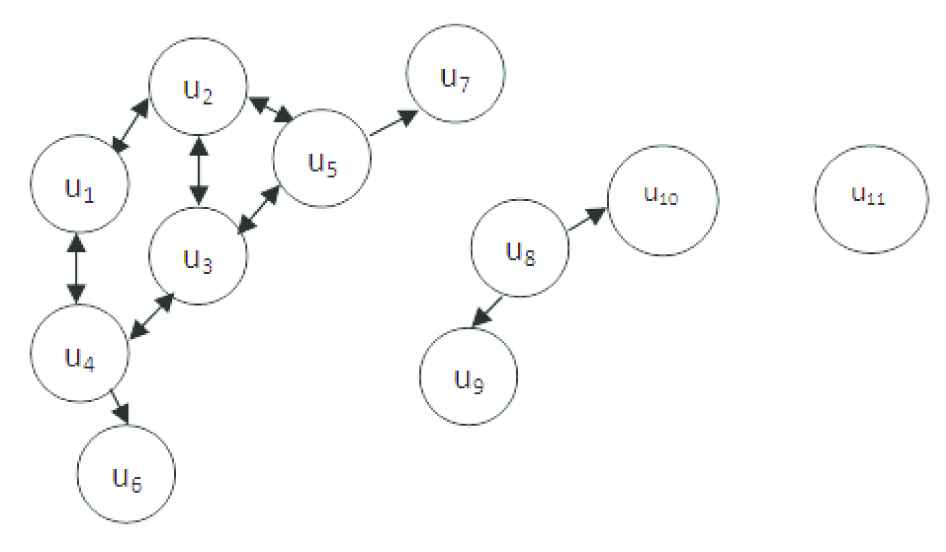
Graph model for the web user community.
If
The set of communities formed by the userCommunityDetection algorithm can be represented as
The quality of clusters formed by different clustering techniques is validated using silhouette coefficient (SC), an intrinsic validity measure which is one of popular methods to assess the quality of the clustering. Since the ground truth labels are not known only the intrinsic clustering index (SC, Calinski-Harabaz Index, Davies Bouldin index) can be used for evaluating the quality of clusters formed. Calinski-Harabaz Index is suitable only if the clusters are spherical and the clustering elements lie in the Euclidean space. Davies Bouldin index involves computation of centroid and is applicable for objects in Euclidean space.
As our work related is non-Euclidean space, we have used SC for cluster evaluation which was found suitable. The scientific contribution of our proposed work lies in the use of within user similarity which reduces the number of users and CFP which reduces the number of pagesets within the user. As number of users and pagesets are reduced, time taken for the clustering is reduced. Since network-based approaches are suitable for applications whose topology is known we have experimented with other clustering approaches such as partitioning-based method (CLARANS), hierarchical clustering method (agglomerative) and DBCD and their results are evaluated and discussed in Section 4.
Algorithm 3: userCommunityDetection
Input: US: HashMap<User, List<Session
minN- minimum number of neighbors,
Output: UL - HashMap<User, clusterLabel>
c = 0
for each user u in US
// if
if
US.remove(u)
end if
end for
for each user u in US
for each user v in US
// β(u, v) is the between user similarity
compute β(u, v) using Eq. (4)
// d(u, v) is the distance between user u and
// user v
end for
end for
for each user u in US
if(is_set(label(u)) then
continue
end if
//if number of neighbors < min N
// label as noise
if
label(u) = noise
continue
end if
c = c + 1
label(u) = c
UL.add(u, label(u))
for each neighbor n in N
// if user already clustered
// move to next user
if (is_set(label(n)) and label(n)!=noise ) then
continue
end if
label(n) = c
UL.add(n, label(n))
// reachable from core user
if
continue
end if
end for
end for
for each user u in US
if(label(u) = noise)
UL.add(u, label(u))
end if
end for
Algorithm 4: findNeighbors
Input: US: HashMap<User, List<Session>>,
m - mth user,
d - dissimilarity matrix
Output:
for each user u in US
if d(m, u) <=
end if
end for
return
4. RESULTS AND DISCUSSION
The web log entries are acquired from the institution where the authors are working over a period of 3 months. The logs are of webserver extended log format. A total of 1402 pages are in the website. The website contains information about the departments, courses offered, curriculum etc., Initially the web server log was having 538308 records. The number of records after data preprocessing is 230005. After preprocessing the number of unique users is identified based on their IP address, OS and browser. From the preprocessed data 31517 unique users are identified. The pagesets produced by pageset identification process is given as input to the CFP identification process.
4.1. Closed Frequent Pageset (CFP Identification)
The classical algorithms for CFP mining such as CloSpan [34], ClaSP [36], CM-ClaSP [37] and CloFAST [38] are implemented and the time taken for computing the CFPs are identified. The runtime of the algorithms by varying the support is given in Figure 4. It is evident from the graph that the runtime of CloFAST algorithm is less compared to other algorithms by the usage of Sparse ID list and vertical ID list.
