
Character-Level Quantum Mechanical Approach for a Neural Language Model
- DOI
- 10.2991/ijcis.d.191114.001How to use a DOI?
- Keywords
- Character-level; Quantum theory; Network-in-network; Language model
- Abstract
This article proposes a character-level neural language model (NLM) that is based on quantum theory. The input of the model is the character-level coding represented by the quantum semantic space model. Our model integrates a convolutional neural network (CNN) that is based on network-in-network (NIN). We assessed the effectiveness of our model through extensive experiments based on the English-language Penn Treebank dataset. The experiments results confirm that the quantum semantic inputs work well for the language models. For example, the PPL of our model is 10%–30% less than the states of the arts, while it keeps the relatively smaller number of parameters (i.e., 6 m).
- Copyright
- © 2019 The Authors. Published by Atlantis Press SARL.
- Open Access
- This is an open access article distributed under the CC BY-NC 4.0 license (http://creativecommons.org/licenses/by-nc/4.0/).
1. INTRODUCTION
Languages are used to convey meaning, so the ultimate goal of natural language processing (NLP) research is to represent the meaning of an utterance in computers. In recent years, a series of semantic models has been proposed for NLP. These semantic models can mimic human thinking to a certain extent and can solve problems in the real world. Although each model has its own detailed characteristics, they all use text collections as input for the model and a vector space to represent words or concepts. With the development of deep learning technology, distributed word representation has become one of the main methods of text representation. Relatively speaking, this form of representation is more condensed and has fewer dimensions, but it is sufficient to represent the elements in space. For example, Bengio et al. [1] proposed a language model that is constructed using a three-layer neural network. Based on this approach, Mnih and Hinton [2] proposed a hierarchical idea to eliminate the most resource-consuming matrix multiplication from the last hidden layer to the output layer, thereby accelerating the process while retaining the performance. Distributed word representation has achieved the most remarkable results to date. In more recent research, it is believed that information about word morphology and shape is normally ignored when learning word representations. Based on this idea, Santos et al. [3] proposed a character-level representation of words and combined it with a distributed word representation to implement the application of voice tags. Later, LeCun et al. [4] proposed a method for learning the distributed character representation directly through character learning without prior distributed word representation training. Their study found that the distributed character representation performed very well in large-scale corpus sets. Kim et al. [5] used the distributed character representation to implement language modeling, and this method could be used in different languages.
Several of the abovementioned distributed character representations are obtained through convolutional neural network (CNN) training. CNNs have achieved state-of-the-art results in computer vision and have been shown to be effective for various NLP tasks. CNNs have the properties of location invariance and compositionality, which is why CNNs play an important role in computer vision. However, the application of CNNs in NLP is different from their use in computer vision. Neighboring pixels in an image are often related (i.e., belong to the same part of an object), but the words might not be the same. In many languages, phrases are segregated by many other words. Additionally, one must pay attention to a word's position in a sentence, so location invariance is not applicable in NLP problems. Similarly, the composability can be unclear. It is obvious that the words are combined together in certain ways, such as using adjectives to modify nouns or using adverbs to modify verbs or adjectives. However, it is not as obvious as computer vision when interpreting the meaning of more advanced features. In the current distributed character representation research, the characters in the CNN's input are all encoded using one-hot or similar methods. This type of coding method is simple but does not provide an intuitive feeling as the image pixels do. However, when considering natural language, does the human brain always read in order? In much of the current research on speed reading [6], the methods that are used to understand and remember words are based on the way in which people recognize images. Therefore, if language coding can reflect more of this rule, then the performance of language models might be greatly improved. As we all know, language is the result of neuron activities in the human brain. If classical physics can be considered an extreme case of quantum mechanics, then the brain can be considered a measuring device with a quantum computing system. Then, language interpretation can be considered a quantum measurement process [7].
The NLP based on quantum theory is a new research idea that differs from distributional semantics representation. The quantum language model encodes the probability uncertainties of both single and compound terms in a density matrix, without extending the vocabulary [8]. In the quantum language model, each text term is represented by a density matrix that is a one-hot vector. The density matrix only encodes the local occurrence without taking into account the global semantic information. Furthermore, a density matrix is calculated via an iterative process, instead of an analytical procedure. Thus it is difficult to integrate such matrix into an end-to-end deep neural network [9].
