
Bi-GRU Sentiment Classification for Chinese Based on Grammar Rules and BERT
- DOI
- 10.2991/ijcis.d.200423.001How to use a DOI?
- Keywords
- Sentiment classification; Grammar rules; BERT; Bi-GRU
- Abstract
Sentiment classification is a fundamental task in NLP, and its aim to predict the sentiment polarities of the given texts. Recent researches show great interest in modeling Chinese sentiment classification. However, the complexity of Chinese grammar makes the performance of the existing Chinese sentiment classification model not perform well. In order to address the above problem, we propose a sentiment classification method based on grammar rules and bidirectional encoder representation from transformers (BERT). We first preprocess data through BERT model. Then we combine the Chinese grammar rules with Bi-gated recurrent neural network (GRU) in the form of constraints, and simulate the linguistic functions at the sentence by standardizing the output of adjacent positions. Extensive experiments on two public datasets demonstrate the effectiveness of our proposed method, and our findings in the experiment provide new insights for the future development of Chinese sentiment classification.
- Copyright
- © 2020 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Sentiment classification, also known as opinion mining, refers to the mining and analysis of viewpoint, sentiment and polarity of texts. Sentiment analysis is an important branch of natural language understanding, involving theories and methods in statistics, linguistics, psychology, artificial intelligence and other fields.
Sentiment classification is widely used in some network platforms of comment mechanism, such as hotel websites. We can analyze the comments of users through sentiment classification technology, and then display them in the comment area according to ranking rules and display proportion. It can provide reference for consumers to choose and provide basis for enterprises to improve product quality. This scene is also applicable to the merchandise evaluation of Amazon, Alibaba, JD and other e-commerce websites.
In recent years, with the rapid development of Internet technology, people have learned more about current affairs, finance, sports and entertainment through the network, and share their lives on the network. This makes the social platforms with convenience, originality and interaction, such as Weibo, popular with the majority of Internet users. At the same time, these social platforms spread quickly, release instantly, especially in emergencies, and became a social media platform for various information releases. Microblog has a large number of potential information data since the influence of the above reasons. Therefore, sentiment classification for social platforms such as microblog has great significance. In addition, sentiment classification technology plays an important role in the analysis of Internet public opinion, which discourse power and influx of Internet users make the environment of the Internet complicated. Using sentiment classification technology could obtain people's views and opinions on an event, and accurately grasp the development trend of public opinion. It will help the government guide the development of network public opinion in the right direction, and promote the healthy development of the network and social environment. At the same time, sentiment analysis in some areas such as election forecasting and stock forecasting has gradually played an important role.
In this paper, we propose a sentiment classification method based on Chinese grammar rules and bidirectional encoder representation from transformers (BERT) pretraining model. We first preprocess data through BERT model, and then combine Chinese grammar rules with Bi-gated recurrent neural network (GRU) model in the form of constraints. We simulate the linguistic functions of nonaffective words, affective words, negative words and degree words at sentence level by standardizing the output of adjacent positions of sentences. Comparing with other deep learning methods, our proposed model has better performance. The contributions of this research are as follows:
The Chinese grammar rules are integrated into the deep learning model, which solves the problem of the complexity of Chinese grammar rules.
Using the BERT pretraining model, the accuracy of the classification result is further improved.
Our proposed method is applicable to sentiment classification in Hotel field, and provides a reference method for sentiment classification in e-commerce field, commentary field and public opinion field. It has good generalization ability.
The following sections are organized as follows: Section 2 presents related work, Section 3 introduces the model we proposed, Section 4 describes the experiments and evaluations and Section 5 presents the conclusion and introduces directions for future research.
2. RELATED WORK
The process of sentiment classification includes four parts: pretreatment, feature extraction, selection of sentiment classification algorithm and sentiment classification evaluation.
Pretreatment is the primary task of sentiment classification, and the main task is to clean data sources and generate datasets for sentiment classification model. Feature extraction is an important task of sentiment classification, and the main task is to convert datasets into feature vectors. Sentiment classification algorithm is the core of sentiment classification, and the main task is to select and apply the appropriate sentiment classification method to process feature vectors and score feature vectors. Sentiment classification evaluation is an important indicator of the accuracy for sentiment classification, and the main task is to evaluate the advantages and disadvantages of the model by comparing the experimental results with different models, which in the same experimental environment.
The first and second parts of this section will focus on the analysis of pretreatment technology and sentiment classification methods.
2.1. Pretreatment Technology
In the pretreatment technology, pretrained word vectors have greatly improved the field of NLP. Word2vec [1], a language model proposed by Google in 2013, has been widely used in the field of NLP due to its efficiency and usability. After that, Word embedding technology, which preprocesses a large number of unmasked data by word2vec and GloVe [2], has been gradually applied to the first layer of initialization neural network. In most tasks with limited training data, word embedding technology has achieved great results.
There are many methods to generate pretrained word vectors, which are mainly divided into statistical method and language model method. Among these methods, the language model method has been used by more researchers. The traditional word embedding techniques based on language model mainly include Word2Vec and GloVe. Word2Vec has two training methods. One is called CBOW [3], the core idea is to remove a word from a sentence, and use the above and below of this word to predict the word which will be removed. The second is Skip-gram, its opposite to CBOW, the core idea is to input a word and ask the network to predict its context words. Global Vectors for Word Representation (GloVe) is a word representation tool based on global count and overall statistics, it could express a word as a vector composed of real numbers, these vectors capture some semantic characteristics between words, such as similarity and analogy. By computing vectors, such as Euclidean distance or cosine similarity, we can calculate the semantic similarity between two words.
With the development of deep learning research, neural network has been gradually applied to word embedding technology, which Embeddings from Language Models (ELMo) [4] word embedding technology is a representative one. ELMo model is learned from the internal state of the deep bidirectional language model, and these word vectors can easily be added to automatic question and answer, text alignment, text categorization and other models. ELMo model has two characteristics, one is that the input of ELMo model is character rather than word, so they can use the advantage of subunit to calculate meaningful word representation, even though these words may be outside the vocabulary. Secondly, ELMo is a series of excitation functions on some layers for the bidirectional language model. Different layers of a language model encode different types of information. For example, part-of-speech tagging is well predicted by the lower level of Bi-LSTM, while word sense disambiguation is better coded by the higher level. By concatenating all the layers, it is possible to freely combine different word representations so as to achieve better model performance in downstream tasks.