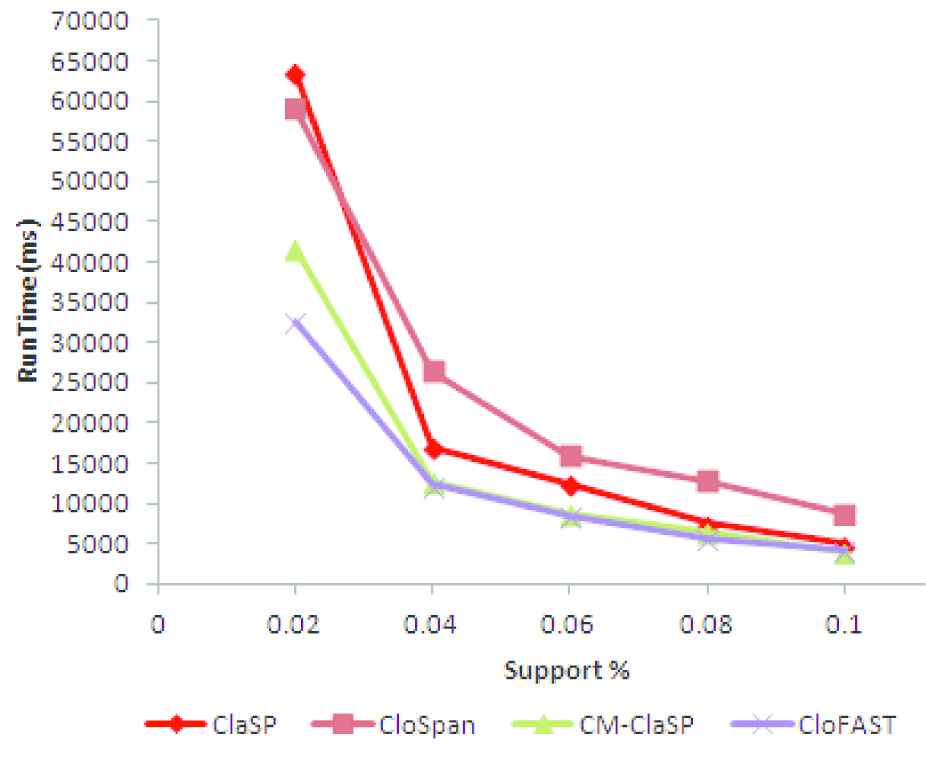
Running time in milliseconds by varying support.
Based on the result, CloFast algorithm is applied for identifying the CFP. The comparison between the PrefixSpan algorithm, used for FP and CloFast algorithm is given in Table 1.
| Metric | Without γk [Number of Users:578] |
With γk [Number of Users:137] |
||
|---|---|---|---|---|
| PrefixSpan [19] | CloFast (Proposed) | PrefixSpan (Proposed) | CloFast (Proposed) | |
| Number of frequent patterns | 2255 | 799 | 609 | 193 |
| Time taken for constructing dissimilarity matrix (in ms) | 68652 | 12637 | 5012 | 609 |
| Memory Usage (MB) | 128.86 | 101.53 | 132.77 | 74.87 |
PrefixSpan versus CloFast.
By taking into consideration all the users without computing within user similarity, the total number of frequent patterns is reduced by 64.57% and the time taken for constructing the DM is reduced by 81.59% and memory usage is reduced by 21.21% by using the CloFast sequential pattern mining algorithm. Considering only the users whose within user similarity is greater than 0.5, the total number of frequent patterns is reduced by 68.31% and the time taken for constructing the DM is reduced by 87.85% and memory usage is reduced by 43.61% by using the closed sequential pattern mining algorithm.
4.2. Clustering
The 137 consistent users along with the CFPs identified by CloFast algorithm is given as input to the clustering process. The consistent users can be considered as the data point in the pattern space.
4.2.1. Agglomerative hierarchical clustering
To determine the optimal number of clusters, agglomerative hierarchical clustering is applied on the FPs. Since the dissimilarity between two pagesets is non-Euclidean, distance metrics such as Single, Complex, Average and Weighted are applied on the FPs. The number of clusters formed at different cut-off distance in the range of 0.1 to 1.0 is shown in Figure 5.
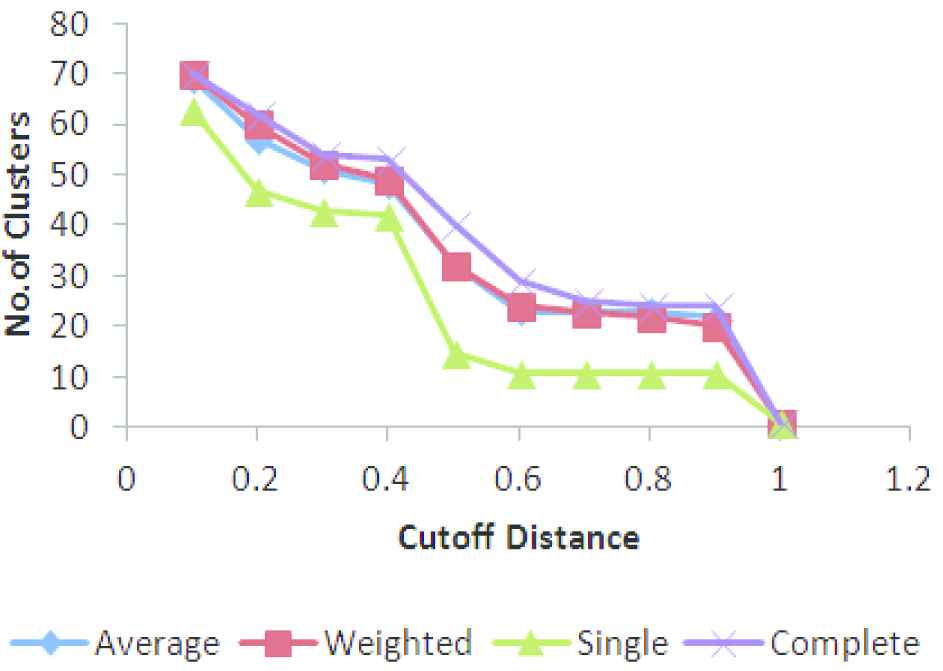
Number of clusters obtained by varying cut-off distance.