In order to address the above problem, we use character-level embedding to represent text to encode richer semantic information than one-hot vector. We use an eigenstate of quantum theory to represent the characters, the superposition of eigenstates to represent words, unitary operator to represent phrases. Therefore, a long text is represented by a mixed state and hence it can be integrated into a neural network. The language models can be used in NLP research fields such as machine translation, question and answer, and text classification.
In the following, we use the mathematical framework of quantum theory to construct a semantic information model. Specifically, the model describes how quantum states can be used to represent characters, words, and even sentences. The resulting language representation then serves as the CNN input, thus achieving the goal of text classification. The present study makes contributions in four main aspects as follows:
We proposed a character-level quantum neural language model (NLM) that does not require word order or syntax information. It implements language representations with rich semantic and orthographic features through character-level coding. Therefore, this method does not need to pre-process the text data for morphological annotation, nor to use pre-trained embedding representation in the input layer.
A CNN is applied to distributed or discrete embedding without knowing the syntactic or semantic structure of languages.
In order to reduce the overfitting risk and computational load, we introduce a network-in-network (NIN) model into the network to reduce the number of parameters and computation cost.
The experiments show that our proposed model achieves the performance of state-of-the-art on the English-language Penn Treebank (PTB) dataset with fewer parameters.
The rest of this paper is organized as follows: Sections 2 and 3 discusses related work and preliminary. Next, we introduce the related mathematical background of quantum theory in Section 4 and propose the quantum semantic space model. In Section 4, the character-level CNN language model is given and quantum semantic feature learning is conducted. The experimental results and analysis are given in Section 5. Finally, the study is concluded in Section 6.
2. RELATED STUDIES
2.1. Neural Language Model
NLM research has made remarkable progress. Various structure models, including feed-forward [1], RNN [10], log-bilinear [11], sum-product Net [12] and CNN [13–15], have achieved state-of-the-art results.
Two main methods are used in the study of natural language semantic representation: distributed word representation models based on n-gram language models [16] and character-level NLMs. N-gram models are language-independent and have advantages such as the ability to handle text in different languages at the same time, not requiring linguistic processing for the text, being tolerant of spelling mistakes, no lexicon or rules required, and fewer text feature dimensions [17]. Bilmes et al. [18] proposed a count-based n-gram language model to represent words as a set of shared factor embeddings. Based on this approach, Alexandrescu et al. [19] proposed the factored neural language model (FNLM) to solve the rare word problem. FNLM can make better use of morphemes, word shape information, and other tags to represent words. FNLM quickly became a popular research topic. Luong [20], Botha [21], and Qui et al. [22], proposed different types of FNLMs for learning morpheme embedding representation. These models can make better use of morphemic information by representing words as a function of their own morpheme embeddings. Word embeddings have become the most widely used mainstream method for natural language semantic representation. Character-level NLM is another research idea that has recently become popular. The inputs and outputs of these models are characters [23,24]. Character-level models do not consider any morphological tagging or manual feature engineering. The latest series of studies has shown that these models performance is usually superior to that of word-level models [4,5].
CNNs [25] are useful in extracting information from raw signals. They have been successfully used in computer vision research area. In recent years, CNNs have been shown to be effective for various NLP tasks. However, the architectures used for NLP applications are different because they typically involve temporal rather than spatial convolutions [4,5]. They consider the character-level text as the raw signal, an applying temporal (one-dimensional) convolutional networks to it. In the temporal convolutional module, the main components are 1-D convolution layers [4]. Similar to zhang [4], Prusa et al. [26] also proposed a character embedding to create a more compact data representation, reducing training time and memory requirements. The main shortcoming of character-level Language Models which use of a vanilla convolutional network like zhang [4] and Prusa [26] is the receptive field of each convolutional layer is often small that the network must very deep in order to capture long-term dependencies in an in-put text. Thus, Kim et al. [5] and Xiao et al. [27] proposed hybrid methods of convolutional and recurrent networks.