In the research of ELMo model, Che et al. [5] applied ELMo model to HIT-SCIR system which is a CoNLL-2018 shared task system for general dependency analysis. The system embedded deep contextualized word embeddings into both the part of speech tagger and parser, and used different set parsers with initialization training. Experimental results on the development data show the effectiveness of methods. In the final evaluation, HIT-SCIR system was ranked first according to LAS (75.84%) and outperformed the other systems by a large margin. Suzana et al. [6] proposed a model that uses character-level vector representations of words, which based on ELMo. This model can capture complex morpho-syntactic features and use them as indicators for irony or sarcasm across dynamic contexts. The experimental results show that model is tested on 7 different datasets derived from 3 different data sources, providing state-of-the-art performance in 6 of them, and otherwise offering competitive results.
2.2. Sentiment Classification Method
Traditional sentiment classification methods mainly include sentiment classification method based on dictionary and sentiment classification method based on machine learning.
The core of classification method based on sentiment dictionary is the combination of dictionary and rules. This method obtains a large number of sentiment words, it gives weight by weighting algorithm and constructs a sentiment dictionary, then it calculates the sentiment score of sentences by using specific formula with syntactic rules, and finally predict the sentiment polarity. Therefore, the construction of sentiment dictionary is the core of this method. In recent years, many representative achievements have been made in the field of English sentiment dictionary construction and Chinese sentiment dictionary construction. In the construction of English sentiment dictionary, Hu et al. [7] argued that the main factor affecting the sentiment polarity of the text in comments is the polarity of adjectives. He created a sentiment dictionary with adjectives as its core, evaluating the emotional polarity of the review text based on the polarity in the sentiment dictionary, and proposing to judge the polarity of adjectives in comments by the synonyms and antonyms of adjectives in WordNet [8].
In the construction of Chinese sentiment dictionary, Zhang et al. [9] proposed a sentiment analysis method of Chinese Weibo text based on sentiment dictionary. First, the sentiment dictionary was expanded by extracting and constructing degree adverb dictionary, network dictionary, negative dictionary and other related dictionaries, and then the sentiment value of Weibo text was obtained by calculating the weight. Finally, Weibo text is divided into positive, negative and neutral. The experimental results show the effectiveness of this method.
The core of machine learning classification method is feature engineering. This method extracts the lexical, grammatical and semantic features of text, then trains the classifier model with corpus text data. Finally, text that needs to be analyzed is input into the trained model to obtain the sentiment classification results. The most commonly used feature methods include N-Gram feature [10], POS feature [11], TF-IDF feature [12], and most commonly used classification methods include KNN [13], Naive Bayesian [14], SVM [15]. Pang et al. [16] pioneered the application of machine learning in sentiment classification. They classified the sentiment data of movie reviews by Naive Bayes, Maximum Entropy Classification [17] and support vector machine (SVM) models respectively. Zhang et al. [18] proposed a selective ensemble algorithm based on machine learning BPSO and stochastic subspace method, which solved the problem of high dimensionality of eigenvector space and improved the accuracy and generalization ability of sentiment classification.
With the deepening of the research on deep learning, sentiment classification methods begin to gradually transit to deep learning methods such as convolutional neural network (CNN) method and recurrent neural network (RNN) method.
CNN [19] is a kind of feed forward neural network (FNN) [20], which contains convolution computation and has deep structure. It consists of input layer, convolution layer, pooling layer and full connection layer. CNN firstly obtains data through the input layer, then extracts data features through the convolution layer and reduces the dimension of extracted features through the pooling layer to obtains local optimal solution, finally the results are output through the full connection layer. For example, Li et al. [21] proposed a fine-grained sentiment analysis model based on multi-granularity convolution kernel CNN, which incorporates attribute features into Word2Vec model and constructs text feature vectors. Experiments show that fine-grained sentiment analysis method based on multi-granularity convolution kernel CNN can further improve the accuracy of sentiment classification.
RNN [22] is a kind of recursive neural network, which takes sequence data as input and recursively connects all nodes (cyclic units) in the direction of sequence evolution. It consists of input layer, hidden layer and output layer. RNN has memory function, and the input of each sequence is related to its previous output. It can remember the output of the hidden layer at one moment and take the output of the previous moment and the input of the current unit as the input of the current hidden layer. For example, Abdi et al. [23] proposed a new sentiment classification method based on deep learning, RNSA, which used an RNN composed of long- and short-term memory (LSTM) to overcome some shortcomings of traditional methods.
This paper focuses on the influence of pretreatment technology and sentiment classification methods for Chinese sentiment classification. Therefore, we will describe the proposed model in the latter part. The first part of the third section focuses on the analysis of BERT model and Transformer model. The second part focuses on the analysis of GRU model and the third part focuses on the analysis of Bi-GRU Chinese sentiment classification model based on grammar rules and BERT.
3. BI-GRU CHINESE SENTIMENT CLASSIFICATION BASED ON GRAMMAR RULES AND BERT
Grammar rules are very important to the task of Chinese sentiment classification. Chinese grammar rules mainly include nonemotional words, sentiment words, negative words and degree words. In Chinese sentences, the modified words of negative words and degree words are usually at the left side of the modified, but sometimes the modified words are at the right side of negative words and degree words. In order to better address this issue, we first employ Bi-GRU model to let itself decide which direction should start from. Then, in order to improve the accuracy of the model, we apply the BERT Chinese pre-training language model into our model. The word vector could better represent the polysemy of words with BERT model, and enhance the semantic representation of sentences.