The cut-off distance at which majority of the linkage methods coincides is selected for identifying the total number of clusters. The cut-off distance for CFPs generated by CloFast is set as 0.8. Figure 6 shows the number of clusters formed by different linkage methods by setting optimal cut-off distance.
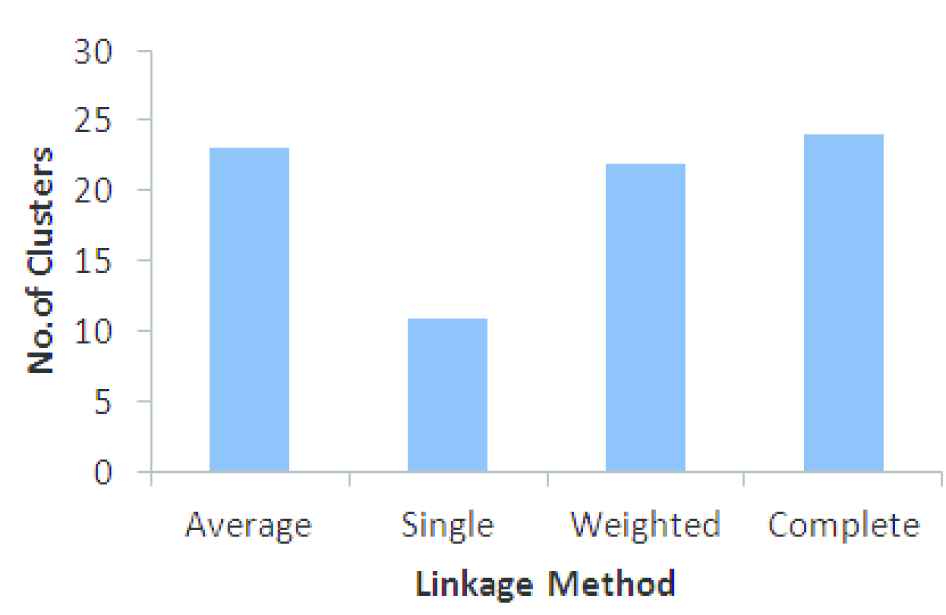
Number of clusters obtained using linkage methods.
To identify the linkage method suitable for clustering, SC is used. It is an intrinsic method which is used for evaluating the quality of clusters formed. The value of SC lies between −1 to 1. The value closer to 1 indicates that the clusters are compact and are well separated from other clusters. The SC denoted as s(u) for a single user u can be computed using Eq. (5).
b(u) - degree to which the user u is separated from other cluster
The SC for various linkage methods is shown in Table 2.
| S. No | Linkage Method | Silhouette Coefficient |
|---|---|---|
| 1 | Average | 0.6124 |
| 2 | Weighted | 0.5821 |
| 3 | Single | 0.1832 |
| 4 | Complete | 0.6035 |
Silhouette coefficient for different linkage methods.
Based on the internal index, Average Linkage method is used for clustering the pageset. The dendrogram obtained by using average linkage agglomerative hierarchical clustering is shown in Figure 7. The horizontal axis represents the number of points in a node within parenthesis or index of the user (without parenthesis) and vertical axis represents the distance between the clusters containing the users.
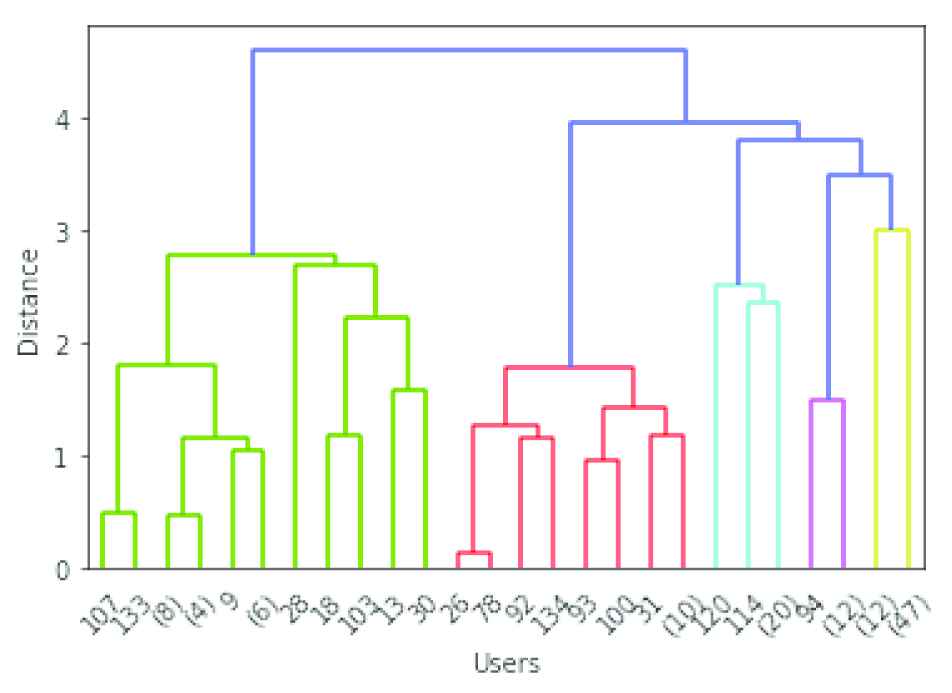
Agglomerative clustering of users.
The optimal number of clusters identified by agglomerative hierarchical clustering algorithm by using average linkage distance metric is 23, which can be set as the value for k.
4.2.2. Clustering Large Applications Using RANdomized Search
It is a medoid-based clustering algorithm, where a graph structure is used for finding the optimal k medoids. Each vertex represents a set of k-medoids. Each vertex has k(n-k) neighbors, where n represents number of users; k represents the number of medoids. Two nodes are said to be neighbors if they differ by only one user. The objective is to identify the vertex with minimum cost.