2.2. Quantum-Theoretic Approach to NLP
The NLP based on quantum theory is a new research idea that differs from natural language distributional semantics representation. The above studies focused on word- or character-level distributional semantic representation. It is very difficult to extend these methods to the sentence level. Quantum states can conveniently represent words and sentences. Aerts et al. [28] and Bruza et al. [29] first attempted to use quantum theory as a mathematical basis for semantic space models. Aerts proved that latent semantic analysis (LSA) model [30] is essentially a series of Hilbert space formalisms. Bruza confirmed that the Hyperspace Analogue to Language (HAL) model [31] also conforms to Hilbert space formalisms and designs lexical operators through corpus co-occurrence counts. Grefenstette et al. [32] proposed a semantic combination model based on a quantum theoretical context; however, this method does not utilize the unique aspects of quantum theory. Blacoe et al. [33] used quantum theory as a standard framework to implement a semantically aware semantic space model that captures lexical meaning. This method establishes density matrices by grammatical dependencies, considers word ordering and utilizes important concepts in quantum theory, such as superposition and entanglement (more details see Section 4).
3. PRELIMINARY
3.1. Quantum Semantic Space Model
In quantum mechanics, the state of the system can be represented by a complex vector, described by the ket-bra symbol, recorded as
There is a class of operators which defined as Equation (2) that preserve the norm of kets.
A quantum mechanical system is linear. That is, if
3.2. Convolutional Neural Network
3.2.1. The basic components
The basic components of CNN consist of three types of layers, namely convolutional, pooling, and fully-connected layers. The convolutional layer which is composed of several convolution kernels aims to learn feature representations of the inputs. The convolution kernel of convolutional layer which is used to compute different feature maps is shared by all spatial locations of the input to generate each feature map. The complete feature maps are obtained by using several different kernels. Mathematically, the feature value at location
Typical activation functions are sigmoid, tanh and ReLU [34].
The pooling layer which is usually placed between two convolutional layers aims to achieve shift-invariance by reducing the resolution of the feature maps. Let
After several convolutional and pooling layers, there may be one or more fully-connected layers which aim to perform high-level reasoning. Let
Training CNN is a problem of global optimization. By minimizing the loss function, we can find the best fitting set of parameters. Stochastic gradient descent is a common solution for optimizing CNN network [34].
3.2.2. CNN for NLP
The architectures used for NLP applications are different from the basic CNN because they typically involve temporal rather than spatial convolutions [4,5]. Suppose there is a discrete input function
3.2.3. Network in network
NIN is a general network structure proposed by Lin et al. [35]. It replaces the linear filter of the convolutional layer by a micro network called mlpconv layer which makes it capable of approximating more abstract representations of the latent concepts. The overall structure of NIN is the stacking of mlpconv layer. The computation performed by mlpconv layer is formulated as Equation (9):
4. OUR MODEL
4.1. Semantic Space Model Inspired by Quantum Theory
In quantum theory, the state of a physical system can be described as superposed eigenstates, and the eigenstates are orthogonal. Any state, including eigenstates, can be represented as a complex number vector. Assuming that
Definition 1
A language formulation representation L is a quantum morphism operator:
In the equation,
Inspired by the literature [4], we used the “one-hot” complex code
When representing a natural language,
Definition 2
Unitary Operator: A bounded linear operator in Hilbert space
The unitary operator
Here,
Here,
Proof.
In quantum mechanics, if the state of a system is certain, it is called a pure state. A pure state is a quantum state that can be directly described by a state vector
Equation (15) shows that the probability that a quantum system is in the pure state of
Combining Equations (14) and (15) gives Equation (16)
In natural language representation, static text strings can be implemented using Equation (11). However, when processing a dynamic text stream, the semantics of the same word, phrase or sentence in different contexts can be different. Therefore, it is necessary to introduce the concept of a mixed state. For example, the statement “I like this song very much” in a static text can be described using the equation
A set of text symbols
Here,
4.2. Character-Level CNN Language Model Based on Quantum Mechanical
However, in the present study, the input data are density operators, and the potential connections among the data are fully considered in this type of representation. Compared with traditional text representation methods, this type of input data can be processed in a more intuitive manner that is more similar to processing pictures. Therefore, the main component of the CNN model that we adopted is the spatial convolutional module. The model structure is shown in Figure 1. The input is the density operator that represented text using the quantum semantic space model.