3.1. BERT Chinese Pretraining Model
In recent years, researchers have been used pretrained neural networks as language models, and on this basis, fine-tuned downstream tasks have achieved good results. For example, Devlin et al. [24] proposed a BERT pretraining language model. The model achieved good results which compared with the traditional N-gram language model [9], and made better use of the context information of words and got better expression of word vectors.
3.1.1. BERT model
BERT model uses Bidirectional Transformer [25] as encoder, which can have deeper layers and better parallelism, The linear Transformer is not susceptible to mask marker, and simply reduce the weight of mask tags with self-attention. The model innovatively puts forward two tasks: Masked Language Model and Next Sentence Prediction, which capture the representation of word level and sentence level respectively, and conduct joint training. The structure of the model is shown in Figure 1.
Masked language model
The role of the Masked Language Model is to train deep bidirectional language representation vectors, which randomly obscure certain words in the sentence and let the encoder predict the original vocabulary of those words. In the model, 15% of the words were randomly occluded as training samples, 80% of them were replaced by masked token, 10% were replaced by a random word, and 10% remained unchanged.
Next sentence prediction
Next sentence prediction refers to pretraining a binary classification model to learn the relationship between sentences. In the many NLP tasks, such as QA and NLI, the language model needed to understand the relationship between two sentences, but it could not directly produce this understanding. In order to understand the relationship between sentences, this method pretrains a task of next sentence prediction. The specific method is to replace some sentences randomly, and then use the previous sentence to predict Is Next/Not Next.
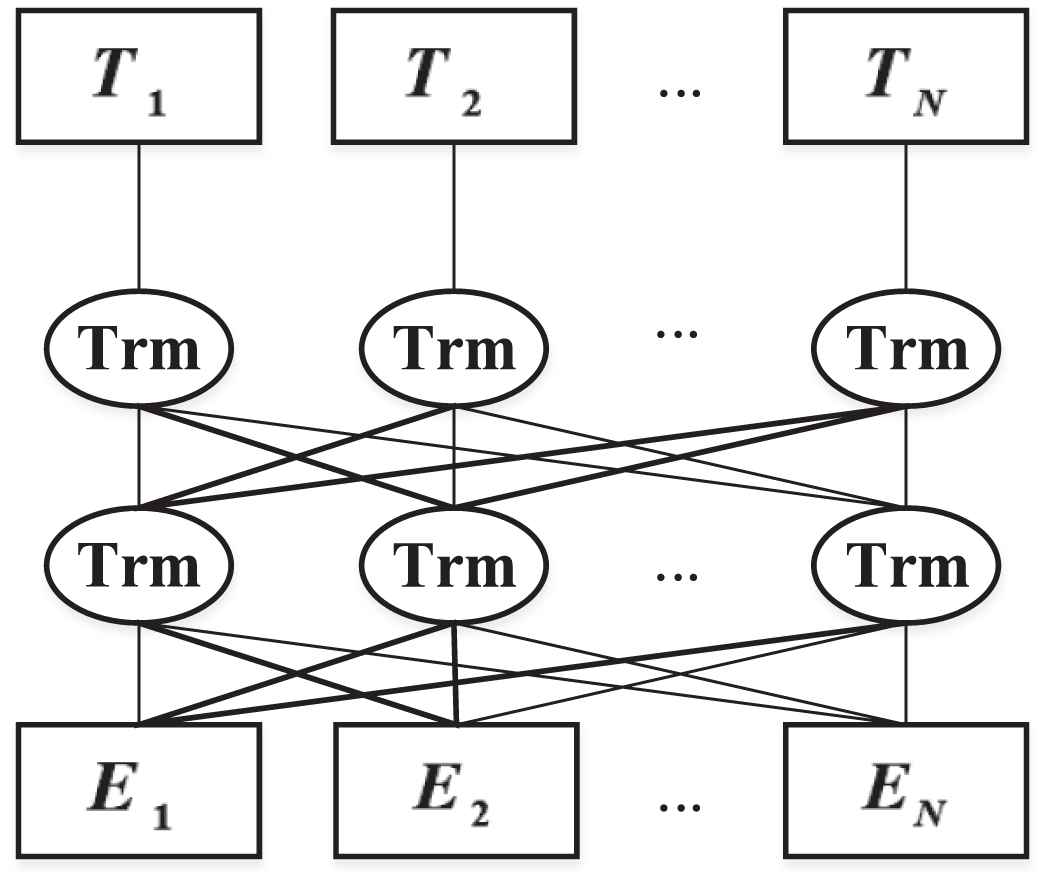
Bidirectional Encoder Representation from Transformers (BERT) model.
3.1.2. Transformer model
The core part of BERT is the bidirectional Transformer model, which uses Encoder–Decoder [26] framework and relies entirely on attention mechanism to construct the global dependence between input and output. Transformer model can be divided into two parts: Encoder and Decoder. Encoder is stacked by multiple Encoders with the same structure, and decoder is stacked by multiple Decoders with the same structure. Each Encoder can be decomposed into two sub-layers: self-attention layer and feed-forward neural network layer. The sentence input from Encoder first passes the self-attention layer, which helps the Encoder to focus on the other words of the input sentence when encoding each word, and then the output from the self-attention layer is transmitted to the FNN layer. The FNN corresponding to each word in each position is exactly the same. In addition to self-attention layer and FNN layer of Encoder, there is an Encoder–Decoder attention layer between the two layers to focus on the relevant parts of the input sentence. The structure of the layer is shown in Figure 2.