The optimal number of clusters identified by hierarchical clustering is used as the value of k. Two important parameters to be set in CLARANS are maxNeighbors and numlocal. The term maxNeighbors represents the number of neighbors inspected and numlocal represents the number of local minima found. The quality of clusters formed by setting numlocal as 2 and by varying the maxNeighbor is tabulated in Table 3. The silhouette plot of the consistent users clustered using CLARANS is given in Figure 8 which shows the density and separation of the clusters formed. The red line represents the average silhouette score.
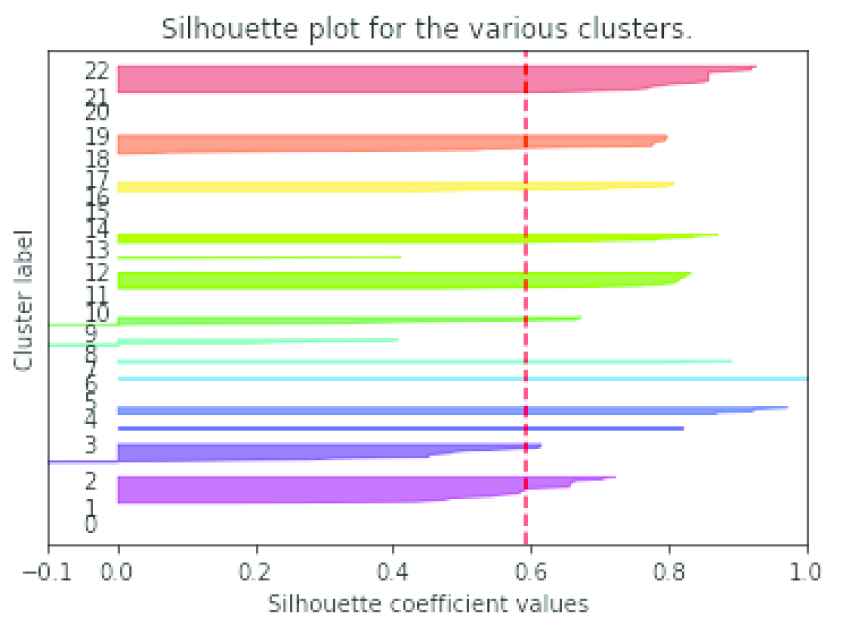
Clusters formed using Clustering Large Applications Using RANdomized Search (CLARANS).
| S. No | maxNeighbor | Silhouette Coefficient |
|---|---|---|
| 1 | 100 | 0.5238 |
| 2 | 150 | 0.5326 |
| 3 | 200 | 0.5460 |
| 4 | 250 | 0.5924 |
Silhouette coefficient for varying number of maxNeighbor.
4.2.3. Density-Based Community Detection
The parameters required for DBCD are minN and epsilon (ε). minN is set as 3, so that a user has at least 3 neighbors within ε distance to make it suitable for recommendation. The quality of clusters formed by setting
| S. No | ε | Number of Clusters | Number of Users Clustered | Silhouette Coefficient |
|---|---|---|---|---|
| 1 | 0.1 | 11 | 75 | 0.8733 |
| 2 | 0.2 | 9 | 93 | 0.8040 |
| 3 | 0.3 | 10 | 99 | 0.7830 |
| 4 | 0.4 | 10 | 101 | 0.7471 |
| 5 | 0.5 | 3 | 123 | 0.2192 |
Silhouette coefficient for different values of ε using closed frequent pageset and within user similarity (Number of users: 137).
If ε value is too small then large part of the users are not clustered and are considered as outliers. If the value chosen is too large then clusters will be merged together and the quality of clusters formed will not be good. So the value of 0.3 is chosen for clustering the users.
The silhouette plot of the consistent users clustered using DBCD is given in Figure 9. It shows the density and separation of the clusters formed. The red line represents the average silhouette score. The cluster number −1 represents the outliers. Out of 137 users 98 users are clustered and the remaining are the outliers. It is interesting to learn web usage behavior by probing into the history of the user’s sessions, which enables recommendation of the next page to be popped. Recent literatures reveal that many of the researchers focus on only FPs and clustering has been completed to predict the web navigation behavior of the unknown users.
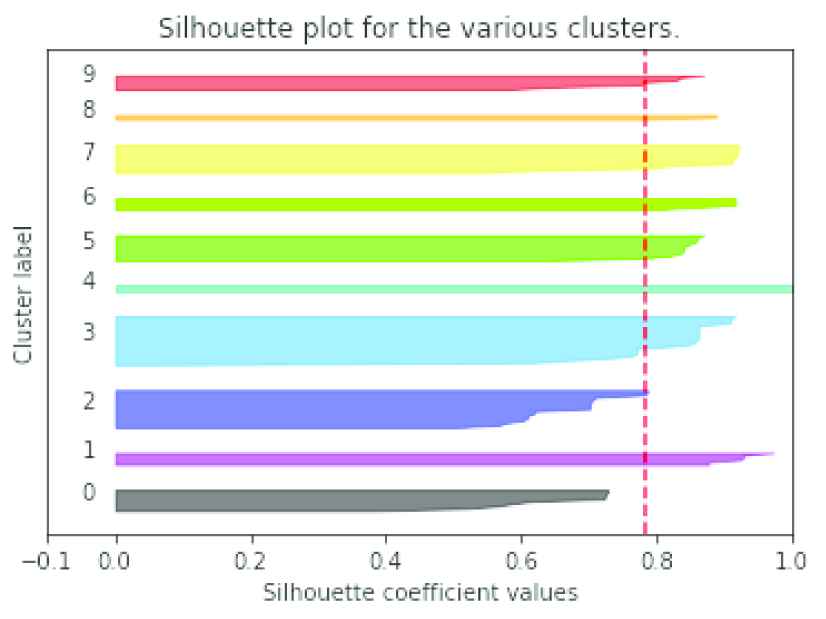
Clusters formed using Density-Based Community Detection (DBCD).