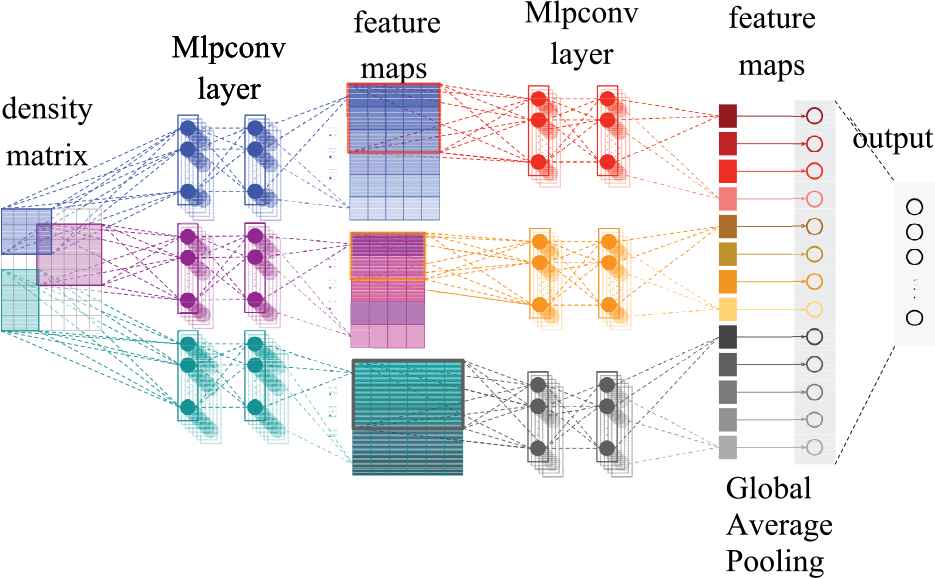
An example of a character-level convolutional neural network (CNN) language model with a two-layer network-in-network (NIN) structure. The input layer is a density operator. The convolution operation was conducted on two layers of mlpconv to obtain feature combinations that represented abstract concepts. Feature combinations went through GAP and were then input into the softmax layer for classification.
Let
To enhance the discrimination ability of the local receptive fields, the NIN model [35] was introduced into the model used in the present study. Its structure is shown in Figure 1. In a traditional CNN, a series of over-complete filters can be used to extract various potential features. However, this process requires too many parameters. Because the high-level features of the CNN are obtained by combining lower-level features, in NIN, the traditional generalized linear model (GLM) filter (mlpconv) in each local receptive field was replaced by a multi-layer perceptron (MLP) to generate concepts that are more abstract before combining low-level features into high-level features. By contrast, the last layer of a traditional CNN is a fully connected layer with many parameters and is prone to overfitting. Therefore, in the NIN, the last mlpconv layer outputs the spatial average of the feature map directly into the next layer for classification using global average pooling (GAP).
The layer structure of mlpconv is shown in Figure 1. It is essentially a general nonlinear function approximator. Thus, the a priori distribution of the potential concepts might not be required but could be obtained through local feature extraction using the universal function approximator. In this way, a more abstract conceptual representation can be achieved. The mlpconv can be trained using the entire network and backpropagation.
The calculation performed by the mlpconv layer is shown as follows:
Unlike the traditional fully connected layer, in GAP, each feature map is globally pooled to generate an output. This pooling can greatly reduce the number of network parameters and avoid overfitting. In addition, each feature map is equivalent to an output feature, and this feature characterizes the output class. GAP can replace the fully connected layer because after passing through the mlpconv layer, each feature map represents high-level information that can be used for classification, detection or other tasks. Algorithm 1 shows the procedure of training the model.
Algorithm 1: Pseudo code for the training process.
1: procedure trainmodel(
2:
3: for
4: for
5:
6:
7:
8: end for
9: end for
10: end procedure
5. EXPERIMENTS
5.1. Dataset
For comparison with existing works [5,12,13,23,39–42], We conduct hyperparameter search, model introspection, and ablation studies on the English PTB. The PTB dataset is a large annotated corpus, which consists of 929k training words, 73k validation words, and 82k test words was used as the experimental corpus in the present study. This corpus has been annotated for part-of-speech (POS) information. Over half of it has been annotated for skeletal syntactic structure [43].
The top 10,000 most frequently used words were used to build the vocabulary, and the remaining words were treated as unknown and mapped to the
5.2. Methodology
All of the parameters of the model were trained using the training set. The performance of the model was evaluated using the standard (per-word) perplexity measure in the test set.
Experiments were conducted on a PC with Intel Core i7, 32 GB of RAM, and a NVIDIAGTX1080Ti GPU running Ubuntu 18.04.3 LTS. Networks were constructed using tensorflow-gpu-1.10.0 with NVIDIA CUDA 9.0 and the NVIDIA CuDNN 7.1 library. In order to create superpositions of states, unitary operator and mixed state, We used: Quantum Toolbox in Python(QuTiP) [44].