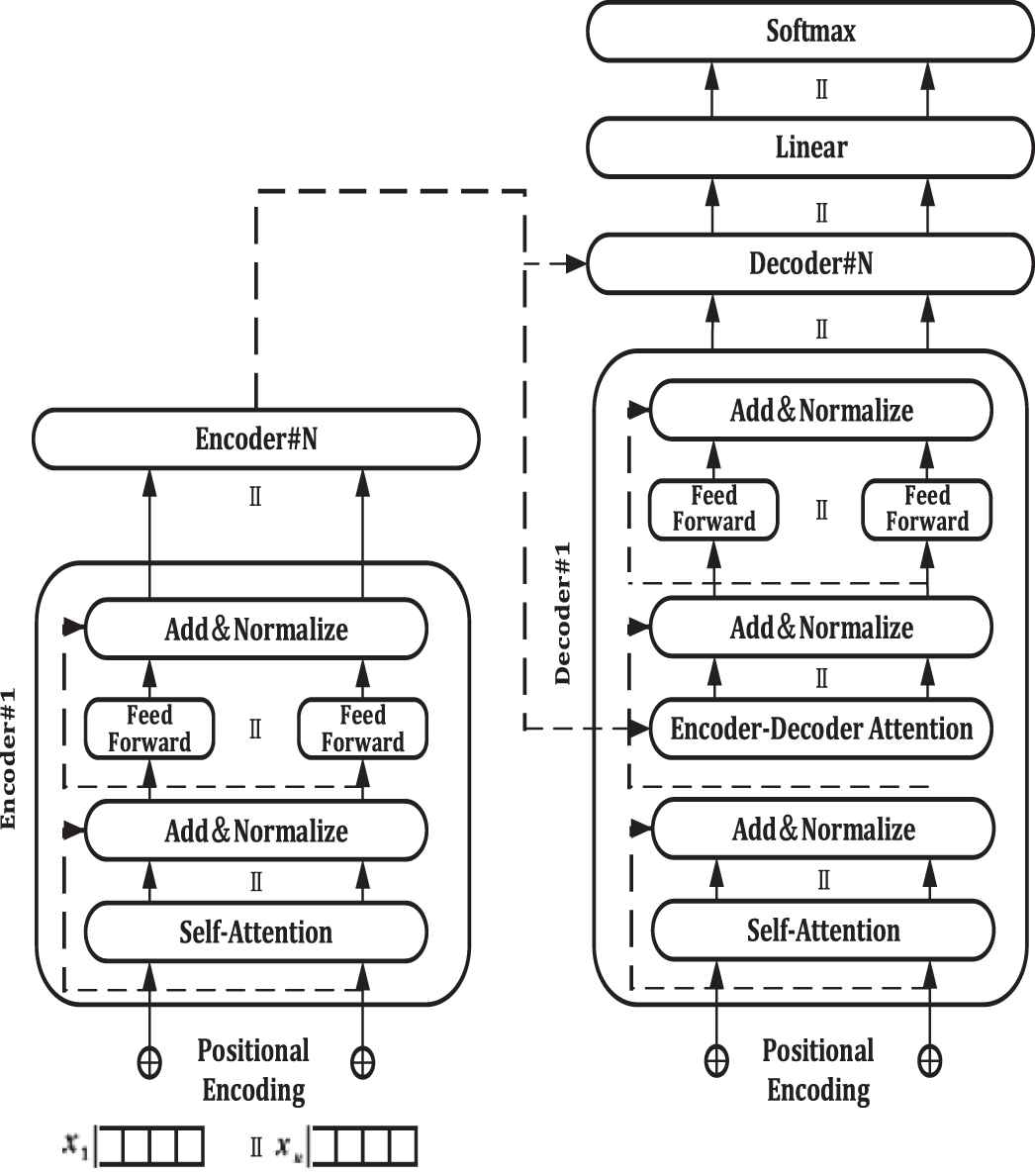
Transformer model.
The core module of Encoder unit is Self-Attention module, the Self-Attention module takes into account all other words in a sentence when encoding a word, and determines how to code the current word. The calculation method is as shown in function (1):
The vectors Q, K and V represent query vectors, Key vectors and Value vectors respectively. Q vector means that we need to pay attention to other words (including ourselves) when coding the current word, so we need to have a query vector. Key vector can be considered as the key of the word for the information to be retrieved, and Value vector is the real content. The core idea of attention module is to calculate the relationship between each word in a sentence and all the words in the sentence, which reflects the relevance and importance of different words in the sentence. Then, we can get a new representation of words with adjusting the weight of each word. This new representation not only implies the word itself, but also the relationship between other words and the word, so it is a more global expression than a simple word vector.
Transformer model further improves the self-attention layer by adding a mechanism called “multi-head” attention, and improves the performance of the attention layer in two aspects. On one hand, it expands the ability of the model to concentrate on different positions, on the other hand, it gives multiple “representation subspaces” of the attention layer, and the calculation methods are as shown in functions (2) and (3):
Since the model contains no recurrence and no convolution, in order to make use of the order of the sequence, the model adds positional encodings to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed. As shown in functions (6) and (7), we use sine and cosine functions of different frequencies to represent position information.
3.2. Gated Recurrent Neural Networks
GRUs [29] is a variant of RNN. It combines short-term memory with long-term memory through delicate gate control, and solves the problem of gradient disappearance to a certain extent. Compared with LSTM [30], GRU can achieve considerable results, and it is easier to train than LSTM, which can greatly improve the training efficiency.
The input and output structure of GRU is the same as that of ordinary RNN. There is a current input
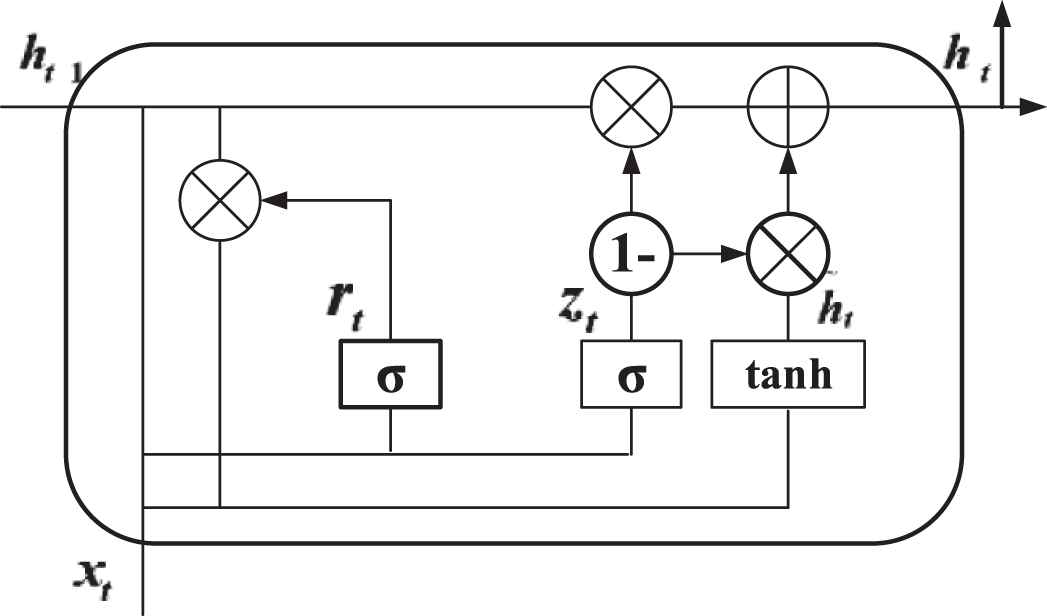
Gated Recurrent Neural Network (GRU) model.