4.2.4. Performance Evaluation
The results of clustering the users having FP and CFP using Hierarchical agglomerative, CLARANS and DBCD algorithms by taking into consideration within user similarity (137 users) and without within user similarity (578 Users) is shown in Figures 10–15. Based on the SC it is found that the quality of the clusters formed without using within user similarity is poorer compared to clustering users using within user similarity measure. Within user similarity enables to identify the consistent behavior of the users. Consistent behavior shows the interest of the users on the pages visited. Clustering users who are not having consistent behavior cannot be used for applications like recommendation as it does not reflect the actual interest of the users on the pages visited.
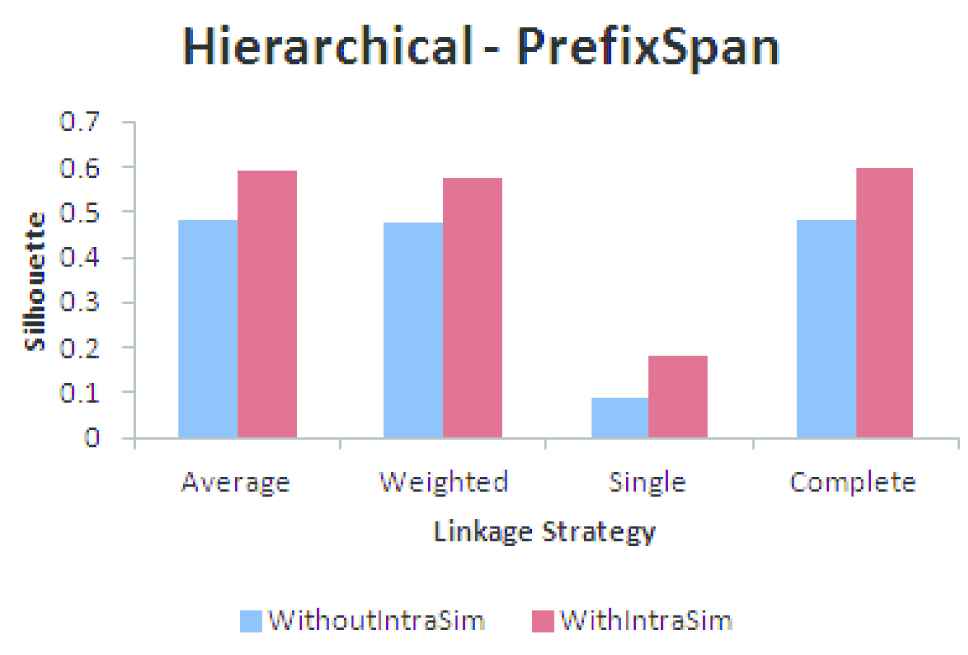
Hierarchical clustering using frequent pagesets (FP).
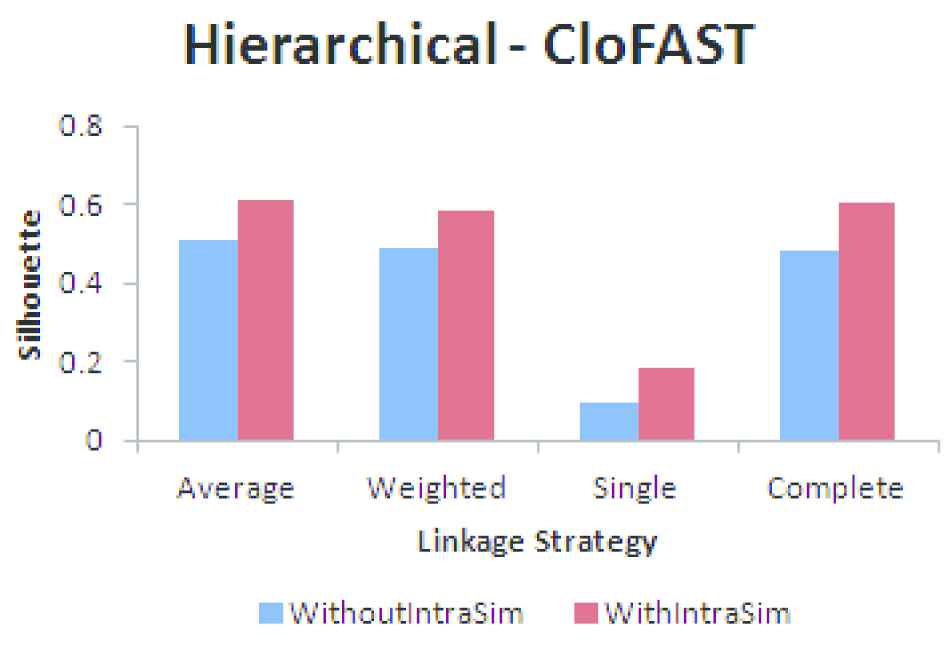
Hierarchical clustering using closed frequent pagesets (CFP).