5.3. Optimization
The models are trained by backpropagation through time. We backpropagate for 35 time steps using stochastic gradient descent with a fixed momentum of 0.9, where the learning rate is initially set to 1.0 and is halved if the perplexity does not decrease by more than 1.0 on the validation set after an epoch. The network is trained using mini-batches of size 128. The training process starts from the initial weights and learning rates, and it continues until there is no further improvement in accuracy on the training set; then, the learning rate is decreased by a factor of 10. This procedure is repeated once, so the final learning rate is one percent of the initial value. The parameters of the model are randomly initialized over a uniform distribution with support [0.05, 0.05]. As a regulariser, dropout with probability 0.5 is applied to the outputs of all layers except the last mlpconv layer. All of the networks used in the experiment section use GAP instead of fully connected layers at the top of the network, and the resulting vector is fed directly into the softmax layer.
5.4. Results
The hyperparameters of the model is summarized in Table 1. The networks we used in the experiment consist of three stacked mlpconv layers, and the mlpconv layers are followed by a spatial max pooling layer that down-samples the inputs.
| 70 | |||
|---|---|---|---|
| 5 | |||
| 5 | |||
| 3 | |||
| 192 | |||
| 2 | |||
| 192 | |||
| 192 | |||
| 10 | |||
| Relu | |||
Notes. CNN = convolutional neural network; MLP = multi-layer perceptron.
Hyperparameter of the character-level CNN language model. Here,
Table 2 shows the comparison results of our model with states of the arts. Comparing with other models, the PPL of our model is slightly higher than LSTM-Char-Large and LSTM-2 [5,23]. However, the number of parameters in our model is around 6 million, which is significantly less than LSTM-Char-Large and LSTM-2. For the model with smaller size of parameters (e.g., KN-5), its PPL is 78% higher than our model. The main reasons are: (1) our QLM-based model is able to embedding not only a single word, but a sentence. Therefore, our model does not need additional filters to abstract the concept, and hence significantly reduces the number of parameters. (2) we add a NIN architecture to directly output the spatial average of the feature maps from the last mlpconv layer as the confidence of categories via a GAP layer. The resulting vector is fed into the softmax layer before final output.
| Model | PPL | Size |
|---|---|---|
| CNN-MLPconv | 79.1 | 6 m |
| LSTM-Char-Small | 92.3 | 5 m |
| LSTM-Char-Large | 78.9 | 19 m |
| KN-5 | 141.2 | 2 m |
| RNN | 124.7 | 6 m |
| RNN-LDA | 113.7 | 7 m |
| genCNN | 116.4 | 8 m |
| FOFE-FNNLM | 108.0 | 6 m |
| DeepRNN | 107.5 | 6 m |
| Sum-Prod Net | 100.0 | 5 m |
| LSTM-1 | 82.7 | 20 m |
| LSTM-2 | 78.4 | 52 m |
Notes. CNN = convolutional neural network; PTB = Penn Treebank.
Comparison between the model proposed and other language models in terms of their performance on the English-language PTB test set. PPL stands for the perplexity and size refers to the approximate number of parameters in the model [5].
5.5. Discussion
5.5.1. Quantum semantic coding analysis
Currently, CNNs in NLP generally use word vector encoding, and the data generated have their own fixed internal order, such as a matrix that represents a sentence, with each row of the matrix representing a word [14,15]. Even in the latest character-level study [5], texts are stitched together in the order of the words. Given that approach, the convolution window should have the same width as the input matrix. In the present study, density operators are used as the CNN input, and the matrix is no longer a sequence of words but a representation of an uncertain state. At the same time, this approach solves the problem of an indefinite text length. To analyze whether it is better to use image-processing methods to process the density-operator text representation, we present the following two comparative experiments for discussion.
Comparison Experiment 1: Use the density operator as the CNN input, set the convolution window width to be the same as the width of the input, and use only one pair of convolution and pooling layers [5].
Comparison Experiment 2: Use word embedding as the CNN input, and the convolution operation is the same as in Section 4.2.