In the first step, GRU obtains two gated states
Among them,
In the second step, the reset gate
The third step is the most critical step in GRU, which named memory updating stage. At this stage, we have two steps of forgetting and remembering at the same time. We use the previously obtained update gated state function and the update function are as follows:
The range of updated gating signal is 0~1, the gated signal is much closer to 1, the more data is remembered. The gated signal is much closer to 0, the more forgotten it is. We use the same gate to make forgetting and selecting memories at the same time.
Traditional GRU model could only process data from forward sequence, and reverse sequence is also very important in text sentiment classification. Bi-GRU model first combines forward GRU with reverse GRU, and then uses two independent hidden layers to process data from forward and reverse simultaneously. This structure make the model learn more context information and improve the classification accuracy.
3.3. Bi-GRU Chinese Sentiment Classification Model Based on Grammar Rules and BERT Pretraining Model
We propose a Bi-GRU Chinese sentiment classification model based on grammar rules and BERT in this paper. We first preprocess data through BERT model, then we construct four kinds of grammar rule regulators in the form of regularization, including nonsentiment word regulators, sentiment word regulators, negative word regulators and degree word regulators. The core idea of the model is simulating the linguistic functions at sentence by standardizing the output of adjacent positions of sentences. Figure 4 shows the construction process of the Bi-GRU model based on grammar rules and BERT.
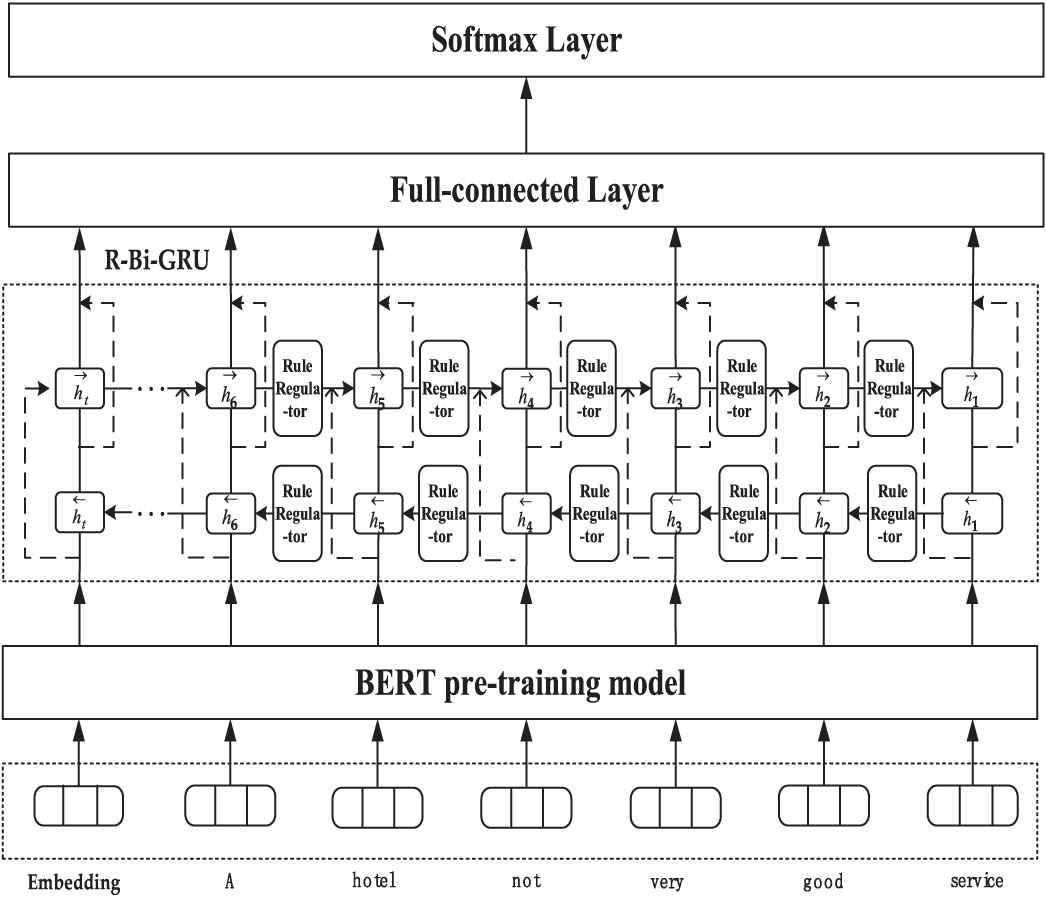
Bi-gated recurrent neural networks (GRU) model combining grammar rules and Bidirectional Encoder Representation from Transformers (BERT).
The construction process of Bi-GRU model based on Chinese grammar rules and BERT is divided into three steps. The first step is to transform the input data into word vectors with BERT, and then input the word vectors into model. The second step is to add Chinese grammar rules into the model in the form of regularization constraints. The third step is to judge the part of speech for the input word vectors with the grammar rule regulator. Then, the linguistic functions at sentence are simulated by standardizing the output of adjacent positions.