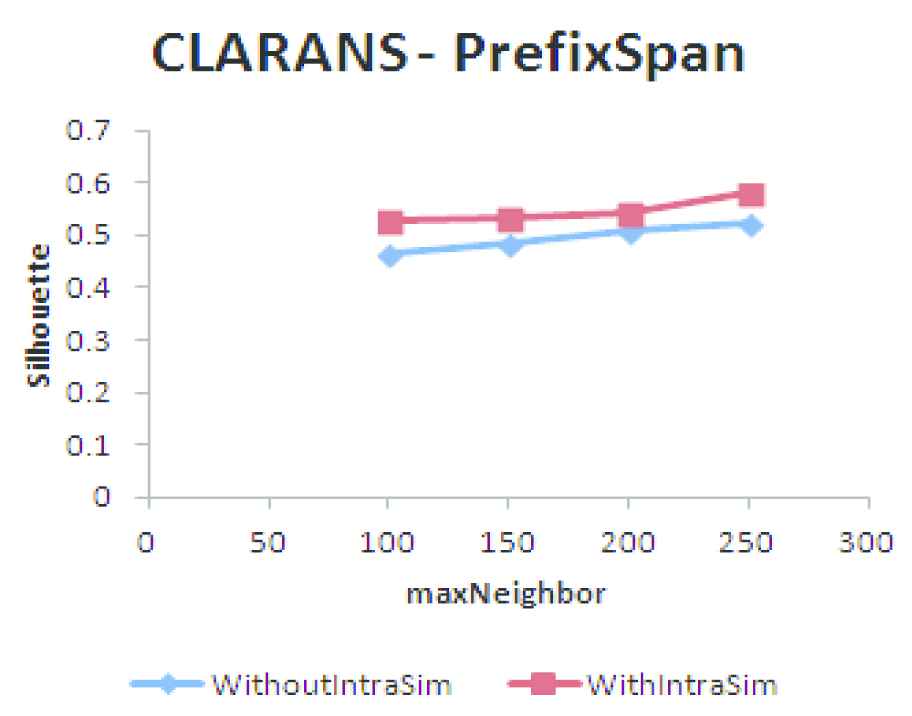
Clustering Large Applications Using RANdomized Search (CLARANS) clustering using frequent pagesets (FP).
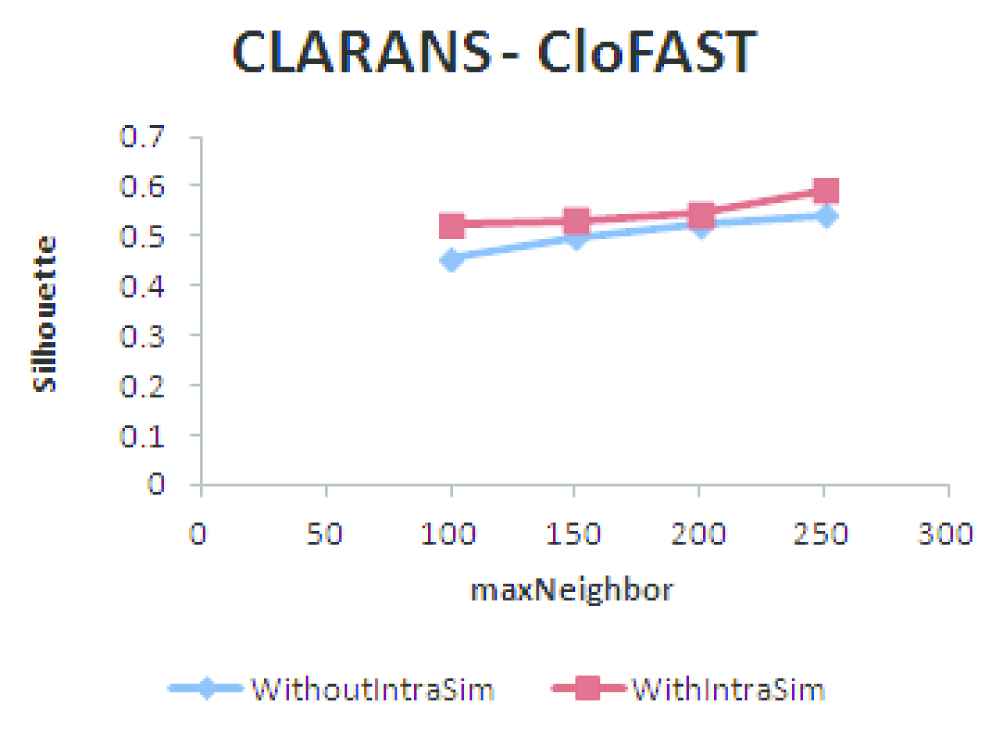
Clustering Large Applications Using RANdomized Search (CLARANS) clustering using closed frequent pagesets (CFP).
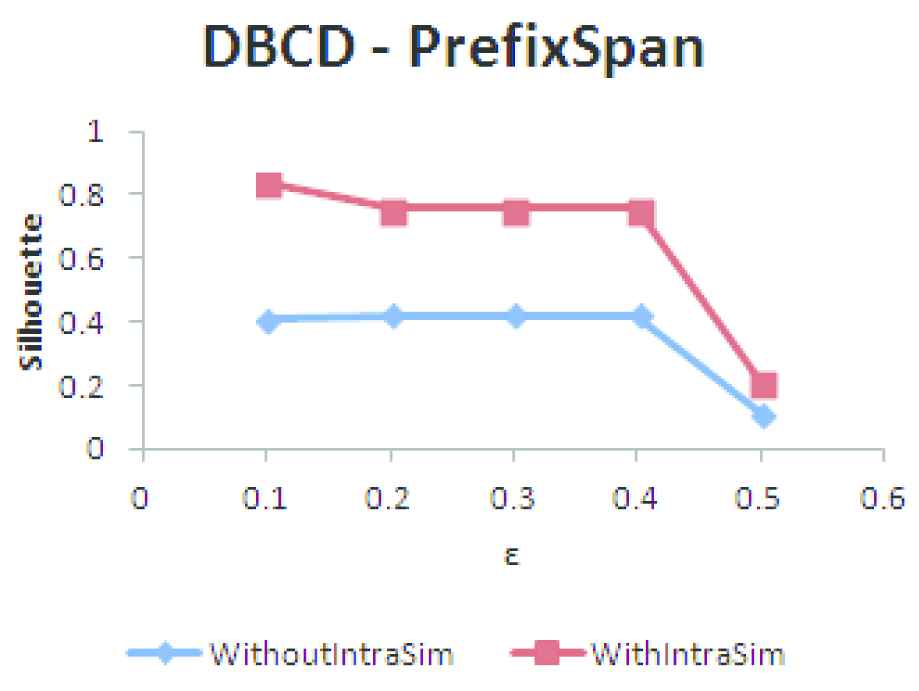
Density-Based Community Detection (DBCD) clustering using frequent pagesets (FP).