According to the results shown in Table 3, the following conclusions and speculations can be drawn:
Combining density-operator representation with CNN-NIN could achieve significantly better results;
When using word vectors as the input, the CNN-NIN structure did not bring significant improvements to the language model; and
When using density-operator representation as the input, the image processing setting worked better for the CNN filters, that is, when using a filter width that differs from the input matrix's width.
| Model | PPL |
|---|---|
| Density Operator+CNN-non-static[5] | 86.3 |
| Word Vectors[5]+CNN–NIN | 99.5 |
| Density Operator+CNN–NIN | 79.1 |
Notes. CNN = convolutional neural network; NIN = network-in-network; PTB = Penn Treebank.
The PPL results of the proposed model and the two comparative experiments on PTB. The model used in the first comparative experiment was a CNN that used a density-operator input and filters of the same width as the input. The model in the second comparative experiment used word-embedding input and CNN–NIN.
5.5.2. Effects of the number of mlpconv and MLP layers on the model
In this paper, ablation studies were applied to quantitatively analyze the role of the NIN network layer. We trained different models based on the settings listed in Table 4, and the results showed that the models that did not use NIN performed significantly worse. We speculated that the NIN network structure was a good fit for optimizing the CNN that used density-operator inputs. It derived more abstract concepts from the density operator through the non-linear structure of the MLP and enhanced the models generalization ability. Additionally, we trained another model that used the same number of layers as that of the NIN, solely to verify whether the performance decline was due to decrease in model size that was caused by not using the NIN. The results showed that this model performed significantly worse than the NIN network did.
The NIN network structure used significantly fewer parameters while achieving good performance; thus, it provided room for using more network layers. Therefore, we trained two models with more layers:
10 layers of mlpconv, and each mlpconv layer had two layers of MLP, and
3 layers of mlpconv, and each mlpconv layer had 10 layers of MLP.
The comparison results are shown in Table 4. Having more mlpconv or MLP layers did not lead to significant changes in the model.
| WithoutNIN | 10NIN+2MLP | 3NIN+10MLP | |||||||
|---|---|---|---|---|---|---|---|---|---|
| filter | - | conv1–3 | conv4–8 | conv9–10 | conv1 | conv2 | conv3 | ||
| filtersize | 3, | 4, | 5 | 8 | 5 | 3 | 8 | 5 | 3 |
| filters | 100, | 100, | 100 | 92 | 192 | 192 | 92 | 192 | 192 |
| mlp layers | - | 2 | 2 | 2 | 10 | 10 | 10 | ||
| nodes | - | 192 | 92 | 92(10) | 192 | 92 | 92(10) | ||
| PPL | 98.1 | 78.9 | 79.5 | ||||||
Notes. MLP = multi-layer perceptron; NIN = network-in-network.
Effects of layer settings of the NIN, mlpconv and MLP on the model.
6. CONCLUSION
This article presents a new NLM whose input is a character-level density operator. This model has fewer parameters but performs better than do baseline models that use word or character embeddings. Analyzing the experimental results shows that the quantum semantic space model can extract rich semantic and orthographic features. Using a CNN in the NIN is an effective method of representation learning. At present, most studies on NLP use words as input and must consider the word order. Even if character-level input is used, word-level analysis is still required after feature learning. In the present study, the input texts are first coded at the character level and then represented using the quantum semantic space model, and the density operator represents an uncertain state of the basic constituent units (characters). Therefore, a long text is represented by a mixed state and hence it can be integrated into a neural network. Using more concepts (such as entanglement) of quantum theory for text representation will be our next research step, as will finding more applications of this model for NLP tasks such as prediction or machine translation.
CONFLICT OF INTEREST
Authors have no conflict of interest to declare.
ACKNOWLEDGMENTS
This work was jointly supported by the Social Science Project of Shandong Province (Nos. 18CSPJ03, 18CHLJ09, 16CFXJ05), the National Natural Science Foundation of China (NSFC, Project No. 71801142), the Industry-University Cooperation and Education Project of Ministry of Education of China (201802047030), the Humanities and Social Sciences Research Project of Ministry of Education of China (17YJC630077).
REFERENCES
Cite this article
TY - JOUR AU - Zhihao Wang AU - Min Ren AU - Xiaoyan Tian AU - Xia Liang PY - 2019 DA - 2019/11/25 TI - Character-Level Quantum Mechanical Approach for a Neural Language Model JO - International Journal of Computational Intelligence Systems SP - 1613 EP - 1621 VL - 12 IS - 2 SN - 1875-6883 UR - https://doi.org/10.2991/ijcis.d.191114.001 DO - 10.2991/ijcis.d.191114.001 ID - Wang2019 ER -