This paper gives an example of Bi-GRU model based on Chinese grammar rules and BERT. As shown in Figure 4, in the sentence “A hotel with not very good service,” the predicted sentiment distribution of “A hotel with not very good service” and “hotel with not very good service” should be close to each other, and the predicted sentiment distribution of “good service” and “not good service” should be completely different. Therefore, four kinds of grammar rule regulators are proposed in this paper.
Nonsentiment word regulator: If adjacent words are nonsentiment words, the sentiment distribution of adjacent positions should be similar. This rule is applicable in most cases.
Sentiment word regulator: If the current word is a sentiment word, the sentiment distribution of the current position should be significantly different from the next or previous position. We use sentiment transfer to deal with this phenomenon.
Negative word regulator: If the current word is a negative word, the sentiment polarity of the current position will be reversed than adjacent words, such as polarity from positive to negative and negative to positive, but sometimes it depends on the words they modify. The negative word regulator uses a specific transformation matrix to simulate the language performance.
Degree word regulator: If the current word is a degree word, the sentiment polarity of the current position will be enhanced or weakened than adjacent words. For fine-grained sentiment classification, it is very important to model with degree words. The degree word regulator uses a specific transformation matrix to simulate the language performance.
Nonsentiment word regulator
The rule of non-sentiment word regulator: If the words of adjacent position are nonsentiment words, the sentiment distribution of the adjacent positions should be similar. The nonsentiment word regulator is combined into the model in the form of constraints. It has the following definitions:
whereThe range of JS divergence is [0, 1], and the predicted distribution is the same as 0, but the opposite is 1.
JS divergence possesses the character of symmetry.
When the words of adjacent position are nonsentiment words, the sentiment distribution of the two words will be closer, and according to functions (13) and (14), the value of nonsentiment word regulator is 0. If the sentiment distribution of two adjacent words is much different, the value of nonsentiment word regulator will become larger.
Sentiment word regulator
The rule of sentiment word regulator: If the word of the current position is a sentiment word, the sentiment distribution of the current position should be significantly different from that of the adjacent position.
As shown in Figure 4, in the sentence “A hotel with not very good service,” when position t = 2 (reverse), the input word is “good” and the predicted sentiment distribution is more positive than the first word “service.” In order to simulate this phenomenon, we deal with the sentiment transfer for each category of words in the sentiment dictionary. Each category of sentiment words has its corresponding sentiment transfer distribution
whereIf the current position is a sentiment word, the sentiment distribution of the adjacent position plusses sentiment transfer distribution will be close to the current location. And according to functions (17) and (18), the value of the sentiment word regulator is 0. If the sentiment distribution is far away, the value of the sentiment word regulator increases.
Negative word regulator
The influence of a negative word on a text depends on the sentiment polarity of the word it modifies. In general, negative words will reverse the sentiment polarity of words which they modify. For example, in the sentence “not good,” the positive polarity of the modifier “good” is transformed into negative polarity, while in the sentence “not bad,” the negative polarity of the modifier “bad” is transformed into neutral polarity.
The rule of negative word regulator: If the word of current position is a negative word, the sentiment distribution of the adjacent position with the treatment of negative matrix
whereDegree words regulator
Degree words change the sentiment intensity of text. It could change weak positive to strong positive and weak negative to strong negative, which is very important for fine-grained sentiment classification.
The rule of degree word regulator: If the word of current position is degree word, the sentiment distribution of the adjacent position with the treatment of degree matrix
wherewhere
4. EXPERIMENT AND EVALUATION
In this section, we first describe the experimental dataset. Then, we describe the experimental details. Afterward, we introduce the several frontier models as baseline models. Finally, we analyze the experimental results to prove the performance of our proposed model.
4.1. Dataset
We use two datasets to evaluate the performance of our model, which were collected by Tsinghua University Chinese Hotel Comment Corpus and Professor Tan Songbo. The Sentiment Dictionary uses the Chinese Sentiment Vocabulary Ontology Library of DUTIR. There are 22012 sentiment vocabularies, which are divided into 7 categories and 21 subcategories. Each category of vocabulary has the sentiment polarity score, including 11229 positive sentiment words and 10783 negative sentiment words. Negative words and degree words are collected by HowNet Chinese Negative Words Dictionary and Degree Words Dictionary. There are 59 negative words and 219 degree words. The distribution is shown in Table 1.
| Dictionary Name | Dictionary Value |
|---|---|
| Positive sentiment words | 11229 |
| Negative sentiment words | 10783 |
| Negative words | 59 |
| Degree words | 219 |
Sentiment dictionary.
4.2. Experimental Details
All the experiments in this paper were performed in the experimental environment shown in Table 2.
| Experimental Environment | Environmental Configuration |
|---|---|
| Operating system | Ubuntu 16.04 |
| CPU | Intel E5-2640v4 2.40 GHz |
| Memory | 4*16G |
| Programing language | Python 3.6 |
| Tensorflow | 1.13.1 |
| Word embedding tool | BERT |
Experimental configuration and environment.
The experiment uses BERT model to train word vectors and the BERT pretraining model provided by Google is divided into two kinds: BERT-Base and BERT-Large. The two models have the same network structure which only some parameters are different. We used BERT-Base in this experiment. BERT-Base consists of 12 layers, the hidden layer is 768 dimensions, using 12 head modes and a total of 110M parameters. The dimension of Bi-GRU hidden layer is 300, model learning rate is 0.01, Batch Size is 64 and L2 Regular coefficient is 0.001. The function of Margin boundary parameter is to make the trained classifier have a better grasp of classification. By referring to the research of Mats et al. [32], we set the Margin parameter as
| Parameter Name | Parameter Value |
|---|---|
| BERT layer | 12 |
| BERT hidden layer | 768 |
| BERT head mode | 12 |
| BERT parameter | 110 |
| Bi-GRU hidden layer | 300 |
| learning rate | 0.01 |
| Batch_Size | 64 |
| L2 Regular coefficient | 0.001 |
BERT, Bidirectional Encoder Representation from Transformers; GRU, Bidirectional Encoder Representation from Transformers.