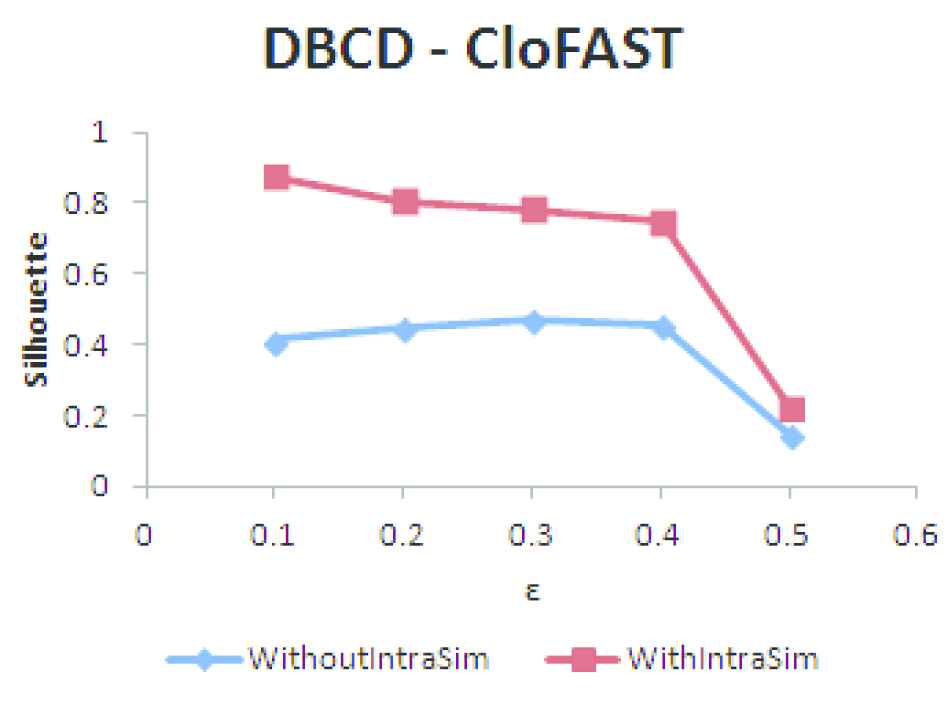
Density-Based Community Detection (DBCD) clustering using closed frequent pagesets (CFP).
An analysis based on clustering the users having FP and CFP, selected using within user similarity is performed and the results are shown in Figures 16–18. From the analysis based on the SC it is found that the quality of the clusters formed using CFP is good compared to FP. There is only a marginal difference in the quality of the clusters formed, but in terms of memory usage and time taken for clustering, CFP is advantageous compared to FP.
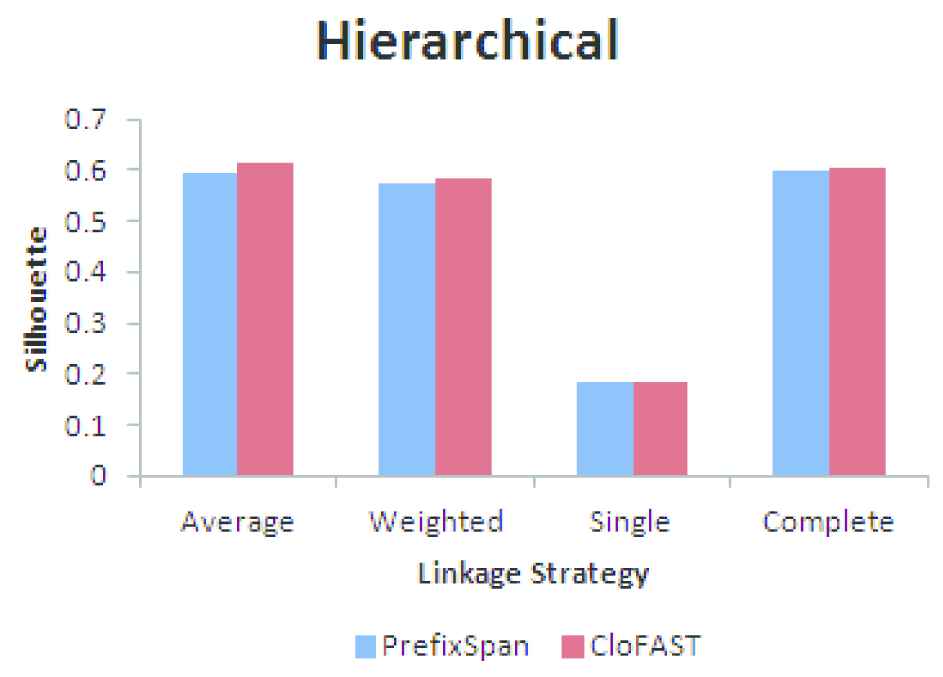
Hierarchical clustering of users.
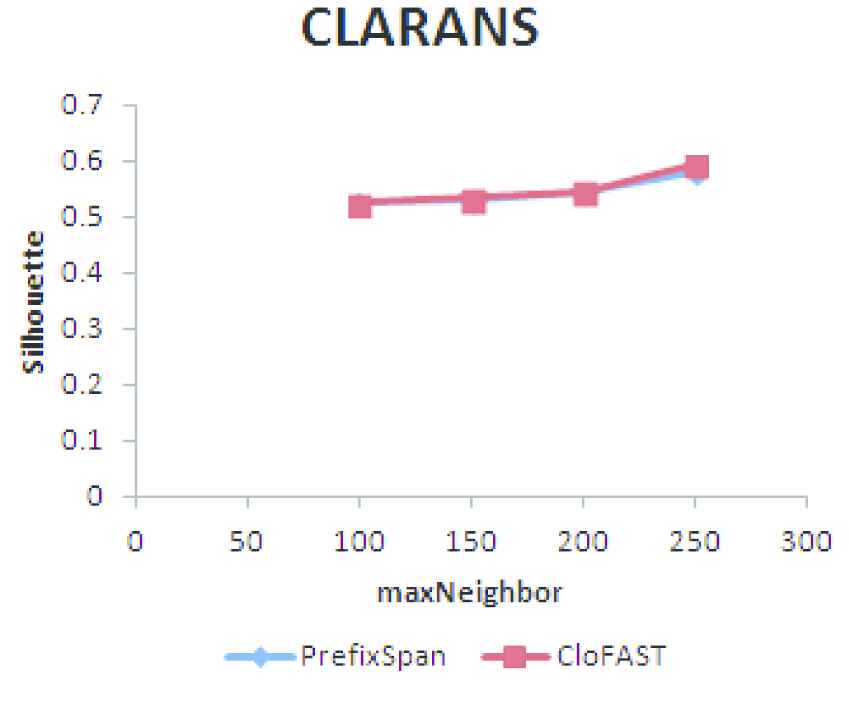
Clustering Large Applications Using RANdomized Search (CLARANS) clustering of users.

Density-Based Community Detection (DBCD) clustering of users.
The proposed work follows three different approaches: (i) Without considering the consistent navigation of the users and using the CFPs, (ii) Considering the consistent behavior of the users and using the FPs, (iii) Considering the consistent behavior of the users and using the CFPs. We observed that all our approaches are providing improved results in terms of metrics such as reduced number of frequent patterns, minimized time taken and memory usage.
5. CONCLUSION AND FUTURE WORK
Our proposed work started with the collection of web pages visited by the users from web log of the web server and the data are preprocessed. The web server log with extended log format is used for our experimental purposes. The user identification is done and the pagesets for the users are separated. By filtering process the FPs are extracted using the support of the pageset. The pagesets which are not having the superset with the same support are selected for the individual user. The pageset similarity is found within users using our proposed within user similarity metric for identifying the users with consistent navigation behavior. The clustering of the consistent users is done using the between user similarity. Each user is represented by a node in a graph and the link between nodes represents the closeness of the users. The pageset associated with the session for the users are internally represented by Hash Map data structure. Most of the existing works have used the FP with prefix span algorithm leading to clustering. However, the CFP approaches have not been found for clustering the web pageset, which is the novelty of the proposed work. The consistent users are subjected to the clustering techniques such as agglomerative, CLARANS and DBCD. The results observed by DBCD method shows promising one using the clustering metric SC. The application of our work will be more suitable for recommendation model. Any new user can be categorized into an appropriate group based on the similarity among the pagesets and the top “n” pages can be recommended to the user. Some of the applications for the proposed work will be to get recommendation in online shopping, e-commerce applications such as customization, web personalization, provision of discount for items based on interest of users and user profiling.
The usefulness of consistent user pruning could be experimentally evaluated by performing the following experiment: Implement the recommendation system and provide the results to the users of the pages. Then the number of clicks on that recommended pages could be measured and the performance can be compared with different recommendation algorithms such as those based on consistent users, FPs and random recommendations.
The proposed methodology can be applied on bigger data provided the system with high configuration and Graphics Processing Unit (GPU) for parallel processing. The work can also be extended to reduce the time taken to cluster the users preferably by exploring the parallel processing concepts. The drawback of our approach is, as the clustering process is iterative and when a new data point comes it has to be clustered once again to reflect the changes which are a time consuming process. As the clustering process is nondeterministic polynomial in nature, it is possible to compare the proposed work with other methods in an appropriate manner.
CONFLICTS OF INTEREST
The authors wish to confirm that there are no known conflicts of interest associated with this publication . The authors also confirm that the manuscript has been read and approved by all named authors and that there are no other persons who satisfied the criteria for authorship but are not listed.
AUTHORS' CONTRIBUTIONS
All authors of this research paper have directly participated in the planning, execution, analysis of this study and approved the final version.
Funding Statement
This research has no significant financial support that could have influenced its outcome.
ACKNOWLEDGMENTS
The authors wish to express their sincere thanks to the Management of Mepco Schlenk Engineering College,Sivakasi(Autonomous), Tamilnadu, India for their support in carrying out this research work.The authors also thank the reviewers for their valuable suggestions in improving the quality of the research article.
REFERENCES
Cite this article
TY - JOUR AU - M. S. Bhuvaneswari AU - K. Muneeswaran PY - 2020 DA - 2020/12/01 TI - User Community Detection From Web Server Log Using Between User Similarity Metric JO - International Journal of Computational Intelligence Systems SP - 266 EP - 281 VL - 14 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.201126.002 DO - 10.2991/ijcis.d.201126.002 ID - Bhuvaneswari2020 ER -