Model parameter setting.
4.3. Experimental Results
In the experiment, we use standard CNN model, RNN model, LSTM model, Bi-LSTM model and Bi-GRU model as baseline model and compare them in the same datasets. We extract 5000 words from each corpus, 80% as training dataset, 10% as test dataset and 10% as validation dataset for cross-validation. In the initial experiment, there was a phenomenon of overfitting. In order to deal with the phenomenon of overfitting, we added the dropout [34] parameter to the model. We introduced the dropout strategy in the training process of the fully connected layer for the model. The dropout mechanism is to randomly discard some training parameters in each iteration. The workflow of dropout is to randomly select and temporarily hide some units in the nerve layer of one cycle, then train and optimize the neural network. In the next cycle, some other neurons will be hidden until the end of training. During the experiment, we compared the Accuracy of dropout (keep_prob parameter) between 0.1 and 1, and finally chose keep_prob of 0.5 as the optimal value. The experimental results are shown in Figure 5.
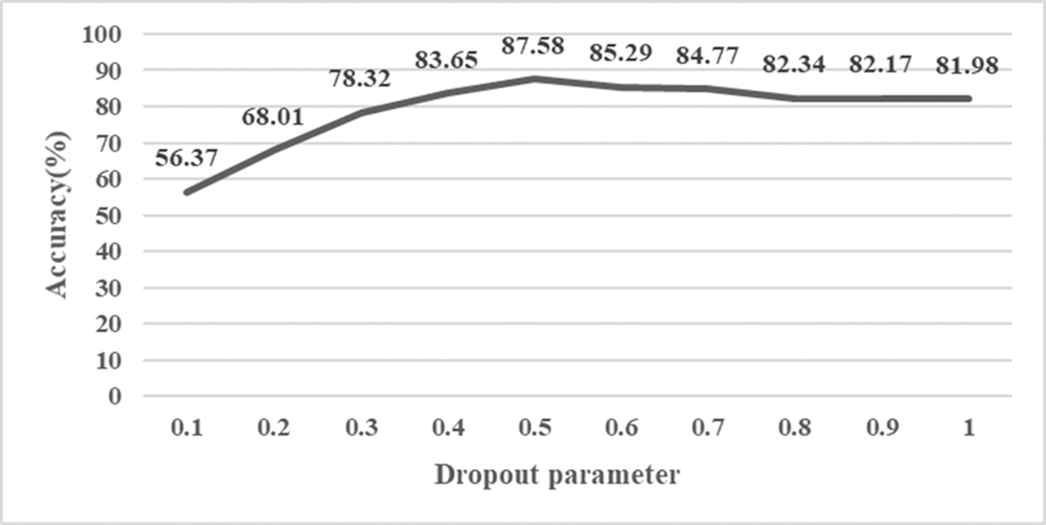
Effect of dropout on model performance.
We found that the number of iterations is also very important to the training results of the model. The model has better fitting ability with increasing the number of iterations. According to the experimental results shown in Figure 5, we set dropout to 0.5 and on this basis, we compare the number of iterations with the change of accuracy, and finally determine that the best accuracy is when the number of iterations is 700. The experimental results are shown in Figure 6.
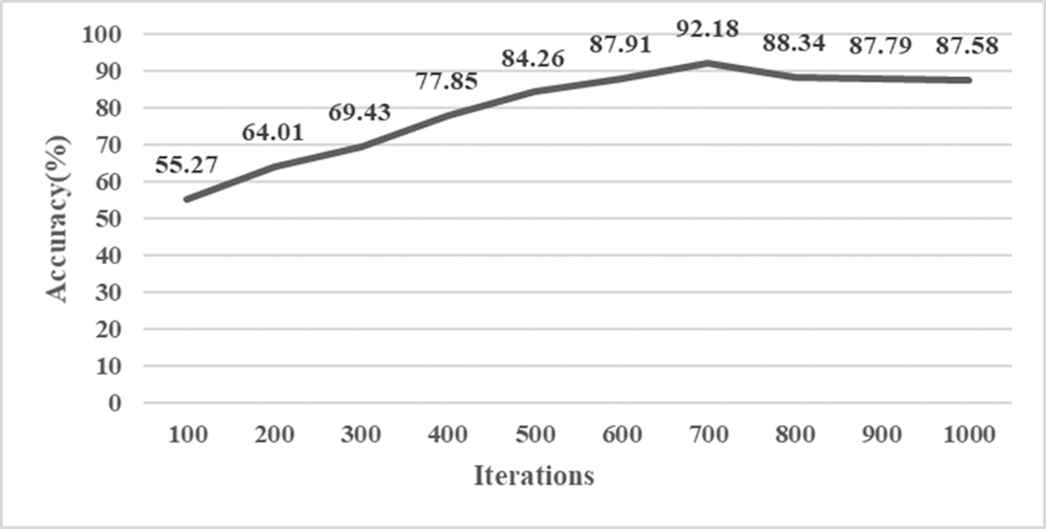
Effect of iterations on model performance.
We use standard CNN, RNN, LSTM, Bi-LSTM and Bi-GRU as benchmark models, and compare them with the Bi-GRU model (RB-Bi-GRU) which combines grammar rules and BERT pretraining. Our experimental datasets use the same datasets. The experimental results are as follows:
As shown in Table 4, Bi-LSTM model based on grammar rules and BERT is superior to the traditional CNN, RNN, LSTM and Bi-LSTM models in accuracy, which reflecting the importance of grammatical rules for Chinese sentiment classification. To further verify the performance of the proposed model, we compared it with the frontier baseline models. Four frontier Chinese sentiment classification models with good results were selected as the baseline model. The baseline model is as follows:
Bi-LSTM model [35]: This method integrates the contribution of sentiment information into the traditional TF-IDF algorithm and generates weighted word vectors. Weighted word vectors are input into Bi-LSTM to capture contextual information effectively and better represent comment vectors.
Stacked Bi-LSTM model [36]: This method combines Word2vec model with Stacked Bi-LSTM model. Firstly, the word 2vec model is used to capture the semantic features of words and convert them into high-dimensional word vectors; then the Stacked Bi-LSTM model is used to extract the features of continuous word vectors; finally, the binary softmax classifier is used to predict the sentiment direction through the semantic and context features.
CNN-Bi-LSTM model [37]: This method uses CNN based on Bi-LSTM, which can extract sequence features from global information and consider the relationship between these features. Bi-LSTM not only solves the problem of long-term dependence, but also considers the context of text.
BI-LSTM-CRF model [38]: In this method, aggregation A21 is expressed as a sequence marker by fine-grained aspect-level affective analysis problem. Aspect words and sentiment words are extracted by aspect-level sentiment word pairing and aspect-level sentiment classification. Firstly, bidirectional LSTM-CRF model is used to extract aspect terms and sentiment words. Then, some grammar rules based on dependency analysis are used to match aspect and sentiment words. Finally, the dominant classifier is used to determine the sentiment polarity.
| Model | Accuracy (%) |
|---|---|
| RNN | 72.63 |
| CNN | 81.65 |
| LSTM | 82.17 |
| Bi-LSTM | 84.51 |
| Bi-GRU | 85.46 |
| RB-Bi-GRU | 92.18 |
RNN, Recurrent Neural Network; CNN, Recurrent Neural Network; LSTM, long-term and short-term memory; BERT, Bidirectional Encoder Representation from Transformers; GRU, Bidirectional Encoder Representation from Transformers.
Comparison with standard classification model.
We use the same datasets to conduct comparative experiments. The experimental results are shown in Table 5.
| Model | Accuracy (%) |
|---|---|
| Bi-LSTM model | 88.32 |
| Stacked Bi-LSTM model | 89.54 |
| CNN-Bi-LSTM model | 90.17 |
| BI-LSTM-CRF model | 87.51 |
| RB-Bi-GRU | 92.18 |
LSTM, long-term and short-term memory; GRU, Bidirectional Encoder Representation from Transformers.
Comparison with frontier classification model.
As shown in Table 5, the Bi-LSTM model based on grammar rules and BERT is superior to the frontier Chinese sentiment classification model in accuracy. The main reason is that due to the ambiguity of Chinese vocabulary and the complexity of grammar rules, existing neural network models do not take into account these factors. The Bi-GRU model based on Chinese grammar rules and BERT takes grammar rules into account and simulates the function of grammar rules by judging the sentiment distribution of adjacent positions.
In order to further verify the effect of grammar rules on accuracy, we add five comparative experimental models based on Bi-GRU, which only contains nonsentiment word regulator, sentiment word regulator, negative word regulator, degree word regulator, or BERT model. And compared with the Bi-GRU model based on grammar rules and BERT (RB-Bi-GRU). The experimental results are as follows:
As shown in Table 6, among the four grammar rule regulators, the sentiment word regulator has the greatest impact on the accuracy of model classification. Because the existence of negative words and degree words is far less than that of nonsentiment words and sentiment words in datasets, the effect of the regulator of negative words and degree words is relatively weak. Similarly, BERT pretraining model also has a great improvement in classification accuracy, so experiments show that grammar rules and BERT pretraining model have a good improvement in Chinese sentiment classification of accuracy.
| Model | Accuracy (%) |
|---|---|
| R(ur)-Bi-GRU | 86.12 |
| R(sr)-Bi-GRU | 90.55 |
| R(nr)-Bi-GRU | 87.06 |
| R(dr)-Bi-GRU | 87.49 |
| BERT-Bi-GRU | 89.64 |
| RB-Bi-GRU | 92.18 |
BERT, Bidirectional Encoder Representation from Transformers; GRU, Bidirectional Encoder Representation from Transformers.
The comparison of experiments involving only grammar rules and BERT pre-training model.
5. CONCLUSIONS
Aiming at the ambiguity of Chinese vocabulary and the complexity of grammar rules, we propose a Bi-GRU sentiment classification method for Chinese based on grammar rules and BERT. It first employs BERT to process word vectors, then integrates Chinese grammar rules such as nonsentiment words, sentiment words, negative words and degree words into Bi-GRU model in the form of regularization to solve the sentiment transfer of words in Chinese sentence level, which further improves the accuracy of sentiment classification.
Since we only consider finding the optimal solution of parameters through a single experiment, and does not consider finding the optimal solution among the correlated parameters. Finding the optimal solution among the correlated parameters is the part that we need to improve and perfect in the next step. In future research, we can try to experiment in more fields to improve the generalization ability of the model, and integrate Chinese grammar rules into other sentiment classification models to further improve the accuracy of model classification.
CONFLICT OF INTEREST
The authors declare no conflict of interest.
AUTHORS' CONTRIBUTIONS
Writing—original draft, Q.L.; Writing—review & editing, Z.Z.; Data curation, F.X.; Methodology, Q.L.; Software, Q.G.; Funding acquisition, Z.Z.; Project administration, Q.L.; Investigation, D.Z.; Validation, W.W.
ACKNOWLEDGMENTS
This work was supported National Social Science Foundation (19BYY076); Science Foundation of Ministry of Education of China (14YJC860042) and Shandong Provincial Social Science Planning Project (19BJCJ51, 18CXWJ01, 18BJYJ04, 17CHLJ07).
REFERENCES
Cite this article
TY - JOUR AU - Qiang Lu AU - Zhenfang Zhu AU - Fuyong Xu AU - Dianyuan Zhang AU - Wenqing Wu AU - Qiangqiang Guo PY - 2020 DA - 2020/05/22 TI - Bi-GRU Sentiment Classification for Chinese Based on Grammar Rules and BERT JO - International Journal of Computational Intelligence Systems SP - 538 EP - 548 VL - 13 IS - 1 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.200423.001 DO - 10.2991/ijcis.d.200423.001 ID - Lu2020 ER -